文章目录
- 1 爬虫基本原理
- 什么是爬虫
- 爬虫功能详解
- 爬虫基本流程
- 两个概念:request和response
- 2 一些问题
- 爬虫能抓取什么样的数据?
- 抓取的数据怎么提取部分内容?数据解析方式。
- 为什么我爬虫抓取的数据和浏览器看到的不一样
- 怎样解决JavaScript渲染的问题?
- 怎样保存数据
1 爬虫基本原理
什么是爬虫
爬虫,又名网络爬虫。顾名思义,就是在网络中爬行的一只蜘蛛。
互联网可以看作是一张巨大的网,爬虫就在这个网上爬来爬去,如果在爬行的过程中遇到了一些网站资源,就会把它抓取下来。
如何抓取、抓取什么内容就由你来决定!
爬虫功能详解
简单来说,爬虫就是:请求网站并提取数据的自动化程序。
关键字说明:
请求:平时我们打开浏览器输入网址按下回车可以看到一些页面,这个过程 其实就是通过浏览器去请求目标服务器,目标服务器同意请求之后返回给我们一个网页。那么爬虫就是写一段代码模拟浏览器的这个过程,去获取网页资源。
提取:一般请求获取到的网页资源是一串HTML代码,其中就包含一些标签以及我们需要的文字等资源。接下来就需要把这些信息提取出来。
自动化:一个爬虫代码一般会爬取一个对应的目标信息,我们程序写好并运行代码之后就会自动的去完成爬取的过程,并且把资源爬取到本地。
爬虫基本流程

爬虫的基本流程基本就这几步:
1 发起请求
2 获取响应内容
3 解析内容
4 保存数据
中间可能会经过一些其他复杂的步骤,但基本步骤就这几步。
两个概念:request和response
request(请求):Request 是爬虫发送给服务器的信息,它包含了要获取特定资源的详细信息。当我们使用爬虫发送一个请求时,我们可以指定请求的类型(GET、POST等)、目标URL、请求头(Headers)、请求体(Body)等信息。请求的目的是向服务器请求特定的数据或资源。

response(响应):Response 是服务器对 Request 的回应,它包含了服务器返回的数据和相关的元信息。当服务器接收到一个请求后,它会根据请求的内容进行处理,并返回相应的数据。响应通常包括状态码(例如200表示成功,404表示未找到等)、响应头(Headers)、响应体(Body)等信息。


2 一些问题
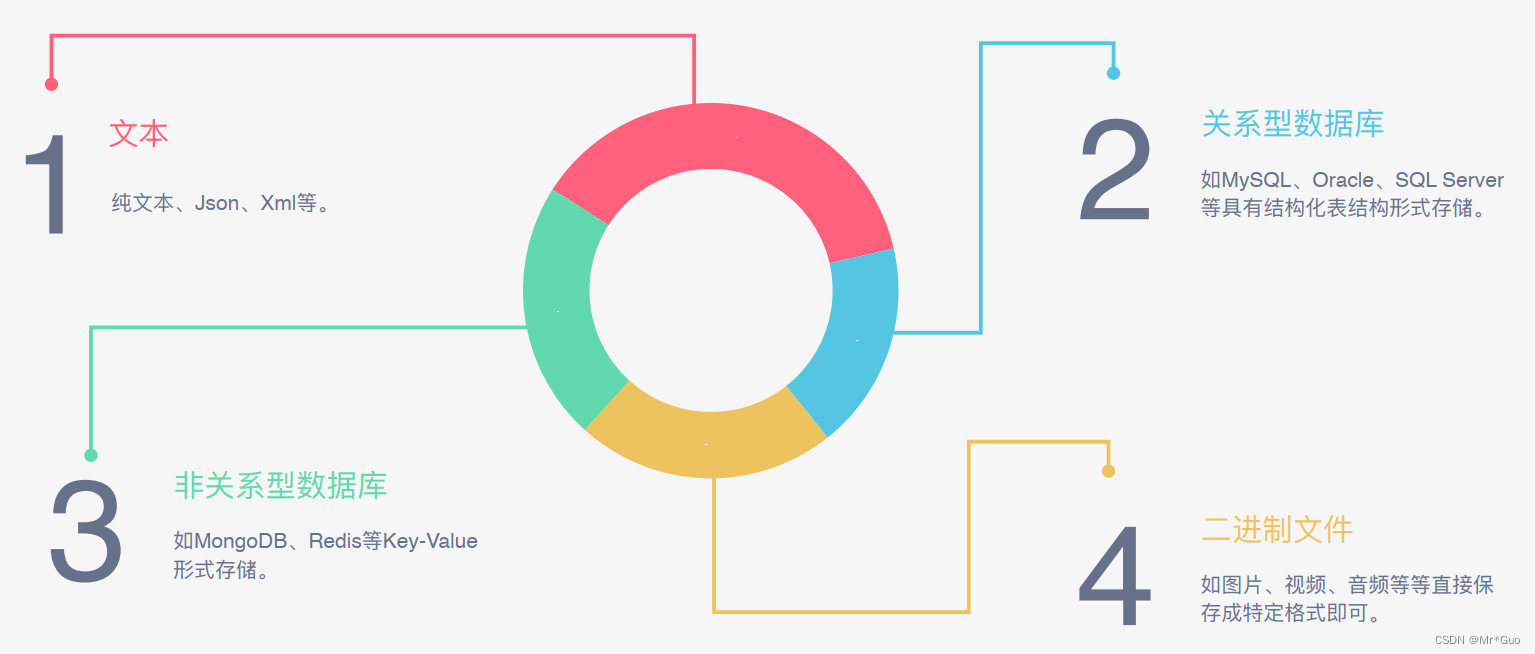
爬虫能抓取什么样的数据?
- 网页文本:如HTML文档、Json格式文本等。
- 图片:获取到的是二进制文件,保存为图片格式。
- 视频:同为二进制文件,保存为视频格式即可。
- 其他:只要是网页上能看得到的东西全都可以爬取下来。
抓取的数据怎么提取部分内容?数据解析方式。
请求服务器之后大部分情况下得到的是HTML代码,所以需要对数据进行解析,获取我们需要的部分。以下是解析数据的方法,选择适合当前情况的方式。
- 直接处理:适用于网页比较简单的情况,直接获取数据,并用strip简单处理一下头尾就可以了。
- json解析:适用于用Ajax加载的网页,通常返回的格式就是json
- 正则表达式:非常常用的方法,它是规则字符串,来把HTML代码中的相应的内容提取出来
- BeautifulSoup:解析库,相对于正则表达式更好用,更加容易
- PyQuery:使用PyQuery可以轻松地从网页或字符串中提取数据,并对文档进行修改和操作。
- XPath:“网页树”,XPath使用路径表达式来描述和定位文档中的节点,通过这些表达式可以实现非常精确的节点选择。
为什么我爬虫抓取的数据和浏览器看到的不一样
当我们使用爬虫抓取网页时,通常只能获取到页面的原始HTML代码,而无法获取到经过JavaScript渲染后生成的动态内容或者其他的一些内容:例如css、图片或者视频等。如果网站使用了JavaScript来加载或修改页面的部分内容,那么你通过爬虫获取到的数据可能与浏览器中看到的不一致。
在这种情况下,可以考虑使用一些支持JavaScript渲染的工具或库,例如Selenium或Puppeteer。这些工具可以模拟浏览器行为,执行JavaScript代码,并获取到完整的页面内容。这样可以更接近浏览器中所看到的内容。
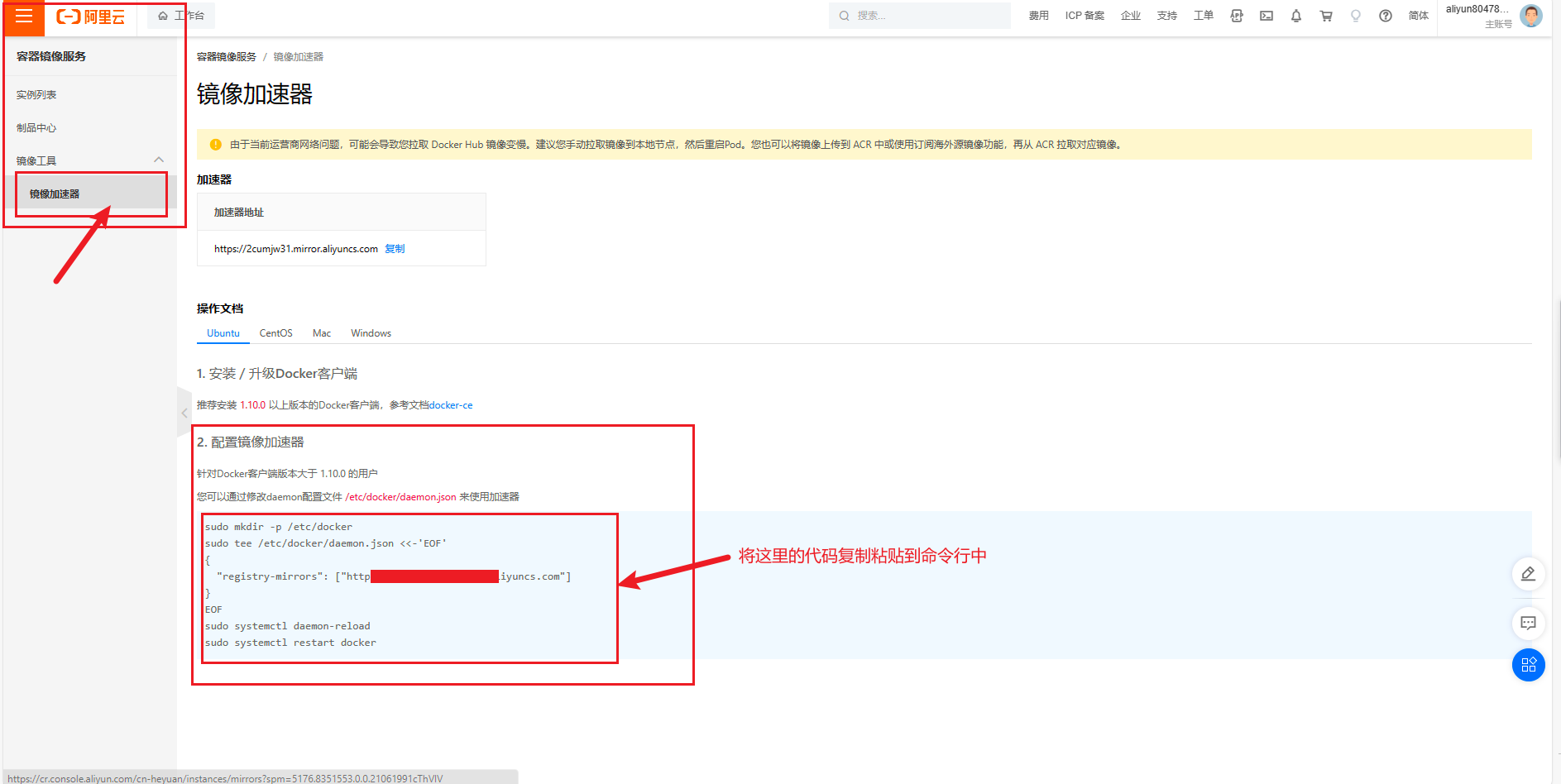
怎样解决JavaScript渲染的问题?
- 分析Ajax请求
Ajax(Asynchronous JavaScript and XML)是一种使用JavaScript实现异步通信的技术。在传统的Web页面中,用户交互通常需要刷新整个页面才能显示新的内容。而使用Ajax,可以通过后台异步请求数据,然后更新页面的局部内容,而不需要刷新整个页面。
现在网页的大部分关键数据都是通过Ajax请求得到的,并通过后期的js渲染显示到页面上。 - Selenium/WebDriver
驱动一个浏览器模拟加载一个网页,这个是用来做自动化测试的一个工具。
通过这个工具去加载一个网页,然后用page_source直接获取网页源代码,可以减少js渲染的问题。
#说明:下面代码就是使用selenium去打开谷歌浏览器,并输入百度网址,然后定位到url输入关键词的部分去输入hello world,并搜索,然后关闭。
from selenium import webdriver
from selenium.webdriver.common.keys import Keys# 创建WebDriver对象
driver = webdriver.Chrome()# 打开百度网站
driver.get("http://www.baidu.com")# 定位搜索框元素,并输入关键字,然后输出网页源代码
search_box = driver.find_element_by_name("wd")
search_box.send_keys("Hello World")
search_box.send_keys(Keys.RETURN)
print(driver.page_source)
# 关闭WebDriver对象和浏览器窗口
driver.quit()
- Splash
跟上一个方法差不多,也是模拟js渲染的 - PyV8、 Ghost.py
怎样保存数据
保存数据可以有多个方式。