目录
- reids 是做什么的
- 为什么那么快
- 有哪些使用场景
- redis有哪些 数据结构
- redis 有哪些底层数据结构
- 为什么设计 sds
- 一个 字符串 存储多大容量
- stream
- 为什么设计 stream
- stream 消费者消息丢失
- stream 消息私信问题
- 持久化机制
- redis 持久化机制,优缺点,怎么用
- rdb 又是怎么触发的呢
- rdb 期间 ,内存很大,如果有写操作,如何保证数据一致性
- 主进程 fork 子进程如何复制数据
- 那么 rdb 期间,服务崩溃怎么办
- 那么 aof 如何实现呢
- 什么是 aof 重写
- aof 重写时,主线程有哪些地方会被阻塞
- aof 重写时,有新数据写入 怎么办?
- 主从模式
- redis 什么是主从,为什么需要主从
- 主服务器数据怎么复制到从服务器,什么 是全量 复制
- 为什么增加增量复制
- repl_backlog_buffer 环形缓冲区满了怎么办
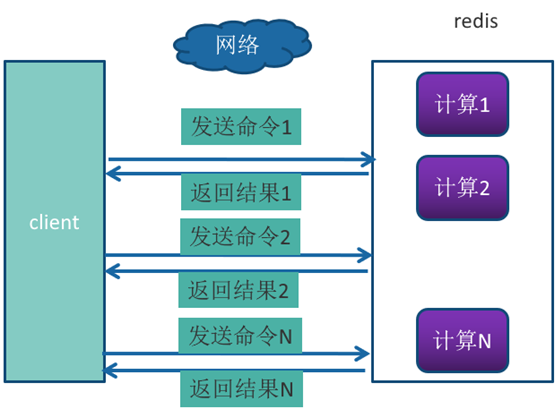
reids 是做什么的
为什么那么快
有哪些使用场景
1.数据缓存
2.计数器
3.限时
4.限流
5.分布式锁
6.队列
7.发布 订阅
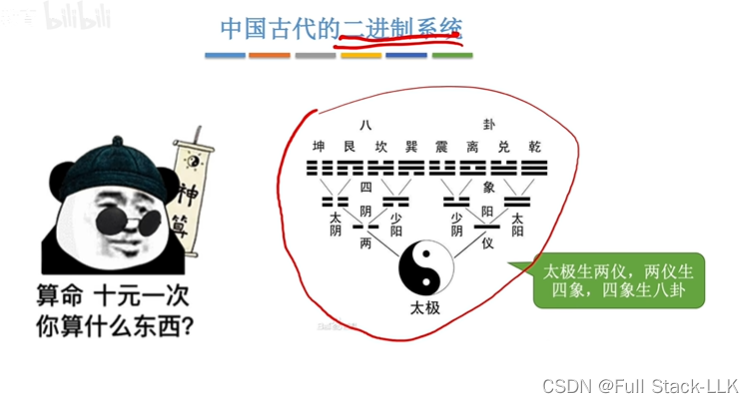
redis有哪些 数据结构
常用的
- string 对字符串 、整数、浮点数
- list 链表 ,字符串
- set 不重复集合 ,交集、并集 差集
- hash 无序散列
- zset 不重复 分数排序 排行榜
特殊的 - 基数统计 hyperloglogs
- 位图 bitmaps
- 地理位置 geo
redis 有哪些底层数据结构
- sds 动态字符串
- quicklist 快表
- ziplist
- inset
- dict
- skiplist
为什么设计 sds
- 常数复杂度获取字符串长度
- 杜绝缓冲区溢出,先判断长度
- 减少内存分配 次数,预分配,惰性释放空间
- 兼容部分 c 函数
- 二进制安全 ,图片,空字符,特殊符号 存储 ,判断结束
一个 字符串 存储多大容量
- 512m
stream
为什么设计 stream
redis 支持发布订阅功能,但是有缺陷
- list和 zet ,支持持久化,不支持主播、多播
- pub、sub,不支持持久化,dwon 机消息丢失,
参考 kafka,设计了 stream,支持消息回溯,消费者组
stream 消费者消息丢失
- 对于组内消费者消费消息,现记录读取位置,消费完,回复 ack,记录消息过,如果消费者宕机,可以调用查询 pengding 列表,读取已经 读取未成功消费的消息
stream 消息私信问题
- 对于反复失败的 消息,redis 会记录失败次数,达到一定次数 ,会打标记,消费者查询该标记,可以决定 是删除 还是怎么 处理
持久化机制
redis 持久化机制,优缺点,怎么用
主要采用两种方式
- 存量复制,采用 rdb 持久化,对已经存在的大量数据拍快照, 速度快,耗内存大
- 增量复制,如果只采用 rdb,redis 数据每次写入,都要实时持久化吗,不合适,所以有了 aof 日志,可以把 redis 命令通过文本 方式实时的追加到文件中
- redis 4.0 采用混合模式 ,rdb 定时执行,期间的命令,采用 aof 追加,这样既避免了 fork 子进程对内存 的影响,有可以记录所有 的命令
rdb 又是怎么触发的呢
- 手动触发
- save 命令,主进程执行,会阻塞客户端,生产环境禁止使用
- bgsave 命令,新版 redis 推出,fork 一个子进程,后台 执行,阻塞只发生在 fork 阶段,其他没事
- 自动触发
- 配置文件配置 save m 秒 n 次
- 主从复制,从节点 执行全量复制时
- 执行shutdown 命令,没有开启 aof 时,也会进行
- 执行 debug reload 命令,重新加载 redis 触发
rdb 期间 ,内存很大,如果有写操作,如何保证数据一致性
- rdb 采用 copy-on-write,通过 fork 一个子进程进行,假设 t0redis 启动 t1 执行 rdb 命令 ,rdb 先 fork 一个主进程备份 t0-t1 期间的数据,假设备份 完成时间 t2,那么 t1-t2 期间数据怎么办?
- rdb 期间,redis 会 提供一个内存缓冲期,t1-t2 期间的都copy 一份副本,写入这个缓冲区 ,带 rdb 完后,同步回去
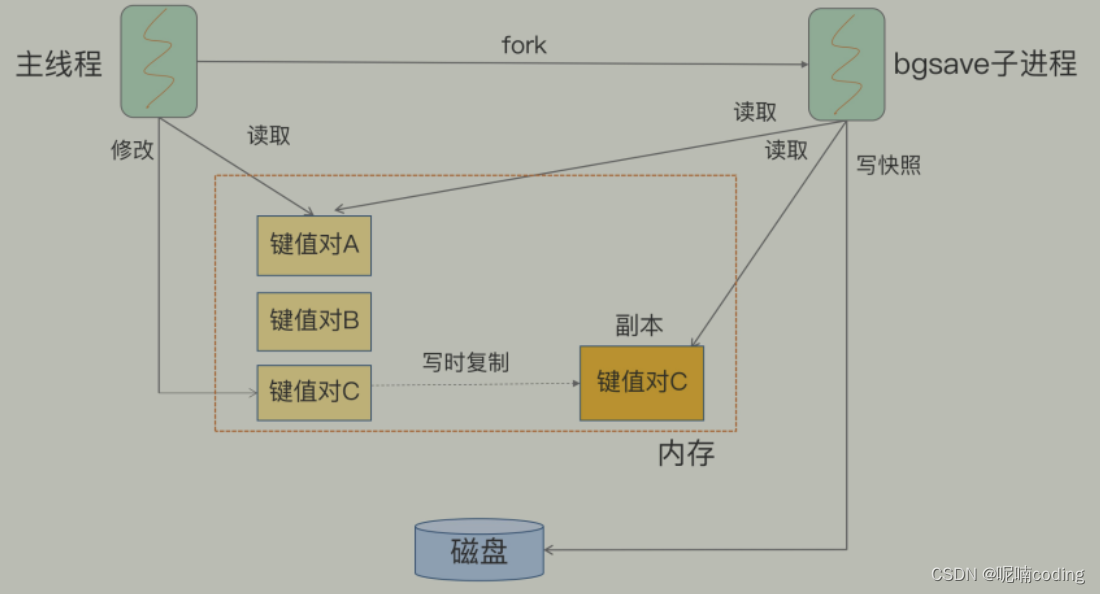
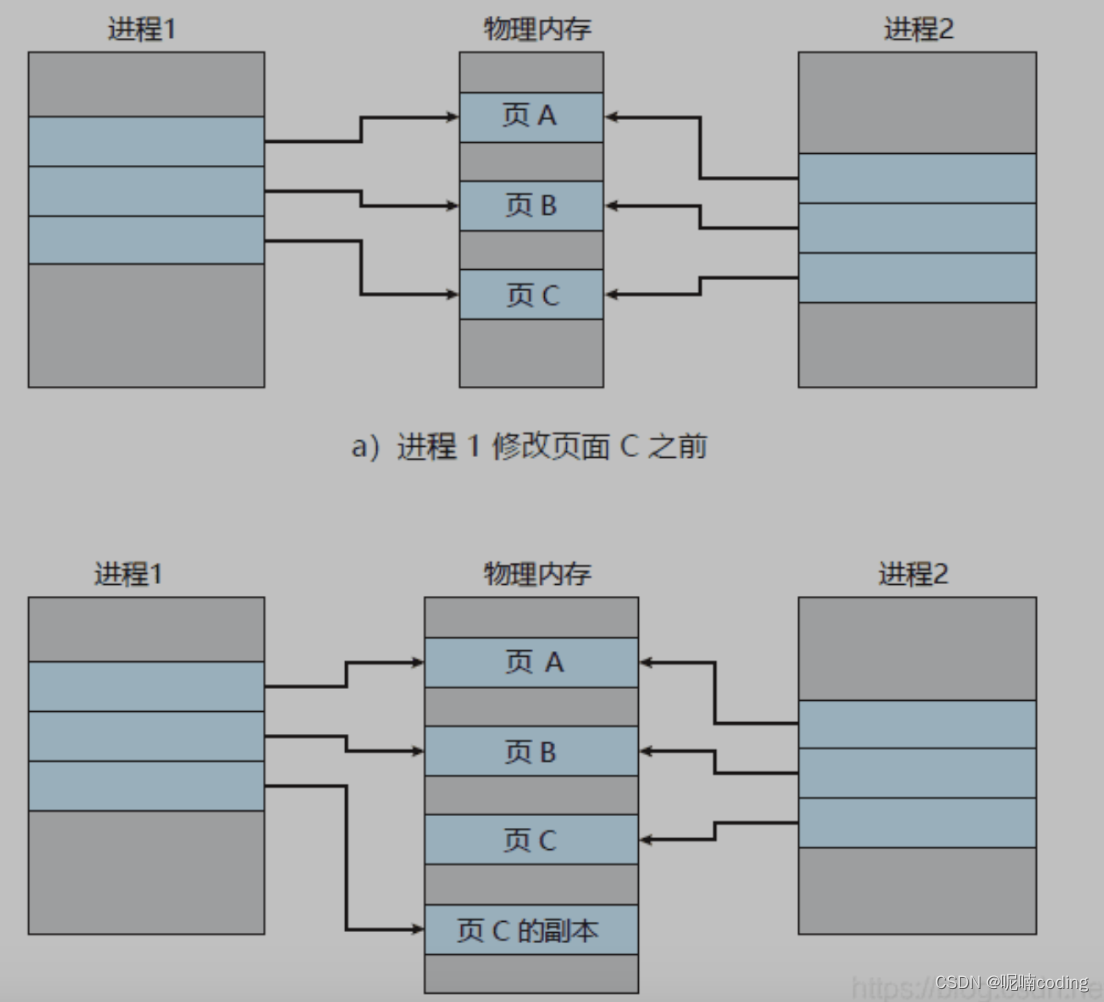
主进程 fork 子进程如何复制数据
- fork 命令有 操作系统提供,不会复制 一份内存,只会复制 虚拟页表的对应关系,会耗费 cpu resource
- 当客户端读取数据,直接读取主进程数据
- 当客户端写入数据,会 copy 一份副本 出来
那么 rdb 期间,服务崩溃怎么办
- rdb 是定时执行的,redis 会存储最近的 rdb 快照,如果最新的一次崩溃, 这次 rdb 就不算 成功,那么重启 redis,就会使用上一次成功的 rdb 快照恢复
- 期间数据会丢失部分
既然数据会丢失,可以每 s 一次吗 - 非常不建议,这样很耗费资源
- fork 子进程耗费 cpu 和内存,多次 bgsave,会阻塞主进程
- 备份多个,耗费磁盘
- 建议采用 aof 和 rdb 结合的方式
那么 aof 如何实现呢
- aof 日志是记录redis 的每个写命令,每次 redis 命令写入成功后,都会发送到一个缓冲区 aof_buf,redis 会读取缓冲 取,把命令 写入文件中
- 文件写入和追加时间 ,什么时候会把 aof_buf 写入 aof 文件呢
什么是 aof 重写
aof 一直追加,时间久了文件 会很大,redis 为了优化这个问题,推出了 aof 重写
- redis 会创建一个 新的文件,redis 数据库的数据,采用命令的方式,重新写入 aof 文件中,写完后,替换之前的 aof 文件
- 这样合并去除了之前的多次 add del 命令,减少了容量

aof 重写时,主线程有哪些地方会被阻塞
- fork 子进程,需要复制虚拟页表
- 有 bigkey 写入,需要 copy 一份副本
- aof 写入完成,主进程 append aof buffer 数据时
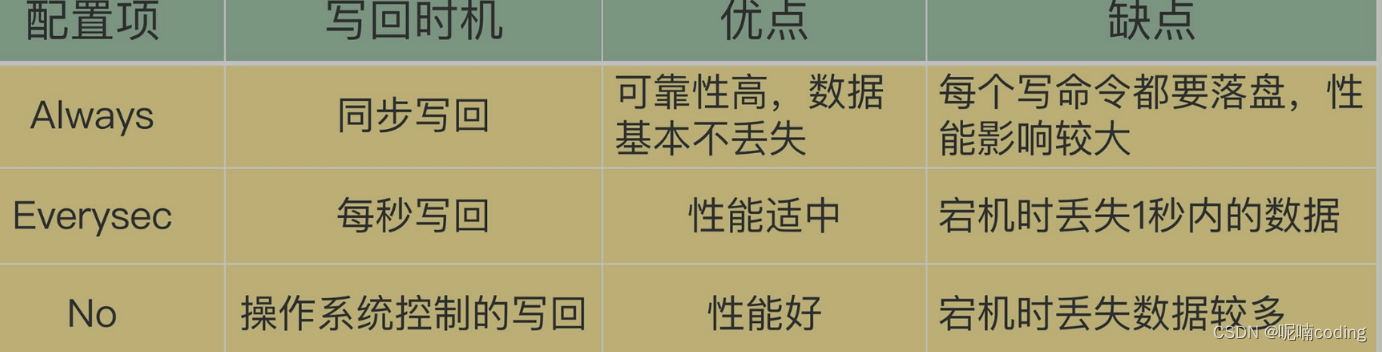
aof 怎么触发呢 - 2 个配置
- auto-aof-rewrite-min-size:表示运行AOF重写时文件的最小大小,默认为64MB。
- auto-aof-rewrite-percentage:这个值的计算方式是,当前aof文件大小和上一次重写后aof文件大小的差值,再除以上一次重写后aof文件大小。也就是当前aof文件比上一次重写后aof文件的增量大小,和上一次重写后aof文件大小的比值。
aof 重写时,有新数据写入 怎么办?
- 总结为 一个拷贝,2 出日志 , 在重新时,会 fork 子进程, 主进程会把命令 记录到 2 个 aof 缓冲区
- bgrewriteaof 重新完成后 ,会通知主进程,主进程会把 aof 缓冲区命令追加到新的 aof 日志文件后面
- 完成,采用重命名方式替换
主从模式
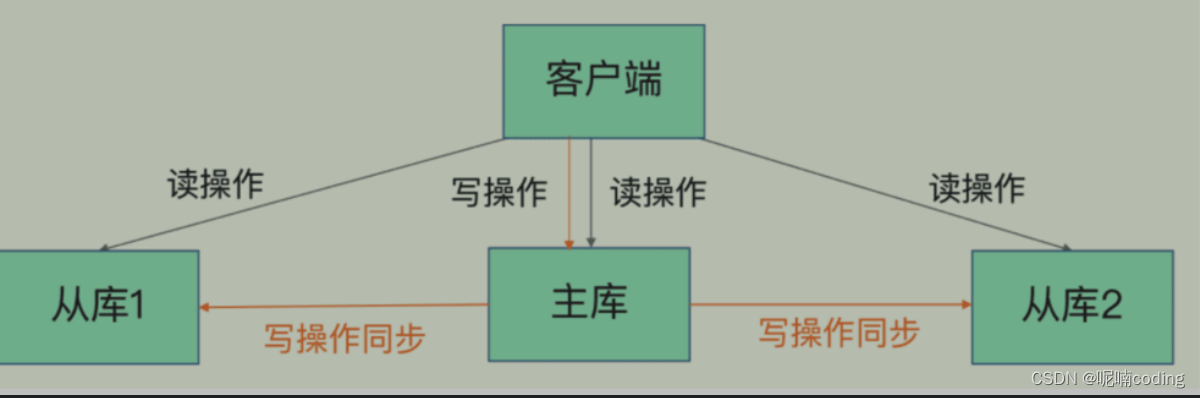
redis 什么是主从,为什么需要主从
- 一般 redis 只有一台节点提供服务,也就是单机 redis,主从最简单的来说就是2台redis服务器,一个台作为主服务器,一台作为从服务器,从服务器同步主服务器的所有数据
- 可以提供
- 数据冗余:多保存一份数据
- 故障恢复:2台机器都有数据,一台有问题,可以切换另一台提供服务
- 负载均衡:一台提供读写,从服务器提供 °,减轻主服务器压力
- 高可用的基础: 主从自动切换的哨兵模式和 redis cluter 都需要主从为基础
主服务器数据怎么复制到从服务器,什么 是全量 复制
复制方式一共有 2 中,2.8之前全量复制

全量复制的过程
- 建立连接,从服务器执行psync ? 1命令 ,包含主库的 runid 和自己的复制 offset 进度,第一次都不知道,传递?和- ,
- 主库收到后,回复fullresync runid offset ,告诉 自己的 runid 和自己的复制进度,
- 主库开始进行 bgsave生成 rdb 文件,发给从库,同时把这期间的命令存储 到 repl buffer 中
- 从库收到 rdb,清库自己的数据,加载 rdb
- 主动发送 repl buffer,从库执行,完成
为什么增加增量复制
2.8之后,增加增量复制,因为主从网络不稳定,会导致断开连接,每次断开,都会进行全量复制,耗费性能,其实一些步骤不需要全部执行一遍,
redis 提取分析了哪些必须执行的步骤,退出了增量复制功能

看图说话,现说 2 个参数 replication buffer 和 repl_backlog_buffer
- repl_backlog_buffer:是为了从库断开之后,如何找到主从差异数据而设计的环形缓冲区,从而避免全量复制带来的性能开销。如果从库断开时间太久,repl_backlog_buffer环形缓冲区被主库的写命令覆盖了,那么从库连上主库后只能乖乖地进行一次全量复制,所以repl_backlog_buffer配置尽量大一些,可以降低主从断开后全量复制的概率。而在repl_backlog_buffer中找主从差异的数据后,如何发给从库呢?这就用到了replication buffer。
- replication buffer: Redis和客户端通信也好,和从库通信也好,Redis都需要给分配一个 内存buffer进行数据交互,客户端是一个client,从库也是一个client,我们每个client连上Redis后,Redis都会分配一个client buffer,所有数据交互都是通过这个buffer进行的:Redis先把数据写到这个buffer中,然后再把buffer中的数据发到client socket中再通过网络发送出去,这样就完成了数据交互。所以主从在增量同步时,从库作为一个client,也会分配一个buffer,只不过这个buffer专门用来传播用户的写命令到从库,保证主从数据一致,我们通常把它叫做replication buffer。#
repl_backlog_buffer 环形缓冲区满了怎么办
- 如果断开时间过长,从库在主库的repl_backlog_buffer和slave_repl_offset都被覆盖了,只能重新全量复制
- 每个从库的 slave_repl_offset 都不一样,主库会自动判断,是否需要全量复制


![[每周一更]-(第51期):Go的调度器GMP](https://img-blog.csdnimg.cn/direct/7bb6910bc70746b384bc78aceab5fe77.png#pic_center)