本文主要介绍OpenMP编程的编程要素和实战,包括并行域管理详细实战、任务分担详细实战。
🎬个人简介:一个全栈工程师的升级之路!
📋个人专栏:高性能(HPC)开发基础教程
🎀CSDN主页 发狂的小花
🌄人生秘诀:学习的本质就是极致重复!
目录
一、前言
1 OpenMP执行模式
2 OpenMP编程要素
二、OpenMP编程实战
1 并行域管理
1.1 parallel 并行域使用
1.2 并行域线程数量控制方式
1.3 并行域动态调整线程数量
2 任务分担
2.1 for 制导指令
2.3 for 调度
2.4 sections 制导指令
2.5 single 制导指令
一、前言
OpenMP 是一种制导指令,用于将 C 语言扩展为并行语言。然而,OpenMP 本身并不是一种独立的并行语言,而是为在多处理器上编写并行程序而设计的编译制导指令和应用程序编程接口(API)。它可以在 C/C++ 和 Fortran中使用,并以编译器可识别的注释形式出现在串行代码中。OpenMP 标准由一些具有国际影响力的软件和硬件厂商共同定义和提出,它是一种在共享存储体系结构上的可移植编程模型,广泛应用于 Unix、Linux、Windows 等多种平台。
1 OpenMP执行模式
OpenMP 的执行模型采用 fork-join 的形式,其中 fork 创建新线程或者唤醒已有线程;join
即多线程的会合。fork-join 执行模型在刚开始执行的时候,只有一个称为“主线程”的运行线
程存在。主线程在运行过程中,当遇到需要进行并行计算的时候,派生出线程来执行并行任务。
在并行执行的时候,主线程和派生线程共同工作。在并行代码执行结束后,派生线程退出或者
阻塞,不再工作,控制流程回到单独的主线程中。
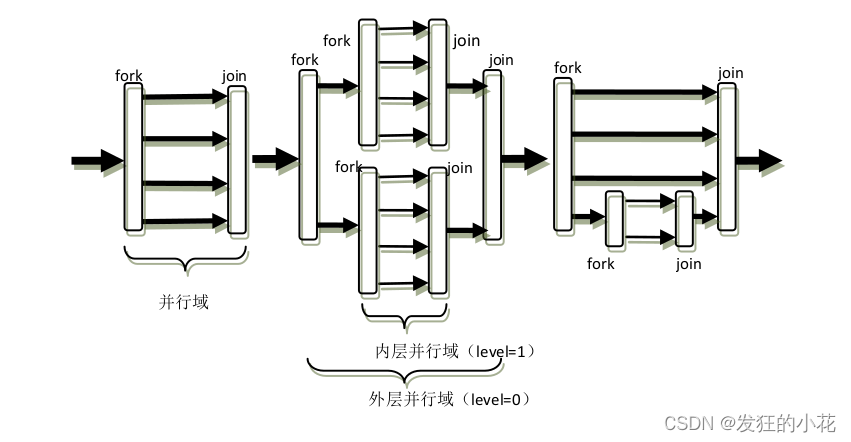
图 1.1 fork-join并行执行模型
OpenMP 的编程者需要在可并行工作的代码部分用制导指令向编译器指出其并行属性,而
且这些并行区域可以出现嵌套的情况,如图1.1所示。
并行域(Paralle region)
在成对的 fork 和 join 之间的区域,称为并行域,它既表示代码也表示执行时间区间。
OpenMP 线程
在 OpenMP 程序中用于完成计算任务的一个执行流的执行实体,可以是操作系统的线程也可以是操作系统上的进程。
2 OpenMP编程要素
OpenMP 编程模型以线程为基础,通过编译制导指令来显式地指导并行化,OpenMP 为编
程人员提供了三种编程要素来实现对并行化的完善控制。它们是编译制导、API 函数集和环境
变量。
在 C/C++程序中,OpenMP 的所有编译制导指令是以#pragma omp 开始,后面跟具体的功
能指令(或命令),其具有如下形式:
#pragma omp 指令 [子句[, 子句]…] 支持 OpenMP 的编译器能识别、处理这些制导指令并实现其功能。其中指令或命令是可
以单独出现的,而子句则必须出现在制导指令之后。制导指令和子句按照功能可以大体上分成
四类:
1)并行域控制类
并行域控制类指令用于指示编译器产生多个线程以并发执行任务
2)任务分担类
任务分担类指令指示编译器如何给各个并发线程分发任务
3)同步控制类
同步控制类指令指示编译器协调并发线程之间的时间约束关系
4)数据环境类
数据环境类指令处理并行域内外的变量共享或私有属性以及边界上的数据传送操作等
具体的编译制导指令和子句,以及API库函数、环境变量等可以参考我前面写的教程(一)、(二)。
二、OpenMP编程实战
内容按照功能进行划分,每个功能部分将可能综合使用编译制导、环境变量和OpenMP API 函数这三种要素。
1 并行域管理
设计并行程序时,首先需要多个线程来并发地执行任务,因此 OpenMP 编程中第一步就是应该掌握如何产生出多个线程。如前面所实,在 OpenMP 的相邻的 fork、join 操作之间我们称之为一个并行域,并行域可以嵌套。parallel 制导指令就是用来创建并行域的,它也可以和其他指令如 for、sections 等配合使用形成复合指令。
1.1 parallel 并行域使用
在 C/C++中,parallel 的使用方法如下:
#pragma omp parallel [for | sections] [子句[子句]„]
{...代码...
}parallel 语句后面要用一个大括号对将要并行执行的代码括起来。
#include <stdio.h>
#include <omp.h>void main(int argc, char *argv[])
{#pragma omp parallel// 并行域的开始 (对应 fork){printf("Hello OpenMP!\n");// 并行域的结束(对应 join)}
}
执行以上代码将会打印出以下结果:
Hello OpenMP!
Hello OpenMP!
Hello OpenMP!
Hello OpenMP!
Hello OpenMP!
Hello OpenMP!
Hello OpenMP!
Hello OpenMP! 可以看得出 parallel 语句中的代码被“相同”地执行了 8 次,说明总共创建了 8 个线程来
执 行 parallel 语 句 中的代 码 。 为 了指 定 使 用多少 个 线 程 来执 行 , 可以通 过 设 置 环境 变
OMP_NUM_THREADS 或者调用 omp_set_num_theads()函数,也可以使用 num_threads 子句,
前者只能在程序刚开始运行时起作用,而 API 函数和子句可以在程序中并行域产生之前起作
用。
1.2 并行域线程数量控制方式
(1)OMP_NUM_THREADS使用方式:(命令端执行)
export OMP_NUM_THREADS=<number>
例子:(4个线程运行该程序)
export OMP_NUM_THREADS=4(2)omp_set_num_theads()使用方式
#include <stdio.h>
#include "omp.h"// 命令端执行下面,表示4个线程执行并行域
// export OMP_NUM_THREADS=4
int main(int argc, char *argv[])
{int nums_threads = 4;omp_set_num_threads(nums_threads);#pragma omp parallel// 并行域的开始 (对应 fork){printf("Hello OpenMP threadID = %d !\n",omp_get_thread_num());} // 并行域的结束(对应 join)return 0;
}运行结果:
Hello OpenMP threadID = 0 !
Hello OpenMP threadID = 2 !
Hello OpenMP threadID = 1 !
Hello OpenMP threadID = 3 !(3)num_threads字句使用方式
#include <stdio.h>
#include "omp.h"// 命令端执行下面,表示4个线程执行并行域
// export OMP_NUM_THREADS=4
int main(int argc, char *argv[])
{// int nums_threads = 4;// omp_set_num_threads(nums_threads);#pragma omp parallel num_threads(4)// 并行域的开始 (对应 fork){printf("Hello OpenMP threadID = %d !\n",omp_get_thread_num());} // 并行域的结束(对应 join)return 0;
}运行结果:
Hello OpenMP threadID = 0 !
Hello OpenMP threadID = 1 !
Hello OpenMP threadID = 2 !
Hello OpenMP threadID = 3 ! 从 threadID 的不同可以看出创建了 4 个线程来执行以上代码。所以 parallel 指令是用来产
生或唤醒多个线程创建并行域的,并且可以用 num_threads 子句控制线程数目。parallel 域中
的每行代码都被多个线程重复执行。和传统的创建线程函数比起来,其过程非常简单直观。
parallel 的并行域内部代码中,若再出现 parallel 制导指令则出现并行嵌套问题,如果设置
了 OMP_NESTED 环境变量,那么在条件许可时内部并行域也会由多个线程执行,反之没有设
置相应变量,那么内部并行域的代码将只由一个线程来执行。还有 一个环境变量
OMP_DYNAMIC 也影响并行域的行为,如果没有设置该环境变量将不允许动态调整并行域内的
线程数目,omp_set_dynamic()也是用于同样的目的。
1.3 并行域动态调整线程数量
(1)omp_set_num_threads()动态调整线程的数量
#include <stdio.h>
#include "omp.h"// 命令端执行下面,表示4个线程执行并行域
// export OMP_NUM_THREADS=4
int main(int argc, char *argv[])
{// int nums_threads = 4;// omp_set_num_threads(nums_threads);omp_set_dynamic(1);#pragma omp parallel// 并行域的开始 (对应 fork){printf("Hello OpenMP threadID = %d !\n",omp_get_thread_num());} // 并行域的结束(对应 join)return 0;
}运行结果:
Hello OpenMP threadID = 0 !
Hello OpenMP threadID = 1 !
Hello OpenMP threadID = 2 !可以看到没有设置线程数量,但动态调整为3个了。
(2)OMP_DYNAMIC方式动态调整线程数量
使用方式:(命令端)
export OMP_DYNAMIC=<true|false>
例子:
export OMP_DYNAMIC=true实例:
第一步:命令端:export OMP_DYNAMIC=true
第二步:
#include <stdio.h>
#include "omp.h"// 命令端执行下面,表示4个线程执行并行域
// export OMP_NUM_THREADS=4
int main(int argc, char *argv[])
{// int nums_threads = 4;// omp_set_num_threads(nums_threads);// omp_set_dynamic(1);printf("DYNAMIC_OMP = %d \n",omp_get_dynamic());#pragma omp parallel num_threads(4)// 并行域的开始 (对应 fork){printf("Hello OpenMP threadID = %d !\n",omp_get_thread_num());} // 并行域的结束(对应 join)return 0;
}运行结果:
DYNAMIC_OMP = 1
Hello OpenMP threadID = 0 !
Hello OpenMP threadID = 1 !
Hello OpenMP threadID = 2 !2 任务分担
当使用 parallel 制导指令创建并行域后,如果多个线程只是执行完全相同的任务,那么当使用 parallel 制导指令创建并行域后,如果多个线程只是执行完全相同的任务,那么只会增加计算工作量而无法实现加速计算的目的,甚至可能导致相互干扰并产生错误结果。因此,在创建并行域之后,接下来的问题就是如何将计算任务分配给这些线程,并加快计算结果的生成速度以及保证正确性。OpenMP 可以完成的任务分配指令只有 for、sections 和 single。
严格来说,只有 for 和 sections 是真正的任务分配指令,而 single 只是一个辅助任务分配的指令。
我们对任务分配域的定义如下:由 for、sections 或 single 制导指令限定的代码及其执行时间段,也就是说任务分配域和并行域的定义相同,既指代代码区间也指代执行时间区间。
2.1 for 制导指令
for制导指令想要达到分担任务的能力,必须与parallel联合使用。
具体的例子可以参考 性能优化-OpenMP基础教程(一) 和 性能优化-OpenMP基础教程(二)
对于for 制导,一个并行域内,可以有多个for 制导,如下:
#include <stdio.h>
#include "omp.h"
int main ()
{int j;#pragma omp parallel{#pragma omp forfor (j = 0;j < 4;j++){printf("ThreadID1 = %d j = %d \n",omp_get_thread_num(),j);}#pragma omp forfor (j = 0;j < 4;j++){printf("ThreadID2 = %d j = %d \n",omp_get_thread_num(),j);}}return 0;
}运行结果:
ThreadID1 = 0 j = 0
ThreadID1 = 0 j = 1
ThreadID1 = 1 j = 2
ThreadID1 = 2 j = 3
ThreadID2 = 0 j = 0
ThreadID2 = 0 j = 1
ThreadID2 = 2 j = 3
ThreadID2 = 1 j = 2 此时只有一个并行域,在该并行域内的多个线程首先完成第一个 for 语句的任务分担,然
后在此进行一次同步(for 制导指令本身隐含有结束处的路障同步),然后再进行第二个 for
语句的任务分担,直到退出并行域并只剩下一个主线程为止。
2.3 for 调度
在 OpenMP 的 for 任务分担中,任务的划分称为调度,各个线程如何划分任务是可以调整的,因此有静态划分、动态划分等,所以调度也分成多个类型。for 任务调度子句只能用于 for制导指令中。
提供多种调度类型的必要性
当循环中每次迭代的计算量不相等时,如果简单地给各个线程分配相同次数的迭代的话,会使得各个线程计算负载不均衡,这会使得有些线程先执行完,有些后执行完,造成某些 CPU核空闲,影响程序性能。例如:
int i, j;
int a[100][100] = {0};
for ( i =0; i < 100; i++)
{for( j = i; j < 100; j++ )a[i][j] = i*j;
} 如果将最外层循环并行化的话,比如使用 4 个线程,如果给每个线程平均分配 25 次循环
迭代计算的话,显然 i=0 和 i=99 的计算量相差了 100 倍,那么各个线程间可能出现较大的负
载不平衡情况。为了解决这些问题,适应不同的计算类型,OpenMP 中提供了几种对 for 循环
并行化的任务调度方案。
在 OpenMP 中,对 for 循环任务调度使用 schedule 子句来实现,下面介绍 schedule 子句的
用法。
(1) schedule 子句用法
schedule 子句的使用格式为:
schedule (type [, size]) schedule 有两个参数:type 和 size,size 参数是可选的。如果没有指定 size 大小,循环迭
代会尽可能平均地分配给每个线程。
1 type 参数
表示调度类型,有四种调度类型如下:
· static
· dynamic
· guided
· runtime
这四种调度类型实际上只有 static、dynamic、guided 三种调度方式。runtime 实际上是
根据环境变量 OMP_SCHEDULED 来选择前三种中的某种类型,相应的内部控制变量 ICV 是run-sched-var。
2 size 参数 (可选)
size 参数表示以循环迭代次数计算的划分单位,每个线程所承担的计算任务对应于 0 个或若干个 size 次循环,size 参数必须是整数。
static、dynamic、guided 三种调度方式都可以使用size 参数,也可以不使用 size 参数。当 type 参数类型为 runtime 时,size 参数是非法的(不需要使用,如果使用的话编译器会报错)。
(2)static 静态调度
静态调度的开销最小,当 for 或者 parallel for 编译制导指令没有带 schedule 子句时,大部分系统中默认采用 size为 1 的 static 调度方式,这种调度方式非常简单。假设有 n 次循环迭代,t 个线程,那么给每个线程静态分配大约 n/t 次迭代计算。这里为什么说大约分配 n/t 次呢?因为 n/t 不一定是整数,因此实际分配的迭代次数可能存在差 1 的情况,如果指定了 size 参数的话,那么可能相差 size 次迭代。
静态调度时可以不使用 size 参数,也可以使用 size 参数。
1 不使用 size 参数
不使用 size 参数时,分配给每个线程的是 n/t 次连续的迭代,不使用 size 参数的用法如下:
schedule(static)例如以下代码:
#include <stdio.h>
#include "omp.h"
int main ()
{#pragma omp parallel for schedule(static) num_threads(2)for (int i = 0;i < 10;i++){printf("ThreadID = %d i = %d \n",omp_get_thread_num(),i);}return 0;
}运行结果:
ThreadID = 0 i = 0
ThreadID = 0 i = 1
ThreadID = 0 i = 2
ThreadID = 0 i = 3
ThreadID = 0 i = 4
ThreadID = 1 i = 5
ThreadID = 1 i = 6
ThreadID = 1 i = 7
ThreadID = 1 i = 8
ThreadID = 1 i = 9 并行域中有两个线程,符合执行结果推测,由于多线程的随机性,每次打印的顺序可能有差别。
2 使用 size 参数
使用 size 参数时,分配给每个线程的 size 次连续的迭代计算,用法如下:
schedule(static, size)例如以下代码:
#include <stdio.h>
#include "omp.h"
int main ()
{#pragma omp parallel for schedule(static,2) num_threads(2)for (int i = 0;i < 10;i++){printf("ThreadID = %d i = %d \n",omp_get_thread_num(),i);}return 0;
}运行结果:
ThreadID = 0 i = 0
ThreadID = 0 i = 1
ThreadID = 0 i = 4
ThreadID = 0 i = 5
ThreadID = 0 i = 8
ThreadID = 1 i = 2
ThreadID = 1 i = 3
ThreadID = 1 i = 6
ThreadID = 1 i = 7
ThreadID = 0 i = 9 从打印结果可以看出,0、1 次迭代分配给 0 号线程,2、3 次迭代分配给 1 线程号,4、5
次迭代分配给 0 号线程, 6、 7 次迭代分配给 1 号线程,„。每个线程依次分配到 2 次(即 size)
连续的迭代计算。本质上将循环分配给线程运算。
(3)dynamic 动态调度
动态调度是动态地将迭代分配到各个线程,动态调度可以使用 size 参数也可以不使用 size
参数,不使用 size 参数时是根据各个线程的完成情况将迭代逐个地分配到各个线程,使用 size
参数时,每次分配给线程的迭代次数为指定的 size 次。各线程动态的申请任务,因此较快的
线程可能申请更多次数,而较慢的线程申请任务次数可能较少,因此动态调度可以在一定程度
上避免前面提到的按循环次数划分引起的负载不平衡问题。
1下面为使用动态调度不带 size 参数的例子
#include <stdio.h>
#include "omp.h"
int main ()
{#pragma omp parallel for schedule(dynamic) num_threads(2)for (int i = 0;i < 10;i++){printf("ThreadID = %d i = %d \n",omp_get_thread_num(),i);}return 0;
}运行结果:
ThreadID = 0 i = 0
ThreadID = 0 i = 2
ThreadID = 0 i = 3
ThreadID = 0 i = 4
ThreadID = 0 i = 5
ThreadID = 0 i = 6
ThreadID = 0 i = 7
ThreadID = 0 i = 8
ThreadID = 0 i = 9
ThreadID = 1 i = 1 由于没有指定 size 所以任务划分是按 1 此迭代进行的,所以分配给每个线程的循环次数是不同的。
2下面为动态调度使用 size 参数的例子
#include <stdio.h>
#include "omp.h"
int main ()
{#pragma omp parallel for schedule(dynamic,2) num_threads(2)for (int i = 0;i < 10;i++){printf("ThreadID = %d i = %d \n",omp_get_thread_num(),i);}return 0;
}运行结果:
ThreadID = 0 i = 0
ThreadID = 0 i = 1
ThreadID = 1 i = 2
ThreadID = 1 i = 3
ThreadID = 1 i = 6
ThreadID = 1 i = 7
ThreadID = 1 i = 8
ThreadID = 1 i = 9
ThreadID = 0 i = 4
ThreadID = 0 i = 5 从打印结果来看,第“0、1“,”4、5” 次迭代被分配给了线程0,第“2、3“,”6、 7“,”8、 9“次循环迭代分配给了线程1.较快的线程抢到了更多的任务。
动态调度时, size 小有利于实现更好的负载均衡,但是会引起过多的任务动态申请的开销,反之 size 大则开销较少,但是不易于实现负在平衡,size 的选择需要在这两者之间进行权衡。
(4)guided调度
guided 调度是一种采用指导性的启发式自调度方法。开始时每个线程会分配到较大的迭
代块,之后分配到的迭代块会逐渐递减。迭代块的大小会按指数级下降到指定的 size 大小,
1如果没有指定 size 参数,那么迭代块大小最小会降到 1
例如:
#include <stdio.h>
#include "omp.h"
int main ()
{#pragma omp parallel for schedule(guided,2) num_threads(2)for (int i = 0;i < 10;i++){printf("ThreadID = %d i = %d \n",omp_get_thread_num(),i);}return 0;
}运行结果:
ThreadID = 0 i = 0
ThreadID = 0 i = 1
ThreadID = 0 i = 2
ThreadID = 0 i = 3
ThreadID = 0 i = 4
ThreadID = 0 i = 8
ThreadID = 0 i = 9
ThreadID = 1 i = 5
ThreadID = 1 i = 6
ThreadID = 1 i = 7 第 0、1、2、3、4 次迭代被分配给线程 0,第 5、6、7 次迭代被分配给线程 1,第 8、9
次迭代被分配给线程 0,分配的迭代次数呈递减趋势,最后一次递减到 2 次。
(5)runtime调度
runtime 调度并不是像前面三种调度方式那样是真实调度方式,它是在运行时根据环境变
量 OMP_SCHEDULE 来确定调度类型,最终使用的调度类型仍然是上述三种调度方式中的一种。
例如在 unix 系统中,可以使用 setenv 命令来设置 OMP_SCHEDULE 环境变量:
export OMP_SCHEDULE="dynamic,2" 如果程序中选择 runtime 调度,那么上述命令设置调度类型为动态调度,动态调度的 size
为 2。
例子:
第一步:命令端:export OMP_SCHEDULE="static,8"
第二步:执行下面代码
#include <stdio.h>
#include "omp.h"
int main ()
{#pragma omp parallel for schedule(runtime) num_threads(2)for (int i = 0;i < 10;i++){printf("ThreadID = %d i = %d \n",omp_get_thread_num(),i);}return 0;
}运行结果:
ThreadID = 0 i = 0
ThreadID = 0 i = 1
ThreadID = 0 i = 2
ThreadID = 0 i = 3
ThreadID = 0 i = 4
ThreadID = 0 i = 5
ThreadID = 0 i = 6
ThreadID = 0 i = 7
ThreadID = 1 i = 8
ThreadID = 1 i = 9 很明显看到,环境变量的配置生效了,前8个循环给线程0,后两个给线程1。
2.4 sections 制导指令
sections 编译制导指令是用于非迭代计算的任务分担,它将 sections 语句里的代码用section 制导指令划分成几个不同的段(可以是一条语句,也可以是用{...}括起来的结构块),不同的 section 段由不同的线程并行执行。用法如下:
#pragma omp [parallel] sections [子句]
{#pragma omp section{...代码块...}[#pragma omp section]...
}例子:
#include <stdio.h>
#include "omp.h"
int main ()
{#pragma omp parallel sections{// printf("Max Threads nums = %d in current parallel!\n",omp_get_max_threads());#pragma omp section{printf("ThreadID = %d \n",omp_get_thread_num());}#pragma omp section{printf("ThreadID = %d \n",omp_get_thread_num());}#pragma omp section{printf("ThreadID = %d \n",omp_get_thread_num());}}return 0;
}运行结果:
ThreadID = 3
ThreadID = 2
ThreadID = 5 此时,各个 section 里的代码是被分配到不同的线程并发地执行。下面来看看在一个并行
域内有多个 sections 的情况:
#include <stdio.h>
#include "omp.h"
int main ()
{#pragma omp parallel sections{// printf("Max Threads nums = %d in current parallel!\n",omp_get_max_threads());#pragma omp section{printf("section1 ThreadID = %d \n",omp_get_thread_num());}#pragma omp section{printf("section2 ThreadID = %d \n",omp_get_thread_num());}#pragma omp section{printf("section3 ThreadID = %d \n",omp_get_thread_num());}}#pragma omp parallel sections{// printf("Max Threads nums = %d in current parallel!\n",omp_get_max_threads());#pragma omp section{printf("section4 ThreadID = %d \n",omp_get_thread_num());}#pragma omp section{printf("section5 ThreadID = %d \n",omp_get_thread_num());}#pragma omp section{printf("section6 ThreadID = %d \n",omp_get_thread_num());}}return 0;
}运行结果:
section3 ThreadID = 6
section1 ThreadID = 4
section2 ThreadID = 2
section4 ThreadID = 2
section5 ThreadID = 7
section6 ThreadID = 1 这种方式和前面那种方式的区别是,这里有三个 sections 构造先后串行执行的,即第二个
sections 构造的代码要等第一个 sections 构造的代码执行完后才能执行。 sections 构造里面的各
个 section 部分代码是并行执行的。
与 for 制导指令一样,在 sections 的结束处有一个隐含的路障同步,没有其他说明的情况下,所有线程都必须到达该点才能往下运行。使用 section 指令时,需要注意的是这种方式需要保证各个 section 里的代码执行时间相差不大,否则某个 section 执行时间比其他 section 过长就造成了其它线程空闲等待的情况。用 for语句来分担任务时工作量由系统自动划分,只要每次循环间没有时间上的差距,那么分摊是比较均匀的,使用 section 来划分线程是一种手工划分工作量的方式,最终负载均衡的好坏得依赖于程序员。
2.5 single 制导指令
单线程执行 single 制导指令指定所包含的代码段只由一个线程执行,别的线程跳过这段代
码。如果没有 nowait 从句,所有线程在 single 制导指令结束处隐式同步点同步。如果 single
制导指令有 nowait 从句,则别的线程直接向下执行,不在隐式同步点等待;single 制导指令用
在一段只被单个线程执行的代码段之前,表示后面的代码段将被单线程执行,具体用法如下:
#pragma omp single [子句]例子:
#include <stdio.h>
#include "omp.h"int main()
{#pragma omp parallel num_threads(4){#pragma omp single{printf("A start threadID = %d \n",omp_get_thread_num());}printf("A parallel run threadID = %d \n",omp_get_thread_num());#pragma omp single{printf("A finished threadID = %d \n",omp_get_thread_num());}#pragma omp single nowait{printf("B start! threadID = %d \n",omp_get_thread_num());}printf("B parallel run threadID = %d \n",omp_get_thread_num()); }return 0;
}运行结果:
A start threadID = 0
A parallel run threadID = 3
A finished threadID = 3
A parallel run threadID = 1
A parallel run threadID = 0
A parallel run threadID = 2
B parallel run threadID = 1
B parallel run threadID = 3
B start! threadID = 0
B parallel run threadID = 0
B parallel run threadID = 2 从上面的结果可以看出,在并行域内有多个线程并发执行,因此“A/B的 parallel run”
将由 4 个线程并发执行,但是对于使用 single 语句制导的“A/B start”以及“A finished”的打印语句只有一个线程在执行。
另一种需要使用 single 制导指令的情况是为了减少并行域创建和撤销的开销,而将多个临
近的 parallel 并行域合并时。经过合并后,原来并行域之间的串行代码也将被并行执行,违反
了代码原来的目的,因此这部分代码可以用 single 指令加以约束只用一个线程来完成。
🌈我的分享也就到此结束啦🌈
如果我的分享也能对你有帮助,那就太好了!
若有不足,还请大家多多指正,我们一起学习交流!
📢未来的富豪们:点赞👍→收藏⭐→关注🔍,如果能评论下就太惊喜了!
感谢大家的观看和支持!最后,☺祝愿大家每天有钱赚!!!下一节将介绍OpenMP在同步、数据环境控制、SIMD方面的实战。









![[C#]C# OpenVINO部署yolov8图像分类模型](https://img-blog.csdnimg.cn/direct/34b8d5a956c6466782ce9b0b6d8f9f0a.jpeg)