知乎:Verlocksss
编辑:马景锐
链接:https://zhuanlan.zhihu.com/p/675216281
1 学习动机
第一次了解到MoE(Mixture of experts),是在GPT-4模型架构泄漏事件,听说GPT-4的架构是8个GPT-3级别大小的模型以MoE架构(8*220B)组合成一个万亿参数级别的模型。不过在这之后开源社区并没有对MoE架构进行很多的探索,更多的工作还是聚焦在预训练新的大模型,在Llama 2或其他模型上做Fine-tune,以及扩展大模型的Context Length。
12月8号,Mistral突然在推特上发布了一条磁力链接,里面指向的是其最新的MoE模型Mixtral 8x7B。在其最新的Blog中[2],Mixtral 8x7B展现出了强大的能力,在多个指标上超越Llama 2,直指ChatGPT-3.5,而其推理时只需要消耗一个13B级别模型的计算量。我之前曾尝试过Mistral发布的Mistral 7B模型,这个模型被誉为最强7B模型,以7B的参数量超越了一众13B模型,如今发布的MoE模型又是一记重磅炸弹。
MoE架构的最大优势在于横向地拓展模型。MoE架构可以在目前已经非常巨大的模型上继续增加模型参数量,使模型的能力继续得到增强,同时,在推理时,可以通过Router只路由到比如8个Experts中的两个,显著降低推理成本。MoE面临的最大问题在于训练困难,训练的时候需要极力避免所有请求都被导向一两个Experts,导致其他Experts不被充分训练。从整体上,MoE非常有可能成为大模型接下来迭代的方向(毕竟GPT-4都已经用了)。
于是,我决定系统性地去学习MoE模型架构,以及该架构在如今大模型方向的发展现状。这篇文章将作为我学习过程的副产物,系统地总结我的学习内容和收获。
2 什么是MoE?
第一个需要解决的问题,是MoE是什么?总体而言,根据MoE的发展、应用场景和使用目的,其可以被分为两个阶段:Deep Learning时代开始前,和Deep Learning时代后,主要区别在于MoE是否被作用在神经网络模型之上。
2.1 Deep Learning时代前
在传统机器学习时期,MoE可以参考Ensemble技术进行理解。Ensemble技术统合多个模型的预测结果,并给出一个最终答案,比如如果是一个分类任务,Ensemble模型内可能包含20个独立的分类模型,每个模型都会根据输入返回一个分类预测结果,Ensemble模型最后使用比如Majority Vote得出最后的预测结果。与Ensemble一样,MoE会训练多个小模型并进行整合,但二者出发点不同:Ensemble统合所有小模型的意见,通过平均或Majority Vote给出综合的答案,目的是使模型更加General和Robust;MoE将每个任务分配给特定的小模型,每个小模型都是解决某些特定问题的Expert,而MoE将会通过weight function计算一个权重来将任务给到具体的模型来解决问题,将一个大的问题空间拆分成小的子空间交由不同Expert解决。
用数学表达式对MoE进行的定义如下[1]:
定义n个experts ,每个expert接受输入x,返回结果 。
一个weight function(即gating function)w,接受输入x,返回结果。
参数 ,其中是w的参数,是 的参数。
对于给定的输入x,MoE根据和,根据特定规则给出一个输出结果,一般而言是加权平均。
此时的MoE还只是一种特殊的机器学习模型,从以上的定义可以看出MoE模型具有很强的设计自由度,Wiki[1]上也介绍了不少变体,但这些与目前大模型使用MoE的出发点无关,所以也不再深入探索。
2.2 Deep Learning时代
在深度学习时代,MoE被应用在神经网络中,用来实现在推理时,只有部分神经网络需要进行计算,而被选择进行计算的部分则根据输入决定。
2.2.1 Deep Mixture of Experts
第一篇提出在神经网络中应用MoE的是在13年12月发表的 Learning Factored Representations in a Deep Mixture of Experts[3]。
在这之前,MoE更多被使用在传统机器学习模型中,这篇文章提出一种新方法,可以在神经网络的每一层之上平行地拓展多个experts,每个expert有其各自的权重矩阵(结构一致,数值不同),然后由一个gating network为多个experts分配权重。简单理解,可以将网络每一层的输入,视为之前章节中提到的输入x;神经网络当前层包含数个权重矩阵,在这篇文章中是一个Linear Layer + Activation,视为一个 ,在设计中,的区别在于权重矩阵的参数不同;w是一个独立的gating network,文章中是一个两层Linear Layer的神经网络,接受输入x,输出分配给每个expert的权重 。神经网络的每一层的输入都会被w引导到合适的权重矩阵上进行这一层的运算,每一层的最终输出就是根据权重,对当前的多个experts的输出做一个整合(加权平均)。
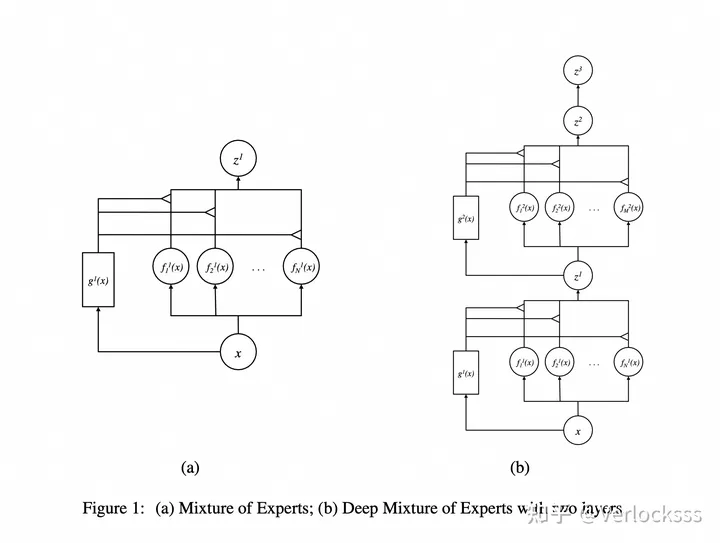
由于这种方法在网络每一层都横向拓展了多个experts,而每一层对expert的选择都是独立的,因此组合之后从整体上会指数级得到更多experts。比如一个两层神经网络,每层有四个experts,由于expert间可以任意搭配,因此可以得到4*4=16个experts。
另外,为了解决模型的gating network只路由到某个expert,而导致其他expert无法得到训练的问题,文章设置了一个threshold,在训练过程中,当单个模型被选中的概率过高时,就会强制使用别的expert,从而保证所有expert都能得到训练,可以说是一种非常强硬(hard)的策略。
这篇文章的探索性质更重一些,重点在于探索MoE架构是否会影响模型性能,以及MoE是否能从训练中学习到有用的知识,模型参数量很小,且数据集是经典的MNIST(毕竟是13年)。并且文章并没有真正利用MoE去减少模型计算量,文章中的gating network得到的expert权重是连续的,所以所有experts都需要在推理时进行计算。
文章最大的贡献应该在于将MoE架构融合进神经网络结构当中,并设计出横向拓展神经网络的方法。之前一直以为每个Expert都是非常独立的一个完整的神经网络,读了这篇文章才意识到原来是每一层网络都独立地进行横向拓展,使得expert数量随着网络深度增加指数级上升。
2.2.2 Sparsely-gated MoE layer
17年1月,Google Brain团队发表论文 Outrageously Large Neural Networks: The Sparsely-Gated Mixture-of-Experts Layer[4],真正意义上将MoE应用到超大参数规模模型之上(本工作中,最大的模型参数量达到137B),应用在NLP领域——这一由于存在大量数据,因此增加模型规模可以不断通过吸收数据提升模型效果的场景——实现语言模型和机器翻译的SOTA。
工作的思路延续上文介绍的DMoE,MoE被作用在Feed-Forward Layer(Linear Layer)上,将LSTM层(当时NLP领域常用)之间的全连接线性层用MoE进行横向拓展,并使用一个Gating Network进行路由。和DMoE核心区别在于Sparsely,在本工作中,Gating Network返回的权重不再分配到所有Expert,而是只分配到权重最高的k个Expert,文章中k=4,这一特性使得MoE真正实现了模型的Conditional Computing,也就是根据输入内容,决定模型的哪一部分进行计算,而其他部分都不需要计算,从而在极大增加模型规模的情况下,维持住计算成本。Sparsely-gated MoE layer可以很直观地用文章中的下图展示。

某种程度上说,将MoE应用到大规模模型场景不但是算法问题,更是一个工程问题。在文章中,模型最大甚至使用了131072个Experts,将这些模型分配给多个机器实现并行训练,保证机器间高效的通信(由于使用gating function进行路由,可能需要将数据传输到别的机器的Expert上计算),保证每个Expert的Load Balance(防止一个Batch内的数据都传给了特定几个Expert,导致大部分机器空转),这些都需要克服工程上大量的问题。文章中分享了一些工程问题的解决方法,感兴趣可以直接阅读原文。
Noisy Top-K Gating
对于Gating Network,除了一个简单的Softmax用来分配给到各个Expert的权重外,文章还引入了Top-K和Noisy两个组成成分。Top-K就是之前提到的,仅使用权重最高的K个Expert,当k不等于1时,可以使用back propogation直接训练gating network。Noise Term则用于实现Load Balance,为Expert的分配增加随机性,方差由可训练权重矩阵 控制。

Balancing Expert Utilization
在DMoE中,作者使用了一个强约束来防止单个Expert被分配到过多的输入。在这篇文章中,除了上面提到的Noisy Gating Network,作者还设计了两个loss,在训练过程中实现Load Balance。

其中一个是importance loss。这个loss作用在一个batch X之上,Importance是不同的Experts在这个batch中被分配到的权重之和,反映了有多少流量被导入给特定的Expert。变异系数(CV)用来衡量数据的离散程度,鼓励Gating Network将权重平均分配给所有experts。
另一个load loss比较复杂,有兴趣可以阅读原文,总的思路是鼓励模型在experts上分配相同数量的样本。简单理解就是importance loss鼓励gating function给每个expert平均分配logits,load loss鼓励最后每个expert拿到相同数量的样本进行计算。
3 MoE与Transformer
3.1 Switch Transformers
进入Transformer时代后,MoE也被作用在Transformer上。21年1月,Google Brain团队提出Switch Transformer[8],以T5模型作为模版,将T5模型中的feed forward network(FFN)更换成MoE架构,将模型的参数量大幅度提升,最高甚至达到1571B。
Switch Transformer的MoE架构和上文并无太大区别,唯一差异在于Switch Transformer只为每个Token分配一个Expert而不是多个。FFN最后的输出将会乘上分配到该Expert的权重p,使得Gating Network可以用BP直接训练。直观的模型结构如下。

另一个区别在于为Load Balance而设计的loss,使用了和 的点积。向量代表一个Batch内分配到不同Expert上的Token数, 向量代表Gating Network分配给不同Expert的概率。当Token数和概率平均分配到所有Expert时,loss达到最小,也即是优化的目标。
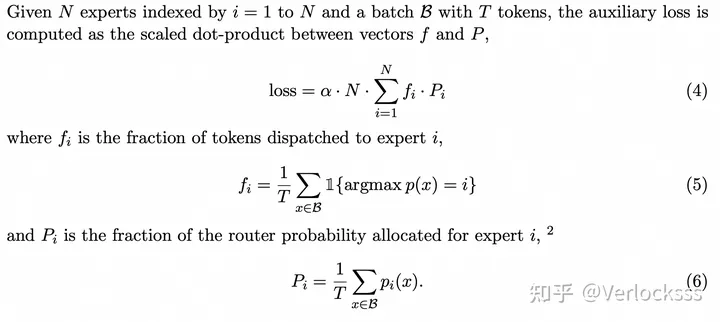
文章另外还提出了Capacity Factor的概念。由于Expert会各自分配给独立的机器,每次将一个Batch内的Token分配给不同的Expert时,我们会希望每个Expert拿到均分的Token,这样最大限度地发挥机器算力。不过在实际计算过程中,是没法保证Tokens能被平均地分配给Expert的,这时会有超出平均的Token被分配到某些Expert上。文章中提出可以为每个Expert分配一个Buffer,这个Buffer的大小等于平均分配到每个Expert的Token数乘上Capacity Factor,即允许Expert接受额外的Token,而如果Buffer溢出,则直接将这个Token丢弃,相当于这个Token直接跳过该FFN层的计算。
通过Capacity Factor,可以实现计算速度和训练质量的trade-off。增大Capacity Factor能保证每个Token都得到计算,但是会导致计算变慢;减少Capacity Factor可以加速训练,但会导致更多的Token被丢弃。

应该说Switch Transformer在模型上并没有提出很大的改动,更多是在工程上和实验上验证MoE在大型Transformer模型上的效果,验证了通过MoE在维持计算量不变的前提下提升模型参数可以加速模型训练,并提升模型效果。文章中特别介绍了Model、Data、Expert并行计算的方法,很值得学习。
3.2 ST-MoE
22年2月,Google Brain团队延续其Switch Transformer的工作,设计了ST-MoE(Stable and Transferable)模型,主要的目的是为了解决MoE模型的两个问题:
MoE模型训练过程中存在不稳定的问题,在一些训练过程中(某些随机种子),模型的Loss会在中途飙升导致训练失败。MoE模型虽然在pre-train上表现良好(语言模型的perplexity能超越稠密模型),但是在一些fine-tune的具体任务上表现不佳,与其pre-train上的优异表现不匹配。针对第一个问题,文章提出了一种新的loss,router z-loss:
这个z-loss作用在router(gating)network返回的logits上。其中B是一个Tokens Batch, 则是返回的logit。这个loss从整体上约束logits的scale,要求logits在绝对值上尽可能地小。这个loss的出发点是当使用bfloat16进行混合精度计算时,如果数值的scale很大,那么会带来很大的误差,这个误差会进一步被softmax的exponential运算放大,因此如果约束这个scale,那么因精度而带来的误差就会减少。
如果从Novelty的角度评价这个工作,其实模型结构上的创新就是这个loss,不过文章针对Stable and Transferable做了大量的超参数和模型结构上的验证,在MoE的进一步优化上很有参考价值。比如说在稳定性上,文章探索了MoE模型训练稳定性和训练效果之间存在的trade-off:
模型当中的乘算(比如GEGLU、RMSnorm)会降低模型训练稳定性但提高模型训练效果。
模型当中增加噪声(比如dropout)会增加模型稳定性但造成训练效果损失。
约束模型参数和梯度的数值scale会提升模型稳定性,同时好的约束(router z-loss)能小幅提升模型效果。
训练时的数据精度也会影响训练稳定性,低精度会导致训练不稳定。
而在可迁移性上,也就是Fine-tune效果不佳的问题上,文章提出这可能是因为MoE模型相较于Dense模型更容易过拟合,同时尝试了多种手段解决过拟合问题,比如:
只更新模型部分参数。
使用与Fine-tune Dense模型不一样的超参数。
模型同时还对单个Token使用几个Expert,以及Capacity Factor如何设置最优进行了许多实验,并总结了很多工程上的经验。
当然,可能持有的疑问就是这些实验经验在现在多数场景下是否还通用,在ST-MoE中,模型是Encoder-Decoder架构,用masked words prediction进行训练,并在Google TPU上部署;现在可能更多是Decoder-only架构,纯自回归任务训练,并在N卡上跑。我觉得可能会有一些很大的不同,特别是文章中更多的是一些经验式的总结,可能并不是一些普适性的结论。不过文章中一些解决问题的思路和方法,在优化MoE时应该还是很有参考价值的。
3.3 Expert Choice Routing
之前的方法都是让Token选择Top-k Expert进行计算,在[7]中,提出了一种Routing方法,让Expert选择Top-k Token进行处理。
这种方法使得模型天然具备Load Balance的能力,因为每个Expert都会处理固定的k个Token,免去了设计auxiliary loss的烦恼,并通过实验验证了使用Expert Choice Routing可以使模型的训练更加有效,并得到更好的下游任务效果。

从上图可以看出,大多数Token会自动地被分配到1-2个Expert上(k=2),但同时也会有许多Token被分配到更多Expert上,这使得模型可以针对更复杂的Token分配不同数量的Expert进行处理,使模型更为灵活。可以说Expert Choice Routing是一个非常简单且有效的方法。
Expert Choice Routing的问题在于不能直接地作用于自回归语言模型上,因为它必须一次同时处理大批量的Token,才能让Expert去选择Top-k Token,没法处理小批量的数据,文章也提到如果想要将此方法作用在自回归语言模型上,则需要更多的工作来解决这个问题。
4 MoE Applications
4.1 MoE with Instruction Tuning
这篇文章[10]尝试了用Instruction数据去Fine-tune MoE模型,并且验证了MoE模型的比较好的效果(和同等计算要求的稠密模型和参数量更大的PaLM模型),然后测试了上述文章当中一些Hyperparameter的选取对实验结果的影响,是一篇比较详尽的实验报告。不过这里的Instruction Tuning还是通过下游任务去验证的结果,与Chat Model的对话能力并没有什么关系。
比较有意思的地方是这篇文章的超参数设置的ablation实验结果并不与ST-MoE总是保持一致,在不同任务和具体架构下,都可能会需要不同的超参数来达到比较好的效果,没有统一的答案。
4.2 Mixtral
关于Mixtral 8*7B的详细介绍,参考官方Blog[2]、GitHub[12]和HuggingFace实现[6]即可,也没有其他更多信息,关于模型结构,上文也说的比较多了,实质上并不复杂。Mixtral在Benchmark上表现不错,不过现在Open Benchmark基本没有太多参考价值。。。
[11]这里有一个有意思的测评,不过局限在单一任务。社区的评价整体看下来,Mixtral在它的模型规模上确实表现非常出色,感觉现在发布的一些模型都已经开始逐渐达到甚至超越GPT-3.5了,而这距离ChatGPT发布也就过了一年,发展是真的太快了。
[13]这里有一个很有意思的Mixtral Expert可视化项目,作者尝试去观察对于不同的话题,Mixtral中每层的Expert激活情况。直观上,对于不同的Topic,比如数学/生物,在MoE模型中需要激发的Expert应当有所区别,而在项目中作者证实了这一点。作者还发现使用一个简单的线性SVM可以很好地对话题进行分类(准确率达到95%),以及浅层的Expert激发情况就可以很好地去做分类,而不需要到比较高层。
一点思考
MoE架构是真的一种极其强调工程的架构,天然地具有Parallel Compute的属性,使得如果想要达到模型最好的结果(包括模型效果和训练、推理效率),需要非常综合地考虑模型结构、当前的硬件基础和所做的任务,这非常难。这方面Google是真的先驱者,上面介绍的工作全都是Google做的。
MoE训练与Fine-tune结果的不稳定性也给模型优化带来了很大的困难,对Hyperparameter的选取具有更高的要求,训练难度很大(架构上可能都会继续参考Mixtral,但如何训练那各大公司肯定都不会公开,也许又只能指望Meta拯救了)。
论文里对MoE的评估都是将MoE和自己同等FLOPS/token的模型去比较,而展现出MoE的优势,并不会拿MoE模型和同参数量的稠密模型去做对比。在比较稠密模型时,比较参数规模就可以对模型能力有一个大致的预估(参考LLM scaling law),但MoE具体如何很难说,不能以参数量进行简单的考虑,毕竟在文章里,Expert数量越多,模型效果就越好(边际效益可能到上千Expert才会出现,但是在原本就很大的模型上是不是这样并不知道,现在GPT和Mixtral都只用了8个Expert以及简单的Top-2 Router),但硬件不太可能支持无限制地增加Expert。这次的Mixtral以46.7B的参数量达到目前的这种效果非常意外,但MoE模型具体的能力与参数量的关系还要进一步观察。(如果按照上述论文里的比较方法,拿Mixtral和13B模型去对比,那Mixtral也太恐怖了。)
参考链接
MoE Wiki:https://en.wikipedia.org/wiki/Mixture_of_experts
Mixtral of experts:https://mistral.ai/news/mixtral-of-experts/
Learning Factored Representations in a Deep Mixture of Experts:https://arxiv.org/abs/1312.4314
Outrageously Large Neural Networks: The Sparsely-Gated Mixture-of-Experts Layer:https://arxiv.org/abs/1701.06538
Mixture of Experts Explained:https://huggingface.co/blog/moe
Welcome Mixtral - a SOTA Mixture of Experts on Hugging Face:https://huggingface.co/blog/mixtral
Mixture-of-Experts with Expert Choice Routing:https://blog.research.google/2022/11/mixture-of-experts-with-expert-choice.html?m=1
Switch Transformers: Scaling to Trillion Parameter Models with Simple and Efficient Sparsity:https://arxiv.org/abs/2101.03961
ST-MoE: Designing Stable and Transferable Sparse Expert Models:https://arxiv.org/abs/2202.08906
Mixture-of-Experts Meets Instruction Tuning:A Winning Combination for Large Language Models:https://arxiv.org/abs/2305.14705
LLM Comparison/Test: Mixtral-8x7B, Mistral, DeciLM, Synthia-MoE:https://www.reddit.com/r/LocalLLaMA/comments/18gz54r/llm_comparisontest_mixtral8x7b_mistral_decilm/
Mistral Official GitHub Repo:https://github.com/mistralai/mistral-src
Some interesting visualizations based on expert firing frequencies in Mixtral MoE:https://www.reddit.com/r/LocalLLaMA
备注:昵称-学校/公司-方向/会议(eg.ACL),进入技术/投稿群

id:DLNLPer,记得备注呦






![[足式机器人]Part3 机构运动学与动力学分析与建模 Ch00-2(4) 质量刚体的在坐标系下运动](https://img-blog.csdnimg.cn/direct/5d11d57df3424ac89acac118bbbde115.png)

![[足式机器人]Part2 Dr. CAN学习笔记-动态系统建模与分析 Ch02-4 拉普拉斯变换(Laplace)传递函数、微分方程](https://img-blog.csdnimg.cn/direct/75539048aed84a8f8f233c199db174c3.png#pic_center)