1、人工智能概念的一般描述
人工智能是那些与人的思维相关的活动,诸如决策、问题求解和学习等的自动化;
人工智能是一种计算机能够思维,使机器具有智力的激动人心的新尝试;
人工智能是研究如何让计算机做现阶段只有人才能做得好的事情;
人工智能是那些使知觉、推理和行为成为可能的计算的研究;
广义地讲,人工智能是关于人造物的智能行为,而智能行为包括知觉、推理、学习、交流和在复杂环境中的行为。
人工智能定义分为4类:像人一样思考的系统、像人一样行动的系统、理性地思考的系统、理性地行动的系统。
2、人工智能的研究途径与方法
心理模拟,符号推演
从人脑的宏观心理层面入手,以智能行为的心理模型为依据,将问题或知识表示成某种逻辑网络,采用符号推演的方法,模拟人脑的逻辑思维过程,实现人工智能。
生理模拟,神经计算
从人脑的生理层面,即微观结构和工作机理入手,以智能行为的生理模型为依据,采用数值计算的方法,模拟脑神经网络的工作过程,实现人工智能。
行为模拟,控制进化
用模拟人和动物在与环境的交互过程中的智能活动和行为特性,如反应、适应、学习、寻优等,来研究和实现人工智能。
着眼数据,统计建模
着眼于事物或问题的外部表现和关系,搜集、采集相关信息并做成样本数据,然后用统计学、概率论和其他数学理论和方法建模,并用适当的算法进行计算,推测事物的内在模式或规律,来实现人工智能。
3、人工智能的分支领域与研究方向
人工智能可分为搜索与求解、知识与推理、学习与发现等十大分支领域。
❖ 从研究途径和智能层次来看,人工智能可分为符号智能、计算智能、统计智能和交互智能等四大分支领域。
❖ 从所模拟的脑智能或脑功能来看,AI中有机器学习、机器感知、机器联想、机器推理、机器行为等分支领域。
❖ 从系统角度看,AI中有智能计算机系统和智能应用系统两大类。
❖ 从应用角度看,人工智能中有难题求解等数十个分支领域和研究方向。
❖ 从信息处理角度看,人工智能则可分为确定-确切性信息处理、不确定性信息处理和不确切性信息处理三大领域。
❖ 从基础理论看,与人工智能密不可分的还有数学和数据科学。
4、卷积计算与图像边缘检测
卷积神经网络是一类包含卷积计算且具有深度结构的前馈神经网络,是深度学习的代表算法之一。卷积神经网络具有表征学习能力。
计算方式见笔记。
微分推导设计的缘检测算子通过卷积计算可以提取图像的边缘特征,那么我们也可以通过其他的算子(卷积核、模板)提取图像的特征,如纹理特征等,这些算子可以通过学习的方式来得到。
优点:
相对SVM或随机森林,可以防止丢失空间信息等其他信息。
相对全连接神经网络可以减少参数。
通过参数共享,在每一层只需要较少的参数可以学到有效特征。
4、ResNet(残差网络)
ResNet的出现,使得网络的深度可以轻松达到100+层以上。
特点:
核心单元简单堆叠。跳连结构解决网络梯度消失问题。Average Pooling层代替fc层。 BN层加快网络训练速度和收敛时的稳定性。加大网络深度,提高模型的特征抽取能力。
5、DialatedNet、Deformable Convolution
DialatedNet:不牺牲特征图尺寸的情况下增加感受野。获取了多尺度的上下文信息。减少的计算量。
Deformable Convolution:增加了可变形卷积,对物体的形变和尺度建模能力比较强。
6、全卷积神经网络
起源:使深度卷积神经网络可以提取高层语义特征的同时保持特征映射的分辨率与原始图像一致。
◆原理:利用反卷积层对最高层的低分辨率特征映射进行上采样处理,使得该特征映射的尺寸与原始图像的相同,然后用步长为1x1的卷积核对该特征映射进行像素分类,从而得到图像语义分割结果;
◆优势:端对端输出、高效率;
◆劣势:小目标分割效果差、分割结果边界粗糙、过分割和欠分割问题突出;
◆FCN-32s:直接将 pool5的输出,上采样到原图大小,做预测,然而预测的结果非常粗糙;
◆FCN-16s:将pool5上采样 2 倍,和pool 4 特征进行相加,然后上采样到原图大小,结
果会比32s的精细一些;
◆FCN-8s:将 pool5(上采样2倍)和 pool4 相加后的特征,先上采样 2 倍,然后和pool3
相加,得到FCN-8s特征;
7、转置卷积
1,在输入特征图元素间填充s-1行和列0
2,在输入特征图四周填充k-p-1行和列0
3,将卷积核参数上下,左右翻转
4,做正常卷积运算(填充0,步距1)
优点:可学习,理论上模型可以通过学习获取最适合当前数据集的上采样方式。 缺点:存在棋盘效应,分割边界为锯齿状。
8、SegNet
SegNet编码部分通过最大池化逐阶段缩小输入图像的尺寸和降低参数量,并且记录图像中的池化索引位置;SegNet解码部分通过上采样逐阶段恢复图像信息,最后通过Softmax 分类器输出语义分割结果。
使用记录maxpool层最大响应特征位置的tensor来进行上采样,避免了FCN中学习上采样带来的消耗,而后再使用可训练的卷积层使稀疏的feature map密集,这将避免上层保存feature map产生的额外空间消耗。
9、DeepLab V1
优点:DeepLab v1 结合了深度卷积神经网络(DCNNs)与概率图模型
• 采用FCN思想,修改VGG16网络,得到 coarse score map并插值到原图像尺寸;
• 使用Atrous convolution得到更dense且感受野不变的feature map概率图模型;
• 借用fully connected CRF对从DCNNs得到的分割结果进行细节上的refine;
10、LSTM(输入门、输出门、遗忘门、细胞更新)
LSTM的第一步是决定我们要从细胞状态中丢弃什么信息。该决定由被称为“忘记门”的Sigmoid层实现。
下一步是决定要在细胞状态中存储什么信息。分为两步。首先,称为“输入门层”的Sigmoid层决定了将更新哪些值。接下来一个tanh层创建候选向量Ct,该向量将会被加到细胞的状态中。更新上一个状态值Ct−1,将其更新为Ct。最后,我们需要决定我们要输出什么。此输出将基于我们的细胞状态,但将是一个过滤版本。首先,我们运行一个sigmoid层,它决定了我们要输出的细胞状态的哪些部分。然后,我们将单元格状态通过tanh(将值规范化到-1和1之间),并将其乘以Sigmoid门的输出,至此我们只输出了我们决定的那些部分。
11、GRU(门阈控制单元)
是循环神经网络的一种,和LSTM一样,也是为了解决长期记忆和反向传播中的梯度等问题而提出来的。相比LSTM,使用GRU能够达到相当的效果,并且相比之下更容易进行训练,能够很大程度上提高训练效率,因此很多时候会更倾向于使用GRU。
12、注意力原理(Attention值的计算(Q,KV)、优点、)
参数少:相比于 CNN、RNN ,其复杂度更小,参数也更少。所以对算力的要求也就更小。
速度快:Attention 解决了 RNN及其变体模型 不能并行计算的问题。Attention机制每一步
计算不依赖于上一步的计算结果,因此可以和CNN一样并行处理。
效果好:在Attention 机制引入之前,有一个问题大家一直很苦恼:长距离的信息会被弱
化,就好像记忆能力弱的人,记不住过去的事情是一样的。
13、自注意力机制(多头注意力机制、Self-Attention的计算公式和优势)
Attention(Q,K,V)=softmax(QKT/√)V
防止softmax()中的分布会趋于陡峭,使训练过程中梯度值保持稳定。
1.参数少:相比于CNN、RNN,其复杂度更小,参数也更少。所以对算力的要求也就更小。2.速度快:Attention解决了RNN及其变体模型不能并行计算的问题。Attention机制每一步计算不依赖于上一步的计算结果,因此可以和CNN一样并行处理。
3.效果好:在Attention机制引入之前,有一个问题大家一直很苦恼:长距离的信息会被弱化,就好像记忆能力弱的人,记不住过去的事情是一样的。
14、Transformer模型(位置编码)
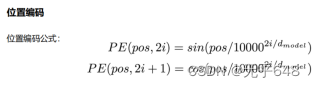
第二个公式应该是2i+1
15、Swin Transformer
使用了类似卷积神经网络中的层次化构建方法,比如部分特征图尺寸中有对图像下采样4倍的,8倍的以及16倍的,这样的backbone有助于在此基础上构建目标检测,实例分割等任务。而在之前的VisionTransformer中是一开始就直接下采样16倍,后面的特征图也是维持这个下采样率不变。在SwinTransformer中使用了WindowsMulti-HeadSelf-Attention(W-MSA)的概念,比如在下图的4倍下采样和8倍下采样中,将特征图划分成了多个不相交的区域,并且Multi-HeadSelf-Attention只在每个窗口内进行。相对于VisionTransformer中直接对整个特征图进行MultiHeadSelf-Attention,这样做的目的是能够减少计算量的,尤其是在浅层特征图很大的时候。这样做虽然减少了计算量但也会隔绝不同窗口之间的信息传递。
16、GAN
在训练过程中,生成网络的目标就是尽量生成真实的图片去欺骗判别网络D。而网络D的目标就是尽量把网络G生成的图片和真实的图片分别开来。这样,G和D构成了一个动态的“博弈过程”。
训练过程
1、随机初始化生成器和判别器
2、固定住生成器参数, 更新判别器的参数
3、固定判别器的参数, 更新生成器的参数
4、重复2、3直到收敛
缺点:生成的图像是随机的,不可预测的,无法控制网络输出特定的图片,生成目标不明确,可控性不强。
2023高级人工智能期末总结
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如若转载,请注明出处:http://www.rhkb.cn/news/231400.html
如若内容造成侵权/违法违规/事实不符,请联系长河编程网进行投诉反馈email:809451989@qq.com,一经查实,立即删除!相关文章
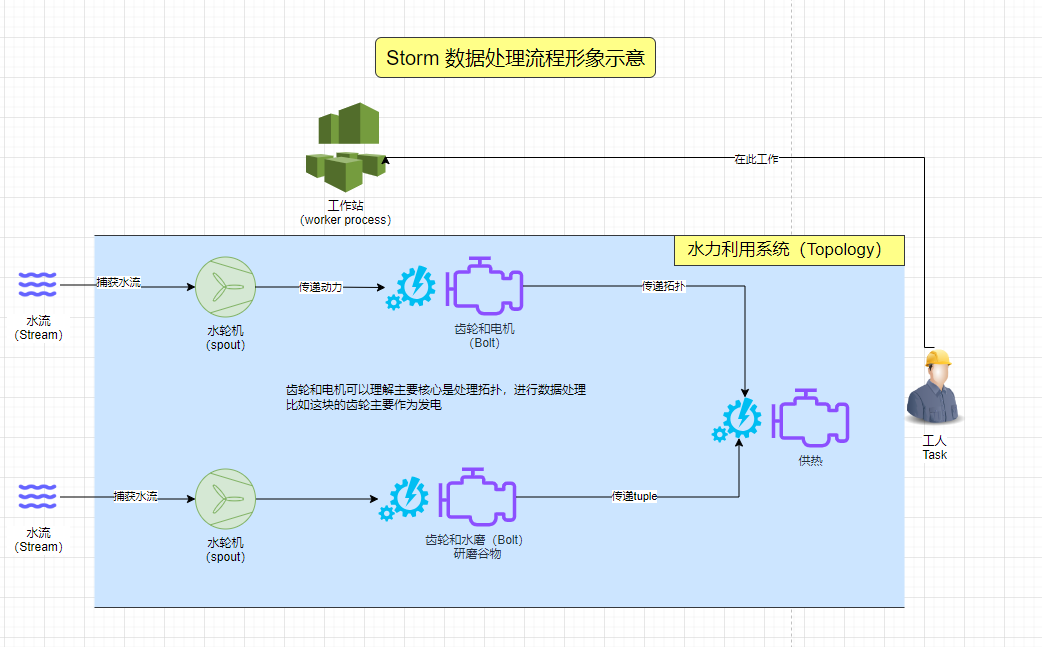
【Storm实战】1.1 图解Storm的抽象概念
文章目录 0. 前言1. Storm 中的抽象概念1.1 流 (Stream)1.2 拓扑 (Topology)1.3 Spout1.4 Bolt1.5 任务 (Task)1.6 工作者 (Worker) 2. 形象的理解Storm的抽象概念2.1 流 (Stream)2.2 拓扑 (Topology)2.3 Spout2.4 Bolt2.5 任务 (Task)2.6 工作者 (Worker)场景1场景2 3.参考文档…
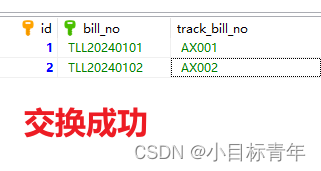
Mysql 将表里的两列值数据互换
示例:
需要将表中的 两个订单号互换 方案:
将同一张表数据做 临时数据 和主表 做数据交互 。 update 表 as main, 表 as temp set main.bill_no temp.track_bill_no, main.track_bill_no temp.bill_no where main.id temp.id…

实时记录和查看Apache 日志
Apache 是一个开源的、广泛使用的、跨平台的 Web 服务器,保护 Apache Web 服务器平台在很大程度上取决于监控其上发生的活动和事件,监视 Apache Web 服务器的最佳方法之一是收集和分析其访问日志文件。
Apache 访问日志提供了有关用户如何与您的网站交互…
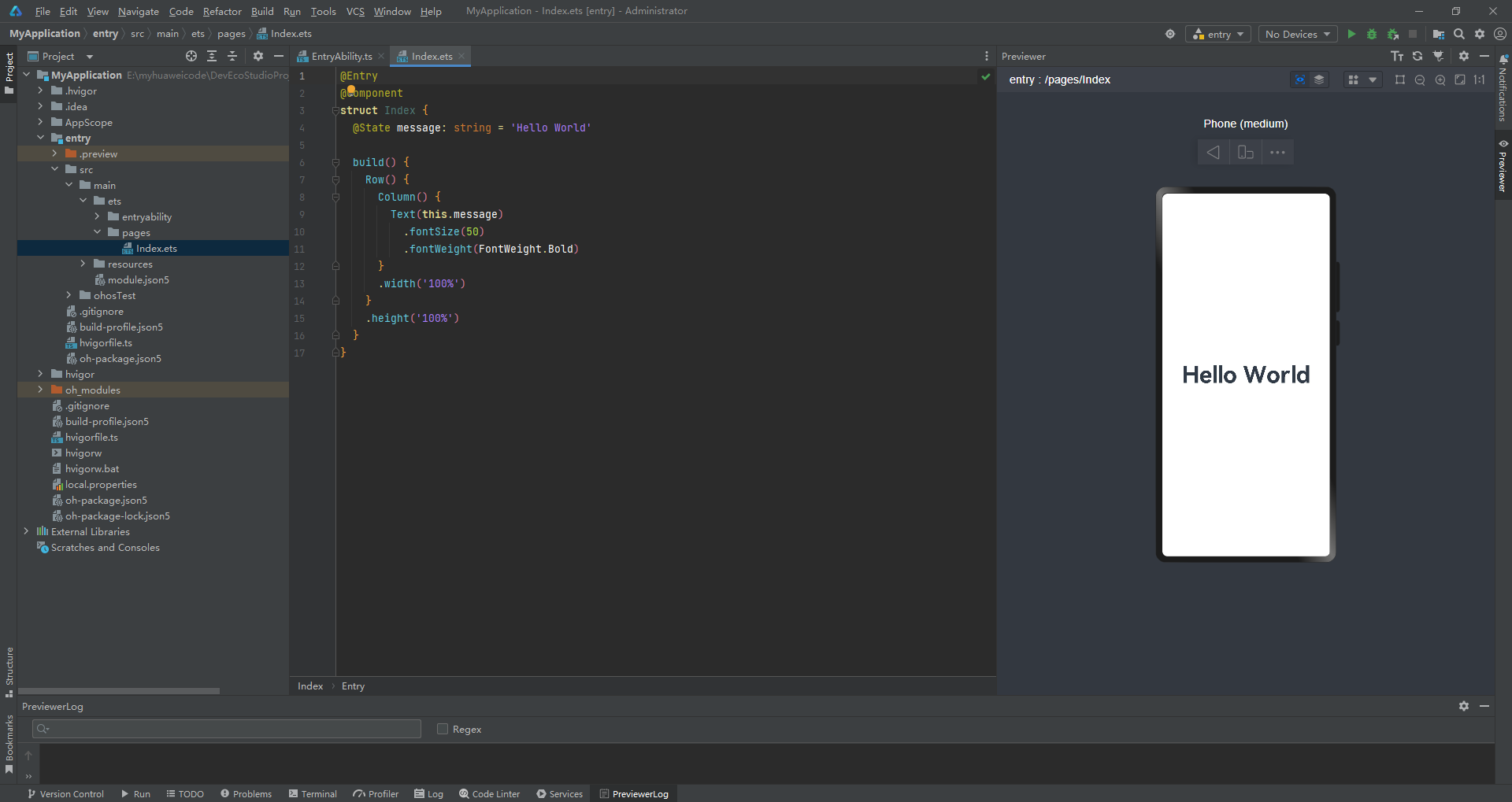
HarmonyOS应用开发之DevEco Studio安装与初次使用
1、DevEco Studio介绍
DevEco Studio是基于IntelliJ IDEA Community开源版本打造,面向华为终端全场景多设备的一站式集成开发环境(IDE),为开发者提供工程模板创建、开发、编译、调试、发布等E2E的HarmonyOS应用/服务的开发工具。…
如何通过HACS+Cpolar实现远程控制米家和HomeKit等智能家居设备
文章目录 基本条件一、下载HACS源码二、添加HACS集成三、绑定米家设备 上文介绍了如何实现群晖Docker部署HomeAssistant,通过内网穿透在户外控制家庭中枢。本文将介绍如何安装HACS插件商店,将米家,果家设备接入 Home Assistant。
基本条件…
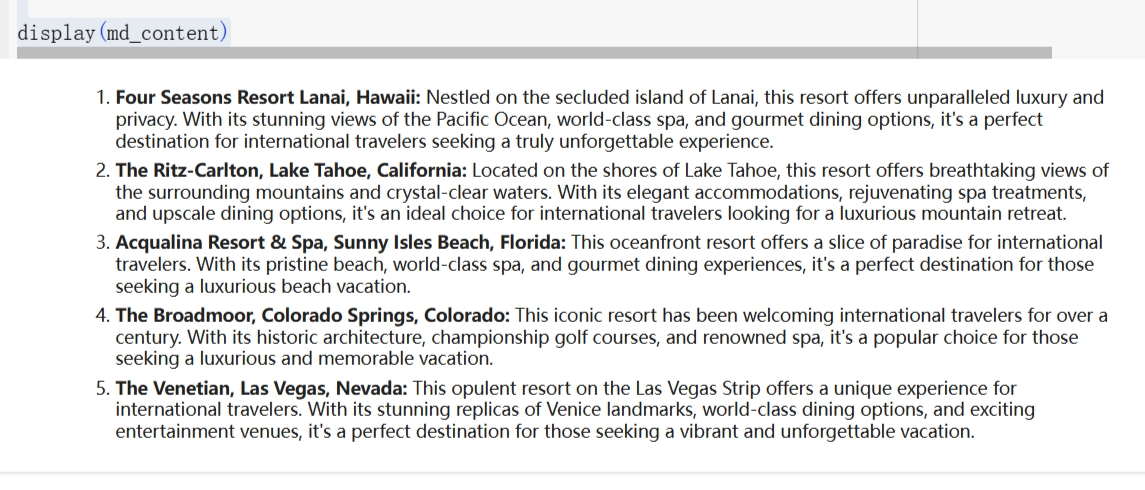
在Google Colab中调用Gemini的API实现智能问答
一、引言
Google终于放出大招,在2023年12月6日正式推出规模最大、功能最强大的人工智能模型Gemini,对标ChatGPT,甚至有要赶超ChatGPT-4.0的节奏。
相比之前的Bard,Gemini的文本理解能力、图片识别能力和语义抽取能力大大增强&am…

Spring见解3 AOP
4.Spring AOP
4.1.为什么要学习AOP? 案例:有一个接口Service有一个insert方法,在insert被调用时打印调用前的毫秒数与调用后的毫秒数,其实现为: public class UserServiceImpl implements UserService {private UserDao userDao…

新年福利|这款价值数万的报表工具永久免费了
随着数据资产的价值逐渐凸显,越来越多的企业会希望采用报表工具来处理数据分析,了解业务经营状况,从而辅助经营决策。不过,企业在选型报表工具的时候经常会遇到以下几个问题: 各个报表工具有很多功能和特性,…
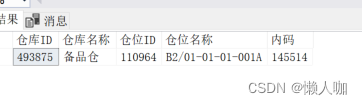
金蝶云星空数据库根据仓库和仓位查询内码(SQL脚本)
SELECT a.仓库ID,a.仓库名称,d.仓位ID,d.仓位名称,c.内码FROM ( SELECT a.FSTOCKID 仓库ID,b.FNAME 仓库名称FROM T_BD_STOCK aINNER JOIN T_BD_STOCK_L bON a.FSTOCKID b.FSTOCKID --仓库列表) aLEFT JOIN ( SELECT FENTRYID 仓位值表FENTRYID,FSTOC…

软件测试基础理论学习-软件测试方法论
软件测试方法论
软件测试的方法应该建立在不同的软件测试类型上,不同的测试类型会存在不同的方法。本文以软件测试中常见的黑盒测试为例,简述常见软件测试方法。
黑盒测试用例设计方法包括等价类划分法、边界值分析法、因果图法、判定表驱动法、正交试…

c语言题目之统计二级制数中1的个数
文章目录 题目一、方法1二、方法2三,方法3总结 题目 统计二进制数中1的个数 输入一行,输出一行 输入: 输入一个整数 输出: 输出存储在内存中二进制的1的个数 一、方法1 之前的文章中,小编写了有关于内存在二进制中的存…
cissp 第10章 : 物理安全要求
10.1 站点与设施设计的安全原则 物理控制是安全防护的第一条防线,而人员是最后一道防线。
10.1.1 安全设施计划
安全设施计划通过关键路径分析完成。
关键路径分析用于找出关键应用、流程、运营以及所有必要支撑元索间的关系。
技术融合指的是各种技术、解决方案…

MongoDB 面试题
MongoDB 面试题
1. 什么是MongoDB?
MongoDB是一种非关系型数据库,被广泛用于大型数据存储和分布式系统的构建。MongoDB支持的数据模型比传统的关系型数据库更加灵活,支持动态查询和索引,也支持BSON格式的数据存储,这…

ARCGIS PRO SDK Geoprocessing
调用原型:Dim gpResult AS IGPResult await Geoprocessing.ExecuteToolAsync(调用工具名称, GPValue数组, environment, null, null, executeFlags)
一、调用工具名称:地理处理工具名称。如面转线:management.PolygonToLine,而非…
![解析为什么Go语言要使用[]rune而不是string来表示中文字符](https://img-blog.csdnimg.cn/direct/5ba1dc7462a34efcb87c304c41e3fe28.png)
解析为什么Go语言要使用[]rune而不是string来表示中文字符
众所周知,Go语言中有以下这些数据类型。但rune32这个go语言特有的数据类型,比较有意思却经常遭到忽视。所以今天探索学习一下这个数据类型的功能、用法。
Go基本数据类型
布尔:bool
字符串:string
整数: int int8 …
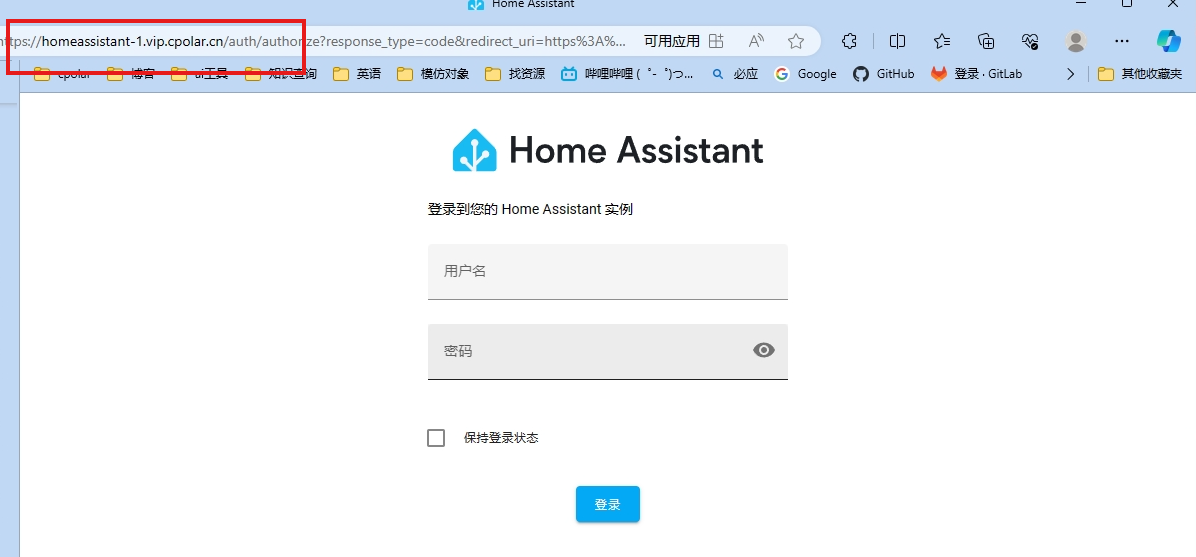
群晖Docker部署HomeAssistant容器结合内网穿透远程控制家中智能设备
目录
一、下载HomeAssistant镜像
二、内网穿透HomeAssistant,实现异地控制智能家居
三、使用固定域名访问HomeAssistant 前些天发现了一个巨牛的人工智能学习网站,通俗易懂,风趣幽默,忍不住分享一下给大家。 点击跳转到网站 Ho…
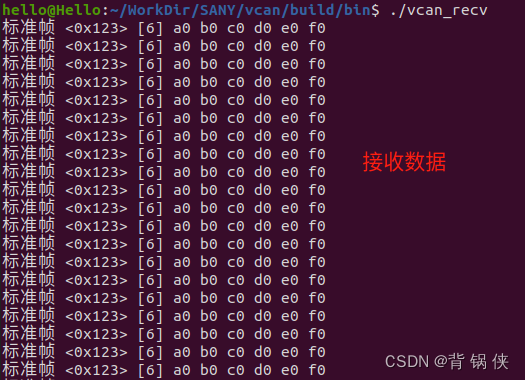
Ubuntu20.04 上启用 VCAN 用作本地调试
目录
一、启用本机的 VCAN 编辑
1.1 加载本机的 vcan
1.2 添加本机的 vcan0
1.3 查看添加的 vcan0
1.4 开启本机的 vcan0
1.5 关闭本机的 vcan0
1.6 删除本机的 vcan0
二、测试本机的 VCAN
2.1 CAN 发送数据 代码
2.2 CAN 接收数据 代码
2.3 CMakeLists.…
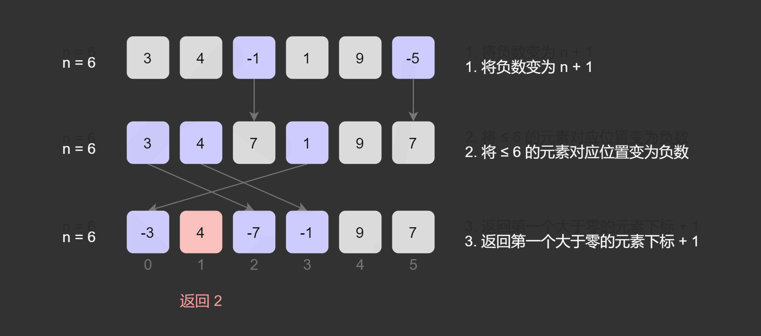
缺失的第一个正数(LeetCode 41)
文章目录 1.问题描述2.难度等级3.热门指数4.解题思路4.1 暴力4.2 排序4.3 哈希表4.4 空间复杂度为 O(1) 的哈希表4.5 置换 参考文献 1.问题描述
给你一个未排序的整数数组 nums ,请你找出其中没有出现的最小的正整数。
请你实现时间复杂度为 O(n) 并且只使用常数级…
推荐文章
- 微软认证最新考题70-029 SQL7.0实现
- 音乐歌词同步实现指南
- # ABAP SQL 字符串处理
- # Kafka_深入探秘者(5):kafka 分区
- # 从浅入深 学习 SpringCloud 微服务架构(六)Feign(3)
- # 渗透测试# 安全见闻(4)操作系统与驱动程序
- (10)svelte 教程:Slots
- (2024,Vision-LSTM,ViL,xLSTM,ViT,ViM,双向扫描)xLSTM 作为通用视觉骨干
- (22)Task.Delay与Thread.Sleep,Wait与When,复习
- (5h)Unity3D快速入门之Roll-A-Ball游戏开发
- (C#面向初学者的 .NET 的生成 AI) 第 2 部分-什么是 AI 和 ML?
- (Spring学习06)Spring之循环依赖底层源码解析