论文题目:TimesURL: Self-supervised Contrastive Learning for Universal Time Series Representation Learning
论文地址:https://arxiv.org/abs/2312.15709
代码地址:暂无
摘要
学习适用于各种下游任务的通用时间序列表示具有挑战性,但在实际应用中很有价值。最近,研究人员试图利用计算机视觉(CV)和自然语言处理(NLP)中自我监督对比学习(SSCL)的成功来解决时间序列表示问题。然而,由于特殊的时间特征,仅仅依靠其他领域的经验指导可能对时间序列无效,并且难以适应多个下游任务。为此,本文综述了SSCL中涉及的三个部分:1)设计正对增广方法,2)构造(难)负对,3)设计SSCL损耗。对于1)和2),我们发现不适当的正负对构建可能会引入不适当的归纳偏差,这既不能保持时间性质,也不能提供足够的判别特征。对于3),仅仅探索段级或实例级语义信息不足以学习通用表示。为了解决上述问题,我们提出了一种新的自监督框架TimesURL。具体来说,我们首先引入基于频率时间的增强来保持时间属性不变。在此基础上,我们构建了双universum作为一种特殊的难负样本来指导更好的对比学习。此外,我们引入时间重构作为与对比学习的联合优化目标,以捕获段级和实例级信息。因此,TimesURL可以学习高质量的通用表示,并在6个不同的下游任务中实现最先进的性能,包括短期和长期预测、imputation、分类、异常检测和迁移学习。
1 介绍
学习信息丰富且通用的多类型下游任务时间序列表示是一个基本但尚未解决的问题。由于时间序列数据的高维性和特殊的时间特征,以及不同任务需要不同的语义信息,将自我监督对比应用于时间序列需要定制解决方案。
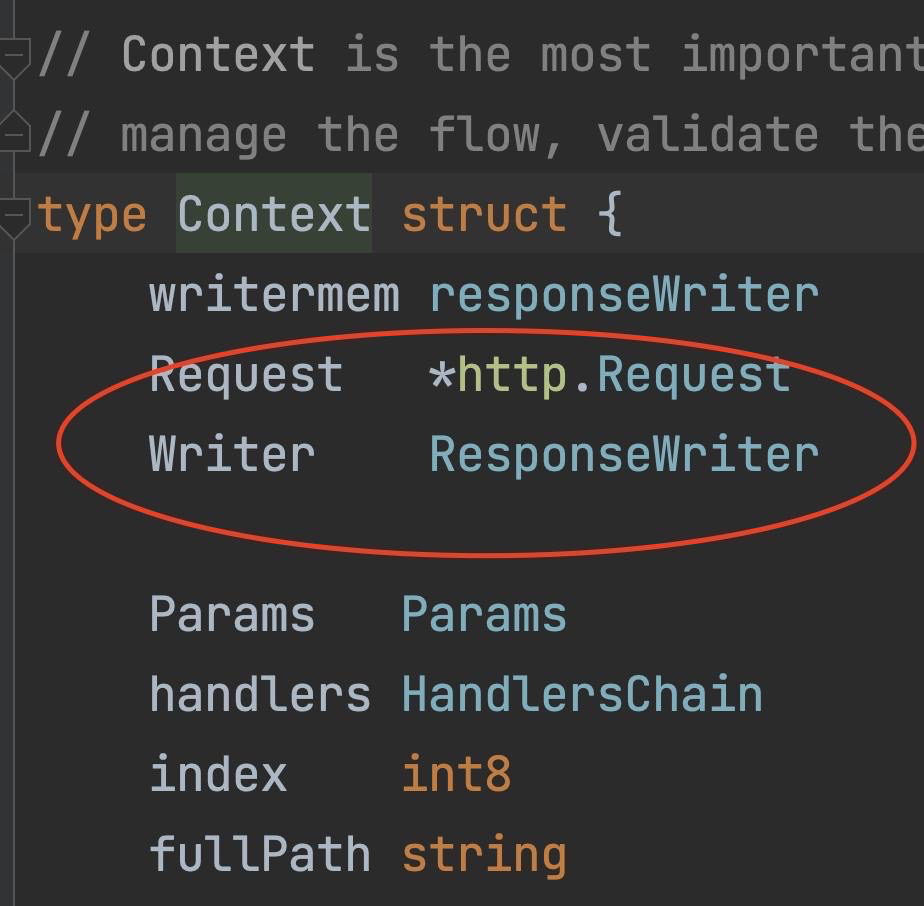
本方法中涉及的四个主要部分,包括1)正样本设计的增强方法,2)骨干编码器,3)(难)负对,4)预训练任务的损失,并试图投入努力探索在通用表示学习中更有效的时间序列特征捕获解决方案。由于骨干编码器在时间序列编码器学习中得到了广泛的研究,我们的注意力主要集中在剩下的三个组成部分:
1)大多数增广方法在应用于时间序列数据时,可能会引入不适当的归纳偏差。
直接借用了CV和NLP领域的思想。可能会破坏原始时间序列中固有的时间变化,干扰时间依赖性,影响过去和未来时间戳信息之间的关系。因此,由于时间序列的有价值的语义信息主要存在于时间变化和依赖关系中,这种增强无法捕获有效的通用表示学习所需的适当特征。
2)难负样本选择的重要性在其他领域得到了证明,但在时间序列文献中仍未得到充分探索。
由于局部平滑性和马尔可夫性,大多数时间序列片段可以看作是简单的负样本。这些片段往往表现出与正样本的语义不相似,只贡献了很小的梯度,因此无法提供有用的判别信息。虽然包含少量难负样本(与正样本具有相似但不完全相同的语义)已被证明有助于改进和加快学习,它们的有效性被大量容易的简单负样本所掩盖。
3)仅使用分段器实例级的信息是不足以学习通用表示的。
预测、异常检测和imputation,它们更多地依赖于在段级别捕获的细粒度信息,因为这些任务需要推断特定的时间戳或子序列。分类和聚类,优先考虑实例级信息,即粗粒度信息,旨在推断整个系列的目标。因此,当面对任务不可知的预训练模型时,在预训练阶段缺乏对特定任务的先验知识或意识,片段级和实例级信息对于实现有效的通用时间序列表示学习是必不可少的。
2 创新点
-
设计了一种新的基于频率时间的增强方法,称为FTAug,该方法是时域裁剪和频域混频的结合。
-
设计了double Universums作为难负样本。在特征空间中,分别在实例和时间维度上,将特定的正样本与负样本进行特异性混合,作为特殊的高质量硬负样本。
-
共同优化对比学习和时间重建,以在片段和实例级别捕获和利用信息。
-
完成六个下游任务:短期和长期预测、imputation、分类、异常检测和迁移学习。
3 方法
-
由原始数据 x 生成被掩蔽的 xm ,再分别经过 FTAug 生成数据增强的 x' 和 xm' 。
-
得到两对原始数据和增强数据,第一对 (x,x') 用于对比学习,第二对(xm, xm')用于时间重构。
-
将上述集合与fθ进行映射,得到相应的表示 r , rm , r' , rm'
-
上述23表示,预训练损失为:计算xm和xm'的重构损失;计算 r 和 r' 之间的对比损失
1)采用合适的增强方法构建正对,2)有一定数量的硬负样本用于模型泛化,3)通过对比学习和时间重建损失共同优化编码器fθ以捕获两层信息,保证了上述模型的有效性。
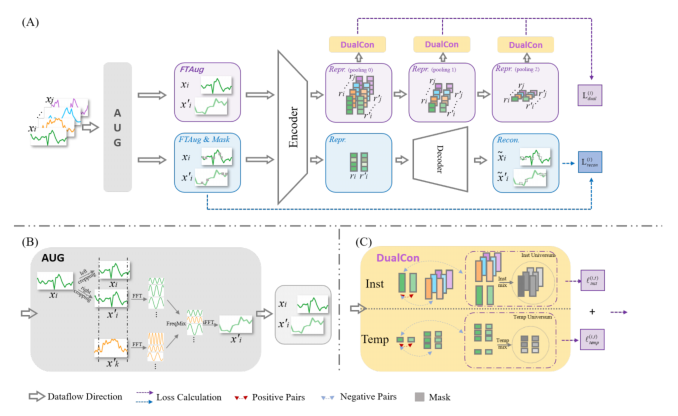
3.1 FTAug增强
大多数增强策略都是任务相关的,可能会引入对数据分布的强假设。更严重的是,它们可能会扰乱对预测等任务至关重要的时间关系和语义一致性。因此,我们选择上下文一致性策略,该策略将两个增强上下文中相同时间戳的表示视为正对。我们的FTAug结合了频率和时域的优势,通过频率混合和随机裁剪产生增强的上下文,FTAug只适用于培训过程。
-
频率混合是将样本进行FFT运算,将xi中一定比例的的频率分量替换为同一批次另一个随机训练实例xk的相同频率分量,从而产生新的上下文视图,然后我们使用逆FFT转换回来得到一个新的时域时间序列。
在样本之间交换频率成分不会引入意想不到的噪声或人为周期性,并且可以为保持数据的语义特征提供更可靠的增强。
-
随机裁剪是上下文一致性策略的关键步骤。对于每个实例xi,我们随机抽取两个重叠的时间段[a1, b1], [a2, b2],其中0<a1≤a2≤b1≤b2≤t,对比学习和时间重构进一步优化重叠时间段[a2, b1]中的表示。
最终,该方法能够保持时间序列的重要时间关系和语义一致性,对各种任务都有帮助。
3.2 Double Universum 构建难负样本
由于时间序列的局部平滑性和马尔可夫性,大多数负样本都是简单的负样本,因为它们从根本上缺乏驱动对比学习所需的学习信号,因此不足以捕获时间智能信息。
Double Universum 是将Mixup Induced universum 应用在实例和时间方面,将特定的正特征与未注释数据集的负特征混合在一起。
i 为输入时间序列样本的索引,t为时间戳。ri,t和r'i,t表示相同时间戳t的表示但是是xi的两个增广。时间戳为t的第i个时间序列的在时间层面的Universum可以表示为:其中,t' 是在两个子序列重叠处的时间戳集合中随机选取的,t'不等于t。
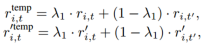
同理,时间戳为t的第i个时间序列的在实例层面的Universum可以表示为:其中,j表示批B中除i以外的任何其他实例。
![]()
λ1, λ2∈(0,0.5)是锚点随机选择的混合系数,λ1, λ2≤0.5保证正样本的贡献始终小于负样本。
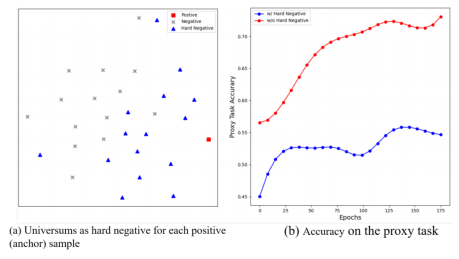
如图(a)所示,大多数Universum(蓝色三角形)更接近正样本,因此可以视为难负样本。
如图(b)所示,在使用(蓝)和不使用(红)Universum在ERing数据集上训练TimesURL时,正面样本被评为整体负面样本的百分比,来表明难负样本的难度。尽管TimesURL的代理任务性能下降了,但是,线性分类的性能得到了进一步的提高。
3.3 段级信息的对比学习
将double Universums分别作为时间和实例对比损失的附加难负样本注入到对比学习中。第 i 个时间序列在时间戳t处的两个损失可以表示为:负样本相当于 batch中其他实例 和 正样本元素所构造的难负样本的集合。

这两种损失是相互补充的,以捕获实例特定特征和时间变化。使用分层对比损失在沿时间轴的学习表征上使用最大池化来进行多尺度信息学习。
在几次最大池化操作之后,重要的时间变化信息(如趋势和季节)会丢失,因此在顶层进行对比实际上无法捕获足够的实例级信息用于下游任务。
![]()
3.4 实例级信息的时间重构
使用随机掩蔽策略,仅在被屏蔽的时间戳上计算MSE损失。
![]()
总的损失为:α是平衡这两种损失的超参数。
![]()
4 实验
使用TCN作为骨干编码器,类似于TS2Vec。baseline有15个,不同任务选择的baseline不同。
4.1 下游任务
4.1.1 分类
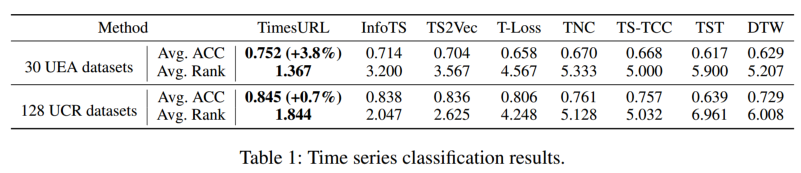
遵循与TS2Vec相同的协议,使用带有RBF内核的SVM分类器在表示上进行分类训练。选择UEA和UCR数据集
4.1.2 插值
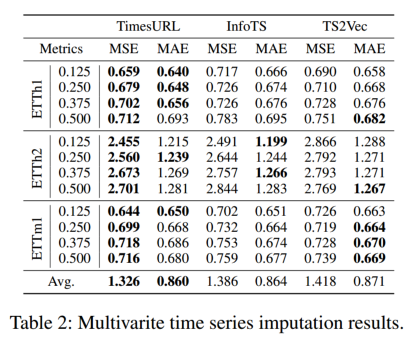
使用ETT数据集,以{12.5%,25%,37.5%,50%}的比例随机屏蔽时间点。遵循与TimesNet相同的设置,使用MLP网络进行下游任务。
4.1.3 长期和短期预测
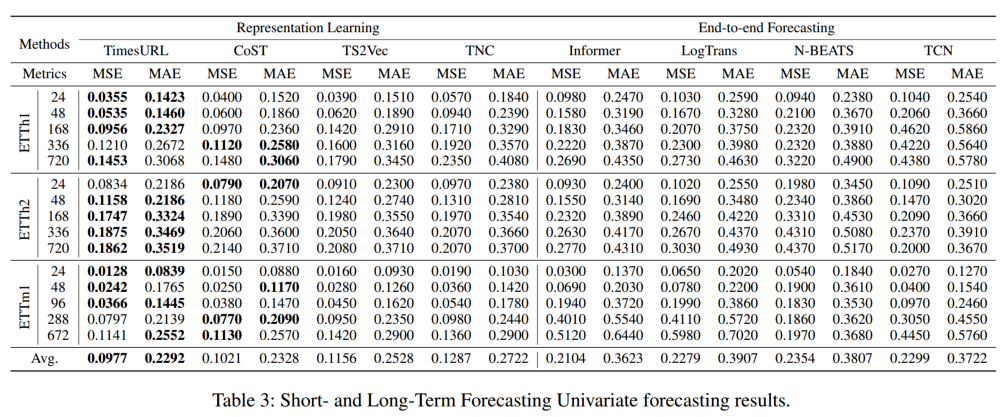
使用ETT、ECL和Weather数据集,后两个数据集的结果见(附录)。短期预测的范围为24和48,而长期预测的范围为96到720
4.1.4 异常检测
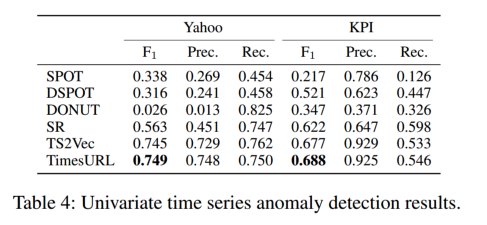
在时间序列异常检测中确定时间序列切片中的最后一个点是否异常,在训练过程中,每个时间序列样本按照时间顺序分成两半,其中前半部分用于训练,后半部分用于评估。使用KPI 和Yahoo 数据集,其中包括367小时采样时间序列。KPI是一个竞争数据集,包含多个分钟采样的真实KPI曲线。
4.1.5 迁移学习
在一个条件下(即源域)训练,在其他多个条件下(即目标域)测试。在UCR中的CBF和 CinCECGTorso上训练模型,在UCR的前10个数据集中评估模型在其他9个目标域的下游分类任务上的性能。
CBF的平均结果为0.864,CinCECGTorso为0.895,无转移的情景为0.912。更多的迁移学习结果见(附录)。
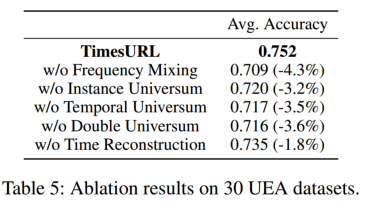
4.2 消融实验
在UEA的30个数据集上比较完整的TimesURL及其五个变体
1)w/o频率混合,
2)w/o实例Universum,
3)w/o时间Universum,
4)w/o double Universum
5)w/o时间重建
5 总结
目前应该只是第一版,实验部分只有六个下游任务和小部分消融实验,没有附录(详细实验结果) 总体框架应该是基于 ts2vec 改进的,既可以做单变量也可以做多变量的数据,不同下游任务不共享预训练网络参数


![[LitCTF 2023]这是什么?SQL !注一下 !](https://img-blog.csdnimg.cn/direct/ca34cbe85b7346d2a00a3f49762010d6.png#pic_center)