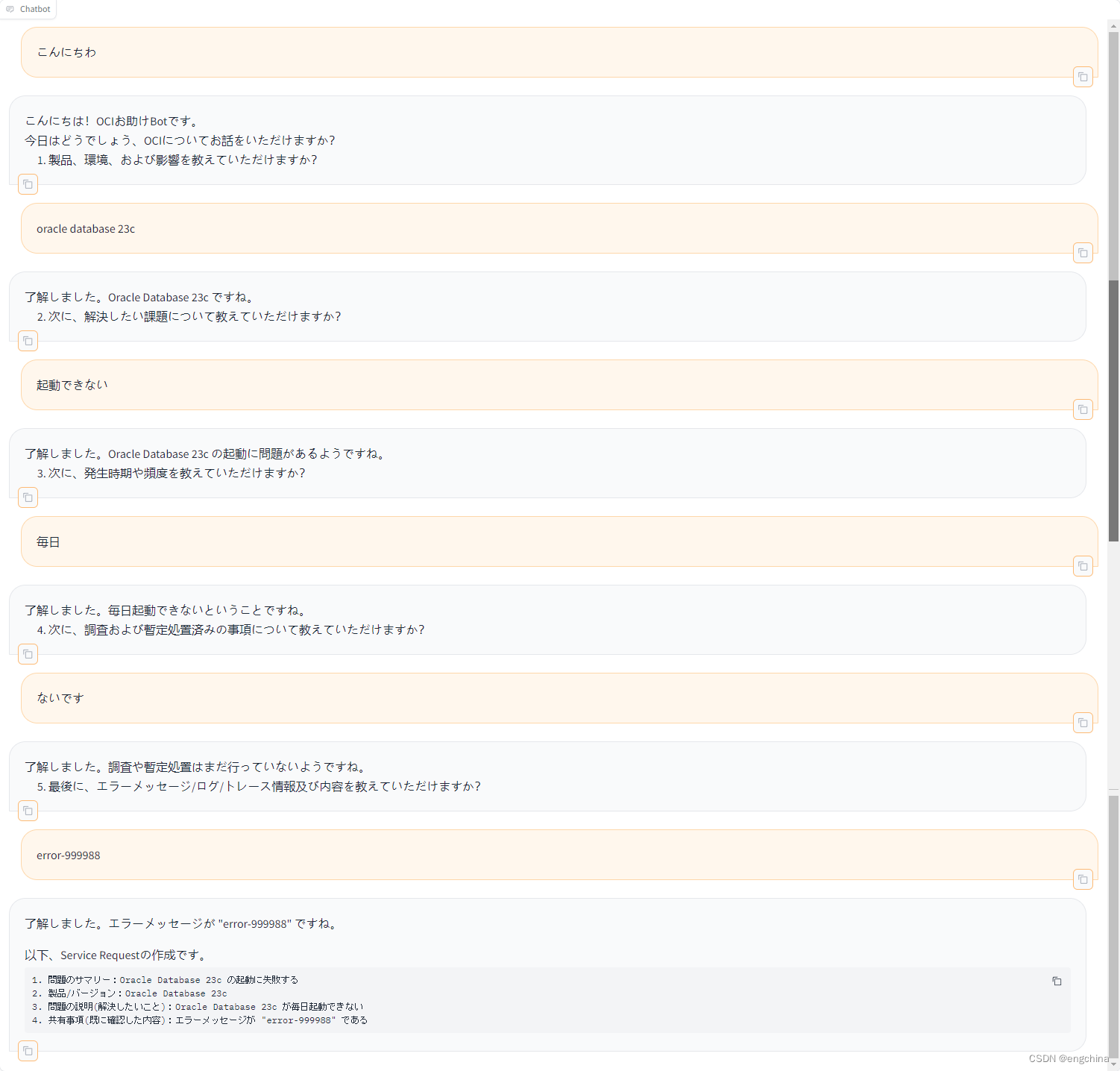
7-5 大師と仙人との奇遇 分数 20
#include<iostream>
#include<queue>
using namespace std;
int n;
long long ans=0,num;
priority_queue<long long,vector<long long>,greater<long long>>q;//记录之前买的,用小顶堆,最上面就是最小的
int main(){cin>>n;for(int i=1;i<=n;i++){cin>>num;while(!q.empty()&&q.top()<num){ans+=(num-q.top());q.pop();}//先卖掉之前的if(i!=n)q.push(num);}while(!q.empty()){ans+=(num-q.top());q.pop();}cout<<ans;return 0;
}采用优先队列,每天,输入一个数,然后检测之前买的股票能不能在今天卖出去,即堆顶元素和今天的比较,不过记得比较之前要保证队列不空,今天卖完后就把今天的股票买进队列里,最后一天不买
然后最后的时候把所以股票都卖掉
7-6 插入排序 分数 10
#include<iostream>
using namespace std;
int n,arr[101];
int main(){cin>>n;for(int i=0;i<n;i++)cin>>arr[i];for(int i=1;i<n;i++){//表示要插入的元素int j=i-1,temp=arr[i];while(j>=0&&arr[j]>temp){arr[j+1]=arr[j];j--;}arr[j+1]=temp;for(int k=0;k<n;k++){cout<<arr[k];if(k!=n-1)cout<<" ";}if(i!=n-1)cout<<endl;}return 0;
}调整牌堆时,是和插入的新牌比较,如果比它大,就把这张牌往后移,即arr[j+1]=arr[j]
while终止时,j=-1越界,或者指向第一个比他小的元素,这张牌是不应该在这里的,所以就放在后面即j+1的位置上
7-7 冒泡排序 分数 15
#include<iostream>
using namespace std;
int n,arr[101];
void swap(int i,int j){int temp=arr[j];arr[j]=arr[i];arr[i]=temp;
}int main(){cin>>n;for(int i=0;i<n;i++)cin>>arr[i];for(int i=n-1;i>0;i--){//表示冒泡的天花板bool flag=false;//每次都建立一个标志,标志是否从发生了交换,如果没有的话就说明已经排序完成for(int j=0;j<i;j++){//表示冒泡的起点,每次都是从最底端开始冒泡if(arr[j]>arr[j+1]){swap(j,j+1);flag=1;//发生了排序交换}}if(flag){for(int k=0;k<n;k++){cout<<arr[k];if(k!=n-1)cout<<" ";}//只有发生了改变才打印if(i!=1)cout<<endl;}else{break;//没有的话就直接退出}}return 0;
}冒泡排序的话,每次确定一个天花板,因为在冒泡的过程中,是最大的元素不断到最大的位置上,所以最大的位置就不用再逐一判断了
然后冒泡都是从最底端开始冒泡,遍历到此时的天花板上,由于这一特性,冒泡排序将会使每次循环都会交换元素,如果一旦有一次没交换元素,那就说明排序已经终止
这一点在插入排序中不适用
7-8 小球装箱游戏 分数 200
每个球箱的数量一样多,是严格的限制
那就是先排序,然后加入
#include<iostream>
#include<algorithm>
using namespace std;
int n,br=0,bg=0,tr=0,tg=0;
struct node{int num,type;
}arr[100005];
bool cmp(node a,node b){if(a.num!=b.num){return a.num<b.num;}else{return a.type>b.type;}
}
int main(){cin>>n;//for(int i=1;i<=n;i++){cin>>arr[i].num>>arr[i].type;if(arr[i].type){tg++;}else{tr++;}}sort(arr+1,arr+n+1,cmp);for(int i=1;i<=n/2;i++){if(arr[i].type){bg++;}else{br++;}}cout<<tr-br<<" "<<tg-bg<<endl;cout<<br<<" "<<bg;return 0;
}7-9 二路归并排序 分数 10
在归并中,先判断是不是为空(不存在),然后是不是递归底层(这里是不做处理,因为只有一个元素),接着就是做递归处理,处理完后进行操作,这个操作就是进行合并,即所谓分治法,向下递归是分,然后“治”,合并。
求叶子结点数量以及树的高度也都是分治的思路
处理到文件尾,就是在while里cin>>n
#include<iostream>
using namespace std;
int n,arr[101];
void merge(int begin,int end){if(begin>=end)return;int i=begin,j=begin,mid=(begin+end)>>1,k=mid+1;int temp[101];merge(begin,mid);merge(k,end);while(j<=mid&&k<=end){if(arr[j]<=arr[k]){temp[i++]=arr[j++];}else{temp[i++]=arr[k++];}}while(j<=mid){temp[i++]=arr[j++];}while(k<=end){temp[i++]=arr[k++];}for(int i=begin;i<=end;i++)arr[i]=temp[i];for(int i=0;i<n;i++){cout<<arr[i];if(i!=n-1)cout<<" ";}if(begin!=0||end!=n-1)cout<<endl;
}
int main(){while(cin>>n){for(int i=0;i<n;i++)cin>>arr[i];merge(0,n-1);cout<<endl;}return 0;
}还需要注意的是,递归过程的打印,递归处理是栈的过程,即先到后出,
即最上层的是最后打印的,所谓最后打印就是最后才会结束所有本层的递归语句,即最后是打印
检测是不是最上层,就是检测左右区间,只有左右都是端点,才是最上层,不然的话就分行
7-10 成绩排名 分数 50
注意sort函数是左闭右开的,即处理左边的元素(是处理的第一个元素),不处理右边的元素(是不处理的第一个元素)
#include<iostream>
#include<algorithm>
using namespace std;
int n;
struct node{int ch,math,id;
}arr[100005];
bool cmp(node a,node b){if(a.ch!=b.ch){return a.ch>b.ch;}else if(a.math!=b.math){return a.math>b.math;}else{return a.id<b.id;}
}
int main(){cin>>n;for(int i=1;i<=n;i++){cin>>arr[i].id>>arr[i].ch>>arr[i].math;}sort(arr+1,arr+n+1,cmp);for(int i=1;i<=n;i++)cout<<arr[i].id<<endl;return 0;
}7-11 根据后序序列和中序序列确定二叉树 分数 10
一种写法是递归函数参数是子树大小以及起点,另一种是参数是起点与终点
下面是起点与终点,有问题版
#include<iostream>
using namespace std;
int n,post[12],in[12];
struct node{int val;node*lchild,*rchild;node(int x):val(x),lchild(nullptr),rchild(nullptr){}
};
node* func(int pend,int pbegin,int iend,int ibegin){if(iend<ibegin)return nullptr;if(iend==ibegin){node* root=new node(in[iend]);return root;}int rindex;//根节点在中序的位置,同时也是左子树大小for(rindex=ibegin;rindex<=iend;rindex++){if(in[rindex]==post[pend]){break;}}node* root=new node(post[pend]);root->lchild=func(pbegin+rindex-1,pbegin,rindex-1,ibegin);root->rchild=func(pend-1,pbegin+rindex,iend,rindex+1);return root;
}
int h(node*root){if(!root)return 0;if(!root->lchild&&!root->rchild)return 1;return max(h(root->lchild),h(root->rchild))+1;
}
void pre(node*root){if(!root)return;cout<<root->val<<" ";pre(root->lchild);pre(root->rchild);
}
int main(){while(cin>>n){for(int i=1;i<=n;i++)cin>>post[i];for(int i=1;i<=n;i++)cin>>in[i];node*root=func(n,1,n,1);cout<<h(root)<<" ";pre(root);cout<<endl;}return 0;
}下面这个是没问题的,问题出在了,直接认为根节点在中序中的位置就是此时左子树的大小,实际上并不是,只有当此时中序起点为0时,这个下标才是此时左子树的大小,不然左子树大小就是根节点下标减去中序起点
#include<iostream>
using namespace std;
int n,post[12],in[12];
struct node{int val;node*lchild,*rchild;node(int x):val(x),lchild(nullptr),rchild(nullptr){}
};
node* func(int pend,int pbegin,int iend,int ibegin){if(iend<ibegin)return nullptr;if(iend==ibegin){node* root=new node(in[iend]);return root;}int rindex;//根节点在中序的位置for(rindex=ibegin;rindex<=iend;rindex++){if(in[rindex]==post[pend]){break;}}node* root=new node(post[pend]);int lsize=rindex-ibegin;root->lchild=func(pbegin+lsize-1,pbegin,rindex-1,ibegin);root->rchild=func(pend-1,pbegin+lsize,iend,rindex+1);return root;
}
int h(node*root){if(!root)return 0;if(!root->lchild&&!root->rchild)return 1;return max(h(root->lchild),h(root->rchild))+1;
}
void pre(node*root){if(!root)return;cout<<" "<<root->val;pre(root->lchild);pre(root->rchild);
}
int main(){while(cin>>n){for(int i=1;i<=n;i++)cin>>post[i];for(int i=1;i<=n;i++)cin>>in[i];node*root=func(n,1,n,1);cout<<h(root);pre(root);cout<<endl;}return 0;
}在递归中,依然是先判断空,然后判断递归底层,再就是递归处理部分
减法的理解
还有就是减法的细节,给定区间端点i,j的话,j-i是j和i之间的差距,可以看成j和i之间棍子的数量
另一种看法是i和j之间的端点数量,是只包含1个端点以及中间所有端点的数量
j-i+1是包含两个区间端点的
在这里,求左子树的大小,左端点是序列起点,右端点是根节点位置,显然左端点在左子树里,右端点不在左子树里,所以减法是左子树大小=根节点位置-序列起点,即只包含区间的一个端点的元素数量,即把根节点排除在外的区间元素数量,即左子树大小
然后是要去确定左右子树的后序中序的起点与终点,就是依据子树大小来确定判断,+1-1的细节靠子树大小去试
这里需要注意,递归参数是左右都闭的,也就是说左右是严格包含的,意思就是说这个划定好的端点结点是严格处于左右子树里的(依据左子树大小去判断具体下标),
此时通过左子树大小判断时,就要采用右端点-左端点+1,因为是严格包含在子树里的,所以左右端点都被包含![]()
上面的求法,思路是通过后序起点,然后利用左子树大小,使出来是这个数,
或者由上面减法的理解,左子树的大小也可以是左端点到根节点之间棍子的数量,而如果要定位到根节点的前一个结点,就只需要减少一个棍子,也就是p+l-1就代表右端点,p+l代表根节点位置,是第一个不在左子树里的元素的位置
即求size的大小是减法的元素数量只含一个端点的理解,求具体的下标是棍子间隔的理解
最后注意输出格式,如果不要每行末尾的空格,空格就改成这样输出
即先输出空格再输出元素就行
7-12 哈夫曼树 分数 25
相比于直接构造哈夫曼树以及获得哈夫曼编码还是弱了一点
#include<iostream>
#include<queue>
using namespace std;
priority_queue<int,vector<int>,greater<int>>q;
int n,num,ans=0;
int main(){cin>>n;for(int i=1;i<=n;i++){cin>>num;q.push(num);}while(q.size()>1){int num1=q.top();q.pop();int num2=q.top();q.pop();ans+=(num1+num2);q.push(num1+num2);}cout<<ans;return 0;
}思路还是优先队列,通过优先队列来完成有规则的递归,在处理过程中就进行了每步的ans+=,完成了对ans的修改,即同一份数据会在处理过程中不断的被加,如果够小的话,而不用建完树后再对它进行处理去求路径长度
7-13 堆的操作 分数 20
#include<iostream>
using namespace std;
int n,k,arr[1005],cnt=0,id,num,m;
void swap(int i,int j){int temp=arr[j];arr[j]=arr[i];arr[i]=temp;
}
void up(int index){int par=index/2;while(par>=1){if(arr[par]>arr[index]){swap(par,index);index=par;par=index/2;}else{break;}}
}
void down(int index){int lc=2*index;while(lc<=cnt){if(lc+1<=cnt){lc=arr[lc]<arr[lc+1]?lc:lc+1;}if(arr[index]>arr[lc]){swap(index,lc);index=lc;lc=index*2;}else{break;}}
}
void insert(int x){if(cnt>=n)return;arr[++cnt]=x;up(cnt);
}
void del(){swap(1,cnt--);down(1);
}
int main(){cin>>n>>k;for(int i=1;i<=k;i++){cin>>id;if(id==1){cin>>num;insert(num);}else{del();}for(int j=1;j<=cnt;j++){cout<<arr[j];if(j!= cnt)cout<<" ";}cout<<endl;}cin>>m;for(int i=1;i<=m;i++)cin>>arr[i];cnt=m;for(int i=m/2;i>=1;i--){down(i);}for(int i=1;i<=m;i++){cout<<arr[i];if(i!=m)cout<<" ";}return 0;
}上调操作

就是从当前的位置往上找,下标从1开始的话,父母结点就是index/2;
然后操作终止的条件就是没有父母结点,即往上就没有了,即par>=1,只要还有父母结点,就还可能继续操作;然后能够继续上调的标志就是父母比自己大(因为要小顶堆),那就交换,然后更新孩子与父母,继续向上调整,直到不能,或者 没有父母,自己就已经是最小的
下调操作

下调的话可能有两个路径,选那个最小的路径换上来,
能够继续操作的前提是存在孩子结点,首先左孩子是最小的,所以迭代是要让左孩子不越界,接着判断是否存在右孩子,如果存在的话判断出一个最小的,然后尝试与此时的父结点交换,如果能换的话,说明可以继续向下,更新父节点与孩子结点,不然就说明最小的孩子都比此时的父节点大,那么已经满足堆的要求了,就不用再调整了
插入与删除

在插入的时候有细节就是如果此时堆已经满了的话,就不继续插入,直接返回了,所以需要加一个判断是cnt>=n
如果可以继续插入,就在新位置上放入元素,然后尝试把这个元素往上调整即可
对于删除,是取出堆顶元素,然后就是要让最后的元素放在堆顶上,然后把这个元素往下调整即可
在插入删除时,都要记得对cnt进行相应的操作
然后是第二部分,快速建堆,此时输入m后记得要更新堆的大小为m,不更新的话保留的依然是上个堆的大小
朴素建堆就是插入一个就上移调整一个,快速建堆是先都放好,放好后再从最后一个非叶子结点开始调整,进行向下调整,往回往上走,这样的话到上面时,下面的都已经满足了堆的要求
即朴素建堆主要用上调,快速建堆主要用向下调整
7-14 堆的建立 分数 20
说的是调整已经存在的N个元素,所以采用快速建堆
#include<iostream>
using namespace std;
int n,arrmin[10005],arrmax[10005];
void swap(int&i,int&j){int temp=i;i=j;j=temp;
}
void downmin(int index){int c=index*2;while(c<=n){if(c+1<=n){c=arrmin[c]<arrmin[c+1]?c:c+1;}if(arrmin[index]>arrmin[c]){swap(arrmin[index],arrmin[c]);index=c;c=index*2;}else{break;}}
}
void downmax(int index){int c=index*2;while(c<=n){if(c+1<=n){c=arrmax[c]>arrmax[c+1]?c:c+1;}if(arrmax[index]<arrmax[c]){swap(arrmax[index],arrmax[c]);index=c;c=index*2;}else{break;}}
}
int main(){cin>>n;for(int i=1;i<=n;i++){cin>>arrmin[i];arrmax[i]=arrmin[i];}for(int i=n/2;i>=1;i--){downmin(i);downmax(i);}for(int i=1;i<=n;i++){cout<<arrmax[i];if(i!=n)cout<<" ";}cout<<endl;for(int i=1;i<=n;i++){cout<<arrmin[i];if(i!=n)cout<<" ";}return 0;
}7-15 折半(二分)查找 分数 20
#include<iostream>
#include<algorithm>
using namespace std;
int n,arr[100005],tar,l,r;
int search(int tar,int l,int r){if(l>r)return -1;int left=l,right=r,mid=(left+right)>>1;while(left<=right){//只要区间里还有元素就可以继续操作if(arr[mid]==tar){return mid;}else if(arr[mid]<tar){left=mid+1;}else{right=mid-1;}mid=(left+right)>>1;}return -1;
}
int main(){cin>>n;for(int i=0;i<n;i++){cin>>arr[i];}sort(arr,arr+n);cin>>n;for(int i=1;i<=n;i++){cin>>tar>>l>>r;cout<<search(tar,l,r)<<endl;}return 0;
}这个查找,先判断是不是空,即l>r,
然后在迭代中,判断能否继续操作,操作的前题是区间里还有元素,即left<=right,然后就是找
如果刚好就返回,小于目标值就往右找,大于目标值就往左找,
后面两种情况由于已经判断过了中间端点,所以在下一轮查找中直接舍弃掉,即查找的过程包含两个区间端点,
7-16 部落冲突 分数 40
去求每个坐标位置对应的左边的面积,然后去找一个与总面积的一半最接近的位置,而且还要满足左边的大于总的减去左边的,即左边和总的一半的差值必须不是负的,必须是0或者正
要求
#include<iostream>
#include<queue>
using namespace std;
struct node{int begin,end,h;
}arr[105];
struct cmp{bool operator()(node a,node b){return a.begin>b.begin;}
}
priority_queue<node,vector<node>,cmp>q;
int n,x,y,w,h,tot=0,maxx=0,minx=1e8;
int main(){cin>>n;for(int i=1;i<=n;i++){cin>>x>>y>>w>>h;arr[i].begin=x;//也就是说绿洲的终止点是在x+w,100处arr[i].end=x+w;//端点数量是w+1,但是长度是w,就是连接的棍子数量arr[i].h=h;maxx=max(maxx,arr[i].end);tot+=w*h;q.push(arr[i]);}for(int i=arr[i].begin;i<=maxx;i++){int cnt=0;while(q.top()<i){}}return 0;
}先按起点从小到大排,然后遍历每个绿洲,如果加上这个绿洲面积不比一般大,那就直接加,并直接下一个
上面的思路是类似于前缀和的,但是由于在输入的时候,左端点与右端点都不知道,所以就很难搞,
可解决
这里就是直接不预处理了,直接二分,在二分的过程中去计算
每次计算都遍历所有的部落,
时间复杂度应该是nlogm的一个级别
上面前缀和的话,每次输入就处理,处理的复杂度是nm差不多,再二分查找,是logm
好像还是在二分过程中去计算会好一点
这个之所以能直接二分,就是是左边累加,一直往右,就是左边面积是递增的,即使不处理也是这样,所以干脆就先不处理了,省去了处理的时间,而是只关注需要的,想要的点的信息,需要的时候就通过Get来计算得到
#include <iostream>
#include <vector>
#include <algorithm>
#include<stack>
#include<queue>
#include <unordered_set>
using namespace std;
#define ll long long
const int N = 105;
struct node {int l, r, w, h;
}s[N];
int n;
ll getd(int mid) {ll sl = 0, sr = 0;for (int i = 1; i <= n; i++) {if (s[i].r <= mid) {sl += (ll)s[i].w * s[i].h;}else if (s[i].l >= mid) {sr += (ll)s[i].w * s[i].h;}else {sl += (ll)s[i].h * (mid - s[i].l);sr += (ll)s[i].h * (s[i].r - mid);}}return sl - sr;
}
//就是说,地图上有很多块,然后划一条线,使这条线上所有左侧的块都归属于A
//剩下的都给B,然后要让A>>B
//自左到右,累积的岛屿面积是不断增加的
//也就是说每个x坐标轴都对应一个值,这个值就是自左到右的岛屿面积,类似于分布函数int main() {cin >> n;int R = 0, L = 1000;for (int i = 1; i <= n; i++) {int x, y, w, h;cin >> x >> y >> w >> h;s[i].l = x, s[i].r = x + w, s[i].w = w, s[i].h = h;R = max(R, s[i].r);L = min(L, s[i].l);}int ans = -1;ll da = 1e10;while (L <= R) {int mid = (L + R) >> 1;ll t = getd(mid);if (t < 0) {L = mid + 1;}else {da = min(da, t);R = mid - 1;ans = mid;}}// while (ans < R && getd(ans + 1) == da) {// ans++;//}cout << ans;return 0;
}#include<iostream>
#include<queue>
#include<algorithm>
using namespace std;
int n,x,y,w,h,l=1e8,r=0,ans;
struct node{int begin,end,h;long long s;
}arr[105];
long long tot=0;
long long gets(int index){long long sl=0;for(int i=1;i<=n;i++){if(arr[i].end<=index){sl+=arr[i].s;}else if(arr[i].begin<index){sl+=(long long)(index-arr[i].begin)*h;}}return sl*2-tot;
}
int main(){cin>>n;for(int i=1;i<=n;i++){cin>>x>>y>>w>>h;arr[i].begin=x,arr[i].end=x+w,arr[i].h=h,arr[i].s=w*h;l=min(l,x),r=max(r,x+w);tot+=arr[i].s;}while(l<=r){int mid=(l+r)>>1;long long ds=gets(mid);if(ds<0){l=mid+1;}else{r=mid-1;ans=mid;}}cout<<ans;return 0;
}#include<iostream>
#include<queue>
#include<algorithm>
using namespace std;
int n,x,y,w,h,l=1e8,r=0,ans;
struct node{int begin,end,h;long long s;
}arr[105];
long long gets(int index){long long sl=0,sr=0;for(int i=1;i<=n;i++){if(arr[i].end<=index){sl+=arr[i].s;}else if(arr[i].begin>=index){sr+=arr[i].s;}else{sl+=(long long)(index-arr[i].begin)*arr[i].h;sr+=(long long)(arr[i].end-index)*arr[i].h;}}return sl-sr;
}
int main(){cin>>n;for(int i=1;i<=n;i++){cin>>x>>y>>w>>h;arr[i].begin=x,arr[i].end=x+w,arr[i].h=h,arr[i].s=(long long)w*h;l=min(l,x),r=max(r,x+w);}while(l<=r){int mid=(l+r)>>1;long long ds=gets(mid);if(ds<0){l=mid+1;}else{r=mid-1;ans=mid;}}cout<<ans;return 0;
}经过排查发现,问题就出现在数据范围上,就是Longlong ,
首先一定要开long long, 然后涉及Longlong的数据类型,如果是从Int型转过来的,也一定要开Longlong
还有就是longlong*2容易直接爆掉,所以还得是缓行,不能随便的乘,容易爆
这也是(left+right)>>1和left+(right-left)>>1等价,但是保险写后面的原因,因为写前面的话,如果数据比较大,就会爆掉出错
总之,这题的思路就是记录范围的左边与右边,然后开始二分查找,使面积差最小,小于0是不能接收的,大于0的话,就尝试继续找,只要还能继续找,就有可能继续缩小这个差距,从而找到最小的面积差
7-17 判断是否二叉排序树 分数 10
#include<iostream>
#include<string>
using namespace std;string s;int index=0;
struct node{int val;node*lchild,*rchild;node(int x):val(x),lchild(nullptr),rchild(nullptr){}
};
node* cr(){if(index>=s.size())return nullptr;if(s[index]=='*')return nullptr;node* root=new node(s[index++]-'0');root->lchild=cr();root->rchild=cr();return root;
}
bool isbst(node*root){if(!root)return true;if(!root->rchild&&!root->lchild)return true;if(root->rchild&&root->val>root->rchild->val)return false;if(root->lchild&&root->val<root->lchild->val)return false;return isbst(root->rchild)&&isbst(root->lchild);
}
int main(){node*root;while(cin>>s){index=0;node*root=cr();if(isbst(root))cout<<"YES"<<endl;else cout<<"NO"<<endl;}return 0;
}主要是建树的细节 以及处理到文件尾的操作
采用输入string,然后对string做处理从而完成建树
这里需要注意,index表示跟踪现在这个字符串建树建到哪了,每建一个结点,index就往后移一位,表示此时的结点已经被建立了,由于给的是先序的字符串,所以是先建,再递归左右,
递归依旧是,判断是否为空,然后是否为底层,是否满足条件,然后递归处理,本层处理
在每次时,都要把index游标重新置0
至于BST的判断逻辑,就是是否为空,是否为底层,
再就是每层的判断以及向下递归的部分
每层判断,如果有右孩子且比它大就是错的;有左孩子比他小就是错的,其它都是正确的,就递归向下,保证子树也都是BST即可
7-18 整型关键字的散列映射 分数 25
#include<iostream>
using namespace std;
int n,p,arr[11000],num;
int main(){cin>>n>>p;for(int i=1;i<=n;i++){cin>>num;int index=num%p;if(!arr[index]){arr[index]=num;cout<<index;}else{while(arr[index]&&arr[index]!=num){index=(index+1)%p;}arr[index]=num;cout<<index;}if(i!=n)cout<<" ";}return 0;
}就是先计算一下对应的下标,然后计算一下对应的哈希值,如果对应位置没有,就插入,不然的话就进行冲突处理,进行线性冲突处理,然后注意存储范围是模p,即0~p-1,所以就是需要注意一下处理后的坐标在这个范围内,所以index=(index+1)%p;
还有需要注意的一点是,要加入的元素可能有重复的,这也就是说哈希表里不能存重复相同的元素,而arr[index]只能够判断当前格子有没有被占用,不能判断是否和此时要插入的元素相同,所以就是要新增一个判断arr[index]!=num才行,如果不满足这个的话,也会退出循环
即这个while出来的时候,要么是第一个还没被占用的格子,要么是第一个已经存储过的相同元素
7-19 数据结构实验三 图的深度优先搜索 分数 50
#include<iostream>
using namespace std;
int n,m,u,v,g[25][25],cnt=0;
bool vis[25]={0};
void dfs(int u){cout<<u<<" ";for(int i=0;i<n;i++){if(vis[i])continue;if(g[u][i]){vis[i]=1;dfs(i);}}
}
int main(){cin>>n>>m;for(int i=1;i<=m;i++){cin>>u>>v;g[u][v]=g[v][u]=1;}for(int i=0;i<n;i++){if(!vis[i]){vis[i]=1;cnt++;dfs(i);}}cout<<endl<<cnt<<endl<<m;return 0;
}用bool类型的vis记录每个结点的访问情况,如果访问过就不继续访问,不然的话就dfs它,下一层在它的基础上进行访问,邻接矩阵可以保证是字典序的访问顺序
在外层,用cnt去记录联通分支数
7-20 抓住那头牛 分数 25
#include<iostream>
#include<queue>
using namespace std;
int n,k,t;
bool vis[100005]={0};
queue<pair<int,int>>q;
int main(){cin>>n>>k;vis[n]=1;q.push({n,0});while(!q.empty()){int cur=q.front().first;t=q.front().second;q.pop();if(cur==k)break;if(cur*2<=100000&&!vis[cur*2]){q.push({cur*2,t+1});vis[cur*2]=1;}if(cur-1>=0&&!vis[cur-1]){q.push({cur-1,t+1});vis[cur-1]=1;}if(cur+1<=100000&&!vis[cur+1]){q.push({cur+1,t+1});vis[cur+1]=1;}}cout<<t;return 0;
}为了防止未访问的结点在同一层(上层)中处理后会发生重复入队的情况,所以就是在入队的时候就对vis做操作,而不是在出队处理时再更改vis操作,这样可以保证在上层有多个结点可到达下层同一结点时,会只入队一个结点,从而减少了时间的复杂度
另外就是注意入队时,对下标的控制,即在合法范围内,不会出界,在遍历的时候,即只有下个位置的坐标处于0和1E5之间才会被考虑,否则不入队,直到遍历BFS搜索到目标点
7-21 任务拓扑排序 分数 10
这里就是注意要是字典序
直接层序不行,用邻接矩阵也不行,因为在上层当中,如果有大编号结点的入度比较小,先被减为0了,同时存在小编号结点,同样在上层,但是是后续被减为0的,那么在下一层当中,就会优先去访问那个大编号结点,而不是小编号结点,从而打破了字典序
即建立在层序上的,不能保证为字典序
所以应该是要用优先队列,以小顶堆,编号最小建堆,这样无论是第几层解锁到的结点,都会被优先访问从而保证字典序
#include<iostream>
#include<queue>
using namespace std;
int n,e,in[105],g[105][105],u,v,ans[105],cnt=0;
priority_queue<int,vector<int>,greater<int>>q;
bool vis[105]={0};
int main(){cin>>n>>e;for(int i=0;i<n;i++)in[i]=0;for(int i=1;i<=e;i++){cin>>u>>v;g[u][v]=1;in[v]++;}for(int i=0;i<n;i++){if(!in[i]){q.push(i);vis[i]=1;}}while(!q.empty()){int cur=q.top();ans[++cnt]=cur;q.pop();for(int i=0;i<n;i++){if(g[cur][i]&&!vis[i]){in[i]--;if(!in[i]){vis[i]=1;q.push(i);}}}}if(cnt==n){for(int i=1;i<=n;i++)cout<<ans[i]<<" ";}else{cout<<"unworkable project";}return 0;
}7-22 信使 分数 100
堆优化
#include<iostream>
#include<queue>
using namespace std;
typedef pair<int,int> pii;
priority_queue<pii,vector<pii>,greater<pii>>q;
int n,m,cnt=0,u,v,w,dis[105],ans=-1,head[105];
bool vis[105];
struct edge{int v,next,w;
}e[1000005];
void add(int u,int v,int w){e[++cnt].v=v;e[cnt].w=w;e[cnt].next=head[u];head[u]=cnt;
}
int main(){cin>>n>>m;for(int i=1;i<=n;i++)dis[i]=1e8;for(int i=1;i<=m;i++){cin>>u>>v>>w;add(u,v,w);add(v,u,w);}vis[1]=1;for(int i=head[1];i;i=e[i].next){dis[e[i].v]=e[i].w;q.push({e[i].w,e[i].v});}while(!q.empty()){int tar=q.top().second,d=q.top().first;q.pop();if(vis[tar])continue;vis[tar]=1;for(int i=head[tar];i;i=e[i].next){if(dis[e[i].v]>d+e[i].w){dis[e[i].v]=d+e[i].w;q.push({d+e[i].w,e[i].v});}}}for(int i=1;i<=n;i++){ans=max(ans,dis[i]);}if(ans>=1e8){cout<<-1;}else cout<<ans;return 0;
}
这部分是链式前向星,注意cnt是边的编号,head记录该起点的第一个边的编号,然后每个边记录下一条边的编号![]()
接着是堆的定义,这里定义数对,gretaer优先判断第一个数,然后相同时再判断编号
就是第一个是距离,第二个是编号,记得typedef后面要加;
还有就是边,边的结构体数组要开大点
初始入队,
入队不会确定结点,只有从优先队列中取出元素时才会确定被访问过,也就是说,当一个结点被访问过时,队列中可能还会存在这个元素,
注意注意,这里vis放的位置和之前那个有所不同,之前那个7-20,是严格的层序,因为是要最早遇到,所以就要避免同一层上,重复的访问到某些结点,所以在第一次遇到的时候,就要vis,因为已经确定到可以访问了,即入队时就Vis
而至于这个有优先顺序的,只有在出队时才会被确定真正访问到,这里就是出队时才vis,这也是拓扑排序要字典序时,在出队时vis,而不是入队时Vis,如果是任意的随便都行
dis始终保持为此时最小的距离
7-23 校园最短路径 分数 10
#include<iostream>
#include<queue>
#include<string>
using namespace std;
typedef pair<int,int> pii;
priority_queue<pii,vector<pii>,greater<pii>>q;
int n,m,w,cnt=0,head[100],pre[100],dis[100];
bool vis[100]={0};
string s,s2;
struct node{int v,w,next;
}e[10000];
void add(int u,int v,int w){e[++cnt].v=v;e[cnt].w=w;e[cnt].next=head[u];head[u]=cnt;
}
void path(int index){if(pre[index]==-1){cout<<s[index];return;}path(pre[index]);cout<<"->"<<s[index];
}
int main(){cin>>n>>m>>s;for(int i=0;i<n;i++)dis[i]=1e8;for(int i=1;i<=m;i++){cin>>s2>>w;add(s.find(s2[0]),s.find(s2[1]),w);add(s.find(s2[1]),s.find(s2[0]),w);}vis[0]=1,dis[0]=0,pre[0]=-1;for(int i=head[0];i;i=e[i].next){dis[e[i].v]=e[i].w;q.push({e[i].w,e[i].v});}while(!q.empty()){int tar=q.top().second;q.pop();if(vis[tar])continue;vis[tar]=1;for(int i=head[tar];i;i=e[i].next){if(dis[e[i].v]>dis[tar]+e[i].w){dis[e[i].v]=dis[tar]+e[i].w;q.push({dis[e[i].v],e[i].v});pre[e[i].v]=tar;}}}for(int i=0;i<n;i++){if(dis[i]>=1e8){cout<<"dist[A]["<<s[i]<<"]="<<256<<endl;cout<<s[i]<<endl;}else{cout<<"dist[A]["<<s[i]<<"]="<<dis[i]<<endl;path(i);cout<<endl;}}return 0;
}7-24 最小生成树-kruskal算法 分数 15
#include<iostream>
#include<algorithm>
using namespace std;
struct edge{int u,v,w;
}e[405];
int n,m,fa[25];
int find(int x){if(fa[x]==x){return x;}fa[x]=find(fa[x]);return fa[x];
}
bool cmp(edge a, edge b){return a.w<b.w;
}
int main(){cin>>n>>m;for(int i=1;i<=n;i++)fa[i]=i;for(int i=1;i<=m;i++){cin>>e[i].u>>e[i].v>>e[i].w;}sort(e+1,e+m+1,cmp);for(int i=1;i<=m;i++){if(find(e[i].u)==find(e[i].v))continue;fa[find(e[i].u)]=find(e[i].v);cout<<min(e[i].u,e[i].v)<<","<<max(e[i].u,e[i].v)<<","<<e[i].w<<endl;}return 0;
}用并查集,合并的时候注意是合并根节点,其它就没什么了
7-1 冰雹猜想。 分数 10
#include<iostream>
using namespace std;
int n,cnt=0;
int main(){cin>>n;while(n!=1){cout<<n<<" ";if(!(n%2)){n=n/2;}else{n=n*3+1;}cnt++;}cout<<1<<endl<<"count = "<<cnt+1;return 0;
}这个题目有点问题,变化的次数输出要注意多1次
7-2 输入正整数n,打印图形。 分数 10
#include<iostream>
using namespace std;
int n;
int main(){cin>>n;for(int i=1;i<=n-1;i++){for(int j=1;j<=n-i;j++){cout<<" ";}for(int j=1;j<=2*i-1;j++){cout<<"*";}for(int j=1;j<=n-i;j++){cout<<" ";}cout<<endl;}for(int i=1;i<=2*n-1;i++)cout<<"*";cout<<endl;for(int i=n-1;i>=1;i--){for(int j=1;j<=n-i;j++){cout<<" ";}for(int j=1;j<=2*i-1;j++){cout<<"*";}for(int j=1;j<=n-i;j++){cout<<" ";}cout<<endl;}return 0;
}