目录
一、套壳的风波此起彼伏
二、到底什么是大模型的壳
2.1 大模型的3部分,壳指的是哪里
大模型的内核
预训练(Pre-training)
调优(Fine-tuning)
2.2 内核的发展历程和万流归宗
2.3 套壳不是借壳
三、软饭硬吃,套壳真的不行吗
四、神仙打架,百姓吃瓜
4.1 自研的佼佼者
4.2 模仿也不丢人
4.3 读书人偷书不算偷
模仿学习(Imitation Learning)
知识蒸馏(Knowledge Distillation)
五、我们还要再硬一点
一、套壳的风波此起彼伏
国内“百模大战”,我形容是“群模乱舞”,具体国内有哪些著名的大模型,请参考我的文章——
群模乱舞,AI大模型盛开,国内大模型盘点_ai大模型有哪些-CSDN博客
里面列出了大厂的模型,以及很多学院派的大模型。
大模型一夜之间,如同AIGAI,自体繁殖一样多起来,很多媒体的声音,也此起彼伏,说国内的大模型,很多都是开源大模型的套壳版本。
这里面动静最大的,可能是李开复先生的零一大模型张量命名事件。其推出的“Yi”大模型,这款模型被揭露只是对LLaMA进行了表面上的修改——仅仅改变了两个张量的名称。这种创新,确实在AI界并非孤例,而是一个普遍现象。
有人说,开源就该这样利用,不然开源干什么?有人说,闭源才是自主研发,参考开源就是套壳。
2023年2月,Meta首次发布了Llama羊驼系列模型。在这个初始版本中,羊驼系列包括了四种不同规模的模型:参数量分别为7亿、13亿、33亿和65亿。7月,Meta公布最新大模型 Llama 2(羊驼 2),包含 7B、13B 和 70B 三种参数变体,可免费用于商业或者研究。这引起不小的轰动,不光是国内,很多国外的大模型,基本都是复用了Llama2,后面我们会讲,为什么选择这个大模型,因为确实不用重复发明轮子了。
有想了解开源和闭源生态的,可以参考我的文章:【AI】马斯克说大模型要开源,我们缺的是源代码?(附一图看懂6大开源协议)_马斯克说大模型在技术上的突破-CSDN博客
非 AI 从业者,视套壳如洪水猛兽,吃瓜者认为套壳就是抄袭的代名词;真正的 AI 从业者,对套壳讳莫如深,需要借鉴,又狠怕惹锅上身。但由于“套壳”本身并没有清晰、准确的定义,导致行业对套壳的理解也是一千个读者有一千个哈姆雷特。
那么,问题来了——
二、到底什么是大模型的壳
2.1 大模型的3部分,壳指的是哪里
要想知道什么是大模型的壳,我们要先知道,大模型包括哪几个部分。
大模型的内核
大模型的内核通常指的是模型的核心架构和算法,这些设计决定了模型如何处理输入数据并生成输出。在大模型中,内核往往包含了大量的计算单元(如神经元、层等),以及它们之间的连接方式和权重。这些计算单元通过特定的数学运算(如矩阵乘法、激活函数等)共同工作,以提取输入数据的特征并做出预测。
大模型的内核设计通常基于深度学习理论,尤其是神经网络。近年来,如上所述,Transformer架构因其出色的性能成为了大模型内核的热门选择。Transformer利用自注意力机制来处理序列数据,能够捕获长距离依赖关系,并在各种NLP任务中取得了显著成果。
也就是说,大家的内核,基本都来自相同的老祖宗。
预训练(Pre-training)
预训练是指在大规模数据上对模型进行初步的训练。这个过程通常是无监督的,意味着模型不需要人工标注的数据就可以学习。预训练的目标是让模型学习到通用的知识和表示方法,这样它就能够更好地适应各种下游任务。
在大模型中,预训练尤为重要,因为庞大的参数量需要大量的数据来有效训练。预训练不仅可以提高模型的泛化能力,还可以加速后续任务的学习过程。例如,在NLP领域,BERT、GPT等模型就是通过在大规模文本语料库上进行预训练来获得强大的语言理解能力的。
调优(Fine-tuning)
调优,也叫做“微调”,是指在特定任务的数据上对已经预训练过的模型进行进一步的训练。这个过程通常是有监督的,需要使用标注好的数据来指导模型的学习。调优的目标是调整模型参数,使其更好地适应特定任务的需求。
在大模型中,调优通常比从头开始训练要高效得多,因为预训练已经为模型提供了一个很好的起点。通过调优,模型可以在较少的迭代次数和较小的数据集上达到较好的性能。此外,调优还可以使模型更加灵活地适应各种场景和任务需求。
在漫长的预训练之后会得到一个基座模型(Base Model),在基座模型的基础上加入特定行业的数据集做进一步的微调,就会得到一个微调模型(Fine-tuning Model),或者称为行业模型、垂直模型。
2.2 内核的发展历程和万流归宗
我们都知道,是大模型让AI达到如此的地位,实际上,AI经历了一段低迷期。
关于AI复兴推进器的自然语言处理、神经网络、遗传算法,我都分别写过文章去介绍。还有AI爆发的推进器之卷积神经网络、生成对抗网络、变分自动编码器、迁移学习、知识图谱、注意力机制与深度学习模型等,也可以参考我的之前的文章。
在 2020 年之前,NLP 的模型研究基本都是围绕算法展开,基于 BERT、T5 与 GPT 架构的模型百花齐放。这一时期模型参数较小,基本都在 10 亿以内量级。其中,谷歌 BERT 的表现独领风骚,基于 BERT 架构的模型一度在阅读理解的竞赛排行榜中屠榜。
唯有不同的是,2017 年谷歌大脑团队发布的Transformer 神经网络架构。"Transformer" 的核心思想是利用自注意力(self-attention)机制来处理序列数据,如文本或音频。这种架构避免了传统循环神经网络(RNN)、卷积神经网络或长短期记忆网络(LSTM)中顺序计算的限制,从而能够并行处理整个输入序列,大大提高了计算效率。
到 2020 年,OpenAI 发布一篇论文,首次提出了 Scaling Laws(尺度定律),NLP 的研究才正式进入大模型时代——大模型基于“大算力、大参数、大数据”,模型性能就会像摩尔定律一样持续提升,直到“智能涌现”的时刻。
OpenAI公司从此进入公众视野,并且一发不可收拾,除了谷歌最新发布的 Gemini 是基于 T5 架构,几乎清一色都是从 GPT 架构衍生而来。可以说,GPT 完成了一场大模型架构内核的大一统。
可以参考下图:
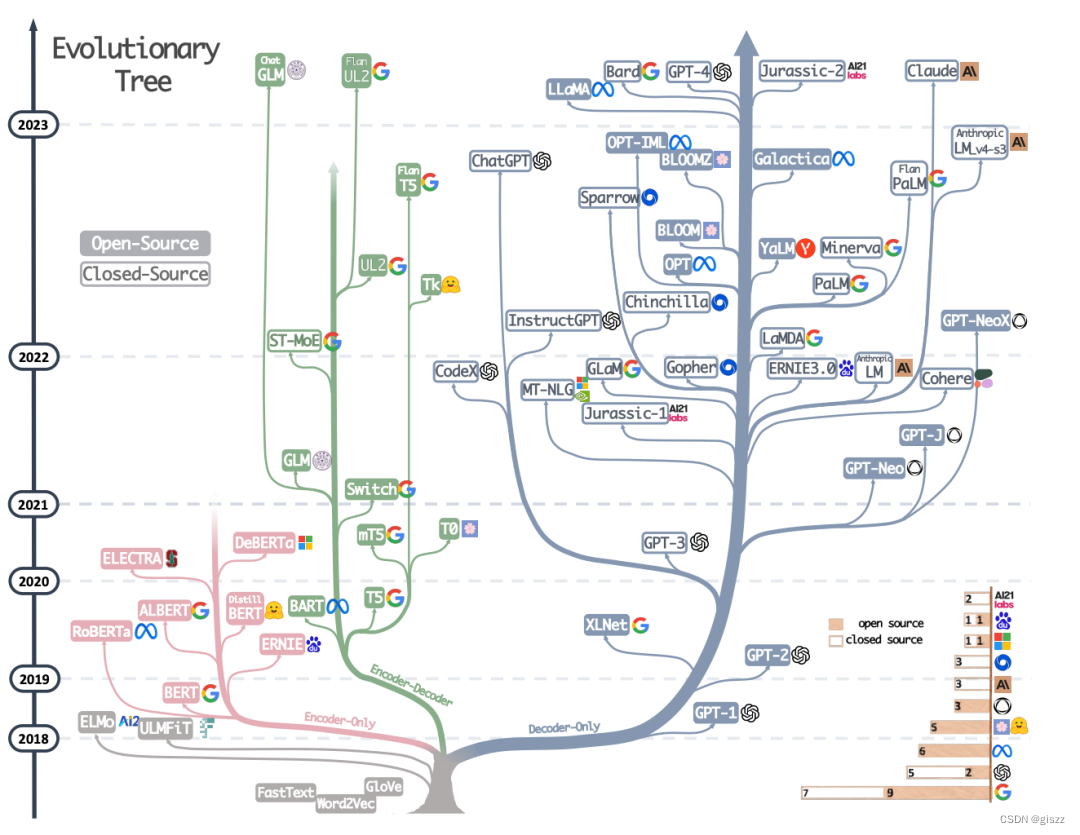
如此看来,别说什么套壳不套壳,人类的发源地就是那么几个。内核(DNA)算法框架,几乎都是一样的。
总结下,内核,就是3种:BERT、T5 和 GPT 。其中GPT是最枝繁叶茂的!
这3种框架内核,都广泛应用于自然语言处理(NLP)领域。
-
BERT(Bidirectional Encoder Representations from Transformers):BERT 是由 Google 在 2018 年提出的一种基于 Transformer 的预训练模型。它采用双向 Transformer 结构,能够在预测单词时同时利用该单词前后的上下文信息。BERT 在多项 NLP 任务中取得了显著的效果提升,并成为了许多后续研究的基础。
-
T5(Text-to-Text Transfer Transformer):T5 是由 Google 在 2019 年提出的另一种基于 Transformer 的模型。与 BERT 不同,T5 采用统一的文本到文本(text-to-text)框架,将所有 NLP 任务都转化为文本生成任务。这意味着无论是分类、问答还是摘要等任务,都可以使用相同的模型结构和训练方式来处理。
-
GPT(Generative Pre-trained Transformer):GPT 是由 OpenAI 在 2018 年提出的一种基于 Transformer 的自回归语言模型。它采用单向的 Transformer 结构,只能利用上文信息来预测下一个单词。GPT 在生成式任务(如文本生成、对话生成等)中表现出色,并且随着版本的迭代(如 GPT-2、GPT-3),其模型规模和性能也在不断提升。
这三种模型框架各有特点,但都是基于 Transformer 架构的深度学习模型,并在 NLP 领域取得了显著的成果。它们通常都需要大量的数据进行预训练,以学习到通用的语言表示和知识,然后再通过微调(fine-tuning)来适应特定的 NLP 任务。
2.3 套壳不是借壳
按照大家的现在普遍理解,实际上,内核我们往往是核心框架+预训练,因为这两个非常难,预训练的费用,动辄上亿,有实力的企业,一年做一次就不错了,文心一言4.0,如今最新的数据还是2023年4月份的。常理说,壳指的是调优,而并不能认为是“改个名字”,特别是改个变量名吧!如果真是直接套开源,改个名字,那才是我们理解的传统意义上的套壳。
除了那些直接用API蒙人的,其实大部分的大模型,都做了调优,也就是很多人说的套壳。当然,也有只做了提示词优化或者注入个性化知识库的大模型产品。
所以在大模型行业,套壳,是个中性词。
照搬开源,或者盗用别人API号称自研的,才是贬义词,那是借壳了。
为什么这么宽容?请往下看。
三、软饭硬吃,套壳真的不行吗
如上,本文内,我们把调优,叫做套壳,没有把改个大模型的名字,或者改个张量的名字,叫做套壳,那是借壳。外人也不懂,忽悠一些普通的资本,上市公司老板,还是绰绰有余的。那个我们是要坚决鄙视。
相反,套壳是个正常的模式,针对某个垂直领域,用几天调优一下,真的是个常见模式。
现在调优的论文非常多,可以这么说,堂而皇之的,软饭硬吃了。
为什么这么多软饭硬吃呢,是不套真的不行。上述我们知道,做一个大模型,包括内核、预悬链和调优三个部分,其中自己做预训练,是比开发一个大模型框架还要难太多的事。把很多公司都拦在了门外,大模型实际是一个高端局,门票太贵。
比如ChatGPT这样的大模型,预训练的花费、数据量和时间都是相当巨大的。
- 预训练的花费:ChatGPT等模型的训练成本非常高昂。根据OpenAI发布的报告,ChatGPT的训练成本大约在4700万美元左右。这包括了硬件、人力、电力等多方面的开支。对于更大的模型,训练成本可能会更高,甚至可能达到数亿美元。
- 预训练的数据量:ChatGPT等模型在预训练阶段需要处理的数据量也是巨大的。它们通常需要在数十亿甚至上百亿的文本数据上进行学习,以理解语言表达和实现人工智能语言处理任务。这些数据可能来自于各种来源,如网页、书籍、新闻文章等。
- 预训练的时间:训练一个大模型需要的时间也是非常长的。在预训练阶段,处理数十亿甚至上百亿的文本数据可能需要数天甚至数周的时间,具体取决于计算资源的多寡和模型规模的大小。此外,在微调阶段,虽然时间相对较短,但也可能需要几个小时到几天的时间,这取决于特定任务的数据量和复杂性。
因此,大部分的企业,一年,或者几个月,做一次预训练,就是很好的了。
正因如此,只有充足的算力、财力的大公司与资本支持的创业公司,才会涉足基座模型(预训练之后得到的模型)。“群模乱舞”中的国产大模型数量虽然多,但只有大约 10% 的模型是基座模型,90% 的模型是在开源模型基础上加入特定数据集做微调的行业模型、垂直模型。其中,应用最广、性能最好的开源基座模型,目前就是 Meta 的 Llama 2。
Llama2已经达到了GPT-3.5的水平,除非有能力自研一个达到GPT-4、甚至下一代 GPT-5 能力的模型,否则用Llama2是最好的选择。这里的能力指的是有技术能力,且有足够的资金持续投入,因为目前预期是 GPT-5 的训练可能需要 3-5 万张 H100,成本在 10-20 亿美金。
Tips:H100是Nvidia推出的一款面向计算的GPU。它采用Hopper架构,建立在一个巨大的814mm²芯片上,使用台积电的4N工艺和800亿个晶体管。这款GPU在算力上的FP16、TF32以及FP64性能都是其前代产品A100的3倍,并且具有强大的能力,据英伟达CEO黄仁勋表示,20个H100 GPU便可承托相当于全球互联网的流量。
四、神仙打架,百姓吃瓜
4.1 自研的佼佼者
有人会觉得奇怪,那么多国产的大模型,我为什么更青睐百度的文心一言,是不是收取了代言费。确实是因为百度在AIGC上,确实赢了一分。
2019年,百度就发布了自研的预训练框架 ERNIE,也就是今天的文心大模型,今天已经更新到ERNIE-4.0(4.0比3.5免费版有较大的跨越,聪明了很多)。值得一提的是,谷歌 BERT 与百度 ERNIE 名字取材于美国著名儿童节目《芝麻街》中的角色,两者是一对好友。
4.2 模仿也不丢人
对于开源社区而言,这是一套非常正常的做法,开源的意义就是公开自己的研究成果,促进技术的交流与共享,让开源社区内更多的研究者受益。
Llama 2 也是站在过去开源模型的肩膀上一步步发展而来。比如,Llama 2 的模型架构中, Pre-normalization(预归一化)受 GPT-3 启发,SwiGLU(激活函数)受 PaLM 的启发,Rotary Embeddings(位置编码)受 GPT-Neo 的启发。其他模型也经常魔改这几个参数来做预训练。
羊驼2这么牛,但是也就是3.5的水平,下一步,就上不去了。这是开源的必然,很多开源软件,都符合这个特征,大模型,当然也不例外。羊驼做到这一步,已经很牛了。
4.3 读书人偷书不算偷
读书人偷书不算偷,还有一句话,叫书非借不能读也。数据当然也可以借一借。
预训练的数据,在于多,不在精。
调优的数据,在于精,不在多。
预训练的数据在于多,对于互联网时代,难的好像就是钱的门槛,数据其实不缺。
调优的数据,要想高质量,或者对齐竞对,那就要下大功夫了,而且要注入商业逻辑。
说到“借书”,这里要提到一个模仿学习,或者知识蒸馏的概念。
模仿学习(Imitation Learning)和知识蒸馏(Knowledge Distillation)是两种机器学习中的技术,它们在不同的场景下被用来提升模型的性能或效率。
模仿学习(Imitation Learning)
模仿学习,又称为学习从示范(Learning from Demonstration, LfD),是一种机器学习的方法,其中模型通过观察专家的行为来学习如何执行任务。专家的示范可以是人类的操作,也可以是一个已经训练好的模型的行为。模仿学习的目标是让模型能够模仿专家的行为,并在没有专家指导的情况下自主地完成任务。
在模仿学习中,有两种主要的方法:行为克隆(Behavior Cloning)和逆强化学习(Inverse Reinforcement Learning, IRL)。
- 行为克隆:这种方法直接将专家的行为映射到模型的行为上。通过收集专家的示范数据,并使用监督学习的方法来训练模型,使其尽可能地模仿专家的行为。
- 逆强化学习:与行为克隆不同,逆强化学习旨在从专家的示范中推断出奖励函数,然后使用强化学习的方法在这个奖励函数下训练模型。
知识蒸馏(Knowledge Distillation)
知识蒸馏是一种模型压缩技术,它允许我们将一个大型、复杂的模型(通常称为“教师模型”)的知识转移到一个较小、较简单的模型(通常称为“学生模型”)中。知识蒸馏的核心思想是利用教师模型的输出来指导学生模型的训练,而不仅仅是使用原始的标签数据。
在知识蒸馏中,除了使用传统的分类损失(如交叉熵损失)来训练学生模型外,还会引入一种额外的损失,这种损失衡量了学生模型的输出与教师模型的输出之间的差异。通过这种方式,学生模型能够学习到教师模型的“暗知识”,即在训练数据中没有明确给出但有助于提升性能的信息。
知识蒸馏可以用于多种应用场景,包括模型压缩、加速推理、以及在不牺牲太多性能的情况下将大型模型部署到资源受限的设备上。
这就是了,偷书是有理论模型滴!
刚刚过去的2023 年 12 月,字节跳动的“疑似套壳”事件正是来源于此。根据字节跳动的回应,2023 年初部分工程师曾将 OpenAI 的 API 服务应用于实验性的模型研究,但并未上线,后来已经禁止该行为。其实,这是很多大模型或者AI公司都心照不宣的事情,是个男人都会犯的那种错误。
其实很多大模型,特别是高校的,都是在当学生,OpenAI,肯定是很好的老师了。值得一提的是,OpenAI 在服务条款中明确禁止使用 ChatGPT 生成的数据开发与 OpenAI 竞争的模型。所以,上述模仿模型不能用于商业用途。
很多国外的大模型,为了加强中文的能力,把文心一言当老师,也是很正常的。
神仙打架,我们老百姓,就是吃个瓜好了。
五、我们还要再硬一点
在预训练阶段模仿 Llama 2、在微调阶段学习ChatGPT 的数据,是个比较不错的技术路线。
当然,我们内心还是渴望自己能再硬一点。
一些模型做prompt的调优,类似文心一言的提示词应用,客户模糊的提示词,根据一定的规律,内置更好的逻辑。
想了解更多提示词的朋友,可以参考我的系列文章:
【AIGC】一起学习prompt提示词(1/4)-CSDN博客
再进一步,一些模型做类似插件,或者植入个性化的数据,行业知识库等。实现更好的表现。
还有一些模型,能做到我们今天说的,调优的大模型,真心是不错的了。
起码没有去偷人家的API,说是自己的产品,或者类似以前的盗图、盗链,说是自己的作品吧!
再次重申,如果是上面的情况,那就是绝对贬义的借壳了。
目前大部分的大模型,都可以说,是站在巨人的肩膀上吧!
大模型的应用,实际还任重而道远。
随着人工智能技术的不断发展,大模型已经在自然语言处理、计算机视觉、语音识别等领域取得了显著的成果。然而,要实现大模型在更多领域的广泛应用,需要将其与具体行业的需求相结合,进行垂直化开发和应用。
行业垂直应用是指将大模型的技术和算法应用到特定行业中,解决该行业中的实际问题。例如,在医疗领域,可以利用大模型进行疾病诊断、药物研发等工作;在金融领域,可以利用大模型进行风险评估、投资决策等工作;在制造领域,可以利用大模型进行智能制造、质量控制等工作。
通过行业垂直应用,大模型可以更好地满足各行业的需求,提高行业的智能化水平和工作效率。同时,由于不同行业的数据和场景具有独特性,这也为大模型的发展提供了更多的挑战和机遇。
然而,要实现大模型在行业垂直应用中的广泛应用,还需要克服一些技术和社会方面的挑战。例如,需要解决大模型的可解释性和鲁棒性问题,以确保其在各种复杂场景下的稳定性和可靠性;同时还需要考虑数据隐私和安全问题,以保护用户的数据安全和隐私权益。
toC领域也有巨大的场景,充满着想象的空间,我们拭目以待吧!
(giszz出品,感谢关注)