前言
YOLO-V8(官网地址):https://github.com/ultralytics/ultralytics
一、yolov8配置yaml文件
YOLOv8的配置文件定义了模型的关键参数和结构,包括类别数、模型尺寸、骨架(backbone)和头部(head)结构。这些配置决定了模型的性能和复杂性。
下面是yolov8模型的配置文件,以及每个参数的详细说明
# Ultralytics YOLO 🚀, AGPL-3.0 license
# YOLOv8 object detection model with P3-P5 outputs. For Usage examples see https://docs.ultralytics.com/tasks/detect# Parameters
nc: 80 # 类别数目,nc代表"number of classes",即模型用于检测的对象类别总数。
scales: # 模型复合缩放常数,例如 'model=yolov8n.yaml' 将调用带有 'n' 缩放的 yolov8.yaml# [depth, width, max_channels]n: [0.33, 0.25, 1024] # YOLOv8n概览:225层, 3157200参数, 3157184梯度, 8.9 GFLOPss: [0.33, 0.50, 1024] # YOLOv8s概览:225层, 11166560参数, 11166544梯度, 28.8 GFLOPsm: [0.67, 0.75, 768] # YOLOv8m概览:295层, 25902640参数, 25902624梯度, 79.3 GFLOPsl: [1.00, 1.00, 512] # YOLOv8l概览:365层, 43691520参数, 43691504梯度, 165.7 GFLOPsx: [1.00, 1.25, 512] # YOLOv8x概览:365层, 68229648参数, 68229632梯度, 258.5 GFLOPs# YOLOv8.0n backbone 骨干层
backbone:# [from, repeats, module, args]- [-1, 1, Conv, [64, 3, 2]] # 0-P1/2 第0层,-1代表将上层的输入作为本层的输入。第0层的输入是640*640*3的图像。Conv代表卷积层,相应的参数:64代表输出通道数,3代表卷积核大小k,2代表stride步长。- [-1, 1, Conv, [128, 3, 2]] # 1-P2/4 第1层,本层和上一层是一样的操作(128代表输出通道数,3代表卷积核大小k,2代表stride步长)- [-1, 3, C2f, [128, True]] # 第2层,本层是C2f模块,3代表本层重复3次。128代表输出通道数,True表示Bottleneck有shortcut。- [-1, 1, Conv, [256, 3, 2]] # 3-P3/8 第3层,进行卷积操作(256代表输出通道数,3代表卷积核大小k,2代表stride步长),输出特征图尺寸为80*80*256(卷积的参数都没变,所以都是长宽变成原来的1/2,和之前一样),特征图的长宽已经变成输入图像的1/8。- [-1, 6, C2f, [256, True]] # 第4层,本层是C2f模块,可以参考第2层的讲解。6代表本层重复6次。256代表输出通道数,True表示Bottleneck有shortcut。经过这层之后,特征图尺寸依旧是80*80*256。- [-1, 1, Conv, [512, 3, 2]] # 5-P4/16 第5层,进行卷积操作(512代表输出通道数,3代表卷积核大小k,2代表stride步长),输出特征图尺寸为40*40*512(卷积的参数都没变,所以都是长宽变成原来的1/2,和之前一样),特征图的长宽已经变成输入图像的1/16。- [-1, 6, C2f, [512, True]] # 第6层,本层是C2f模块,可以参考第2层的讲解。6代表本层重复6次。512代表输出通道数,True表示Bottleneck有shortcut。经过这层之后,特征图尺寸依旧是40*40*512。- [-1, 1, Conv, [1024, 3, 2]] # 7-P5/32 第7层,进行卷积操作(1024代表输出通道数,3代表卷积核大小k,2代表stride步长),输出特征图尺寸为20*20*1024(卷积的参数都没变,所以都是长宽变成原来的1/2,和之前一样),特征图的长宽已经变成输入图像的1/32。- [-1, 3, C2f, [1024, True]] #第8层,本层是C2f模块,可以参考第2层的讲解。3代表本层重复3次。1024代表输出通道数,True表示Bottleneck有shortcut。经过这层之后,特征图尺寸依旧是20*20*1024。- [-1, 1, SPPF, [1024, 5]] # 9 第9层,本层是快速空间金字塔池化层(SPPF)。1024代表输出通道数,5代表池化核大小k。结合模块结构图和代码可以看出,最后concat得到的特征图尺寸是20*20*(512*4),经过一次Conv得到20*20*1024。# YOLOv8.0n head 头部层
head:- [-1, 1, nn.Upsample, [None, 2, 'nearest']] # 第10层,本层是上采样层。-1代表将上层的输出作为本层的输入。None代表上采样的size(输出尺寸)不指定。2代表scale_factor=2,表示输出的尺寸是输入尺寸的2倍。nearest代表使用的上采样算法为最近邻插值算法。经过这层之后,特征图的长和宽变成原来的两倍,通道数不变,所以最终尺寸为40*40*1024。- [[-1, 6], 1, Concat, [1]] # cat backbone P4 第11层,本层是concat层,[-1, 6]代表将上层和第6层的输出作为本层的输入。[1]代表concat拼接的维度是1。从上面的分析可知,上层的输出尺寸是40*40*1024,第6层的输出是40*40*512,最终本层的输出尺寸为40*40*1536。- [-1, 3, C2f, [512]] # 12 第12层,本层是C2f模块,可以参考第2层的讲解。3代表本层重复3次。512代表输出通道数。与Backbone中C2f不同的是,此处的C2f的bottleneck模块的shortcut=False。- [-1, 1, nn.Upsample, [None, 2, 'nearest']] # 第13层,本层也是上采样层(参考第10层)。经过这层之后,特征图的长和宽变成原来的两倍,通道数不变,所以最终尺寸为80*80*512。- [[-1, 4], 1, Concat, [1]] # cat backbone P3 第14层,本层是concat层,[-1, 4]代表将上层和第4层的输出作为本层的输入。[1]代表concat拼接的维度是1。从上面的分析可知,上层的输出尺寸是80*80*512,第6层的输出是80*80*256,最终本层的输出尺寸为80*80*768。- [-1, 3, C2f, [256]] # 15 (P3/8-small) 第15层,本层是C2f模块,可以参考第2层的讲解。3代表本层重复3次。256代表输出通道数。经过这层之后,特征图尺寸变为80*80*256,特征图的长宽已经变成输入图像的1/8。- [-1, 1, Conv, [256, 3, 2]] # 第16层,进行卷积操作(256代表输出通道数,3代表卷积核大小k,2代表stride步长),输出特征图尺寸为40*40*256(卷积的参数都没变,所以都是长宽变成原来的1/2,和之前一样)。- [[-1, 12], 1, Concat, [1]] # cat head P4 第17层,本层是concat层,[-1, 12]代表将上层和第12层的输出作为本层的输入。[1]代表concat拼接的维度是1。从上面的分析可知,上层的输出尺寸是40*40*256,第12层的输出是40*40*512,最终本层的输出尺寸为40*40*768。- [-1, 3, C2f, [512]] # 18 (P4/16-medium) 第18层,本层是C2f模块,可以参考第2层的讲解。3代表本层重复3次。512代表输出通道数。经过这层之后,特征图尺寸变为40*40*512,特征图的长宽已经变成输入图像的1/16。- [-1, 1, Conv, [512, 3, 2]] # 第19层,进行卷积操作(512代表输出通道数,3代表卷积核大小k,2代表stride步长),输出特征图尺寸为20*20*512(卷积的参数都没变,所以都是长宽变成原来的1/2,和之前一样)。- [[-1, 9], 1, Concat, [1]] # cat head P5 第20层,本层是concat层,[-1, 9]代表将上层和第9层的输出作为本层的输入。[1]代表concat拼接的维度是1。从上面的分析可知,上层的输出尺寸是20*20*512,第9层的输出是20*20*1024,最终本层的输出尺寸为20*20*1536。- [-1, 3, C2f, [1024]] # 21 (P5/32-large) 第21层,本层是C2f模块,可以参考第2层的讲解。3代表本层重复3次。1024代表输出通道数。经过这层之后,特征图尺寸变为20*20*1024,特征图的长宽已经变成输入图像的1/32。- [[15, 18, 21], 1, Detect, [nc]] # Detect(P3, P4, P5) 第20层,本层是Detect层,[15, 18, 21]代表将第15、18、21层的输出(分别是80*80*256、40*40*512、20*20*1024)作为本层的输入。nc是数据集的类别数。
在yolov8.yaml配置文件中,整个yaml文件主要分为4个参数,每个关键词都扮演着特定的角色,下面是对这些关键词及其含义的详细解释:
1. nc
- 含义: nc代表"number of classes",即模型用于检测的对象类别总数。
- 示例中的值: 80,表示该模型配置用于检测80种不同的对象。由于默认使用COCO数据集,这里
nc=80;
2. scales
- 含义: scales用于定义模型的不同尺寸和复杂度,它包含一系列缩放参数。
- 子参数: n, s, m, l, x表示不同的模型尺寸,每个尺寸都有对应的depth(深度)、width(宽度)和max_channels(最大通道数)。
- depth: 表示深度因子,用来控制一些特定模块的数量的,模块数量多网络深度就深;
- width: 表示宽度因子,用来控制整个网络结构的通道数量,通道数量越多,网络就看上去更胖更宽;
- max_channels: 最大通道数,为了动态地调整网络的复杂性。在 YOLO 的早期版本中,网络中的每个层都是固定的,这意味着每个层的通道数也是固定的。但在 YOLOv8 中,为了增加网络的灵活性并使其能够更好地适应不同的任务和数据集,引入了 max_channels 参数。
3. backbone
主干网络是模型的基础,负责从输入图像中提取特征。这些特征是后续网络层进行目标检测的基础。在YOLOv8中,主干网络采用了类似于CSPDarknet的结构。
- 含义: backbone部分定义了模型的基础架构,即用于特征提取的网络结构。
- 关键组成:
- [from, repeats, module, args]表示层的来源、重复次数、模块类型和参数。
from:表示该模块的输入来源,如果为-1则表示来自于上一个模块中,如果为其他具体的值则表示从特定的模块中得到输入信息;repeats:这个参数用于指定一个模块或层应该重复的次数。例如,如果你想让某个卷积层重复三次,你可以使用 repeats=3。module:这个参数用于指定要添加的模块或层的类型。例如,如果你想添加一个卷积层,你可以使用 conv 作为模块类型。args:这个参数用于传递给模块或层的特定参数。例如,如果你想指定卷积层的滤波器数量,你可以使用 args=[filters]。
Conv表示卷积层,其参数指定了输出通道数、卷积核大小和步长。C2f可能是一个特定于YOLOv8的自定义模块。SPPF是空间金字塔池化层,用于在多个尺度上聚合特征。
- [from, repeats, module, args]表示层的来源、重复次数、模块类型和参数。
4. head
- 含义: head部分定义了模型的检测头,即用于最终目标检测的网络结构。
- 关键组成:
- nn.Upsample表示上采样层,用于放大特征图。
- Concat表示连接层,用于合并来自不同层的特征。
- C2f层再次出现,可能用于进一步处理合并后的特征。
- Detect层是最终的检测层,负责输出检测结果。
二、模型结构图
这张图是 YOLOv8(You Only Look Once version 8)目标检测模型的结构图。它展示了模型的三个主要部分:Backbone(主干网络)、Neck(颈部网络)和 Head(头部网络),以及它们的子模块和连接方式。

模型结构解释
Backbone(主干网络)
主干网络是模型的基础,负责从输入图像中提取特征。这些特征是后续网络层进行目标检测的基础。在YOLOv8中,主干网络采用了类似于CSPDarknet的结构,
Head(头部网络)
头部网络是目标检测模型的决策部分,负责产生最终的检测结果。
Neck(颈部网络)
颈部网络位于主干网络和头部网络之间,它的作用是进行特征融合和增强。
其他细节
- ConvModule:包含卷积层、BN(批量归一化)和激活函数(如SiLU),用于提取特征。
- DarknetBottleneck:通过residual connections增加网络深度,同时保持效率。
- CSP Layer:CSP结构的变体,通过部分连接来提高模型的训练效率。
- Concat:特征图拼接,用于合并不同层的特征。
- Upsample:上采样操作,增加特征图的空间分辨率。
IoU (交并比)
IoU是评估目标检测模型性能中一个非常重要的指标。它衡量的是预测边界框和真实边界框之间的重叠程度。IoU的计算方式如下:
I o U = A r e a o f O v e r l a p A r e a o f U n i o n IoU=\frac{Area\ of\ Overlap}{Area\ of\ Union} IoU=Area of UnionArea of Overlap
其中,Area of Overlap是预测边界框和真实边界框重叠的区域面积,Area of Union是两个边界框覆盖的总面积。
- 优点:IoU提供了一个明确的指标来衡量位置预测的准确性。
- 作用:它被广泛用于训练阶段来优化模型(作为损失函数的一部分),以及评估阶段来比较不同模型或同一模型在不同参数下的性能。
Bbox Loss
Bbox Loss用于计算预测边界框和真实边界框之间的差异。均方误差(MSE)是一个常用的损失函数,其计算公式如下:
L o s s b b o x = ∑ i = 1 N ( x i − x ^ i ) 2 Loss_{bbox}=\sum_{i=1}^{N}(x_{i}-\hat{x}_{i})^{2} Lossbbox=i=1∑N(xi−x^i)2
其中,x_{i} 是真实边界框的坐标,而 \hat{x}_{i} 是预测边界框的坐标。该损失计算预测与实际坐标之间的差异的平方和。
- 优点:MSE是一个很好的损失函数,因为它在较大误差时赋予更高的惩罚,这有助于模型快速修正大的预测错误。
- 作用:作为优化目标,引导模型在训练过程中减少预测框和真实框之间的差距。
Cls Loss(分类损失)
Cls Loss用于衡量模型预测的类别分布与真实标签之间的差异。交叉熵损失函数是分类任务中常用的一种损失函数,其公式为:
L o s s c l s = − ∑ c = 1 M y o , c l o g ( p o , c ) Loss_{cls}=-\sum_{c=1}^{M}y_{o,c}log(p_{o},c) Losscls=−c=1∑Myo,clog(po,c)
这里,y_{o,c} 是一个指示器,如果样本o属于类别c,则为1,反之为0。而p_{o,c}是模型预测样本o属于类别c的概率。
- 优点:交叉熵损失对于错误预测给出了很大的惩罚,尤其是在预测的概率和实际标签相差很大时。
- 作用:帮助模型在多分类问题中优化其预测,使预测概率分布尽可能接近真实的标签分布。
每一个损失函数都专注于模型的一个特定方面,确保模型能够从多个维度进行学习和优化。在训练时,这些损失通常被组合起来形成一个综合的优化目标,以便模型能够同时提高其在定位和分类任务上的性能。
模型结构图
来自RangeKing(github)的这个模型结构图相信很多人看过,但是他是怎么画出来的呢, 我用一个简化的图来演示
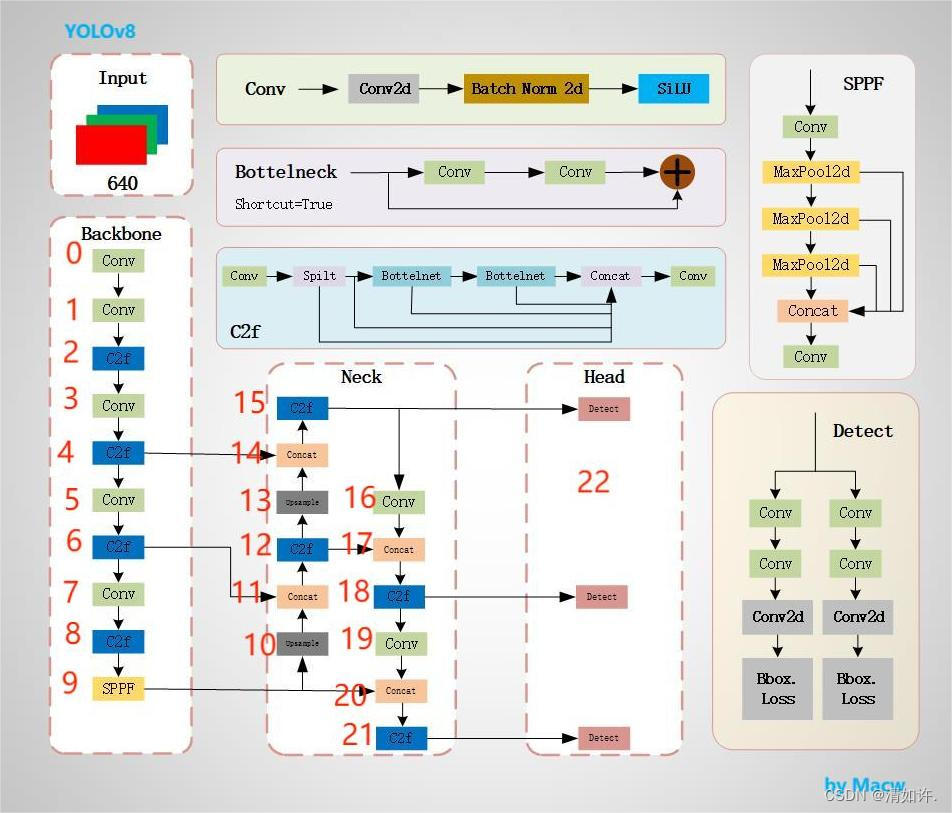
在这张图上我标注了1-22个layer层,对应下面这张结构输出图的最左侧一列
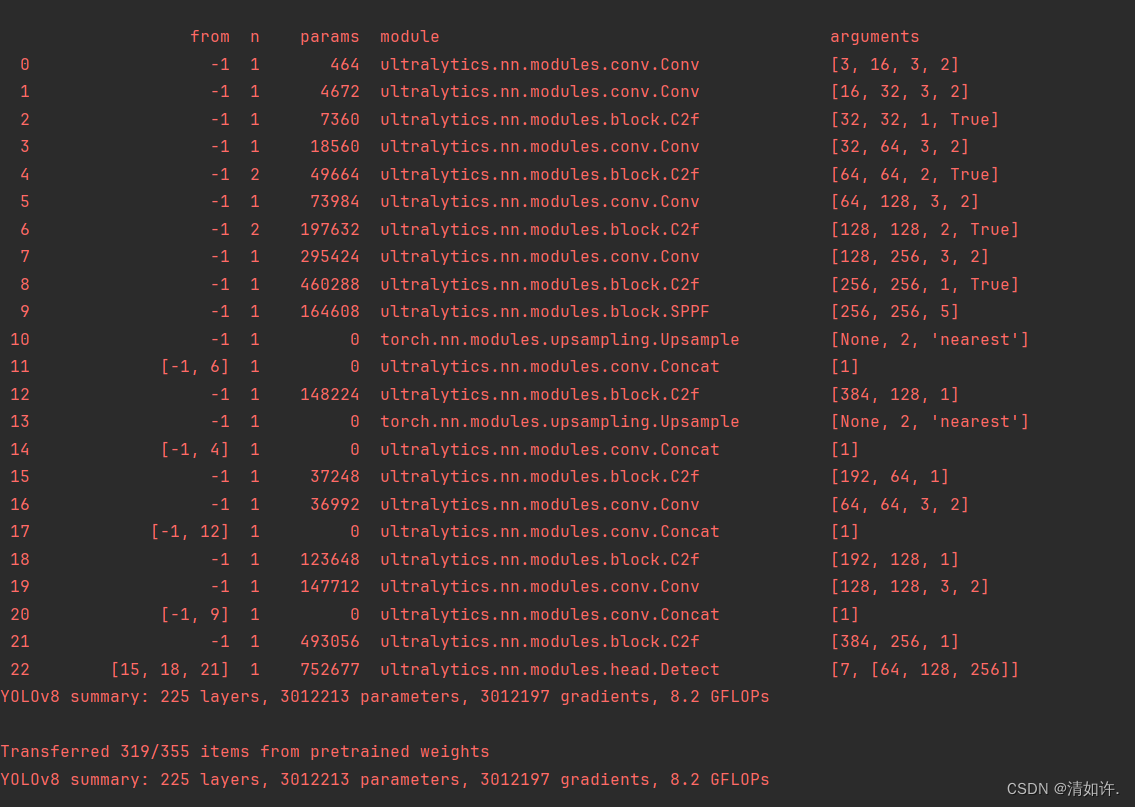
三、逐层分析
从输出的模型结构信息,结合画的结构图,yaml配置文件,逐层分析如下:
Backbone部分:
# YOLOv8.0n backbone
backbone:# [from, repeats, module, args]- [-1, 1, Conv, [64, 3, 2]] # 0-P1/2- [-1, 1, Conv, [128, 3, 2]] # 1-P2/4- [-1, 3, C2f, [128, True]]- [-1, 1, Conv, [256, 3, 2]] # 3-P3/8- [-1, 6, C2f, [256, True]]- [-1, 1, Conv, [512, 3, 2]] # 5-P4/16- [-1, 6, C2f, [512, True]]- [-1, 1, Conv, [1024, 3, 2]] # 7-P5/32- [-1, 3, C2f, [1024, True]]- [-1, 1, SPPF, [1024, 5]] # 9
# [from, repeats, module, args]
- from: 本层的来源,也就是输入。-1表示将上层的输出作为本层的输入。第11层【-1,6】表示将第6层的输出作为本层的输入。如上图的6(c2f)→11(concat),其他层也类似。
- repeats:本层的重复次数。
- module:本层的名称。
- args:本层的参数。
第0层: - [-1, 1, Conv, [64, 3, 2]] # 0-P1/2
-1代表将上层的输入作为本层的输入。第0层的输入是640*640*3的图像。
Conv代表卷积层,相应的参数:64代表输出通道数,3代表卷积核大小k,2代表stride步长。
这里给出Conv的代码供参考
def autopad(k, p=None, d=1): # kernel, padding, dilation# Pad to 'same' shape outputsif d > 1:k = d * (k - 1) + 1 if isinstance(k, int) else [d * (x - 1) + 1 for x in k] # actual kernel-sizeif p is None:p = k // 2 if isinstance(k, int) else [x // 2 for x in k] # auto-padreturn pclass Conv(nn.Module):# Standard convolution with args(ch_in, ch_out, kernel, stride, padding, groups, dilation, activation)default_act = nn.SiLU() # default activationdef __init__(self, c1, c2, k=1, s=1, p=None, g=1, d=1, act=True):super().__init__()self.conv = nn.Conv2d(c1, c2, k, s, autopad(k, p, d), groups=g, dilation=d, bias=False)self.bn = nn.BatchNorm2d(c2)self.act = self.default_act if act is True else act if isinstance(act, nn.Module) else nn.Identity()def forward(self, x):return self.act(self.bn(self.conv(x)))def forward_fuse(self, x):return self.act(self.conv(x))
可以从代码中看出,当k=3时,p=1
所以第0层的卷积f_in=640, c_out=64, k=3, s=2, p=1
输出的特征图大小计算公式:f_out = ((f_in - k + 2*p ) / s ) 向下取整 +1
计算出卷积后的特征图大小:640-3+2=639,639/2向下取整=319,319+1=320
所以经过此层,输出的特征图尺寸为320*320*64,长宽为初始图片的1/2。
第1层: - [-1, 1, Conv, [128, 3, 2]] # 1-P2/4
本层和上一层是一样的操作(128代表输出通道数,3代表卷积核大小k,2代表stride步长),卷积后的特征图尺寸为160*160*128(320-3+2=319,319/2向下取整=159,159+1=160),长宽为初始图片的1/4。
第2层: - [-1, 3, C2f, [128, True]]
本层是C2f模块,3代表本层重复3次。128代表输出通道数,True表示Bottleneck有shortcut。
经过这层之后,特征图尺寸依旧是160*160*128。
结合RangeKing绘制的YOLOv8网络结构图理解:
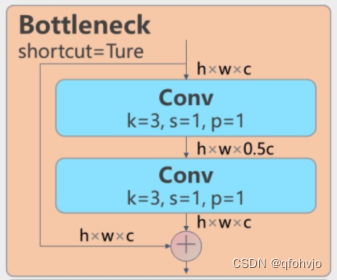
先介绍一下YOLOv5使用的C3模块(往下滑有结构图),以下是C3模块的代码:
class C3(nn.Module):# CSP Bottleneck with 3 convolutionsdef __init__(self, c1, c2, n=1, shortcut=True, g=1, e=0.5): # ch_in, ch_out, number, shortcut, groups, expansionsuper().__init__()c_ = int(c2 * e) # hidden channelsself.cv1 = Conv(c1, c_, 1, 1)self.cv2 = Conv(c1, c_, 1, 1)self.cv3 = Conv(2 * c_, c2, 1) # optional act=FReLU(c2)self.m = nn.Sequential(*(Bottleneck(c_, c_, shortcut, g, k=((1, 1), (3, 3)), e=1.0) for _ in range(n)))def forward(self, x):return self.cv3(torch.cat((self.m(self.cv1(x)), self.cv2(x)), 1))
假设C3的输入是h*w*cin,输出通道数是cout,则c1=cin,c2=cout,c_=0.5*cout。
1*1卷积不改变特征图大小
cv1是Conv(cin, 0.5*cout, 1, 1) (k=1,s=1)下图最左边的CBS模块 //输出为h*w*0.5cout
cv2是Conv(cin, 0.5*cout, 1, 1)(k=1,s=1)下图中间的CBS模块 //输出为h*w*0.5cout
cv3是Conv(cout, cout, 1) (k=1)下图最右边的CBS模块 // 输出为 h*w*cout
n是bottleneck的个数 ,m是接上了n个Bottleneck模块
整个过程就是cv1接上了n个bottleneck模块再与cv2进行concat操作,最后在进行一次cv3的Conv。
所以经过了C3模块,输出特征图尺寸是h*w*cout。

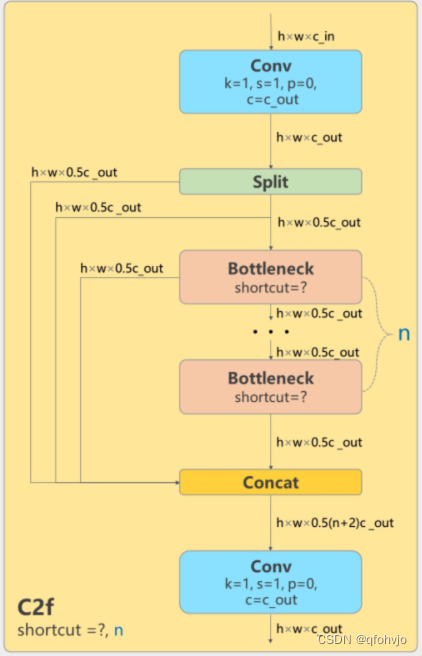
对比C3模块和C2f模块,可以看到C2f获得了更多的梯度流信息(参考了YOLOv7的ELAN模块的思想) 。
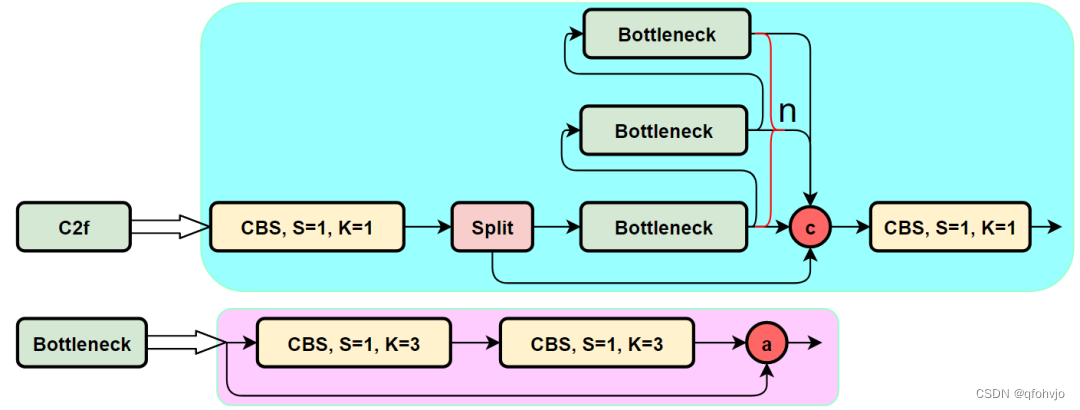
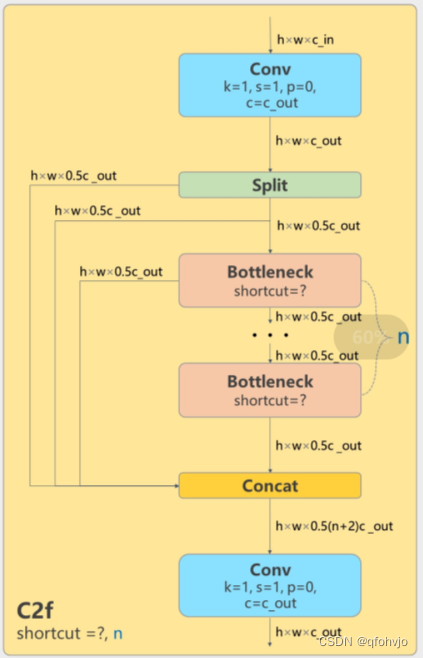
假设输入C2f模块的特征图尺寸是h*w*cin,输出通道数是cout,则c1=cin,c2=cout,c=0.5*cout。
cv1是Conv(cin, cout, 1, 1) (k=1,s=1)上图C2f模块中最左边的CBS模块 //输出为h*w*cout
cv2是Conv((2+n)*0.5*cout, cout, 1) (k=1,s=1)上图C2f模块中最右边的CBS模块 //输出为h*w*cout
n是bottleneck的个数 ,m是接上了n个Bottleneck模块。
Bottlenectk输入和输出通道数都是c=0.5*cout。
在forward方法里,先将输入的特征图x进行cv1的Conv(cin, cout, 1, 1) (k=1,s=1)操作,然后使用chunk将其分成2块。
所以y得到的是被分成2块的特征图的list。
torch.chunk:将tensor分成很多个块,在不同维度上切分。
torch.chunk(tensor,chunk数,维度)
y[-1]表示被切分的最后一块,也就是第二块。
m(y[-1]) for m in self.m就是把第二块放进n个连续的Bottleneck里。
y.extend(经过n个连续的Bottleneck的第二块),就是把y列表扩充了,把"经过n个连续的Bottleneck的第二块"加到列表尾部,y变成2+n块。
torch.cat(y, 1) 将y按第一维度拼接在一起。
最后对拼接好的特征图进行cv2的Conv((2+n)*0.5*cout, cout, 1) (k=1,s=1)操作。
以上就是C2f模块的全过程,输出的特征图尺寸为h*w*cout。
class C2f(nn.Module):# CSP Bottleneck with 2 convolutionsdef __init__(self, c1, c2, n=1, shortcut=False, g=1, e=0.5): # ch_in, ch_out, number, shortcut, groups, expansionsuper().__init__()self.c = int(c2 * e) # hidden channelsself.cv1 = Conv(c1, 2 * self.c, 1, 1)self.cv2 = Conv((2 + n) * self.c, c2, 1) # optional act=FReLU(c2)self.m = nn.ModuleList(Bottleneck(self.c, self.c, shortcut, g, k=((3, 3), (3, 3)), e=1.0) for _ in range(n))def forward(self, x):y = list(self.cv1(x).chunk(2, 1))y.extend(m(y[-1]) for m in self.m)return self.cv2(torch.cat(y, 1))def forward_split(self, x):y = list(self.cv1(x).split((self.c, self.c), 1))y.extend(m(y[-1]) for m in self.m)return self.cv2(torch.cat(y, 1))class Bottleneck(nn.Module):# Standard bottleneckdef __init__(self, c1, c2, shortcut=True, g=1, k=(3, 3), e=0.5): # ch_in, ch_out, shortcut, groups, kernels, expandsuper().__init__()c_ = int(c2 * e) # hidden channelsself.cv1 = Conv(c1, c_, k[0], 1)self.cv2 = Conv(c_, c2, k[1], 1, g=g)self.add = shortcut and c1 == c2def forward(self, x):return x + self.cv2(self.cv1(x)) if self.add else self.cv2(self.cv1(x))
第3层: - [-1, 1, Conv, [256, 3, 2]] # 3-P3/8
进行卷积操作(256代表输出通道数,3代表卷积核大小k,2代表stride步长),输出特征图尺寸为80*80*256(卷积的参数都没变,所以都是长宽变成原来的1/2,和之前一样),特征图的长宽已经变成输入图像的1/8。
第4层: - [-1, 6, C2f, [256, True]]
本层是C2f模块,可以参考第2层的讲解。6代表本层重复6次。256代表输出通道数,True表示Bottleneck有shortcut。
经过这层之后,特征图尺寸依旧是80*80*256。
第5层: - [-1, 1, Conv, [512, 3, 2]] # 5-P4/16
进行卷积操作(512代表输出通道数,3代表卷积核大小k,2代表stride步长),输出特征图尺寸为40*40*512(卷积的参数都没变,所以都是长宽变成原来的1/2,和之前一样),特征图的长宽已经变成输入图像的1/16。
第6层: - [-1, 6, C2f, [512, True]]
本层是C2f模块,可以参考第2层的讲解。6代表本层重复6次。512代表输出通道数,True表示Bottleneck有shortcut。
经过这层之后,特征图尺寸依旧是40*40*512。
第7层: - [-1, 1, Conv, [1024, 3, 2]] # 7-P5/32
进行卷积操作(1024代表输出通道数,3代表卷积核大小k,2代表stride步长),输出特征图尺寸为20*20*1024(卷积的参数都没变,所以都是长宽变成原来的1/2,和之前一样),特征图的长宽已经变成输入图像的1/32。
第8层: - [-1, 3, C2f, [1024, True]]
本层是C2f模块,可以参考第2层的讲解。3代表本层重复3次。1024代表输出通道数,True表示Bottleneck有shortcut。
经过这层之后,特征图尺寸依旧是20*20*1024。
第9层: - [-1, 1, SPPF, [1024, 5]] # 9
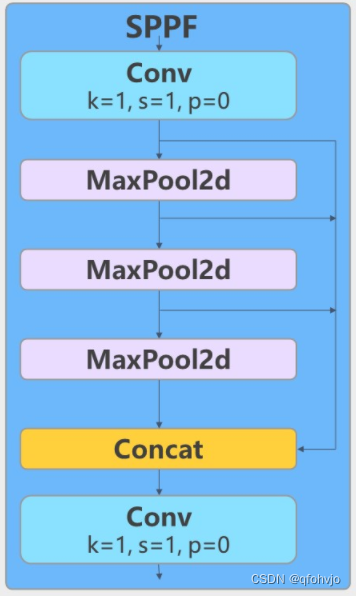
class SPPF(nn.Module):# Spatial Pyramid Pooling - Fast (SPPF) layer for YOLOv5 by Glenn Jocherdef __init__(self, c1, c2, k=5): # equivalent to SPP(k=(5, 9, 13))super().__init__()c_ = c1 // 2 # hidden channelsself.cv1 = Conv(c1, c_, 1, 1)self.cv2 = Conv(c_ * 4, c2, 1, 1)self.m = nn.MaxPool2d(kernel_size=k, stride=1, padding=k // 2)def forward(self, x):x = self.cv1(x)y1 = self.m(x)y2 = self.m(y1)return self.cv2(torch.cat((x, y1, y2, self.m(y2)), 1))本层是快速空间金字塔池化层(SPPF)。1024代表输出通道数,5代表池化核大小k。结合模块结构图和代码可以看出,最后concat得到的特征图尺寸是20*20*(512*4),经过一次Conv得到20*20*1024。
Head部分:
# YOLOv8.0n head
head:- [-1, 1, nn.Upsample, [None, 2, 'nearest']]- [[-1, 6], 1, Concat, [1]] # cat backbone P4- [-1, 3, C2f, [512]] # 12- [-1, 1, nn.Upsample, [None, 2, 'nearest']]- [[-1, 4], 1, Concat, [1]] # cat backbone P3- [-1, 3, C2f, [256]] # 15 (P3/8-small)- [-1, 1, Conv, [256, 3, 2]]- [[-1, 12], 1, Concat, [1]] # cat head P4- [-1, 3, C2f, [512]] # 18 (P4/16-medium)- [-1, 1, Conv, [512, 3, 2]]- [[-1, 9], 1, Concat, [1]] # cat head P5- [-1, 3, C2f, [1024]] # 21 (P5/32-large)- [[15, 18, 21], 1, Detect, [nc]] # Detect(P3, P4, P5)
第10层: - [-1, 1, nn.Upsample, [None, 2, ‘nearest’]]
torch.nn.Upsample(size=None, scale_factor=None, mode='nearest', align_corners=None)
本层是上采样层。-1代表将上层的输出作为本层的输入。None代表上采样的size(输出尺寸)不指定。2代表scale_factor=2,表示输出的尺寸是输入尺寸的2倍。nearest代表使用的上采样算法为最近邻插值算法。经过这层之后,特征图的长和宽变成原来的两倍,通道数不变,所以最终尺寸为40*40*1024。
第11层: - [[-1, 6], 1, Concat, [1]] # cat backbone P4
本层是concat层,[-1, 6]代表将上层和第6层的输出作为本层的输入。[1]代表concat拼接的维度是1。从上面的分析可知,上层的输出尺寸是40*40*1024,第6层的输出是40*40*512,最终本层的输出尺寸为40*40*1536。
第12层: - [-1, 3, C2f, [512]] # 12
本层是C2f模块,可以参考第2层的讲解。3代表本层重复3次。512代表输出通道数。与Backbone中C2f不同的是,此处的C2f的bottleneck模块的shortcut=False。
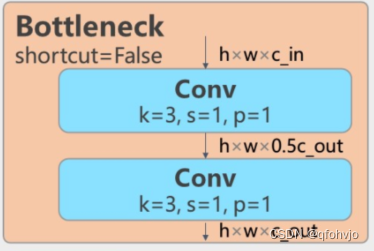
经过这层之后,特征图尺寸变为40*40*512。
第13层: - [-1, 1, nn.Upsample, [None, 2, ‘nearest’]]
本层也是上采样层(参考第10层)。经过这层之后,特征图的长和宽变成原来的两倍,通道数不变,所以最终尺寸为80*80*512。
第14层: - [[-1, 4], 1, Concat, [1]] # cat backbone P3
本层是concat层,[-1, 4]代表将上层和第4层的输出作为本层的输入。[1]代表concat拼接的维度是1。从上面的分析可知,上层的输出尺寸是80*80*512,第6层的输出是80*80*256,最终本层的输出尺寸为80*80*768。
第15层: - [-1, 3, C2f, [256]] # 15 (P3/8-small)
本层是C2f模块,可以参考第2层的讲解。3代表本层重复3次。256代表输出通道数。
经过这层之后,特征图尺寸变为80*80*256,特征图的长宽已经变成输入图像的1/8。
第16层: - [-1, 1, Conv, [256, 3, 2]]
进行卷积操作(256代表输出通道数,3代表卷积核大小k,2代表stride步长),输出特征图尺寸为40*40*256(卷积的参数都没变,所以都是长宽变成原来的1/2,和之前一样)。
第17层: - [[-1, 12], 1, Concat, [1]] # cat head P4
本层是concat层,[-1, 12]代表将上层和第12层的输出作为本层的输入。[1]代表concat拼接的维度是1。从上面的分析可知,上层的输出尺寸是40*40*256,第12层的输出是40*40*512,最终本层的输出尺寸为40*40*768。
第18层: - [-1, 3, C2f, [512]] # 18 (P4/16-medium)
本层是C2f模块,可以参考第2层的讲解。3代表本层重复3次。512代表输出通道数。
经过这层之后,特征图尺寸变为40*40*512,特征图的长宽已经变成输入图像的1/16。
第19层: - [-1, 1, Conv, [512, 3, 2]]
进行卷积操作(512代表输出通道数,3代表卷积核大小k,2代表stride步长),输出特征图尺寸为20*20*512(卷积的参数都没变,所以都是长宽变成原来的1/2,和之前一样)。
第20层: - [[-1, 9], 1, Concat, [1]] # cat head P5
本层是concat层,[-1, 9]代表将上层和第9层的输出作为本层的输入。[1]代表concat拼接的维度是1。从上面的分析可知,上层的输出尺寸是20*20*512,第9层的输出是20*20*1024,最终本层的输出尺寸为20*20*1536。
第21层: - [-1, 3, C2f, [1024]] # 21 (P5/32-large)
本层是C2f模块,可以参考第2层的讲解。3代表本层重复3次。1024代表输出通道数。
经过这层之后,特征图尺寸变为20*20*1024,特征图的长宽已经变成输入图像的1/32。
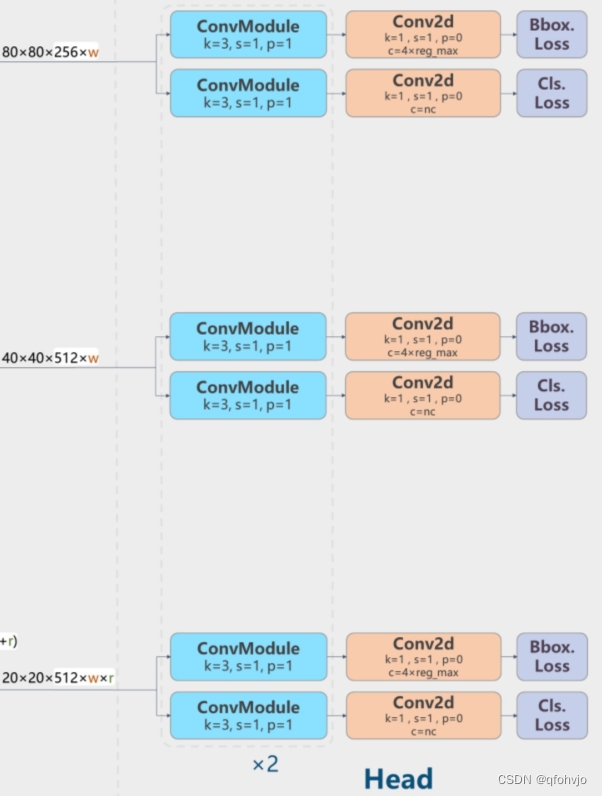
第22层: - [[15, 18, 21], 1, Detect, [nc]] # Detect(P3, P4, P5)
本层是Detect层,[15, 18, 21]代表将第15、18、21层的输出(分别是80*80*256、40*40*512、20*20*1024)作为本层的输入。nc是数据集的类别数。
class Detect(nn.Module):# YOLOv8 Detect head for detection modelsdynamic = False # force grid reconstructionexport = False # export modeshape = Noneanchors = torch.empty(0) # initstrides = torch.empty(0) # initdef __init__(self, nc=80, ch=()): # detection layersuper().__init__()self.nc = nc # number of classesself.nl = len(ch) # number of detection layersself.reg_max = 16 # DFL channels (ch[0] // 16 to scale 4/8/12/16/20 for n/s/m/l/x)self.no = nc + self.reg_max * 4 # number of outputs per anchorself.stride = torch.zeros(self.nl) # strides computed during buildc2, c3 = max((16, ch[0] // 4, self.reg_max * 4)), max(ch[0], self.nc) # channelsself.cv2 = nn.ModuleList(nn.Sequential(Conv(x, c2, 3), Conv(c2, c2, 3), nn.Conv2d(c2, 4 * self.reg_max, 1)) for x in ch)self.cv3 = nn.ModuleList(nn.Sequential(Conv(x, c3, 3), Conv(c3, c3, 3), nn.Conv2d(c3, self.nc, 1)) for x in ch)self.dfl = DFL(self.reg_max) if self.reg_max > 1 else nn.Identity()def forward(self, x):shape = x[0].shape # BCHWfor i in range(self.nl):x[i] = torch.cat((self.cv2[i](x[i]), self.cv3[i](x[i])), 1)if self.training:return xelif self.dynamic or self.shape != shape:self.anchors, self.strides = (x.transpose(0, 1) for x in make_anchors(x, self.stride, 0.5))self.shape = shapeif self.export and self.format == 'edgetpu': # FlexSplitV ops issuex_cat = torch.cat([xi.view(shape[0], self.no, -1) for xi in x], 2)box = x_cat[:, :self.reg_max * 4]cls = x_cat[:, self.reg_max * 4:]else:box, cls = torch.cat([xi.view(shape[0], self.no, -1) for xi in x], 2).split((self.reg_max * 4, self.nc), 1)dbox = dist2bbox(self.dfl(box), self.anchors.unsqueeze(0), xywh=True, dim=1) * self.stridesy = torch.cat((dbox, cls.sigmoid()), 1)return y if self.export else (y, x)def bias_init(self):# Initialize Detect() biases, WARNING: requires stride availabilitym = self # self.model[-1] # Detect() module# cf = torch.bincount(torch.tensor(np.concatenate(dataset.labels, 0)[:, 0]).long(), minlength=nc) + 1# ncf = math.log(0.6 / (m.nc - 0.999999)) if cf is None else torch.log(cf / cf.sum()) # nominal class frequencyfor a, b, s in zip(m.cv2, m.cv3, m.stride): # froma[-1].bias.data[:] = 1.0 # boxb[-1].bias.data[:m.nc] = math.log(5 / m.nc / (640 / s) ** 2) # cls (.01 objects, 80 classes, 640 img)class DFL(nn.Module):# Integral module of Distribution Focal Loss (DFL) proposed in Generalized Focal Loss https://ieeexplore.ieee.org/document/9792391def __init__(self, c1=16):super().__init__()self.conv = nn.Conv2d(c1, 1, 1, bias=False).requires_grad_(False)x = torch.arange(c1, dtype=torch.float)self.conv.weight.data[:] = nn.Parameter(x.view(1, c1, 1, 1))self.c1 = c1def forward(self, x):b, c, a = x.shape # batch, channels, anchorsreturn self.conv(x.view(b, 4, self.c1, a).transpose(2, 1).softmax(1)).view(b, 4, a)# return self.conv(x.view(b, self.c1, 4, a).softmax(1)).view(b, 4, a)
以上是对yolov8模型结构的一个大概的梳理,有一些模块的细节本人了解的也没有很清楚,所以就没有对全部代码进行解释。希望我的文章对你有帮助!