在大语言模型(LLM)端侧部署上,基于 MNN 实现的 mnn-llm 项目已经展现出业界领先的性能,特别是在 ARM 架构的 CPU 上。目前利用 mnn-llm 的推理能力,qwen-1.8b在mnn-llm的驱动下能够在移动端达到端侧实时会话的能力,能够在较低内存(<2G)的情况下,做到快速响应。

背景
在大型语言模型(LLM)领域的迅猛发展背景下,开源社区已经孵化了众多优异的 LLM 模型。这些模型在自然语言处理的各个领域展现出了强大的能力,但同时也带来了一个挑战,即如何有效地将这些模型部署到端侧设备上。为此,原来只支持特定模型的 ChatGLM-MNN 项目已升级并更名为 mnn-llm,并集成到了MNN项目中;该项目支持多个目前主流的开源LLM模型的部署。与此同时,为了简化不同 LLM 模型向 ONNX 格式导出的流程,我们推出了 llm-export 项目。该项目为多种 LLM 模型提供了统一的导出方案,大大地降低了从预训练模型导出的复杂度。在本文中,我们将介绍LLM模型的导出与部署支持与MNN针对LLM端侧CPU推理的性能优化方案。
mnn-llm地址:https://github.com/wangzhaode/mnn-llm
llm-export地址:https://github.com/wangzhaode/llm-export

模型导出
在将深度学习模型从研究原型转换为实际可部署的产品时,模型导出阶段的顺畅与否对于整个工作流程至关重要。通常,这个过程涉及将模型从训练框架中导出到一个中间表示,如 ONNX(开放神经网络交换格式),然后再转换为目标部署框架——在本例中为 MNN格式。为了简化并标准化这一过程,我们开发了一个名为 llm-export 的工具。
llm-export 工具的核心思想在于对大型语言模型(LLM)进行了高度抽象,建立了一个统一化的导出框架。这个项目的目标是消除将各种 LLM 模型导出到 ONNX 格式的障碍,确保无论是何种架构的 LLM 都能通过一个清晰定义的接口进行处理。在 llm-export 中,我们定义了一套公用的导出逻辑,这意味着对于任何特定的 LLM,开发者只需实现模型的加载逻辑。这极大地减少了从多样化的训练环境向 ONNX 模型迁移的复杂性,并显著提高了整个导出过程的易用性。模型一旦被成功导出至 ONNX,即可利用现有的mnnconver工具转换到 MNN 格式,从而使用MNN完成llm模型的推理。
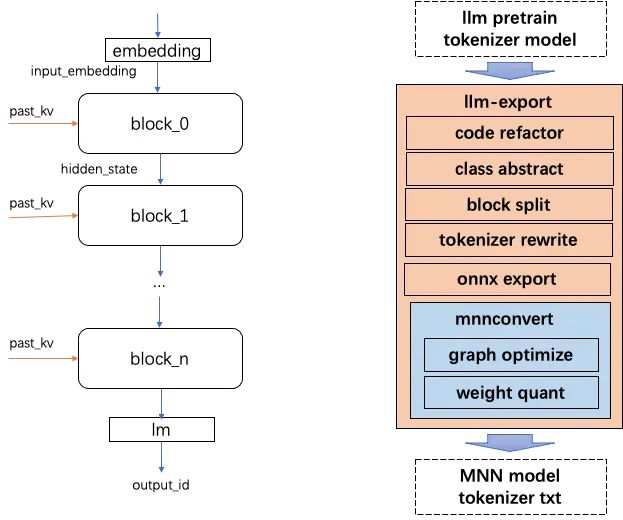
llm-export中将llm模型抽象为4部分:tokenizer, embedding, blocks, lm;主要代码如下:
class LLM(torch.nn.Module):def __init__(self, args):super().__init__()# load tokenizer, embed, blocks, lmself.load_model(args.path)def forward(self, input_ids, attention_mask, position_ids, past_key_values):hidden_states = self.embed(input_ids)presents = []for i in range(self.block_nums):hidden_states, kv = self.blocks[i](hidden_states, attention_mask,position_ids, past_key_values[i])presents.append(kv)token_id = self.lm(hidden_states).view(1)presents = torch.stack(presents)return token_id, presentsdef export(self):# export llm to onnx and mnn...class Chatglm2_6b(LLM):def load_model(self, model_path: str):# chatglm2 load impl...class Qwen_7b(LLM):def load_model(self, model_path: str):# qwen load impl...
模型部署
在部署大型语言模型(LLM)时,兼容性和易用性是关键因素。为了解决这一挑战,我们开发了一个名为 mnn-llm 的项目。考虑到MNN在跨平台上支持上的优秀表现,该项目基于 MNN 构建,旨在为各种平台提供一个统一的 LLM 模型部署解决方案。mnn-llm 项目使得从 llm-export 导出的模型能够无缝进行端到端的推理,并为开发者提供了一个简易的文本到文本(txt2txt)调用接口。
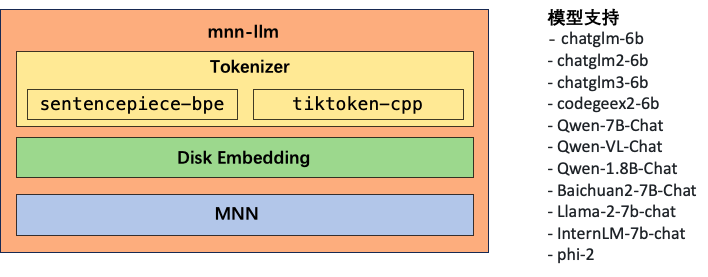
在mnn-llm中我们移植实现了目前主流的tokenizer工具:Sentencepiece 和 Tiktoken。这些 tokenizer 组件是处理自然语言输入的关键部分,它们能够将原始文本转换为模型能理解的格式。同时为了轻量化,两种模型都使用文本的方式存储,移除了Sentencepiece中迪对protobuf的依赖。此外,考虑到内存占用在移动设备上尤为宝贵,我们还在 mnn-llm 中引入了 disk embedding 功能。这意味着用户可以根据需要选择:在模型推理过程中使用 embedding 模型在内存计算,或者直接从磁盘加载 embedding 值。这种灵活性不仅降低了运行时的内存需求,也为用户提供了更多的选择来平衡推理性能和资源使用。为了确保 mnn-llm 的通用性和扩展性,我们设计了一种易于扩展的架构。开发者可以通过继承基类并实现特定的配置来支持不同的 LLM 模型。这种架构设计使得整合新的 LLM 模型变得简单快捷,大大降低了将最新的研究成果应用到实际产品中的门槛。

性能优化
▐ 性能分析
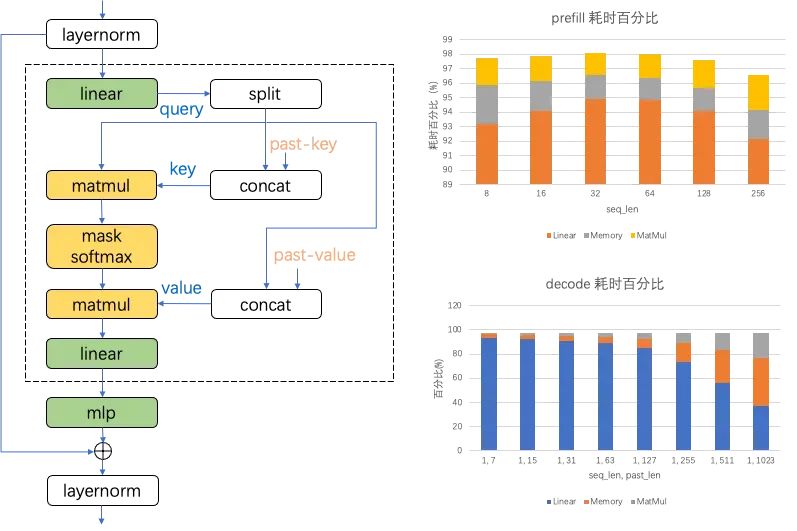
在深入研究大型语言模型(LLM)的性能时,理解主干网络的构成至关重要。LLM的主干网络由一系列连续的block组成,每个block的核心计算部分是Attention。如图所示,Attention的执行涉及到两个主要的计算操作:Linear(绿色表示)和MatMul(黄色表示)。这两种操作不仅要执行复杂的数学计算,还要伴随诸如split、concat和transpose等内存操作,这些统称为Memory算子。因此,我们可以将LLM模型推理过程中的核心操作分为三类:Linear, MatMul和Memory。
值得注意的是,这三类算子的计算量和内存访问量会受到输入数据的batch大小和kv-cache长度的影响。而根据batch和kv-cahce的输入特点,LLM推理可以被分为两个阶段:prefill和decode。在prefill阶段,我们输入了一个包含m个token的提示(prompt),执行batch为m的推理,此时由于是初始输入,没有kv-cache的需求,得到了首个token的输出。接着,在decode阶段,我们以上一轮的输出token作为输入,进行batch为1的推理,这时kv-cache的长度变为m+n,其中n代表之前已生成的token数量。
通过在ARM-CPU上的测试,我们可以详细分析在这两个阶段中上述三类核心算子的耗时情况。例如,单个block的耗时分析显示:
在prefill阶段,Linear算子的耗时占比相对稳定,超过了93%,而MatMul和Memory算子的耗时占比分别约为3%和2%;
在decode阶段,随着m+n的增长,Linear算子的时间占比有所下降,而MatMul和Memory算子的占比有所上升。尽管如此,在多数情况下,耗时主要集中在Linear算子上。
综合以上分析,我们决定将优化工作的重点放在Linear算子上。通过对Linear计算的深入优化,我们有望实现整个LLM推理过程的性能提升。这将是提高LLM整体推理效率的关键所在,尤其是在资源受限的设备上,每一次性能的增益都至关重要。
▐ 优化策略
在llm模型推理过程中,线性层(Linear layers)的计算效率对于整体性能至关重要。这个计算主要分为两个阶段:prefill阶段处理大量输入数据时,线性层是矩阵乘法(GEMM),这是一个计算密集的过程;在模型解码(decode)阶段时,线性层的计算是矩阵向量乘法(GEMV),这时候访存的效率变得更加关键。
为了优化这两个阶段的性能,我们采取了不同的技术策略:
对于计算密集型的优化:我们关注于使用更强大的计算指令,选择计算峰值更高的SIMD指令集来完成核心的计算,同时使用汇编实现多种规模的kernel,以此来加速矩阵乘法操作。
对于访存密集型的优化:我们的策略是通过降低数据的位宽来减少内存访问量(量化技术)和数据重排来实现。我们选择了 W4A8 的量化方案,即将模型中的权重(W)量化到 4 位,而将激活值(A,即模型的输入和输出)量化到 8 位。这样做可以大幅减少模型的内存占用,并提升性能,因为较低位宽的数据需要更少的内存带宽来读写;同时针对W4A8的量化方案按照设备支持的最优SIMD计算指令对数据进行特定的重排以提升内存局部性,提升访存效率。
在当今流行的大型语言模型(LLM)中,线性层的权重数量达到了惊人的规模,常常包含数十亿个参数。举个例子,一个70亿参数(7b)的模型,即使采用16位浮点(fp16)来存储,也需要约14GB的内存空间。这种规模的模型在内存受限的移动设备上部署是一大挑战。为了解决这个问题,我们必须采取措施来压缩这些权重,使它们占用更少的内存。量化技术为我们提供了一条可行之路。幸运的是,LLM中的线性层权重之间的差异相对较小,这使得它们非常适合进行低比特量化——即使用较少的比特表示每个权重值。即使经过量化,计算结果仍能保持与原始浮点计算高度一致,这表明量化对模型性能的影响很小。考虑到移动端设备的内存大小,我们选择了4位量化作为解决方案。通过这种方法,那个需要7b模型现在只需大约3.5GB内存即可运行。这意味着拥有8GB内存的设备也能够运行这样一个大模型。我们采用了非对称量化方案,具体的4位量化公式是:
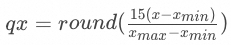
采用这种量化方法的一个巨大优势在于,计算过程中模型的权重访存量可以减少四倍,从而有效提高访存性能。
在量化权重的同时,我们也审视了模型输入的处理方式。过去,我们利用了混合精度计算,即结合了4位量化的权重与16位或32位浮点的输入。这要求我们在计算前将量化后的权重解量化为浮点数,同时从内存中加载浮点型的输入数据,接着进行浮点乘加运算。这种方法在处理输入时需要较多的内存访问,并且由于权重是以行优先的方式存储的,这进一步增加了内存访问量。另外,由于涉及浮点计算,它使用浮点型的SIMD指令,其峰值性能低于整数型指令。
为了应对这些问题,我们采取了针对输入的动态量化方案,即W4A8的量化方案。首先我们需要在运行时统计输入的分布情况,使用absmax-quant的方案将输入两位8bit整形作为线性性层的如数。然后我们将4bit量化的权重加载并转换为8位整数值,使用8位整数来完成矩阵乘的乘累加操作,使用32位整数来保存累加结果。最终,在整个计算过程结束后,我们会将这些累加结果反量化回浮点数。采用W4A8技术不仅显著降低了内存访问量,还使我们能够利用更高算力的整数计算指令,大幅提升了模型的计算性能。
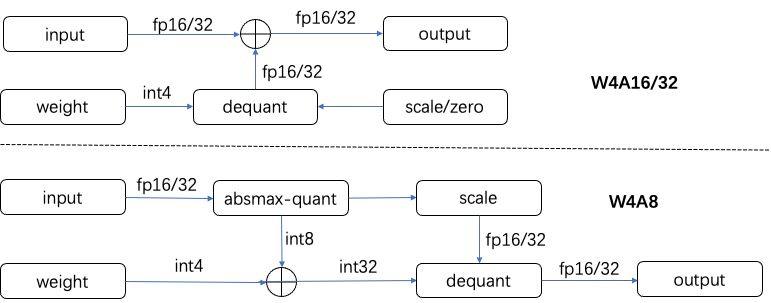
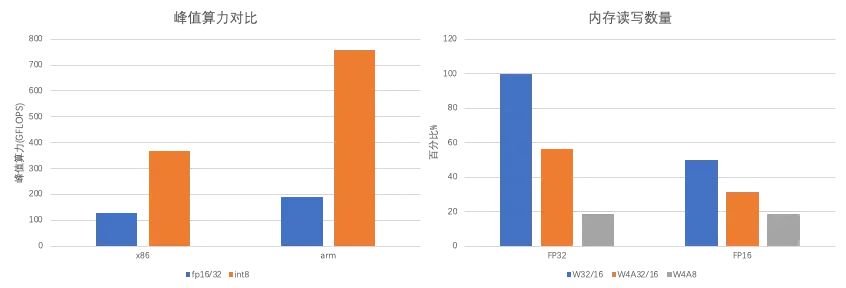
采用 W4A8 量化策略,我们能够在保持计算精度的同时显著提高模型的计算和内存访问效率。以往的实践中,W4A16或W4A32方案采用浮点运算,其中权重以int4存储,而输入数据保持16位或32位的浮点精度。在x86架构的系统中,此类浮点运算通常依赖于vfmadd132ps这类SIMD指令。相对地,当转向W4A8方案,即使用8位整数(int8)来执行计算,我们可以利用vpmaddubsw这类更高效的整数指令。在ARM架构的系统中,浮点计算使用fmla指令,而在采用8位整数计算时,可以使用如sdot或smmla的指令。性能测试显示,在x86平台上,vpmaddubsw的峰值性能几乎是vfmadd132ps的三倍。而在ARM平台上,smmla指令的峰值性能则是fmla的四倍。这一显著提升反映了通过优化指令选择可实现的算力增益。除了提升计算性能外,内存访问效率也是模型优化中不可或缺的一环。以一个具有4096x4096大小权重矩阵的广义矩阵向量乘法(GEMV)为例,我们将以传统的32位浮点(fp32)权重和输入数据的内存访问量作为基准。与此基准相比,W4A8方案明显减少了内存访问量,降幅超过五倍。即使与W4A16和W4A32方案相比,W4A8方案仍实现了两到三倍的访存量减少。
同时为了提升内存局部性,减少访存开销,我们结合W4A8的计算模式与设备支持的计算指令对输入和权重做了特定的数据重排。
具体来说,考虑到输入数据的形状通常为 [batch, ic],权重的形状为 [oc, ic],我们将这些数据重新排列为 [ic/pack, batch, pack] 和 [oc/pack, ic/pack, pack, pack]。这里的 "pack" 是一种按照硬件支持的计算指令精心选取的分块大小。例如,当系统支持 smmla 指令时,我们选择 pack = 8;而当系统支持 sdot 指令时,我们选择 pack = 4;当系统支持AVX2 时选择pack = 8;而当系统仅支持SSE 时,选择使pack = 4。这种重排策略使得计算核心(kernel)能够执行更为紧凑的矩阵乘法操作:[batch, pack] 与 [pack, pack] 的矩阵相乘,生成 [batch, pack] 的结果矩阵。我们进一步针对可用的寄存器数量,实现了针对 batch 维度的不同的计算Kernel,可以充分利用计算器来提升访存效率。在大型语言模型(LLM)的线性层中,输出通道的数量(oc)往往较大。这为我们提供了在 [oc/pack] 维度上执行多线程并行计算的机会,能够充分利用现代多核能力,提升多核性能。
以下是ARM上针对smmla 指令的矩阵乘kernel核心代码:
LoopSz_TILE_2:// src : 1 x [2 x 8] : v4// weight : 4 x [2 x 8] : v0-3// dst : 1 x 4 x [4] : v16-19ld1 {v0.16b, v1.16b}, [x25], #32 // weight// int4 to int8: v0, v1, v2, v3ushr v8.16b, v0.16b, #4and v9.16b, v0.16b, v14.16bsub v8.16b, v8.16b, v15.16bsub v9.16b, v9.16b, v15.16bushr v10.16b, v1.16b, #4and v11.16b, v1.16b, v14.16bsub v10.16b, v10.16b, v15.16bsub v11.16b, v11.16b, v15.16bzip1 v0.16b, v8.16b, v9.16bzip2 v1.16b, v8.16b, v9.16bzip1 v2.16b, v10.16b, v11.16bzip2 v3.16b, v10.16b, v11.16bld1 {v4.16b}, [x24], x15 // src.inst 0x4e80a490 // smmla v16.4s, v4.16b, v0.16b.inst 0x4e81a491 // smmla v17.4s, v4.16b, v1.16b.inst 0x4e82a492 // smmla v18.4s, v4.16b, v2.16b.inst 0x4e83a493 // smmla v19.4s, v4.16b, v3.16bsubs x26, x26, #1bne LoopSz_TILE_2
性能测试
测试模型主要选取1.8b, 6b与7b的模型,其中6b, 7b模型均使用4bit量化;1.8b模型分别测试了4bit和8bit量化。均使用CPU-4线程测试,android使用fp16, 其他平台使用fp32,具体测试环境如下:
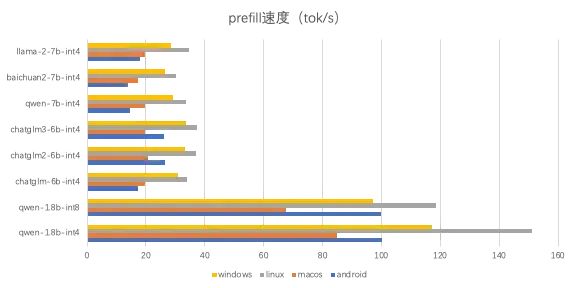
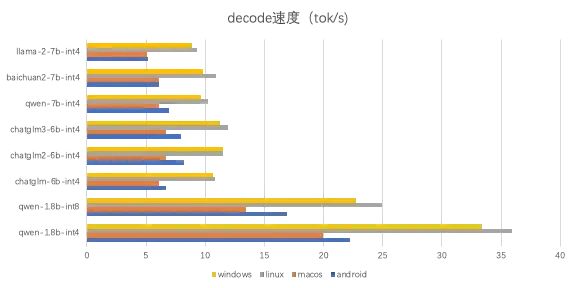
分别测试llm的prefill速度与decode速度,
prefill速度计算:输入token数目为m的prompt, 计算得到第一个输出token的时间为t1, 则prefill_speed = m / t1
decode速度计算:在输出第二个token开始直到结束输出token数为n, 耗时为t2, 则decode_speed = n / t2
各模型的速度如下图所示:
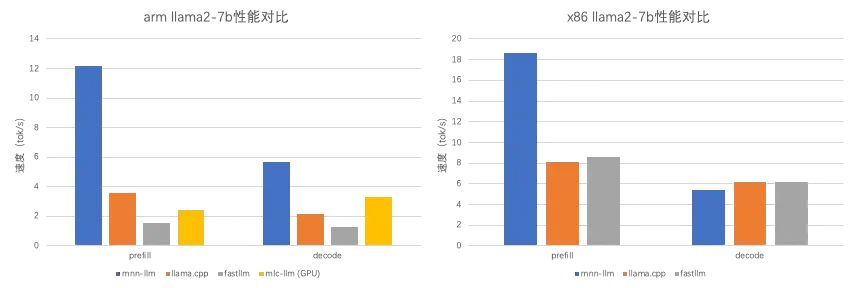
在CPU上选择了与llama.cpp和fastllm进行性能对比,模型选取3个框架都支持的llama2-7b,均采用4bit量化;输入采用fp32。测试结果表明在ARM CPU上mnn-llm的性能大幅领先;在x86上decode速度略慢,prefill速度有较大领先。同时我们选择了与编译方法实现的llm框架mlc-llm作对比,但是mlc-llm官方不支持CPU部署,因此我们对比了mlc-llm在相同的Android设备上的GPU性能。

总结与展望
在大语言模型(LLM)端侧部署上,基于 MNN 实现的 mnn-llm 项目已经展现出业界领先的性能,特别是在 ARM 架构的 CPU 上。目前利用 mnn-llm 的推理能力,qwen-1.8b在mnn-llm的驱动下能够在移动端达到端侧实时会话的能力,能够在较低内存(<2G)的情况下,做到快速响应,Android可以下载 qwen-1.8b-apk 来体验;iOS也可以编译mnn-llm-ios体验。然而,端侧部署 LLM 仍然面临着一系列挑战。尽管 qwen-1.8b 模型能在端侧设备上达到实用性能,但更大规模的模型如 6b 或 7b 仍然存在较高的部署门槛。这些模型往往要求更多的内存(~3GB)并且在处理较长文本(~ 100 token)时,很难在 1 秒内给出响应,这限制了其在实时应用场景下的可用性。此外,MNN在移动端 GPU 上的 LLM 推理性能尚未达到预期水平,目前正持续地在 GPU 性能上进行优化。
qwen-1.8b-apk地址:https://github.com/wangzhaode/mnn-llm/releases/tag/qwen-1.8b-apk

项目代码
https://github.com/alibaba/MNN/tree/master/llm
https://github.com/wangzhaode/llm-export
https://github.com/wangzhaode/mnn-llm

团队介绍
大淘宝技术Meta Team,负责面向消费场景的3D/XR基础技术建设和创新应用探索,通过技术和应用创新找到以手机及XR 新设备为载体的消费购物3D/XR新体验。团队在端智能、商品三维重建、3D引擎、XR引擎等方面有深厚的技术积累。先后发布端侧推理引擎MNN,端侧实时视觉算法库PixelAI,商品三维重建工具Object Drawer等技术。团队在OSDI、MLSys、CVPR、ICCV、NeurIPS、TPAMI等顶级学术会议和期刊上发表多篇论文。
本篇内容作者:雁行
¤ 拓展阅读 ¤
3DXR技术 | 终端技术 | 音视频技术
服务端技术 | 技术质量 | 数据算法