简介:
我们都知道在数据比较少的情况下,我们是可以很轻易的获取到数据中的信息。但是当数据比较庞大的时候呢,我们就很难看出来了。尤其是面对现如今数以万计的数据,就更了。
不过好在我们可以通过计算机来帮我们进行分析,其中比较高效的手段便是数据可视化了。通过将数据进行可视化,我们可以让数据开口说话。进而有利于我们进行数据的分析,让我们可以更加快速的读懂数据。
回顾:
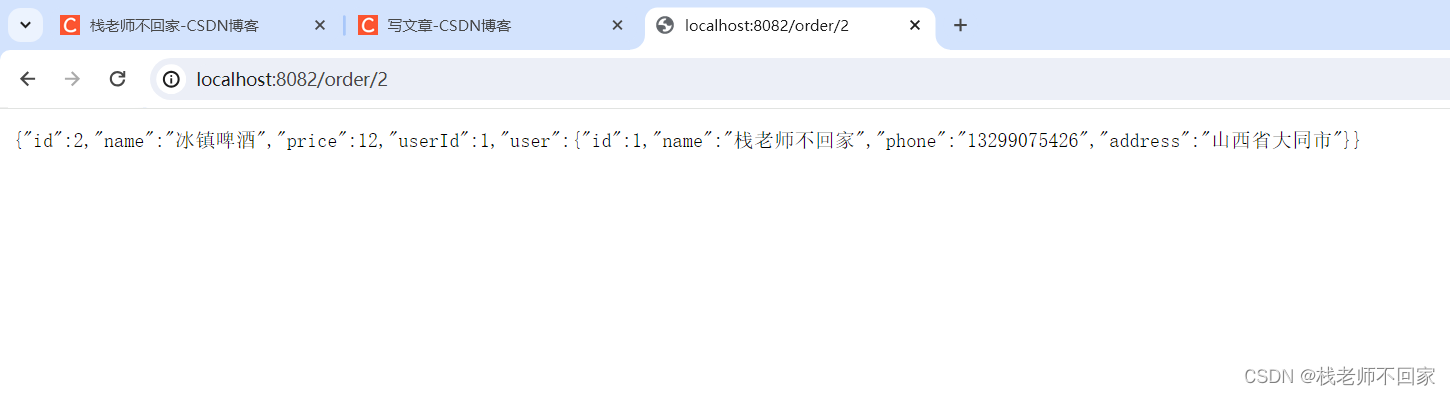
书接上回,咱们之前写了一个获取微博评论的爬虫。获取到的数据如下:
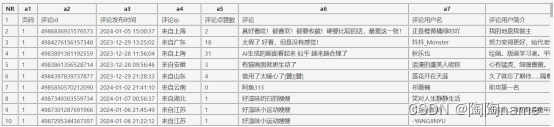
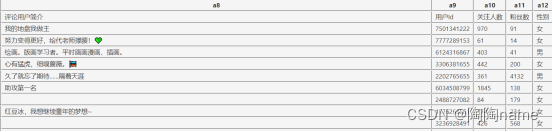
可以看到,上面的的数据其实凭借肉眼看的话很难看出来其中的规律。同时这些数据也是非常不直观的。那么我们就可以通过数据可视化的方式对这些数据进行可视化了。
下面是使用pyecharts对我们爬取到的数据进行可视化的效果。
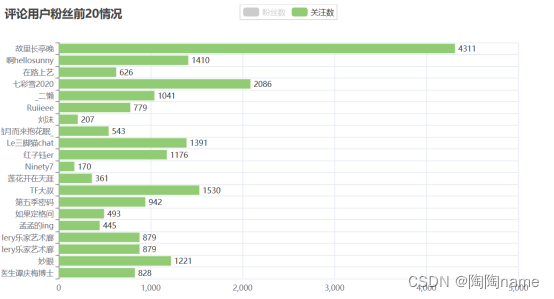
第一个是关于评论数据中粉丝较多的用户的粉丝数据
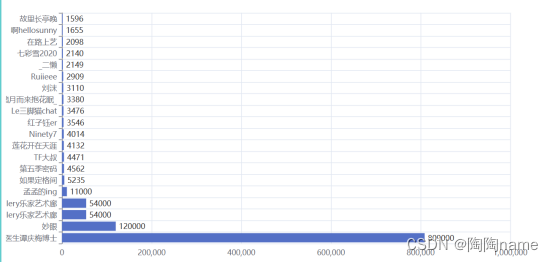
第二个是关于评论数据中粉丝较多的用户的关注数据
接下来呢就是对评论发布的地址进行可视化了,从图中可以考到哪个地方的人看评论的人数比较的多。具体效果可以看下面的视频。
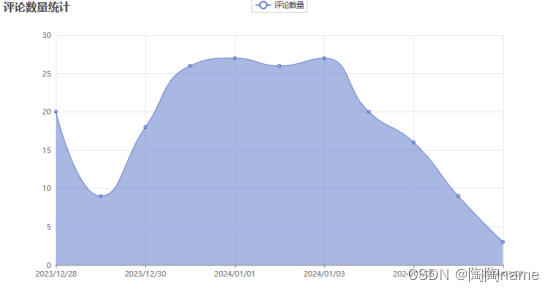
再者呢就是对时间进行统计了,就是看哪一个时间评论发布的最多
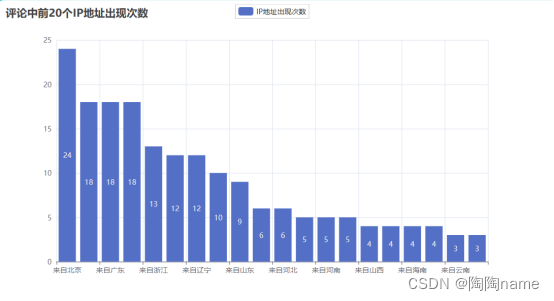
下面的这个表示的是关于所有评论中,地址中前20的ip地址出现次数。从这里可以看到,这条微博评论中北京的评论用户最多
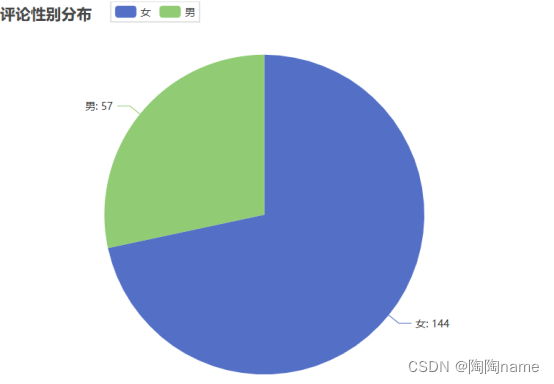
同时我们还可以对评论者的性别进行统计,下面是该微博评论中性别的分布情况
最后一个就是评论中用户的简介数据可视化,也就是说在这条微博中发布评论的用户的个性签名,然后对这些签名数据进行词云展示。

评论数据可视化视频介绍:
爬虫实战-微博评论可视化
以上就是本次分享的全部内容了。
源码获取,关注“陶陶name”,回复“数据可视化”即可无套路获取!
由于笔者能力有限,在问题表述方面可能有不准确的地方,还请多多包涵!!!