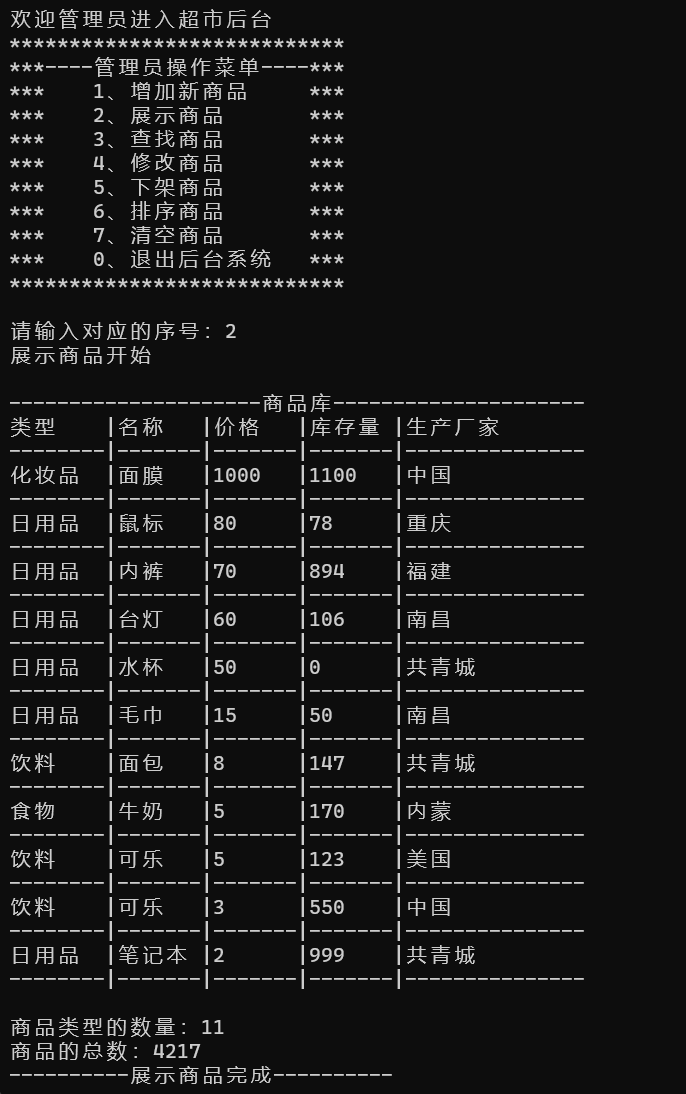
一、层次结构

具体到某个broker上则是, 数据目录/分区名/日志相关文件集合。其中日志文件集合内包括.log文件, index索引文件和.timeindex时间戳索引文件。
二、.log 结构
.log中记录具体的消息。一般消息由header和body组成, 这点儿在Kafka消息中也同样适用。
message
MESSAGE=OVERHEAD+RECORD
OVERHEAD=xxx
v0
RECORD = CRC32+BODY
BODY = magic + attributes + key_len + key + val_len + value

v1
RECORD = CRC32+BODY
BODY = magic + timestamp + attributes + key_len + key + val_len + value

v2

message set
网络传输和存储的基本单位, 也是消息压缩的基本单位。相当于在bit, byte之上page的概念, 只不过叠加更多的约束。
不同颗粒度与存储体系下的能力相对应。
file name
第一条记录的逻辑offset, 这样不需要读取文件内容便知道offset, 充分利用信息位置。
三、.index文件
.index文件是一种稀疏索引。稀疏索引是内存占用, 磁盘占用和查找时间的折中。索引的内容为索引key和对应的物理偏移量。每个索引key的写入受索引项增加速率和索引文件大小限制。索引项增加速率就是数据写入字节数log.index.interval.bytes。另一个是索引文件分割, 如日志文件大小(log.segment.bytes),时间大小(log.roll.ms,hours),索引大小(log.index.size.max.bytes),追加消息的偏移量过大超过了Integer.MAX_VALUE。
文件名称为整个日志段的base offset。其中的索引项记录逻辑offset对应的物理position。每个索引项占8个字节, 前面4个是相对偏移量(absolute offset-base offset, 相对偏移比绝对偏移占用的空间更小), 后者是文件中的物理偏移量(第一个字节在文件中的位置)。
基于索引检索消息时, Kafka基于ConcurrentSkipListMap定位到base offset对应的索引文件, 而后在索引文件内通过二分查找得到对应的物理偏移量。
四、.timeIndex
最大timestamp和逻辑offset的集合, 如果说.index是主键索引, 那么时间戳索引则是二级索引。其查找过程需要先根据.timeIndex查找到不大于目标时间戳的relative offset, 然后通过.index文件定位到对应的物理offset, 然后从.log文件的特定位置开始查找目标位置,最终定位到日志内容。
五、日志删除
作用是删除不再需要消息, 减少磁盘空间占用。
清理触发条件
- 按时间清理
- 按文件大小清理
- 按偏移量清理
日志清理
- 清理过程包括2个步骤, 标记和删除;
- 标记阶段, 遍历文件夹下的segment, 如果满足触发条件则标记为可删除;
- 删除阶段, 删除被标记的segment文件, 更新topic对应的offset;
日志压缩
- 针对相同key仅保留最新的消息, 减少磁盘空间占用。整个过程与日志清理类似, 差别在标记后的处理;
- 记录最大offset, 扫描整个segment文件, 记录每个key的最大offset到Map中;
- 清理消息的value, 扫描整个segment文件, 如果消息offset小于Map中的offset, 则将其value设置为NULL(将消息转变为墓碑消息);
- 扫描整个topic下的文件, 创建新的segment文件, 文件名以.swap结尾。一组源日志文件创建一个新的segment文件。
六、高性能IO
IO过程

常规IO

性能地下的原因: 1. 太多小的IO; 2. 大量的字节拷贝。
顺序读写
相比于RabbitMQ基于内存堆积消息, Kafka将消息存储在磁盘上。通常我们会觉得磁盘的IO速度非常慢, 但大神们发现IO效率也与IO方式有关。比如对磁盘的顺序读写性能也可以匹配固态盘的随机读写。于是Kafka引入了MessageSet, 对应的是更大的网络包,顺序磁盘IO, 连续的内存块等等, 最终把不稳定的随机stream转换为线性flow。
NIO

基于NIO可以减少内存拷贝和内核上下文切换, 可参见这篇文件https://developer.ibm.com/articles/j-zerocopy/。
端到端压缩
MessageSet在producer, consumer和broker保持统一的压缩方式, 在数据传输过程中不需要进行解压, 做到尽可能充分利用带宽。
七、小结
本文介绍了Kafka关于日志存储相关的目录结构, 日志内容结构, 日志删除策略以及Kafka使用的高性能IO策略。
八、参考内容
深入Kafka核心设计与与实践原理
https://developer.ibm.com/articles/j-zerocopy/