引言
上篇文章我们在单卡上完成了完整的训练过程。
从本文开始介绍模型训练/推理上的一些优化技巧,本文主要介绍多卡并行训练。
下篇文章将介绍大模型推理常用的缓存技术。
多卡训练
第一个要介绍的是利用多GPU优化,因为在单卡上训练实在是太慢。这里使用的是PyTorch提供的DistributedDataParallel。
还有一种简单的方法是DataParallel,但效率没有DistributedDataParallel高。
DistributedDataParallelis proven to be significantly faster thantorch.nn.DataParallelfor single-node multi-GPU data parallel training.
分布式数据并行训练(Distributed Data Parallel Training, DDP)是一种广泛采用的单程序多数据训练范式。使用DDP,模型在每个进程上都被复制,每个模型副本将被提供不同的输入数据样本。DDP负责梯度通信,以保持模型副本同步,并将其与梯度计算重叠,以加快训练速度。
如果想让你的单GPU训练代码可并行化,而且只想做最少的改动,那么你可以选择DataParallel,但正如上面所说,它的效率不高。因此我们使用DistributedDataParallel来进一步加速训练。
由于只有单机资源,因此本文不会涉及多机训练,只关注单机多GPU。
我们先了解下将涉及到的几个术语:
- 主节点(master node):负责同步、复制以及加载模型和记录日志的主GPU;
- 进程组(process group):要并行训练的N个GPU组成一个组,由nccl后端支持;
- 排名(rank):在进程组内,每个进程通过其排名进行标识,从0到N-1。rank=0为主节点;
- 世界大小(world size):进程组内的进程数量,即GPU数量N;
DistributedDataParallel通过在每个模型副本之间同步梯度来提供数据并行,要同步的设备由输入process_group指定,默认情况下是所有设备(entire world)。注意DistributedDataParallel需要由用户指定如何对参与的GPU进行分片,比如通过使用DistributedSampler对数据进行分片。也就是说假设有N个GPU,我们可以对数据切分成N部分,每个GPU只需要处理原来 1 N \frac{1}{N} N1大小的数量,但批大小可以保持不变,从而加速训练过程。
假设在一个包含N个GPU的设备上。

首先通过torch.distributed.init_process_group来创建进程组;
我们接着需要创建(spawn)N个进程,并且要确保每个进程独占从0到N-1的单个GPU,可以通过为每个进程设置torch.cuda.set_device(i)来实现。要创建进程可以通过torch.multiprocessing.spawn来实现;
torch.distributed.init_process_group(backend='nccl', world_size=N, init_method='...'
)
model = DistributedDataParallel(model, device_ids=[i], output_device=i)
DistributedDataParallel可以与 torch.distributed.optim.ZeroRedundancyOptimizer 结合使用,以减少每个rank上优化器状态的内存占用。
nccl 后端目前是使用 GPU 时最快且最受推荐的后端,适用于单节点和多节点分布式训练。
当模型在M个节点上以 batch=N进行训练时,如果损失在一个批次中的样本之间进行求和(而不是常用的平均),梯那度将比在单个节点上以 batch=M*N 进行训练的相同模型小 M 倍(因为不同节点之间的梯度是平均的)。
当想要获得与本地训练对应的数学等价训练过程时,你应该考虑这一点。但在大多数情况下,可以将一个 DistributedDataParallel 包装的模型和一个普通的单 GPU 上的模型视为相同的(例如,可以为同样的批大小使用同样的学习率)。
参数永远不会在进程之间广播。该模块(DistributedDataParallel)对梯度执行全局归约(all-reduce)步骤,并假定它们将以相同的方式被优化器在所有进程中修改。缓冲(如BatchNorm统计信息)从rank为 0 的进程开始,在每次迭代中对系统中的所有副本进行广播。
总结一下,我们要做的事情是:
- 设置进程组;
- 拆分进程组内的数据加载器;
- 通过DDP封装我们的模型;
- 训练/测试模型,与单GPU相同;
- 最后清理进程组,释放内存;
核心流程如下:
from argparse import ArgumentParserimport torch
import torch.distributed as dist
from torch.nn.parallel import DistributedDataParallel as DDP
from torch.utils.data import DataLoader, Dataset
from torch.utils.data.distributed import DistributedSamplerSEED = 42
BATCH_SIZE = 8
NUM_EPOCHS = 3class YourDataset(Dataset):def __init__(self):passdef main():parser = ArgumentParser('DDP usage example')parser.add_argument('--local_rank', type=int, default=-1, metavar='N', help='Local process rank.') # you need this argument in your scripts for DDP to workargs = parser.parse_args()# 记录当前进程是否为主节点args.is_master = args.local_rank == 0# 获取当期设备args.device = torch.cuda.device(args.local_rank)# 初始化进程组dist.init_process_group(backend='nccl', init_method='env://', world_size=N)# 设置GPU设备torch.cuda.set_device(args.local_rank)# 设置所有GPU的随机种子torch.cuda.manual_seed_all(SEED)# 初始化模型model = YourModel()# 将模型设置到GPUmodel = model.to(device)# 初始化DDPmodel = DDP(model,device_ids=[args.local_rank],output_device=args.local_rank)# 初始化数据集dataset = YourDataset()# 初始化分布式采样器sampler = DistributedSampler(dataset)# 基于分布式采样器初始化数据加载器dataloader = DataLoader(dataset=dataset,sampler=sampler,batch_size=BATCH_SIZE)# 开始训练for epoch in range(NUM_EPOCHS):model.train()# 在开始新epoch之前,让所有进程保持同步dist.barrier()for step, batch in enumerate(dataloader):# 将数据发送到对应的设备batch = tuple(t.to(args.device) for t in batch)# 正常的前向传播outputs = model(*batch)# 计算损失 假设是基于Transformers的模型,它会在第一个变量中返回损失loss = outputs[0]if __name__ == '__main__':main()
下面来对单GPU训练代码进行改造。
首先额外引入三个包:
from torch.nn.parallel import DistributedDataParallel as DDP
from torch.utils.data.distributed import DistributedSampler
import torch.multiprocessing as mp接着,定义一个函数用于初始化进程组:
def setup(rank: int, world_size: int) -> None:"""Args:rank (int): within the process group, each process is identified by its rank, from 0 to world_size - 1world_size (int): the number of processes in the group"""# Initialize the process group# world_size process forms a group which is supported by a backend(nccl)# rank 0 as master node# master node: the main gpu responsible for synchronizations, making copies, loading models, writing logs.dist.init_process_group("nccl", rank=rank, world_size=world_size)
同时定义清理函数:
def cleanup():"Cleans up the distributed environment"dist.destroy_process_group()
然后修改脚本入口代码:
if __name__ == "__main__":os.environ["CUDA_VISIBLE_DEVICES"] = ",".join(map(str, train_args.gpus))# Sets up the process group and configuration for PyTorch Distributed Data Parallelismos.environ["MASTER_ADDR"] = "localhost"os.environ["MASTER_PORT"] = "12355"world_size = min(torch.cuda.device_count(), len(train_args.gpus))print(f"Number of GPUs used: {world_size}")mp.spawn(main, args=(world_size,), nprocs=world_size)
通过CUDA_VISIBLE_DEVICES环境变量设置可见的GPU;设置Master地址和端口;
调用spawn方法来创建进行,它需要传入要使用的GPU总数量,假设为N,它会依次创建rank=0到N-1的进程。
那么我们就看这个main函数是如何定义的。
def main(rank, world_size):print(f"Running DDP on rank {rank}.")# 设置GPU设备torch.cuda.set_device(rank)setup(rank, world_size)# 加载分词器source_tokenizer, target_tokenizer = load_tokenizer(rank)# 设置随机种子set_random_seed(train_args.seed)# 获取训练集train_dataset = get_dataset(rank, source_tokenizer, target_tokenizer, "train")valid_dataset = get_dataset(rank, source_tokenizer, target_tokenizer, "dev")# 准备数据加载器train_dataloader = prepare_dataloader(train_dataset, rank, world_size, train_args.batch_size)valid_dataloader = prepare_dataloader(valid_dataset, rank, world_size, train_args.batch_size)# 定义模型并发送到设备rank上model = TranslationHead(model_args,target_tokenizer.pad_id(),target_tokenizer.bos_id(),target_tokenizer.eos_id(),).to(rank)# 是否为masteris_main_process = rank == 0# master负责打印if is_main_process:print(f"The model has {count_parameters(model)} trainable parameters")# 通过DDP封装modelmodel = DDP(model, device_ids=[rank])# 获取封装的modelmodule = model.module # the wrapped modelargs = asdict(model_args)args.update(asdict(train_args))if train_args.use_wandb and is_main_process:import wandb# start a new wandb run to track this scriptwandb.init(# set the wandb project where this run will be loggedproject="transformer",config=args,)train_criterion = LabelSmoothingLoss(train_args.label_smoothing, model_args.pad_idx)valid_criterion = LabelSmoothingLoss(pad_idx=model_args.pad_idx)optimizer = torch.optim.Adam(model.parameters(), betas=train_args.betas, eps=train_args.eps)scheduler = WarmupScheduler(optimizer,warmup_steps=train_args.warmup_steps,d_model=model_args.d_model,factor=train_args.warmup_factor,)if train_args.calc_bleu_during_train:# bleu scoreearly_stopper = EarlyStopper(mode="max", patience=train_args.patient)best_score = 0.0else:# dev lossearly_stopper = EarlyStopper(mode="min", patience=train_args.patient)best_score = 1000if is_main_process:print(f"begin train with arguments: {args}")print(f"total train steps: {len(train_dataloader) * train_args.num_epochs}")for epoch in range(train_args.num_epochs):# 记录训练时长start = time.time()# 每个数据加载器的sampler需要指定当前的epochtrain_dataloader.sampler.set_epoch(epoch)valid_dataloader.sampler.set_epoch(epoch)# 调用训练函数train_loss = train(model,train_dataloader,train_criterion,optimizer,train_args.grad_clipping,train_args.gradient_accumulation_steps,scheduler,rank,)if is_main_process:print()# 显示GPU利用率GPUtil.showUtilization()# 清除GPU缓存torch.cuda.empty_cache()if is_main_process:print("begin evaluate")valid_loss = evaluate(model, valid_dataloader, valid_criterion, rank)torch.cuda.empty_cache()if train_args.calc_bleu_during_train:if is_main_process:print("calculate bleu score for dev dataset")# 计算bleu得分valid_bleu_score = calculate_bleu(model.module,target_tokenizer,valid_dataloader,train_args.max_gen_len,rank,save_result=True,save_path="result-dev.txt",)torch.cuda.empty_cache()metric_score = valid_bleu_scoreelse:valid_bleu_score = 0metric_score = valid_losselapsed = time.time() - start# 每个GPU都打印信息print(f"[GPU{rank}] end of epoch {epoch+1:3d} [{elapsed:4.0f}s]| train loss: {train_loss:.4f} | valid loss: {valid_loss:.4f} | valid bleu_score {valid_bleu_score:.2f}")if is_main_process:if train_args.use_wandb:wandb.log({"train_loss": train_loss,"valid_bleu_score": valid_bleu_score,"valid_loss": valid_loss,})wandb.save(f"result-dev.txt")if train_args.calc_bleu_during_train:if metric_score > best_score:best_score = metric_scoreprint(f"Save model with best bleu score :{metric_score:.2f}")# 保存验证集上bleu得分最好的模型torch.save(module.state_dict(), train_args.model_save_path)else:if metric_score < best_score:best_score = metric_scoreprint(f"Save model with best valid loss :{metric_score:.4f}")torch.save(module.state_dict(), train_args.model_save_path)# 早停if early_stopper.step(metric_score):print(f"stop from early stopping.")break# 清理cleanup()
其中用到的一些函数定义如下。
准备数据加载器:
def prepare_dataloader(dataset, rank, world_size, batch_size, pin_memory=False, num_workers=0
):# 定义分布式采样器sampler = DistributedSampler(dataset, num_replicas=world_size, rank=rank, shuffle=False, drop_last=False)dataloader = DataLoader(dataset,batch_size=batch_size,pin_memory=pin_memory,num_workers=num_workers,collate_fn=dataset.collate_fn,drop_last=False,shuffle=False,sampler=sampler,)return dataloader
训练函数:
def train(model: nn.Module,data_loader: DataLoader,criterion: torch.nn.Module,optimizer: torch.optim.Optimizer,clip: float,gradient_accumulation_steps: int,scheduler: torch.optim.lr_scheduler._LRScheduler,rank: int,
) -> float:model.train() # train mode# let all processes sync up before starting with a new epoch of trainingdist.barrier()total_loss = 0.0tqdm_iter = tqdm(data_loader)for step, batch in enumerate(tqdm_iter, start=1):# 发送到指定设备source, target, labels = [x.to(rank) for x in (batch.source, batch.target, batch.labels)]logits = model(source, target)# loss calculationloss = criterion(logits, labels)loss.backward()# 支持梯度累积if step % gradient_accumulation_steps == 0:if clip:torch.nn.utils.clip_grad_norm_(model.parameters(), clip)optimizer.step()optimizer.zero_grad(set_to_none=True)scheduler.step()total_loss += loss.item()description = f"[GPU{rank}] TRAIN loss={loss.item():.6f}, learning rate={scheduler.get_last_lr()[0]:.7f}"del losstqdm_iter.set_description(description)# average training lossavg_loss = total_loss / len(data_loader)return avg_loss
主要修改差不多就完了,更详细的可以访问文末的仓库地址。
下面基于一个调好的配置训练一下,看下效果:
class TrainArugment:"""Create a 'data' directory and store the dataset under it"""dataset_path: str = f"{os.path.dirname(__file__)}/data/wmt"save_dir = f"{os.path.dirname(__file__)}/model_storage"src_tokenizer_file: str = f"{save_dir}/source.model"tgt_tokenizer_path: str = f"{save_dir}/target.model"model_save_path: str = f"{save_dir}/best_transformer.pt"dataframe_file: str = "dataframe.{}.pkl"use_dataframe_cache: bool = Truecuda: bool = Truenum_epochs: int = 40batch_size: int = 32gradient_accumulation_steps: int = 1grad_clipping: int = 0 # 0 dont use grad clipbetas: Tuple[float, float] = (0.9, 0.98)eps: float = 1e-9label_smoothing: float = 0warmup_steps: int = 4000warmup_factor: float = 0.5only_test: bool = Falsemax_gen_len: int = 60use_wandb: bool = Falsepatient: int = 5gpus = [1, 2, 3]seed = 12345calc_bleu_during_train: bool = True这里使用了3块RTX 3090GPU。
训练过程日志为:
Number of GPUs used: 3
Running DDP on rank 1.
Running DDP on rank 0.
source tokenizer size: 32000
target tokenizer size: 32000
Loads cached train dataframe.
Loads cached dev dataframe.
Loads cached test dataframe.
The model has 93255680 trainable parameters
begin train with arguments: {'d_model': 512, 'n_heads': 8, 'num_encoder_layers': 6, 'num_decoder_layers': 6, 'd_ff': 2048, 'dropout': 0.1, 'max_positions': 5000, 'source_vocab_size': 32000, 'target_vocab_size': 32000, 'pad_idx': 0, 'norm_first': True, 'dataset_path': 'nlp-in-action/transformers/transformer/data/wmt', 'src_tokenizer_file': 'nlp-in-action/transformers/transformer/model_storage/source.model', 'tgt_tokenizer_path': 'nlp-in-action/transformers/transformer/model_storage/target.model', 'model_save_path': 'nlp-in-action/transformers/transformer/model_storage/best_transformer.pt', 'dataframe_file': 'dataframe.{}.pkl', 'use_dataframe_cache': True, 'cuda': True, 'num_epochs': 40, 'batch_size': 32, 'gradient_accumulation_steps': 1, 'grad_clipping': 0, 'betas': (0.9, 0.98), 'eps': 1e-09, 'label_smoothing': 0, 'warmup_steps': 4000, 'warmup_factor': 0.5, 'only_test': False, 'max_gen_len': 60, 'use_wandb': True, 'patient': 5, 'calc_bleu_during_train': True}
total train steps: 73760
[GPU0] TRAIN loss=7.039197, learning rate=0.0001612: 100%|██████████| 1844/1844 [03:51<00:00, 7.98it/s]
[GPU1] TRAIN loss=7.088427, learning rate=0.0001612: 100%|██████████| 1844/1844 [03:58<00:00, 7.74it/s]0%| | 0/264 [00:00<?, ?it/s]
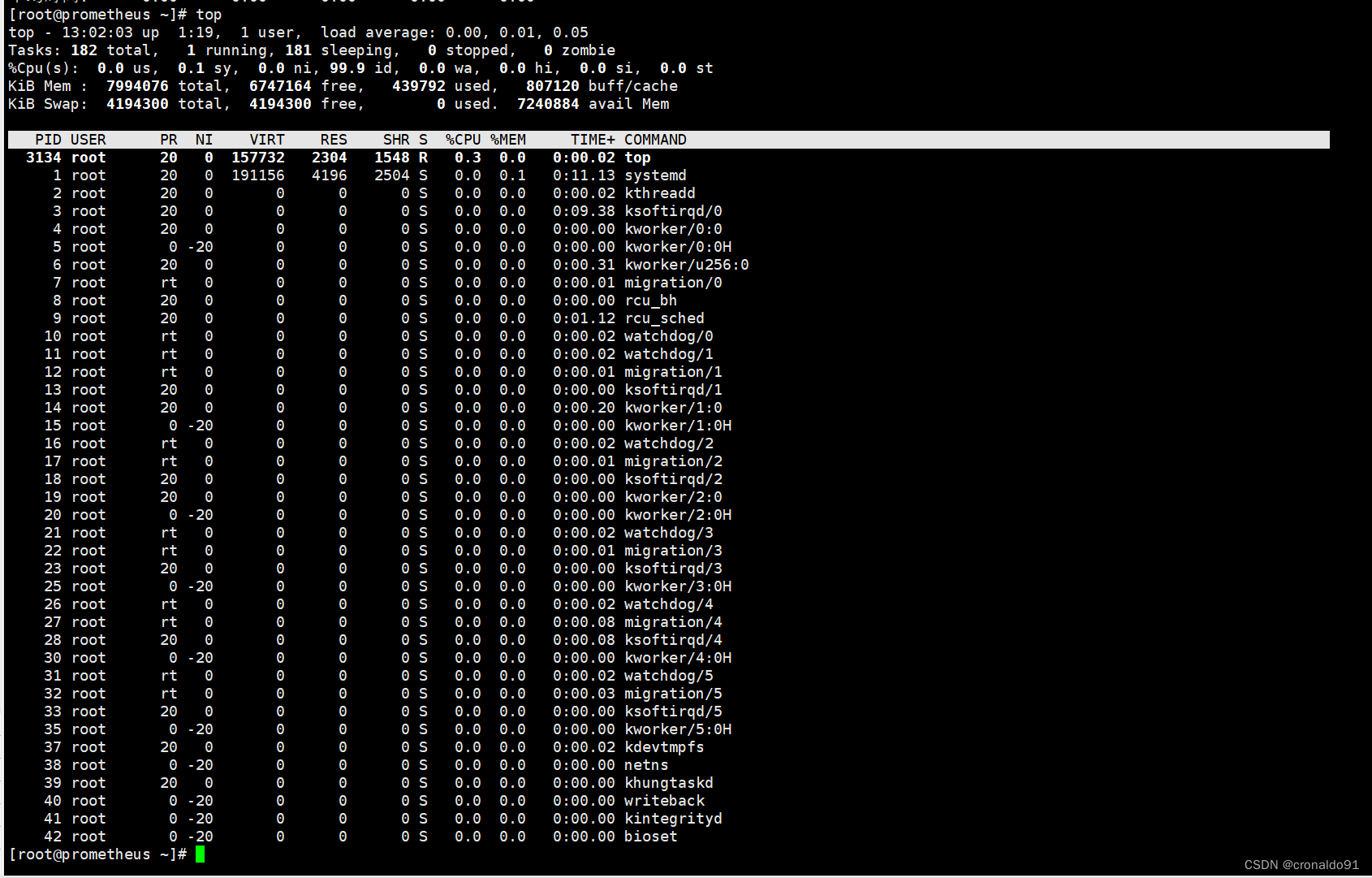
| ID | GPU | MEM |
------------------
| 0 | 1% | 22% |
| 1 | 82% | 80% |
| 2 | 96% | 74% |
| 3 | 88% | 75% |
begin evaluate
100%|██████████| 264/264 [00:06<00:00, 38.75it/s]
100%|██████████| 264/264 [00:06<00:00, 38.41it/s]
calculate bleu score for dev dataset
100%|██████████| 264/264 [00:07<00:00, 37.36it/s]
100%|██████████| 264/264 [03:28<00:00, 1.27it/s]98%|█████████▊| 260/264 [03:30<00:03, 1.24it/s][GPU1] end of epoch 1 [ 457s]| train loss: 8.0777 | valid loss: 7.1328 | valid bleu_score 0.44
100%|██████████| 264/264 [03:33<00:00, 1.23it/s]
100%|██████████| 264/264 [03:34<00:00, 1.23it/s]
[GPU2] end of epoch 1 [ 463s]| train loss: 8.0691 | valid loss: 7.1192 | valid bleu_score 0.470%| | 0/1844 [00:00<?, ?it/s][GPU0] end of epoch 1 [ 456s]| train loss: 8.0675 | valid loss: 7.1118 | valid bleu_score 0.42
Save model with best bleu score :0.42[GPU0] end of epoch 2 [ 429s]| train loss: 6.5028 | valid loss: 5.8428 | valid bleu_score 6.66
Save model with best bleu score :6.66[GPU0] end of epoch 3 [ 422s]| train loss: 5.2749 | valid loss: 4.6848 | valid bleu_score 16.72
Save model with best bleu score :16.72[GPU0] end of epoch 4 [ 430s]| train loss: 4.3027 | valid loss: 4.1180 | valid bleu_score 21.81
Save model with best bleu score :21.81...[GPU0] end of epoch 12 [ 415s]| train loss: 2.1461 | valid loss: 3.6046 | valid bleu_score 26.98
Save model with best bleu score :26.98[GPU0] end of epoch 17 [ 413s]| train loss: 1.6261 | valid loss: 3.7982 | valid bleu_score 26.19
[GPU0] stop from early stopping.wandb: | 3.412 MB of 3.412 MB uploaded
wandb: Run history:
wandb: train_loss █▆▅▄▃▃▃▂▂▂▂▂▁▁▁▁▁
wandb: valid_bleu_score ▁▃▅▇▇▇███████████
wandb: valid_loss █▆▃▂▂▁▁▁▁▁▁▁▁▁▁▁▁
wandb:
wandb: Run summary:
wandb: train_loss 1.62611
wandb: valid_bleu_score 26.19141
wandb: valid_loss 3.79825日志太多了,因此只摘录一部分,设置了随机种子,有条件的可以尝试复现。
从日志可以看到,在第12个epoch后就取得了验证集最佳得分26.98,并且每个epoch耗时从20分钟减少到了430秒,即7分钟左右, 基本上是减少了3倍,和GPU数量一致。
如果仔细分析每个epoch中耗时占比,会发现计算bleu得分和训练耗时和一样多,虽然我们已经对计算bleu得分进行批处理优化,但实际上我们还可以继续优化这个时间。
详见下篇文章~。
代码地址
完整代码点此