1. 集群角色
zookeeper集群下,有3种角色,分别是领导者(Leader)、跟随着(Follower)、观察者(Observer)。接下来我们分别看一下这三种角色的作用。
领导者(Leader):
事务请求(写操作)的唯一调度者和处理者,保证集群事务处理的顺序性;
集群内部各个服务器的调度者。对于create、setData、delete等有写操作的请求,则要统一转发给leader处理,leader需要决定编号、执行操作,这个过程称为事务。
跟随着(Follower)
处理客户端非事务(读操作)请求(可以直接响应)。
转发事务请求给Leader。
参与集群Leader选举投票。
观察者(Observer)
对于非事务请求可以独立处理(读操作)。
对于事务性请求会转发给leader处理。
Observer节点接收来自leader的inform信息,更新自己的本地存储,不参与提交和选举投票。通常在不影响集群事务处理能力的前提下提升集群的非事务处理能力。
如何配置观察者:
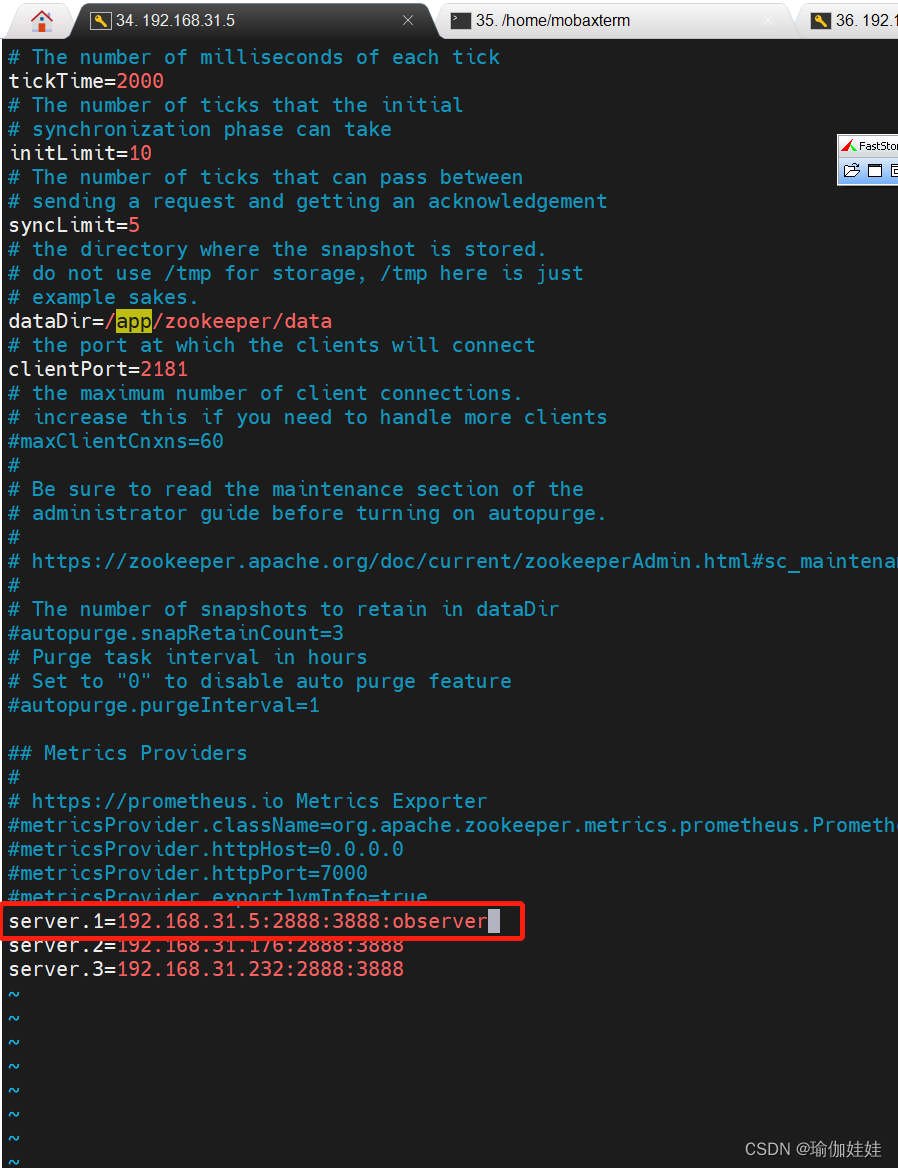
在配置文件zoo.cfg写集群配置时需要后面写observer
#配置一个ID为1的观察者节点 server.1=192.168.31.5:2888:3888:observer
Observer应用场景:
提升集群的读性能。因为Observer和不参与提交和选举的投票过程,所以可以通过往集群里面添加observer节点来提高整个集群的读性能。
跨数据中心部署。 比如需要部署一个北京和香港两地都可以使用的zookeeper集群务,并且要求北京和香港客户的读请求延迟都很低。解决方案就是把香港的节点都设置为observer。
2. 集群架构
leader节点可以处理读写请求;
follower只可以处理读请求,follower在接到写请求时会把写请求转发给leader来处理。

Zookeeper数据一致性保证:
- 全局可线性化(Linearizable )写入∶先到达leader的写请求会被先处理,leader决定写请求的执行顺序。
- 客户端FIFO顺序∶来自给定客户端的请求按照发送顺序执行。
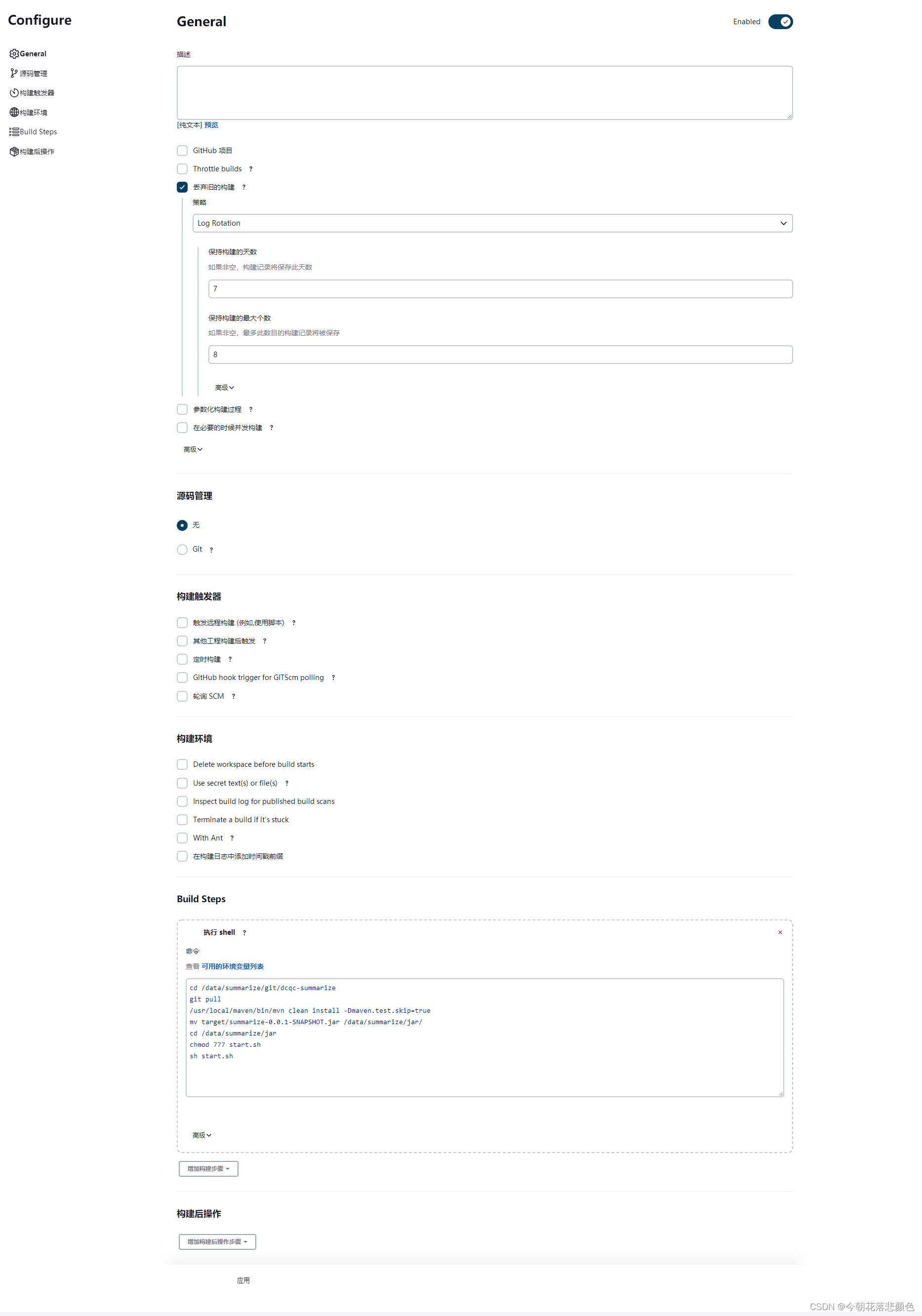
3. 集群搭建
本节介绍的一主两从的集群搭建。
3.1 准备工作
准备三台虚拟机
192.168.31.5
192.168.31.176
192.168.31.232
每台机器根据单机环境先进行单机环境的搭建 ;
注意:根据单机环境搭建集群的每个节点时,先不要启动,继续按照一下后续步3.2骤修改完文件以及3.3创建myid文件后再启动。否则启动集群节点时可能会出现状态是standalone的问题,解决看3.4启动时遇到的问题进行解决。
单机环境搭建参考:Zookeeper特性与节点数据类型详解-CSDN博客中的Zookeeper单机搭建。
3.2 修改配置文件
修改每台机器中zookeeper的zoo.cfg文件
vim zoo.cfg#修改数据存储目录 dataDir=/app/zookeeper/data#文件末尾追加配置内容 server.1=192.168.31.5:2888:3888 server.2=192.168.31.176:2888:3888 server.3=192.168.31.232:2888:3888

集群配置内容含义:
server.Number=IP:port1:port2
Number 是一个数字,表示这个是第几号服务器; 集群模式下配置一个文件 myid,这个文件在 dataDir目录下,这个文件里面有一个数据 就是Number 的值,Zookeeper 启动时读取此文件,拿到里面的数据与 zoo.cfg 里面的配置信息比较从而判断到底是哪个server。
IP 是这个服务器的地址;
port1 是这个服务器Follower与集群中的Leader服务器交换信息的端口;
port2 是万一集群中的Leader服务器挂了,需要一个端口来重新进行选举,选出一个新的Leader,而这个端口就是用来执行选举时服务器相互通信的端口。
3.3 创建myid文件,配置服务器编号
- 在每台服务器zookeeper的dataDir对应目录下创建 myid 文件,内容为对应ip的zookeeper服务器编号。
- dataDir目录是你在zoo.cfg中配置的目录。内容是你在zoo.cfg中配置集群时server.后面的数字。
- 添加 myid 文件时,一定要在 Linux 里面创建,不要 notepad++等工具里面创建后上传,因为可能会乱码。并且内容上下不要有空行,左右不要有空格。
vim myid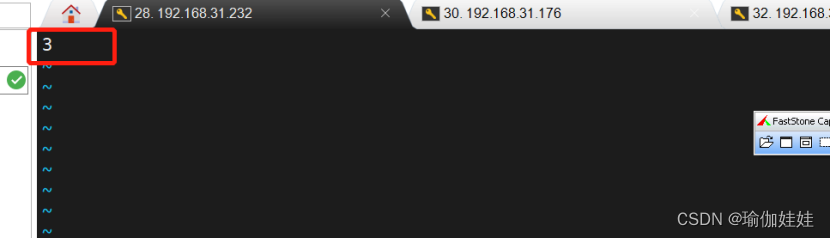
3.4 启动集群
启动前需要关闭防火墙(生产环境需要打开对应端口)
分别启动三个节点的zookeeper的server
#启动节点 bin/zkServer.sh start #查看节点状态 bin/zkServer.sh status如列图所示,我依次启动了192.168.31.5、192.168.31.176、192.168.31.232服务器中zk的节点,每次都是启动后直接查看状态。
首先,我们启动192.168.31.5上的zk,启动后,我直接查看的状态,报错了,不用管。jps查看,其实我们的服务已经启动了
继续启动第二台机器192.168.31.176上的zk,查看状态,leader已经产生了,就是这台机器。
接着,我回头就查看了一下第一台机器上zk的状态,此时查看状态不报错了,改节点是follower。
最后,我启动了最后一台机器192.168.31.232上的zk。状态是follower.
所以,三个节点启动后状态是leader或者follower才表示集群启动成功了。




3.4 启动时遇到的问题
集群启动时有可能会失败,一般情况就是zoo.cfg配置错误或者防火墙没有关闭(生产环境端口没有开放)
3.4.1关闭防火墙
#centos7
# 检查防火墙状态
systemctl status firewalld
#关闭防火墙
systemctl stop firewalld
systemctl disable firewalld3.4.2 启动后查看状态的Mode是standalone
解决:
1. 检查zoo.cfg文件中有书写错误是否有误;
2. 如果这台机器上有单机版的zookeeper启动,关闭之前的zookeeper,重新启动;(我的单机版的zk改配置,变为集群节点时就遇到的是这个问题。)
3.4.3 .sh权限不足
在启动zookeeper时,报zkServer.sh权限不足,当时没有截图记录,但和下述截图中zkCli.sh权限不足一样,明明有root权限,但是就是提示权限不足。
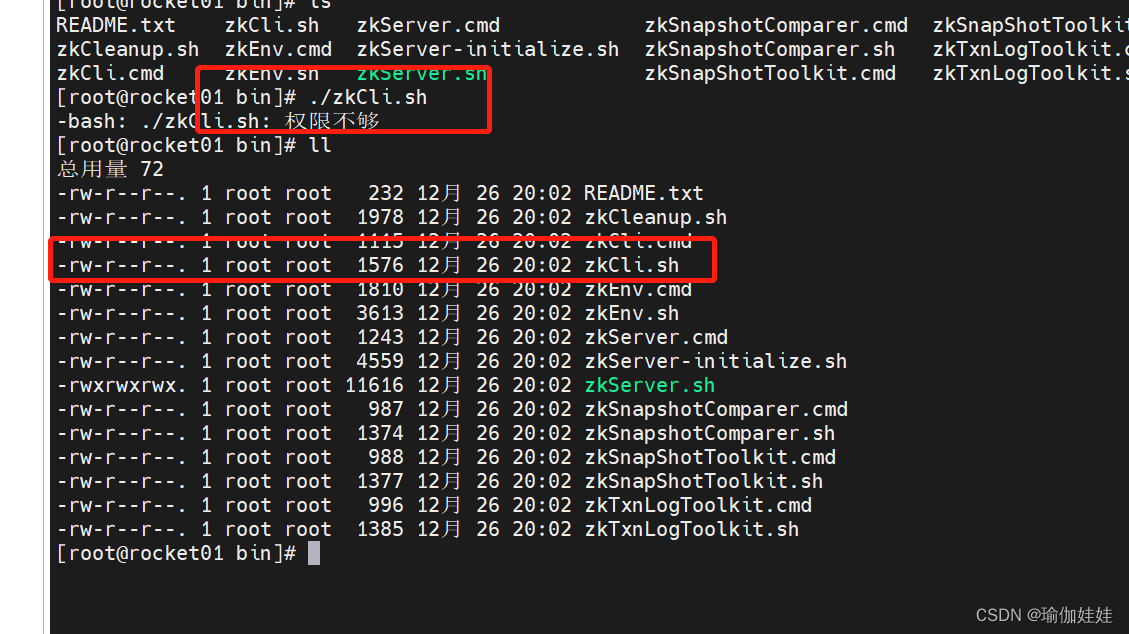
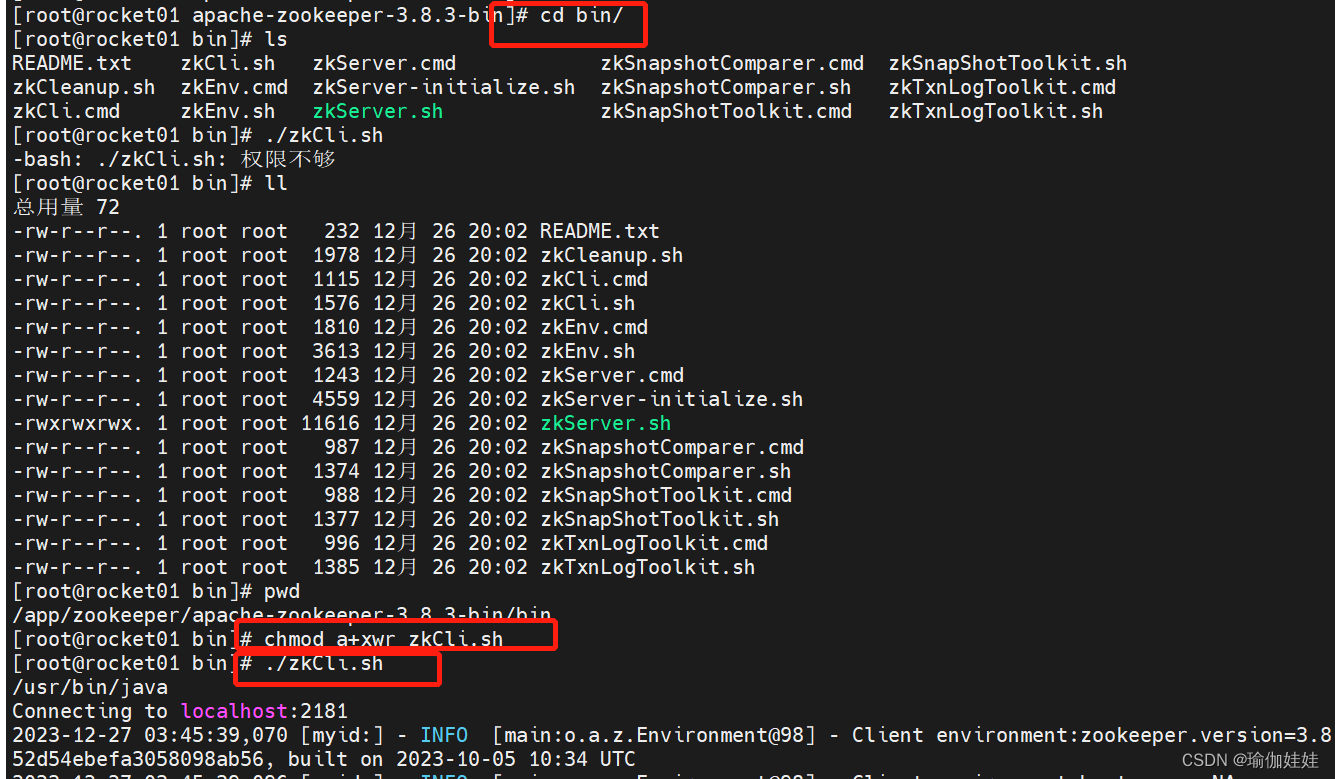
接下来,以解决zkCli.sh权限不足为例,解决该问题,如遇到zkServer.sh权限不足,可参考这个解决方法;
进去zookeeper的bin目录后,执行以下指令
chmod a+xwr zkCli.sh再次执行
./zkCli.sh客户端执行成功了
4. 集群下leader的选举原理
本节我们将简单看一丢丢zookeeper选举相关的源码,来理解一下zookeeper集群下leader是如何被选举出来的。
选举投票对比核心源码:
org.apache.zookeeper.server.quorum.FastLeaderElection类中totalOrderPredicate方法
/*** Check if a pair (server id, zxid) succeeds our* current vote.**/protected boolean totalOrderPredicate(long newId, long newZxid, long newEpoch, long curId, long curZxid, long curEpoch) {LOG.debug("id: {}, proposed id: {}, zxid: 0x{}, proposed zxid: 0x{}",newId,curId,Long.toHexString(newZxid),Long.toHexString(curZxid));if (self.getQuorumVerifier().getWeight(newId) == 0) {return false;}/** We return true if one of the following three cases hold:* 1- New epoch is higher* 2- New epoch is the same as current epoch, but new zxid is higher* 3- New epoch is the same as current epoch, new zxid is the same* as current zxid, but server id is higher.*/return ((newEpoch > curEpoch)|| ((newEpoch == curEpoch)&& ((newZxid > curZxid)|| ((newZxid == curZxid)&& (newId > curId)))));}
从上述源码中我们可以得知,zk选举leader投票对比规则如下:
- 首先比较epoch,选取具有最大epoch的服务器。epoch用于区分不同的选举轮次,每次重新选举时都会增加epoch。
- 如果epoch相同,则比较zxid(事务ID),选取事务ID最大的服务器。zxid表示最后一次提交的务ID。
- 如果zxid也相同,则比较myid(服务器ID),选取服务器ID最大的服务器。
ZooKeeper的Leader选举过程是基于投票和对比规则的,确保集群中选出一个具有最高优先级的服务器作为Leader来处理客户端请求。
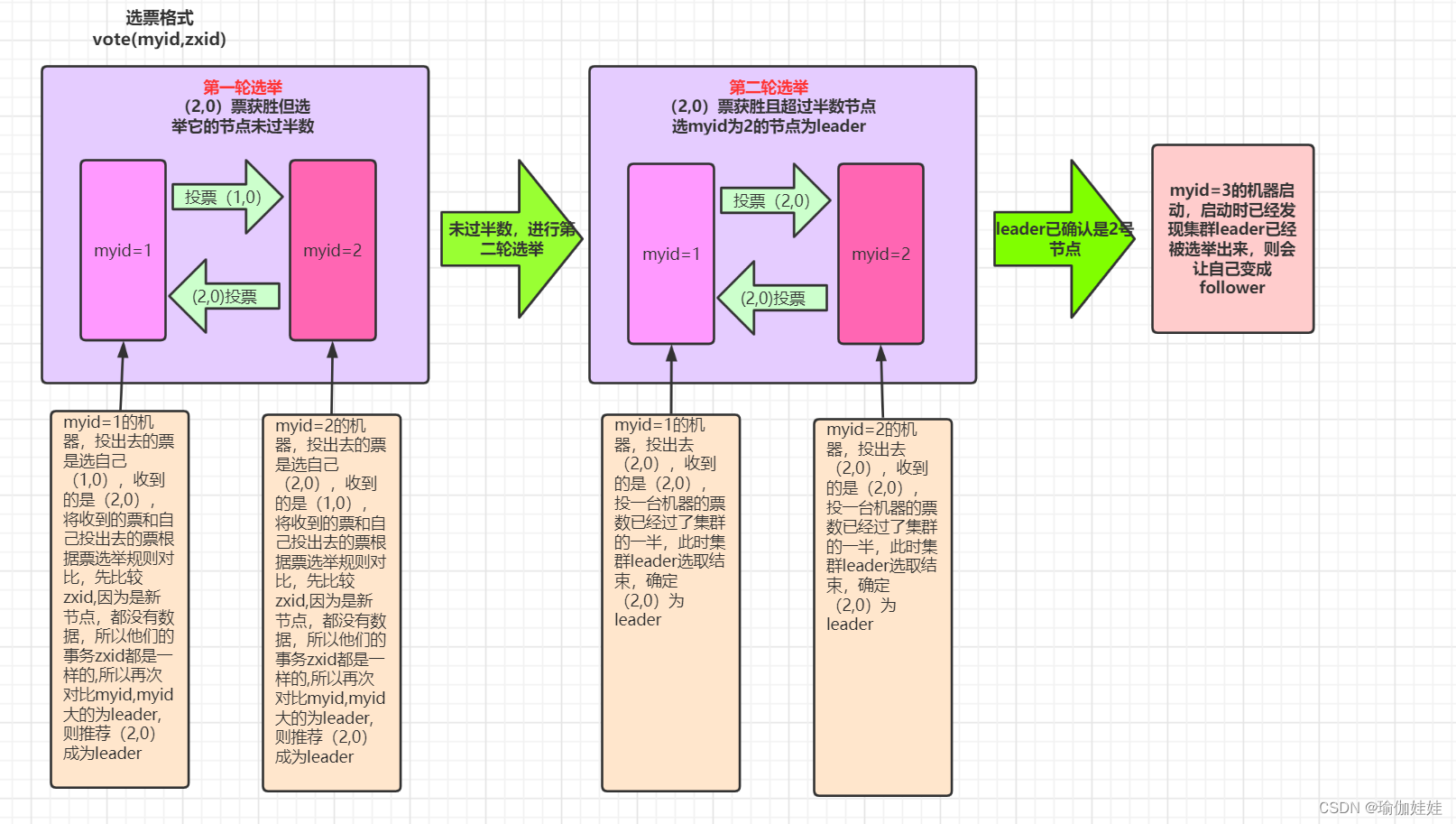
接下来,我们根据上述规则,以服务启动期间选举为例,来理解一下选举的过程。
场景:3个节点的myid依次为1,2,3;我们启动节点的顺序也是1,2,3。则leader则是myid为2的节点。当我们启动2台机器后,就开始发生了选举。(可以对照本文章的3.4启动集群,详细描述了启动过程以及成为leader节点的是哪一个)。