目录
1.HBase默认负载均衡策略
1.1 负载均衡总体流程
1.2 不能触发负载均衡的情况
1.3 负载均衡算法
2.自定义的 HBase 负载均衡器的步骤
3.MyCustomBalancer的代码细节
3.1 balanceCluster 方法的作用
3.2balanceCluster 对数据的影响
3.3监控HBase的性能指标
3.3.1 指标介绍
3.3.2 新建 run_canary.sh 的脚本
3.3.3 cron 作业定期执行脚本
3.3.4 解析 Canary 输出
4.注意事项
5.相关资料
1.HBase默认负载均衡策略
HBase通过Region的数量实现负载均衡,即通过hbase.master.loadbalancer.class实现自定义负载均衡算法。下面将为大家剖析HBase负载均衡的相关内容以及性能指标。
1.1 负载均衡总体流程

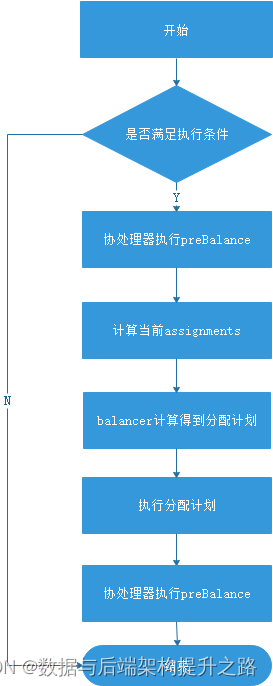
1.2 不能触发负载均衡的情况
HBase系统负载均衡是一个周期性的操作,通过负载均衡来均匀分配Region到各个RegionServer上,通过hbase.balancer.period属性来控制负载均衡的时间间隔,默认是5分钟。触发负载均衡操作是有条件的,但是如果发生以下情况则不会触发负载均衡操作:
- 负载均衡自动操作balance_switch关闭,即:balance_switch false;
- HBase Master节点正在初始化操作;
- HBase集群中正在执行RIT,即Region正在迁移中;
- HBase集群正在处理离线的RegionServer;
1.3 负载均衡算法
HBase执行负载均衡操作的时候,如何判断各个RegionServer节点上的Region个数是否均衡,这里通过以下步骤来判断
- 计算均衡值的区间范围,通过总Region个数以及RegionServer节点个数,算出平均Region个数,然后在此基础上计算最小值和最大值;
- 遍历超过Region最大值的RegionServer节点,将该节点上的Region值迁移出去,直到该节点的Region个数小于等于最大值的Region;
- 遍历低于Region最小值的RegionServer节点,分配集群中的Region到这些RegionServer上,直到大于等于最小值的Region;
- 负责上述操作,直到集群中所有的RegionServer上的Region个数在最小值与最大值之间,集群才算到达负载均衡,之后,即使再次手动执行均衡命令,HBase底层逻辑判断会执行忽略操作
2.自定义的 HBase 负载均衡器的步骤
集群规模大了以后需要更多细粒度的监控和负载均衡,这个时候需要考虑自定义的 HBase 负载均衡器。要使自定义的 HBase 负载均衡器 MyCustomBalancer 生效,需要进行几个步骤:
-
编译和打包:首先,您需要将
MyCustomBalancer类编译并打包成一个 JAR 文件。这个 JAR 文件应该包含您自定义的负载均衡器类以及可能的任何依赖。 -
部署 JAR 文件:将编译好的 JAR 文件放置在 HBase 集群中的所有节点上。通常,这意味着需要将 JAR 文件放置在每个节点的 HBase lib 目录下(例如
/path/to/hbase/lib/)。 -
更新 HBase 配置:在 HBase 的配置文件
hbase-site.xml中指定您的自定义负载均衡器类。这告诉 HBase 使用您的负载均衡器而不是默认的。在每个 HBase 节点的配置文件中添加以下配置:<property><name>hbase.master.loadbalancer.class</name><value>your.package.MyCustomBalancer</value> </property>请确保
<value>中的值匹配您的自定义负载均衡器类的完全限定名。 -
重启 HBase 集群:更改配置文件后,您需要重启 HBase 集群,以便更改生效。这通常涉及重启 HBase Master 和所有的 RegionServer。
-
验证:重启 HBase 服务后,验证自定义负载均衡器是否正在使用。您可以通过查看 HBase Master 的日志来确认是否已成功加载自定义负载均衡器。
3.MyCustomBalancer的代码细节
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.hbase.HBaseConfiguration;
import org.apache.hadoop.hbase.ServerName;
import org.apache.hadoop.hbase.client.RegionInfo;
import org.apache.hadoop.hbase.master.LoadBalancer;
import org.apache.hadoop.hbase.master.balancer.BaseLoadBalancer;import java.util.ArrayList;
import java.util.List;
import java.util.Map;public class MyCustomBalancer extends BaseLoadBalancer {private CanaryDataCollector dataCollector = new CanaryDataCollector();@Overridepublic void setConf(Configuration conf) {super.setConf(conf != null ? conf : HBaseConfiguration.create());}@Overridepublic void initialize() throws HBaseIOException {// 初始化,可以在这里实现一些监控逻辑}@Overridepublic List<RegionPlan> balanceCluster(Map<ServerName, List<RegionInfo>> clusterState) {// 1. 从 Canary 数据收集器获取延时数据Map<RegionInfo, Long> regionDelays = dataCollector.getRegionDelays();// 2. 分析和决策List<RegionPlan> plans = new ArrayList<>();if (需要负载均衡) {// 3. 计算出最优的Region迁移方案for (Map.Entry<ServerName, List<RegionInfo>> entry : clusterState.entrySet()) {ServerName server = entry.getKey();List<RegionInfo> regions = entry.getValue();for (RegionInfo region : regions) {// 假设逻辑:如果一个 RegionServer 上的 Region 数量超过某个阈值,则迁移一部分 RegionsLong delay = regionDelays.get(region);// 如果延时超过阈值,生成迁移计划if (delay != null && delay > THRESHOLD) {// 选择一个目标 ServerName 并创建 RegionPlanServerName targetServer = ...; // 选择一个目标服务器RegionPlan plan = new RegionPlan(region, server, targetServer);plans.add(plan);}}}}}return plans;}private boolean 需要负载均衡() {// 实现监控和分析逻辑// 比如基于 Regions 的大小、读写负载等因素进行判断return true; // 示例代码}
}3.1 balanceCluster 方法的作用
-
分析集群状态:
balanceCluster方法分析当前集群的状态,包括每个 RegionServer 上托管的 Region 数量、Region 的大小、读写负载等。 -
决定 Region 迁移:基于分析的结果,
balanceCluster决定是否有必要进行 Region 迁移,以及如何迁移。例如,如果一个 RegionServer 承载的负载过重,方法可能决定将一些 Region 迁移到负载较轻的 RegionServer 上。 -
生成迁移计划:
balanceCluster生成一个 Region 迁移计划,该计划由一系列的RegionPlan对象组成。每个RegionPlan指定了一个 Region 从一个 RegionServer 迁移到另一个 RegionServer。
3.2balanceCluster 对数据的影响
-
不影响数据完整性:负载均衡过程中,Region 中存储的数据不会受到影响。HBase 保证了在迁移过程中数据的完整性和一致性。
-
可能暂时影响可用性:在 Region 迁移过程中,被迁移的 Region 可能会暂时不可用。这意味着对这些 Region 的读写操作可能会在迁移期间受到影响。
-
不直接修改数据:
balanceCluster方法本身不会修改 Region 中的数据。它只是决定 Region 应该在哪些 RegionServer 之间移动。
3.3 监控HBase的性能指标
3.3.1 指标介绍
HBase系统为了反应集群内部处理请求所耗费的时间提供一个工具类即
org.apache.hadoop.hbase.tool.Canary如果不知道使用方法,通过help命令来查看具体的用法,操作命令:
hbase org.apache.hadoop.hbase.tool.Canary -help3.3.2 新建 run_canary.sh 的脚本
#!/bin/bash
# run_canary.sh# 运行 Canary 工具并将输出重定向到日志文件
hbase org.apache.hadoop.hbase.tool.Canary > /path/to/canary_output.log 2>&1
3.3.3 cron 作业定期执行脚本
# 编辑 crontab
crontab -e# 添加一行来每小时运行一次脚本
0 * * * * /path/to/run_canary.sh3.3.4 解析 Canary 输出
import java.io.BufferedReader;
import java.io.FileReader;
import java.util.HashMap;
import java.util.Map;public class CanaryDataCollector {public Map<RegionInfo, Long> getRegionDelays() {Map<RegionInfo, Long> regionDelays = new HashMap<>();String line;try (BufferedReader br = new BufferedReader(new FileReader("/path/to/canary_output.log"))) {while ((line = br.readLine()) != null) {// 解析每一行来提取 Region 信息和延时// 假设你有一种方法来从一行文本中解析出 RegionInfo 和延时RegionInfo regionInfo = ...; // 解析 Region 信息Long delay = ...; // 解析延时regionDelays.put(regionInfo, delay);}} catch (Exception e) {e.printStackTrace();}return regionDelays;}
}
4.注意事项
请注意,自定义负载均衡器的开发和部署是一个高级操作,需要对 HBase 有深入的理解。在进行这些更改之前,请确保在一个测试环境中进行充分的测试,以避免在生产环境中意外影响集群的稳定性和性能。自定义负载均衡器的行为可能会根据负载、数据分布和集群配置的不同而大不相同。
5.相关资料
Apache HBase 负载均衡机制-云社区-华为云
深度剖析HBase负载均衡和性能指标 - 墨天轮