作者:聚水潭数据研发负责人 溪竹
聚水潭是中国领先的 SaaS 软件服务商,核心产品是电商 ERP,协同350余家电商平台,为商家提供综合的信息化、数字化解决方案。公司是偏线下商家侧的 toB 服务商,员工人数超过3500,线下网点超过100个,每天要承载大概2亿包裹量的 ERP 发货流程,产生的数据量超过10TP。
公司数据智能产品的定位是将数据融入到服务流程中,在 ERP 这个大的体系里,帮助商家进行数据提效。从整体分层来说,包括智能报表、智能经营、智能分析,其中智能分析包括实时大屏、渠道分析等。
今年3月,聚水潭将 StarRocks 引入到数仓架构中,针对数据智能产品中的多个服务进行了升级。在 StarRocks Summit 2023 上,公司数据研发负责人溪竹结合应用场景分享了在 StarRocks 使用过程中的许多经验和感受。
我们将溪竹的精彩演讲整理出来,希望对你有所帮助。
数仓架构演进
聚水潭数仓经历了大约 10 年的发展,早期跟很多公司一样采用的是 SQL Server 集群,在数据规模较小的情况下 SQL Server 的在线服务和 OLAP 能力都能满足业务需求。随着业务发展,SQL Server 在复杂查询场景下,无法提供丰富的多维统计指标计算能力。所以从 2018 年开始自建 GreenPlum 作为 AP 分析集群,至 2021 年集群数量已经超过 70 个集群。另外在线的 SQL Server 集群也在不断增加,现在已经超过了 1000 套。从 2020 年开始,我们接入了实时链路,从偏数据库的场景转向了偏计算和存储能力的场景。
至此我们只是在不断的扩展集群规模,增加服务数量,导致了数据是隔离的,服务是分散的。为此我们希望有一款产品具有更强的在线化服务能力和实时数据处理能力,能够帮我们整合数据存储,统一数据服务。经过充分的调研和验证,今年 3 月,我们将 StarRocks 引入进来,逐步形成了现在的统一在线服务架构。目前我们的 StarRocks 集群规模约 10 个,整体 CPU 约 1000 个。

StarRocks 大规模集群的构建及验证
今年 3 至 11 月份,我们一直跟着 StarRocks 在迭代,这个过程中我们根据不同系统和服务的要求总结了三种模式,分别服务于不同业务。
存算分离模式之快递揽收报表
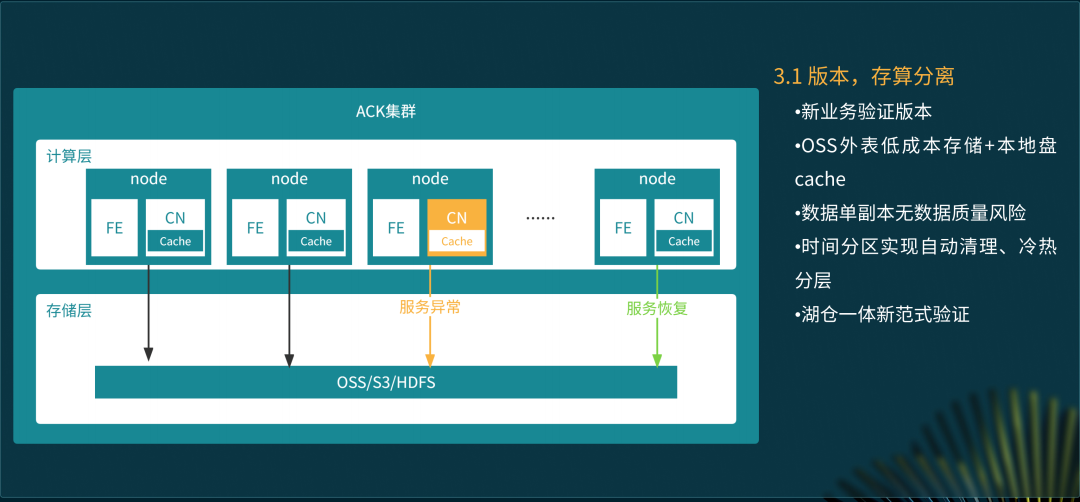
存算分离模式是基于 3.1 的新的湖仓范式探索对于湖能力的一些补充。从 ERP 视角来看,在线业务 10 多年积累下来的庞大的数据之前没有做分级的存储,这块存在很大的资源优化空间。经过统计,我们查询数据的范围超过近三年的都不到 1% ,所以我们通过存算分离的方式将全量数据存储到价格较低的 OSS,本地只 cache 近期的热数据。这样的方式不仅满足了 99% 以上的查询性能要求,同时存储成本也约等于原先的 1/8。
今年 7 月份左右,我们在快递揽收报表业务场景上对 StarRocks 3.1 存算分离进行了完整测试。从业务场景来说,快递揽收属于物流场景,一个单子被揽收掉以后,历史数据就没有意义了,所以我们就默认做了 105 天的本地数据清理策略,完全自动化地管理数据清理动作。这个测试当时在 StarRocks 社区还产生了一些影响力。测试表明,在开启本地 cache 的情况下,查询性能和存算一体基本持平,响应基本上都是毫秒级别,另外让我们有一点惊喜的是,内存管理变得更高效了,存算分离的内存使用相比存算一体减少了 50%,计算资源性价比更高。

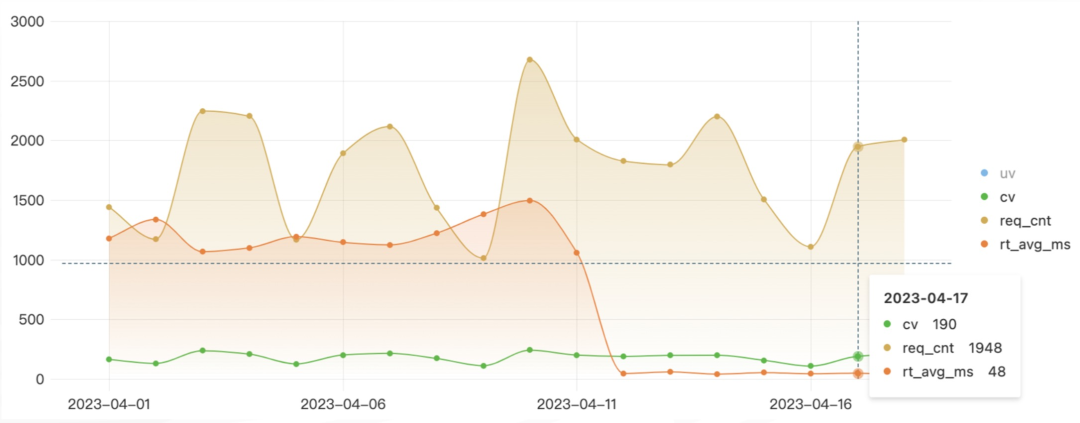
下图中为针对 StarRocks 存算分离版本查询性能的测试,我们从一款商业化产品 OLAP 外表切流到 StarRocks 内部表,使用本地盘加速 OSS 的效果非常好,延迟直接从秒级降到了毫秒级,这对于我们基于 StarRocks 3.1 建立湖仓模式是一个信心的基础。
高可用模式之订单全链路分析
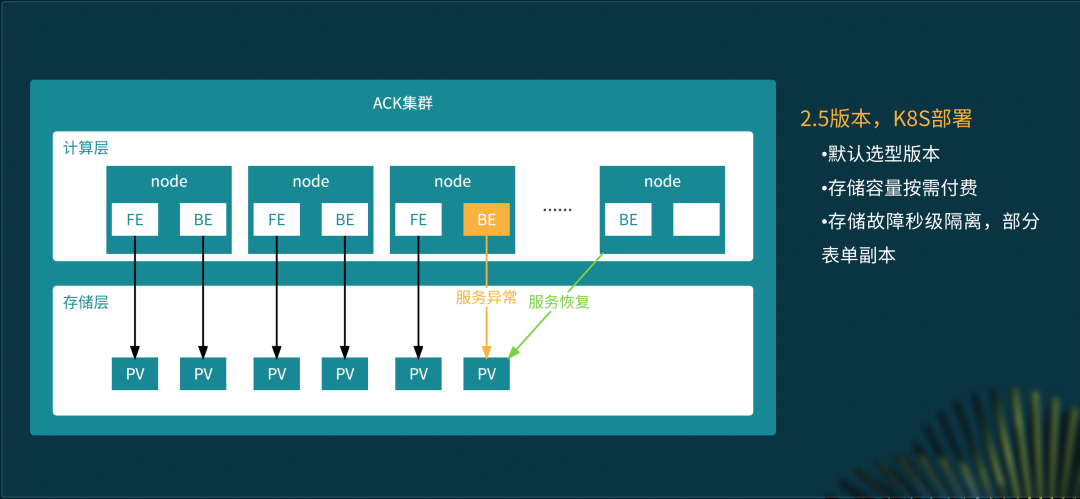
在高可用模式下,最重要的就是服务不可以中断,异常情况下服务可以快速恢复。此时 StarRocks 计算节点为单独购买,存储主要依靠云盘,在节点出现故障时,无论是本身基于容器弹性的逃逸能力,还是副本数据迁移的能力,都能够快速恢复服务,保证了服务的高可用。
订单全链路分析业务采用了高可用模式的的部署方式。通过出库单得到拣货、验货、播种、打包等各阶段操作人和操作时间,进行订单的全链路分析。业务方最主要的诉求就是服务稳,查询快。
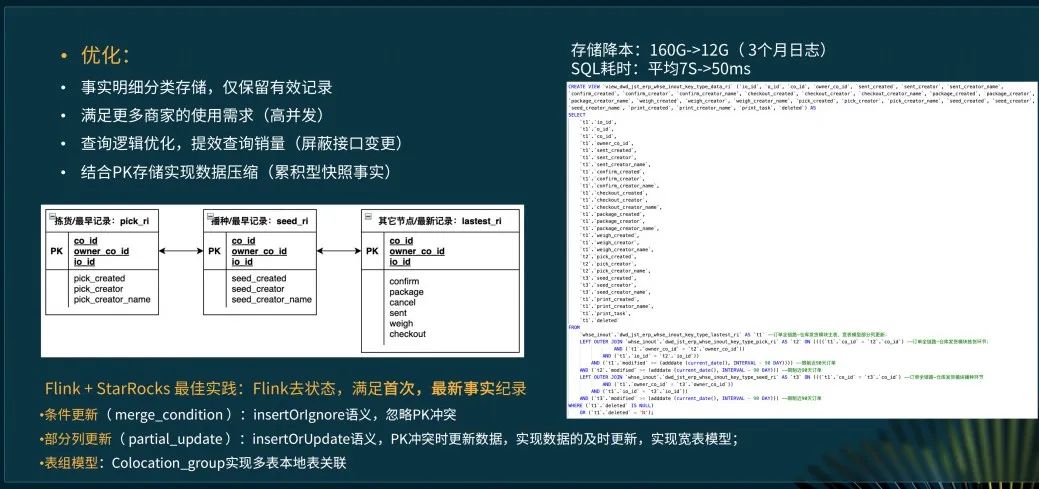
我们采用了主键模型对事实明细分类存储,仅保留有效记录,通过 colocate group 的方式加速查询效率并优化了查询逻辑,最后 SQL 平均耗时从 7 秒降到了 50 毫秒,性能提升 8 倍!
高性能模式之售后预警
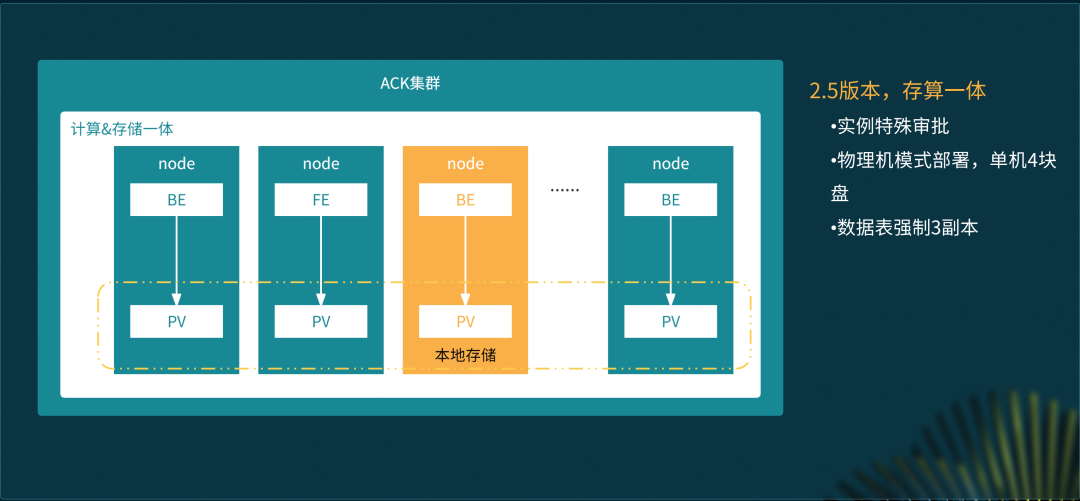
以售后预警中的发货监控服务为例,需要支持六七千的商家同时访问,且对查询访问的时延要求很高。这类业务模式下我们采用高性能模式的部署方案。我们把存储从云盘改到了本地盘。这套架构是一个很经济的架构,3 年 4 折去买 ECS 的机器,然后去部署这套架构,性能很好,成本又很低。
售后实时预警监控如下图所示:
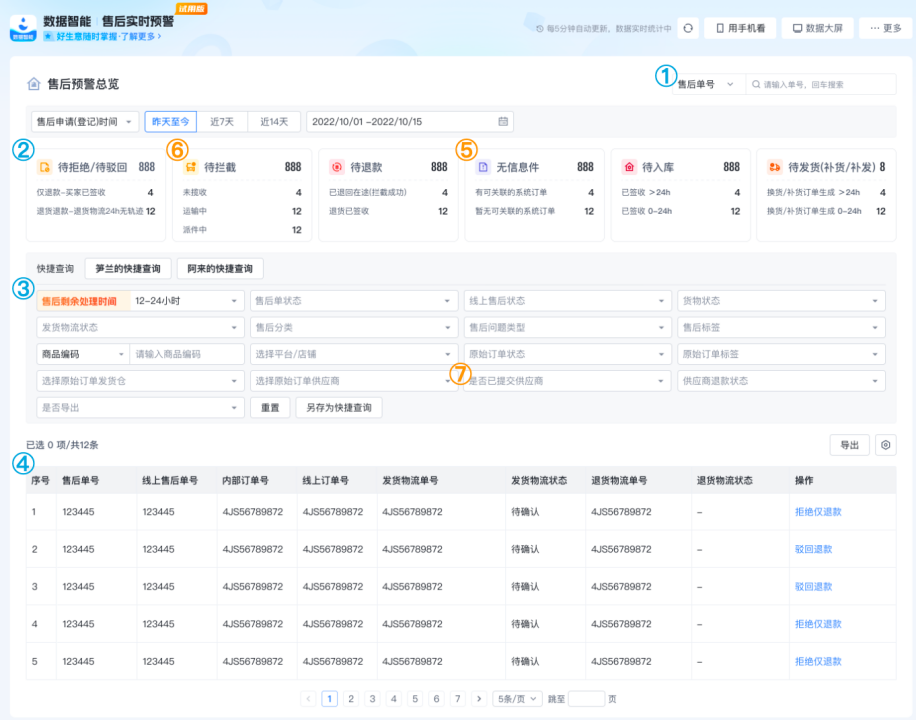
这其中包含了订单/售后单/物流单查询,分类型风险提醒,多店铺/长周期/多维度组合筛选,明细筛选/排序/处理/导出-外部业务对接,智能识别退货物流异常/无信息件,拦截提醒防资损,供分销、三方仓业务等多个业务。主要为售后提效,资损监控提供服务保证。
采用高性能模式我们做到了百亿级数据秒级计算,100MB/s 的写入吞吐,300QPS ,RT 350ms。大家可以在评估自己业务的时候,大概能有一个体感,现在一个 300 core 的 StarRocks 集群能达到什么样的能力?基于本地盘的部署,是可以实现百亿级数据、毫秒级延迟的。
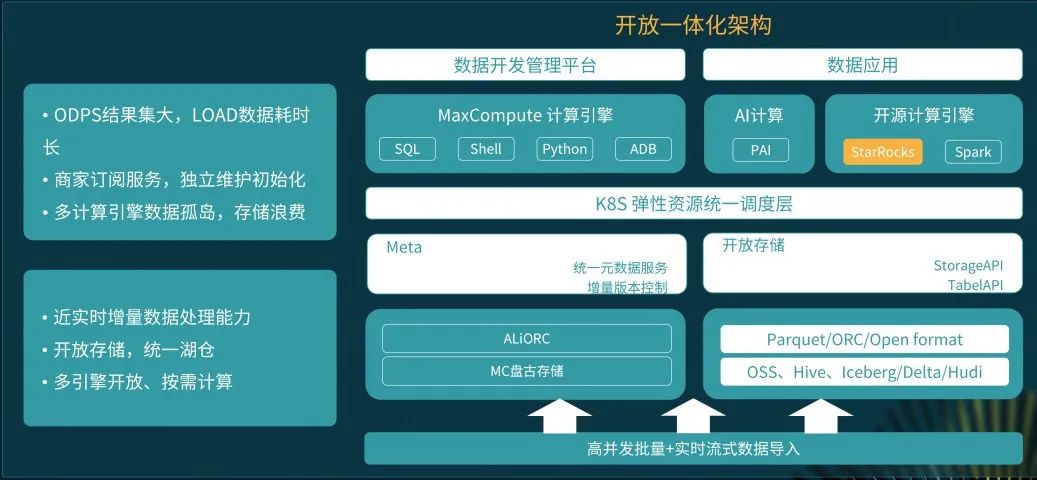
未来展望
我们每天要 load 的数据超过百亿,目前架构下还存在着 load 数据耗时长,多计算引擎数据孤岛、存储浪费等问题,StarRocks 无论是加速 OSS,还是帮助我们去加速阿里云 ODPS 的数据,都可以有效简化我们的数据加工、降低存储成本,这一块非常值得期待。另外,我们从 0 到 1000 core的规模只用了不到一年,我觉得在 StarRocks 使用上还有很大想象空间,未来一年我们希望用 StarRocks 来探索真正的湖仓新范式的落地。
本文由 mdnice 多平台发布











![Linux操作系统极速入门[常用指令]](https://img-blog.csdnimg.cn/direct/c7b1dfc1c1714edd9682e3f289855e82.png)