前置知识:参考上一篇博文 CMU15-445-Spring-2023-Project #2 - 前置知识(lec07-010)
CHECKPOINT #1
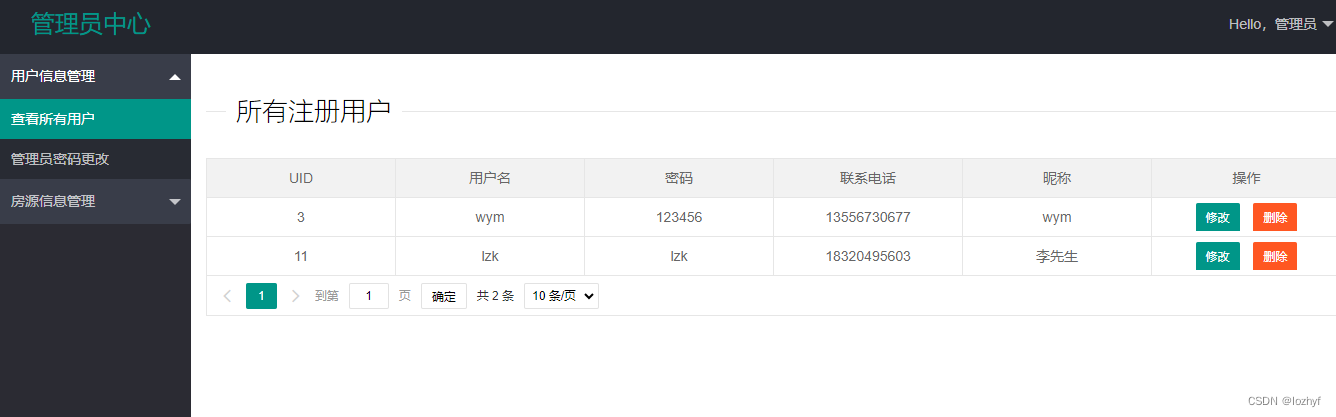
Task #1 - B+Tree Pages
实现三个page class来存储B+树的数据。
- B+Tree Page
- internal page和leaf page继承的基类,只包含两个子类共享的信息;

- Impl:
- src/include/storage/page/b_plus_tree_page.h
- src/storage/page/b_plus_tree_page.cpp
- B+Tree Internal Page
- 一个内部页面存储 m 个有序键和 m+1 个指向其他 B+Tree 页面的子指针(作为 page_id)。这些键和指针在内部表示为一个 key/page_id 对数组。由于指针的数量不等于键的数量,因此第一个键被设置为无效,查找应始终从第二个键开始;
- 在任何时候,每个内部页面都应至少满一半。在删除过程中,可以合并两个半满的页面,或者重新分配键和指针以避免合并。在插入过程中,可以将一个完整的页面分割成两个,也可以重新分配键和指针以避免分割;
- Impl:
- src/include/storage/page/b_plus_tree_internal_page.h
- src/storage/page/b_plus_tree_internal_page.cpp
- B+Tree Leaf Page
- leaf page存储 m 个有序键及其 m 个相应的值。值应始终是tuple实际存储位置的 64 位 record_id;参阅 src/include/common/rid.h 中的 RID 类。leaf page对k/v对数量的限制与内部页面相同,并应遵循合并、拆分和重新分配键的相同操作;
- Impl:
- src/include/storage/page/b_plus_tree_leaf_page.h
- src/storage/page/b_plus_tree_leaf_page.cpp
每个 B+Tree 的leaf/internal page都与缓冲池获取的内存页的内容(即 data_ 部分)相对应。每次读取或写入leaf/internal page时,必须先从缓冲池中获取该页(使用其唯一的 page_id),然后 reinterpret cast 成leaf/internal page,并在读取或写入该页后将其unpin。
Task #2a - B+Tree Insertion and Search for Single Values
Impl:
src/storage/index/b_plus_tree.cpp
如果插入改变了根页面的 ID,则必须更新 B+Tree 索引头页面中的 root_page_id。为此,可以访问在构造函数中给出的 header_page_id_ page。然后,通过使用 reinterpret cast,将该页面解释为 BPlusTreeHeaderPage(来自 src/include/storage/page/b_plus_tree_header_page.h),并从这里更新根页面 ID。实现 GetRootPageId(目前默认返回 0)。
使用 project 1 中的page guard类来帮助防止同步问题。在访问页面时使用 FetchPageBasic(定义于 src/include/storage/page/)。以后在task 4 中实施并发控制时,可以根据需要将其改为使用 FetchPageRead 和 FetchPageWrite。
可以选择使用 Context 类(定义于 src/include/storage/index/b_plus_tree.h)来跟踪已读取或写入的页面(通过 read_set_ 和 write_set_ 字段),或存储需要递归传递到其他函数的其他元数据。
只需要在插入或删除时使用 write_set_。可能不需要使用 read_set_,这取决于实现。
在context中存储根页面 id,并在修改 B+Tree 时获取头页面的写保护。
write_set_ 的尾部保存当前节点的父节点,它应该包含访问路径上的所有节点。
如果要拆分节点(根节点除外),要确保 write_set_ 中至少还有一个节点。
要解锁header page,只需将 header_page_ 设为 std::nullopt。要解锁其他页面,只需从 write_set_ 中弹出即可。
插入后,当值的数量达到 max_size 时,分割叶节点;插入前,当值的数量达到 max_size 时,分割内部节点。这将确保在进行 InsertIntoLeaf 等操作后再重新分配时,插入叶节点不会导致页面数据溢出;这也将防止内部节点只有一个子节点。
当叶页面无法获取同级页面的latch时,需要抛出一个 std::exception 异常,以避免潜在的死锁。
每个线程将始终从头页到底部获取锁存器。释放锁存器时,请确保以相同的顺序(从页眉到底部)释放。
在插入时,即使拥有父节点的锁,也应始终获取子节点的锁。想想这样一种情况:一些线程正在使用读锁从叶子页中获取值,而另一些线程正在更新页面(例如,在聚合时)。如果不加锁,就会出现race。
- GetValue()
- 使用ReadPageGuard访问页面。通过header_page_id_访问header page,header page的root_page_id_指向根节点的第一个k/v对;
- 当获取了根节点的页面的latch后,释放header page的latch;
- 通过二分搜索key在页面中的位置,迭代向下查找到leaf page,然后找到leaf page中相应的value(rid)。
- Insert()
- 同样,先获取根页面,若根为空,通过NewPageGuarded获取一个新页面,然后插入;
- 若根节点不为空,通过write_set_维护向下搜索的path,直到到达leaf page,并且通过prev_和next_维护路径上节点的左右兄弟节点(插入分裂优化);
- 若搜索过程中某个internal page的size小于max size,就可以将write_set_中的节点弹出,因为即使叶子节点需要分裂,internal page需要插入新k/v对,size也是够的;
- 插入分裂优化:若leaf page插入后超过了max size,但是其兄弟节点没满,会将最左/右记录移动到其兄弟节点上,默认先向左移动;(参考InnoDB,充分利用索引页,还有一种方法就是在特定的递增key插入情况下,如果检测到三个连续递增的key,那么就不进行分裂,而是直接往右新建一个页面插入,避免频繁分裂)常规分裂就是50%。
- leaf page分裂会产生新的k/v,继续向上往internal page插入(根据write_set_维护的path),同样进行插入分裂优化;
- 若write_set_遍历完后还需要向上插入,那么通过NewPageGuarded获取新页面作为根节点,然后更新即可;
CHECKPOINT #2
Task #2b - B+Tree Deletions
支持key的删除,包括页面的合并或重新分配键。与插入一样,如果根页面发生变化,必须正确更新 B+Tree 的根页面 ID。
Impl:
src/storage/index/b_plus_tree.cpp
- Remove()
- 几乎与Insert同样的思路,进行合并优化,优先从兄弟节点拉取单个k/v到本节点;
Task #3 - An Iterator for Leaf Scans
添加一个 C++ 迭代器,以有效支持对leaf page中的数据进行顺序扫描。基本思路是存储同胞指针,以便高效地遍历leaf page,然后实现一个迭代器,按顺序遍历每个leaf page中的每个键值对。
- C++17 style;
- isEnd():返回此迭代器是否指向最后一个键/值对;
- operator++():移动到下一个键/值对;
- operator*():返回该迭代器当前指向的键/值对;
- operator==():返回两个迭代器是否相等;
- operator!=():返回两个迭代器是否不相等;
- Begin() & End():返回最左/右的leaf page的迭代器;
Impl:
src/include/storage/index/index_iterator.h
src/index/storage/index_iterator.cpp
src/storage/index/b_plus_tree.cpp
IndexIterator内部维护三个值:bpm、page id、page内部index。
Task #4 - Concurrent Index
FetchPageWrite or FetchPageRead
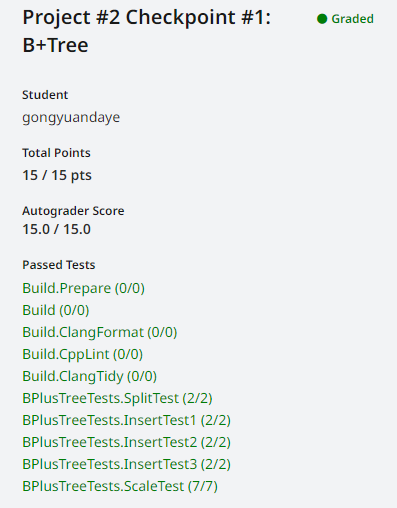
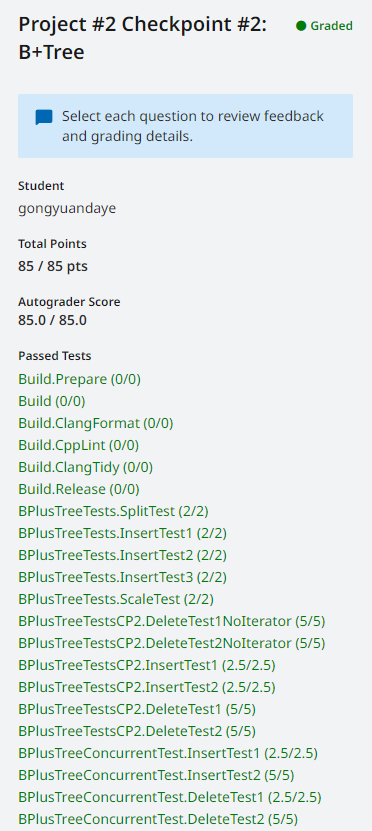
实验结果

![Flask+Bootstrap4案例[有源码]](https://img-blog.csdnimg.cn/direct/d5fe8abb004c4e3c82825ab5ef38de41.png#pic_center)