目录
🐶2.1 安装前准备
🥙1.设置系统最大文件打开句柄数 ==>启动一个程序的时候,打开文件的数量就是句柄数
🥙2.设置文件包含限制一个进程可以拥有的VMA(虚拟内存区域)的数量
🥙3.时钟同步
🥙4.关闭交换分区(swap)
🐶2.2 安装FE
🐶2.3 安装BE
🐶2.4 BE向FE注册
🐶2.5 扩容和缩容(搭建集群)
🥙2.5.1 doris集群的扩容
🥙2.5.2 缩容
🐶2.1 安装前准备
-
Linux 操作系统版本需求
| Linux 系统 | 版本 |
| CentOS | 7.1 及以上 |
| Ubuntu | 16.04 及以上 |
-
软件需求
| 软件 | 版本 |
| Java | 1.8 及以上 |
| GCC | 4.8.2 及以上 |
-
测试环境硬件配置需求
| 模块 | CPU | 内存 | 磁盘 | 网络 | 实例数量 |
| Frontend | 8核+ | 8GB+ | SSD 或 SATA,10GB+ * | 千兆网卡 | 1 |
| Backend | 8核+ | 16GB+ | SSD 或 SATA,50GB+ * | 千兆网卡 | 1-3 * |
-
生产环境硬件配置需求
| 模块 | CPU | 内存 | 磁盘 | 网络 | 实例数量(最低要求) |
| Frontend | 16核+ | 64GB+ | SSD 或 RAID 卡,100GB+ * | 万兆网卡 | 1-5 * |
| Backend | 16核+ | 64GB+ | SSD 或 SATA,100G+ * | 万兆网卡 | 10-100 * |
-
操作系统环境要求
🥙1.设置系统最大文件打开句柄数 ==>启动一个程序的时候,打开文件的数量就是句柄数
doris要求在linux上面只要要打开65536的句柄数,doris才能正常运行。而linux默认打开的句柄数为1000.所以需要修改。
1.打开文件
security /sɪˈkjʊərəti/
vi /etc/security/limits.conf
2.在文件最后添加下面几行信息(注意* 也要复制进去)* soft nofile 65536
* hard nofile 65536
* soft nproc 65536
* hard nproc 65536ulimit -n 65536 临时生效修改完文件后需要重新启动虚拟机,重启永久生效
reboot如果不修改这个句柄数大于等于60000,回头启动doris的be节点的时候就会报如下的错
如果报错:Please set the maximum number of open file descriptors to be 65536 using 'ulimit -n 65536'.
代表句柄数没有生效,需要临时设置或者重启电脑第一次启动的时候可能会报错
Please set vm.max_map_count to be 2000000 under root using 'sysctl -w vm.max_map_count=2000000'.
解决方案:
命令行输入:sysctl -w vm.max_map_count=2000000🥙2.设置文件包含限制一个进程可以拥有的VMA(虚拟内存区域)的数量
临时生效:
sysctl -w vm.max_map_count=2000000永久剩下
vi /etc/sysctl.conf
在文件最后一行添加
vm.max_map_count=2000000让他永久生效
sysctl -p检查是否生效
sysctl -a|grep vm.max_map_count🥙3.时钟同步
Doris 的元数据要求时间精度要小于5000ms,所以所有集群所有机器要进行时钟同步,避免因为时钟问题引发的元数据不一致导致服务出现异常。
如何时间同步??
首先安装 ntpdate
# ntpdate是一个向互联网上的时间服务器进行时间同步的软件
[root@doitedu01 doris]# yum install ntpdate -y然后开始三台机器自己同步时间[root@node01 ~]# ntpdate ntp.sjtu.edu.cn美国标准技术院时间服务器:time.nist.gov(192.43.244.18)
上海交通大学网络中心NTP服务器地址:ntp.sjtu.edu.cn(202.120.2.101)
中国国家授时中心服务器地址:cn.pool.ntp.org(210.72.145.44)# 将当前时间写入bios,这样才能永久生效不变,不然reboot后还会恢复到原来的时间
clock -w 🥙4.关闭交换分区(swap)
交换分区是linux用来当做虚拟内存用的磁盘分区;
linux可以把一块磁盘分区当做内存来使用(虚拟内存、交换分区);
Linux使用交换分区会给Doris带来很严重的性能问题,建议在安装之前禁用交换分区;
1、查看 Linux 当前 Swap 分区
free -m
2、关闭 Swap 分区
swapoff -a[root@doitedu01 app]# free -mtotal used free shared buff/cache available
Mem: 5840 997 4176 9 666 4604
Swap: 6015 0 6015
[root@doitedu01 app]# swapoff -a3.验证是否关闭成功
[root@doitedu01 app]# free -m total used free shared buff/cache available
Mem: 5840 933 4235 9 671 4667
Swap: 0 0 0注意事项:
-
FE 的磁盘空间主要用于存储元数据,包括日志和 image。通常从几百 MB 到几个GB 不等。
-
BE 的磁盘空间主要用于存放用户数据,总磁盘空间按用户总数据量* 3(3 副本)计算,然后再预留额外 40%的空间用作后台 compaction 以及一些中间数据的存放。
-
一台机器上可以部署多个 BE 实例,但是只能部署一个 FE。如果需要 3 副本数 据,那么至少需要 3 台机器各部署一个 BE 实例(而不是 1 台机器部署 3 个 BE 实例)。多 个 FE 所在服务器的时钟必须保持一致(允许最多 5 秒的时钟偏差)
-
测试环境也可以仅适用一个 BE 进行测试。实际生产环境,BE 实例数量直接决定了整体查询延迟。
-
所有部署节点关闭 Swap。
-
FE 节点数据至少为 1(1 个 Follower)。当部署 1 个 Follower 和 1 个 Observer 时,可以实现读高可用。当部署 3 个 Follower 时,可以实现读写高可用(HA)。
-
Follower 的数量必须为奇数,Observer 数量随意。
-
根据以往经验,当集群可用性要求很高时(比如提供在线业务),可以部署 3 个Follower 和 1-3 个 Observer。如果是离线业务,建议部署 1 个 Follower 和 1-3 个 Observer。
-
Broker 是用于访问外部数据源(如 HDFS)的进程。通常,在每台机器上部署一个 broker 实例即可。
🐶2.2 安装FE
-
去官网下载源码包,官网地址:https://doris.apache.org
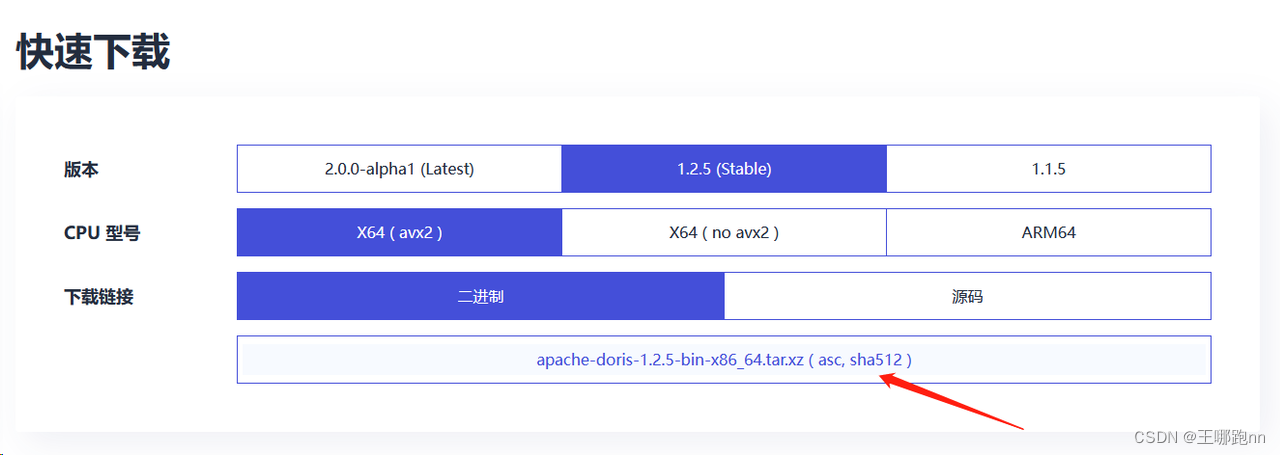
 根据自己的配置选择性点击下载
根据自己的配置选择性点击下载
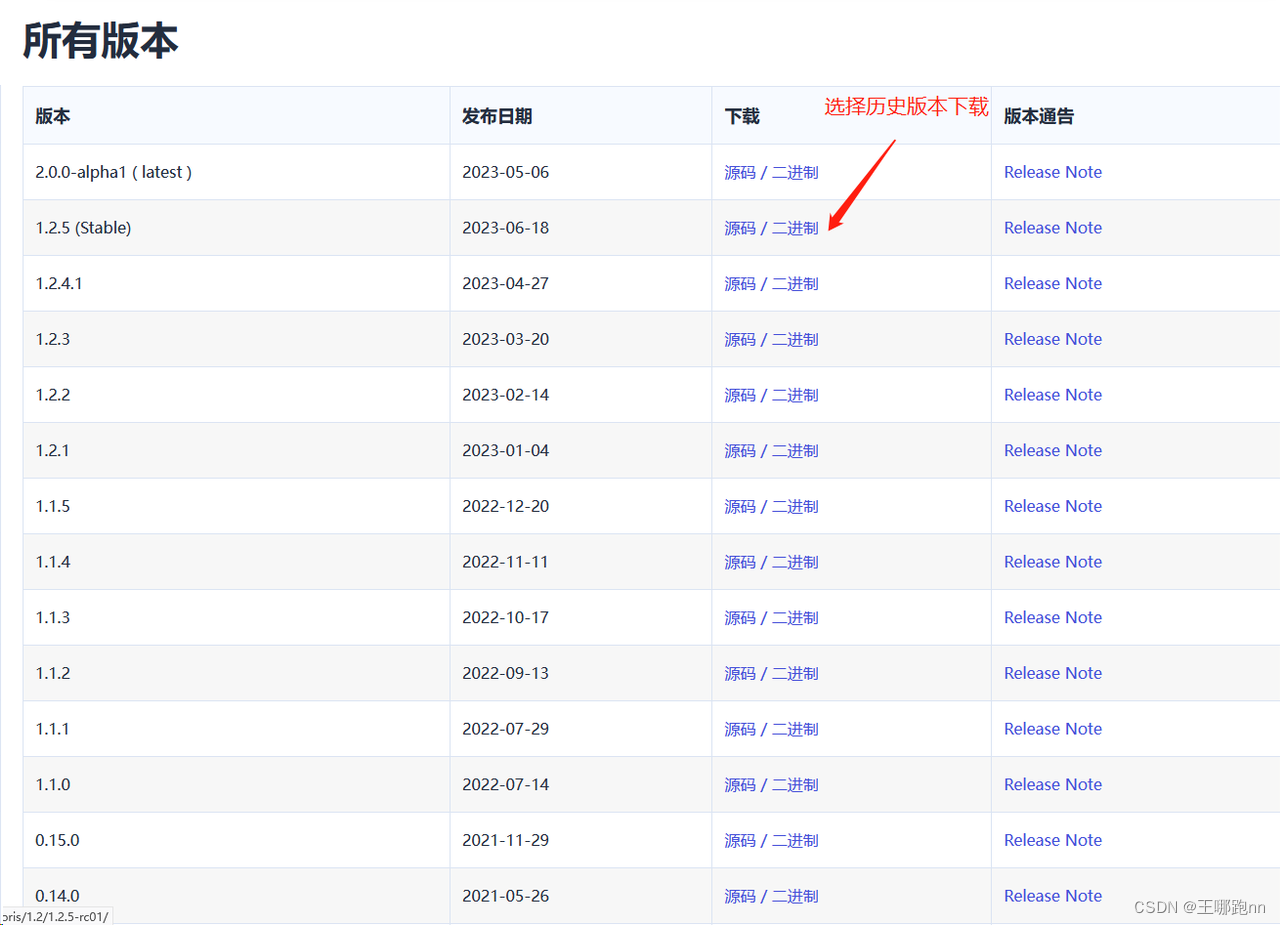
 当然你也可以选择历史版本下载
当然你也可以选择历史版本下载
2. 上传到linux
3. 解压
官网下载下来的是xz结尾的,所以解压需要用
tar -xvJf ***.tar.xz4.修改配置文件
-- 去自己的路径中找到fe.conf文件
vi /opt/app/doris1.2.5/fe/conf/fe.conf #配置文件中指定元数据路径: 注意这个文件夹要自己创建
meta_dir = /opt/data/doris/fe/doris-meta#修改绑定 ip(每台机器修改成自己的 ip)
priority_networks = 192.168.100.0/24 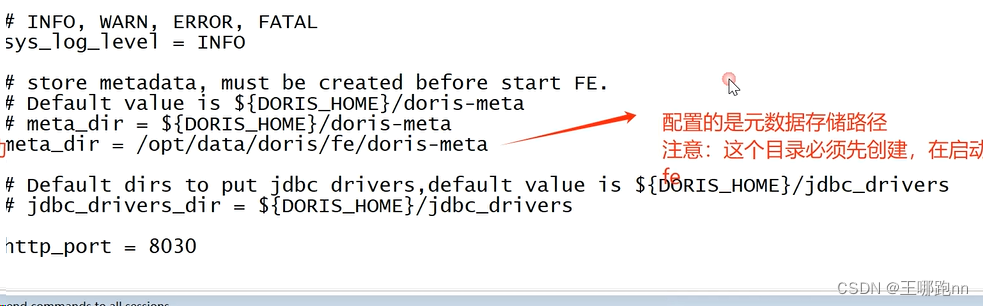
这个元数据的存放路径是在linux本地的
5. 添加环境变量
#doris_fe
export DORIS_FE_HOME=/opt/app/doris1.2.5/fe
export PATH=$PATH:$DORIS_FE_HOME/bin6. 分发集群
> scp /et/profile hadoop02:/etc/profile
> scp -r /opt/apps/doris1.2.5/ hadoop02:/opt/apps/doris1.2.5/> scp /et/profile hadoop03:/etc/profile
> scp -r /opt/apps/doris1.2.5/ hadoop03:/opt/apps/doris1.2.5/7. 启动
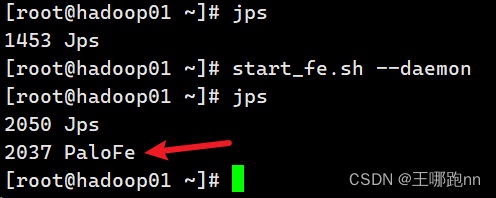
进入到fe的bin目录下执行
[root@doitedu01 bin]# ./start_fe.sh --daemon //该脚本以守护(daemon)模式运行8. 查看是否启动成功
jps结果:
9. 安装问题
问题:在这里我一开始只用./start_fe.sh 启动,进程一直结束不了。使用ctrl+C跳出后,进程也随之结束了。
原因这可能是因为在非守护(daemon)模式下,该命令在前台运行,占用了终端并阻塞了你的输入。通过使用 --daemon 参数,你将该命令转为在后台以守护进程的形式运行,不再与当前终端关联,因此可以正常结束终端而不影响该进程的运行。
生产环境强烈建议单独指定目录不要放在 Doris 安装目录下,最好是单独的磁盘(如果有 SSD 最好)。 如果机器有多个 ip, 比如内网外网, 虚拟机 docker 等, 需要进行 ip 绑定,才能正确识别。 JAVA_OPTS 默认 java 最大堆内存为 4GB,建议生产环境调整至 8G 以上。
🐶2.3 安装BE
1. 修改配置文件
 2. 进入到be的conf目录下修改配置文件
2. 进入到be的conf目录下修改配置文件

vi be.conf #配置文件中指定数据存放路径:
storage_root_path = /opt/data/doris/be/storage.HDD;/opt/data/doris/be/storage.SSD#修改绑定 ip(每台机器修改成自己的 ip)
priority_networks = 192.168.100.0/24 第一次启动的时候可能会报错
Please set vm.max_map_count to be 2000000 under root using 'sysctl -w vm.max_map_count=2000000'.
解决方案:
命令行输入:sysctl -w vm.max_map_count=2000000如果报错:Please set the maximum number of open file descriptors to be 65536 using 'ulimit -n 65536'.
硬盘驱动器(HDD)和固态硬盘(SSD)都是计算机存储设备,但它们在工作原理和性能方面有很大的不同。
HDD(Hard Disk Drive)硬盘驱动器:
工作原理: HDD使用旋转的磁盘(称为盘片)来存储数据。数据存储在盘片的表面,通过一个移动的读写头来读取或写入数据。这个读写头在盘片上移动,类似于唱片机的臂。
特点: 相对较便宜,容量大,适用于大量数据存储。但由于机械部件的存在,速度相对较慢,对冲击和振动敏感。
SSD(Solid State Drive)固态硬盘:
工作原理: SSD没有机械部件,而是使用闪存存储技术,类似于USB闪存驱动器。数据通过电子存储在芯片中,读写速度更快。
特点: 速度更快,对冲击和振动不敏感,能耐受更高的温度。相对较小轻便,省电。但价格相对较高,容量较小。
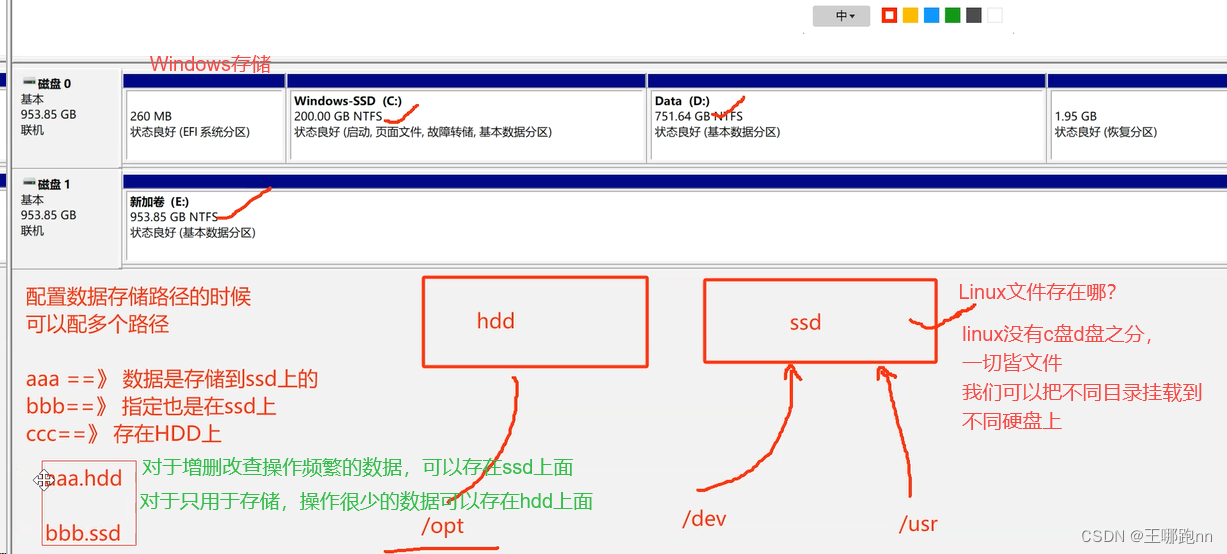
Doris不会检查到底是否挂载到hdd或者ssd上,它只会根据你创建的文件夹的后缀去判断是ssd还是hdd
一般我们电脑只有一个SSD硬盘,我们可以将storage.HDD和storage.SSD文件夹都挂载到SSD硬盘上。
2. 添加环境变量
#doris_be
export DORIS_BE_HOME=/opt/app/doris1.2.5/be
export PATH=$PATH:$DORIS_BE_HOME/bin3. 启动BE
启动 BE(每个节点)
/opt/app/doris/be/bin/start_be.sh --daemon 4. 尝试登录doris看看是否成功
启动后再次查看BE的节点
mysql -h doitedu01 -P 9030 -uroot -p 123456
mysql -uroot -p -P9030 -hhadoop01结果:

5. 尝试访问Web UI界面看看是否成功
主机名:8030(fe Web UI界面)
 主机名:8040(BE WEB UI界面)
主机名:8040(BE WEB UI界面)
6. 注意事项:
1)storage_root_path 默认在 be/storage 下,需要手动创建该目录。多个路径之间使用英文状
态的分号;分隔(最后一个目录后不要加)。
2)可以通过路径区别存储目录的介质,HDD 或 SSD。可以添加容量限制在每个路径的末
尾,通过英文状态逗号,隔开,如:
storage_root_path=/home/disk1/doris.HDD,50;/home/disk2/doris.SSD,10;/home/disk2/doris
3)说明:
/home/disk1/doris.HDD,50,表示存储限制为 50GB,HDD;
/home/disk2/doris.SSD,10,存储限制为 10GB,SSD;
/home/disk2/doris,存储限制为磁盘最大容量,默认为 HDD
🐶2.4 BE向FE注册
这样就好了嘛?不是哦
因为FE和BE两个都是单独的个体,所以他俩相互间还不认识,就需要我们通过mysql的客户端将他们建立起联系

show proc '/backends' \G; --以文本的形式展示所有的be节点
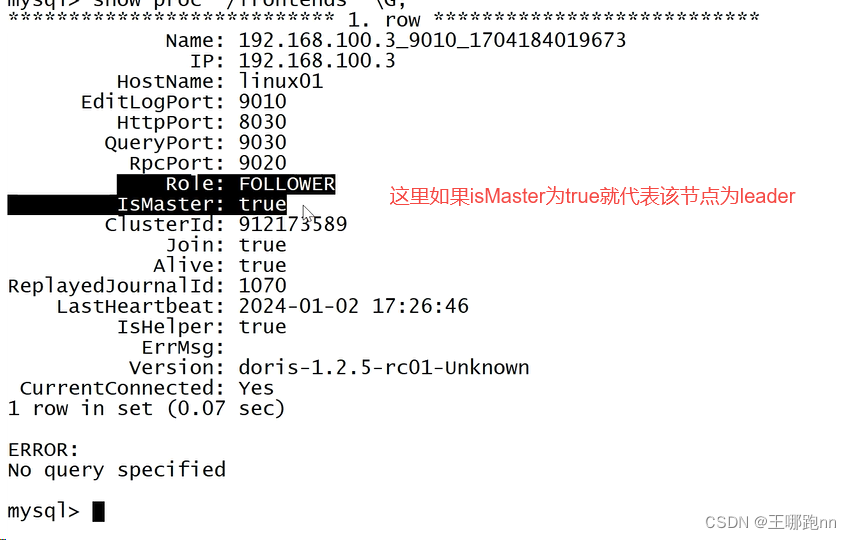
show proc '/frontends' \G; --以文本的形式展示所有的fe节点Alive so为 false 表示该 BE 节点还是死的
Alive 为 true 表示该 BE 节点存活。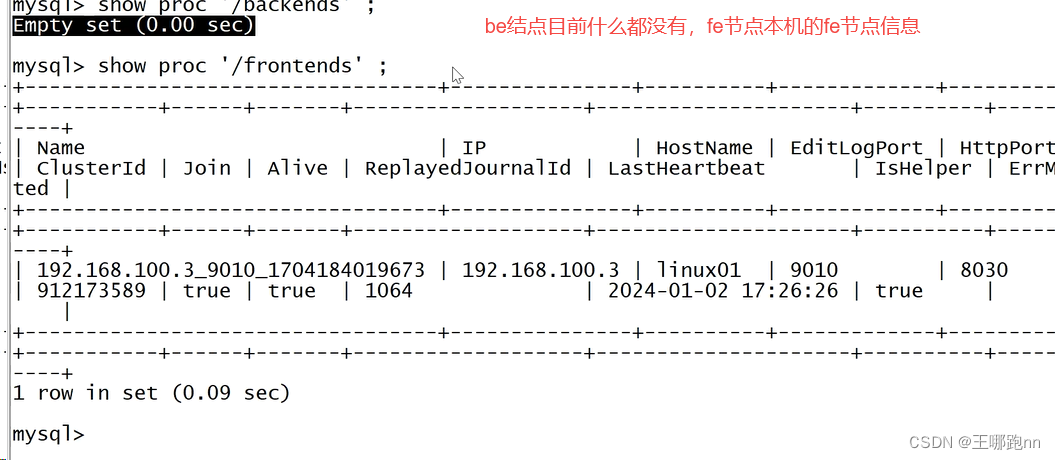
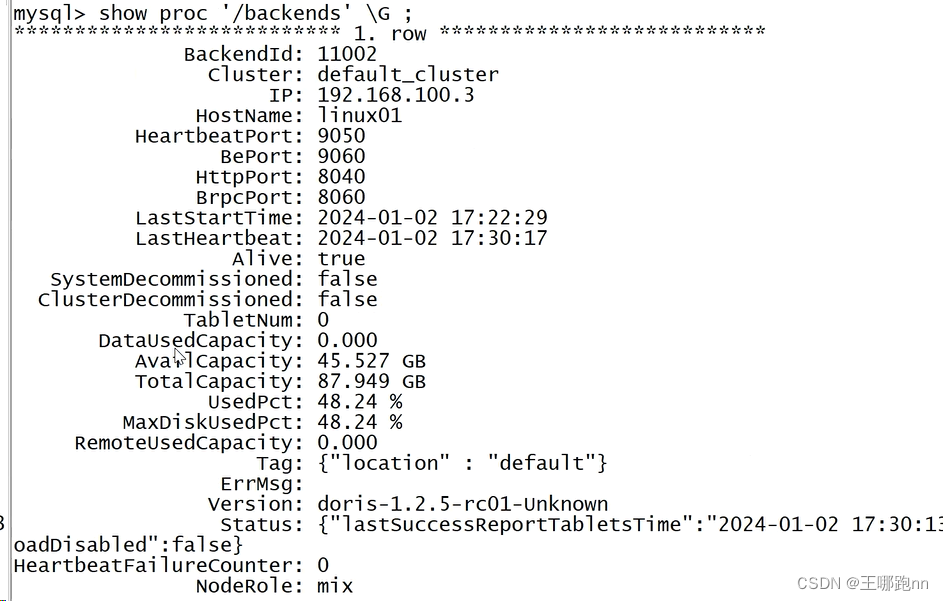
be和fe本身都是两个单独的后台服务进程需要将be向fe进行注册
alter system add backend 'hadoop01:9050';此时再次show backends,就可以看到信息了。
🐶2.5 扩容和缩容(搭建集群)
🥙2.5.1 doris集群的扩容
1)需要将linux01上面配好的doris文件分发到linux02和03两台机器上
2)--修改配置文件
- fe ip:192.168.100. ==》因为ip地址前24位是相同的所以,所以这里不需要修改
- 元数据存储的路径要改吗?==》要在linux02,linux03上创建一个空的文件夹
- be ip ==》因为ip地址前24位是相同的所以,所以这里不需要修改)
- 数据存储的路径要不要改 ==》 创建空文件夹

3)启动linux02和linux03上的fe和be
第一次启动fe的时候,需要加上一个参数 --helper linux01:9010
be不需要,只有fe需要
start_fe.sh --daemon --helper linux01:9010
start_be.sh --daemon
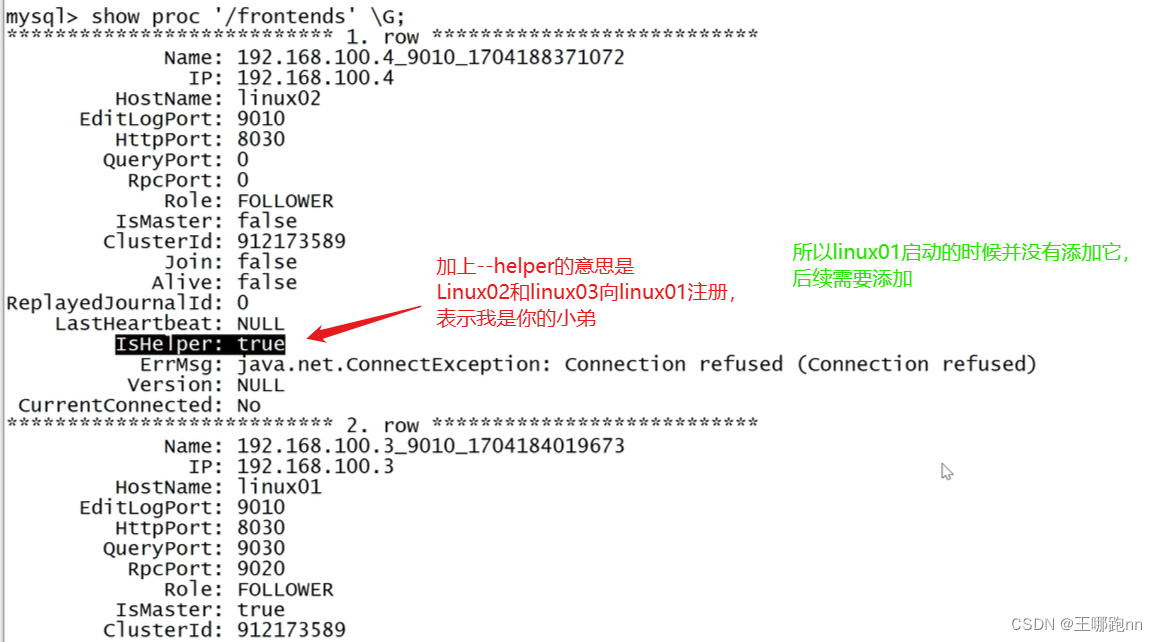
4)将02 和 03 上的fe和be启动起来之后
linux01上的fe认识这俩吗?
不认识,同理,linux02和linux03的fe及be节点也需要向linux01的fe节点报道,这样才能写进元数据。
alter system add backend 'linux02:9050';
alter system add backend 'linux03:9050';
alter system add follower 'linux03:9010';
alter system add follower 'linux02:9010';🥙2.5.2 doris集群的缩容
- FE
--先将该台机器的fe进程停掉
alter system drop follower/observer "doitedu01:9010"; 直接删除-
BE
--先将该台机器的be进程停掉
alter system drop backend "doitedu01:9050"; 直接删除,可能会造成数据的误删,丢失,不建议使用
alter system decommission backend "doitedu01:9050"; 先备份后删除该命令用于安全删除 BE 节点。命令下发后,Doris 会尝试将该 BE 上的数据向其 他 BE 节点迁移,当所有数据都迁移完成后,Doris 会自动删除该节点。