| Category | Content |
|---|---|
| 论文题目 | Position-guided Text Prompt for Vision-Language Pre-training Code: ptp |
| 作者 | Alex Jinpeng Wang (Sea AI Lab), Pan Zhou (Sea AI Lab), Mike Zheng Shou (Show Lab, National University of Singapore), Shuicheng Yan (Sea AI Lab) 另一篇论文:All-in-one 作者主页:https://github.com/FingerRec 参与其他:EditAnything 、Image2Paragraph |
| 发表年份 | 2023 |
| 摘要 | 提出了一种名为Position-guided Text Prompt (PTP)的新方法,以增强视觉语言预训练(VLP)模型在视觉定位方面的能力。PTP通过将图像分割成N×N块并通过VLP中广泛使用的对象检测器识别每个块中的对象,然后将视觉定位任务转化为填空问题。这种机制提高了VLP模型的视觉定位能力,从而更好地处理各种下游任务。通过将PTP引入多个先进的VLP框架中,我们观察到在代表性的跨模态学习模型架构和多个基准测试中都取得了显著的改进。 |
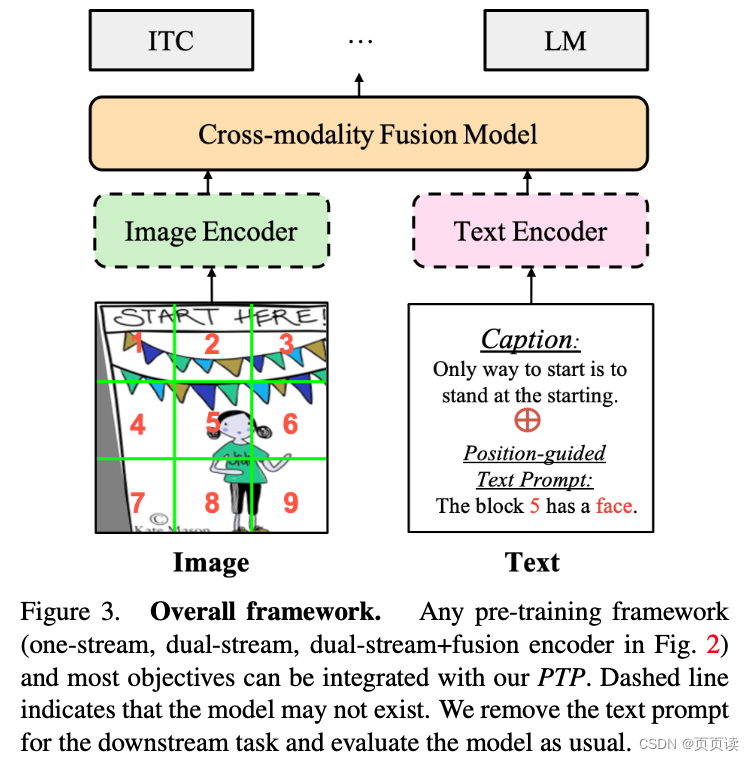
| 主要内容 | 为了增强VLP模型在跨模态学习中的视觉定位能力,我们提出了PTP。PTP与传统的视觉语言对齐方法不同,它将对象特征和边界框作为输入来学习对象与相关文本之间的对齐。PTP包括两个步骤: 1) 块标记生成,将输入图像划分为多个块,并识别每个块中的对象; 2) 文本提示生成,根据第一步中的对象位置信息将视觉定位任务转化为填空问题。 将PTP集成到主流VLP框架中,包括PTP-ViLT、PTP-CLIP和PTP-BLIP。 |
| 实验 | 对PTP进行了多项下游任务的实证评估,并进行了全面研究。在图像-文本检索、图像字幕、视觉问答和视觉推理等任务中,PTP均取得了显著的改善。例如,PTP在MSCOCO数据集的图像-文本检索任务中,相对于ViLT基线,平均回忆率提高了5.3%,并且在类似的框架和数据量下取得了与ALBEF接近的结果。此外,我们还探讨了PTP作为一个新的预文本任务的效果,并发现它在所有任务中都优于基线模型。 |
| 结论 | 通过在多种VLP模型架构下的实验结果表明,PTP有效地提高了模型在各种视觉语言任务中的表现。特别是在图像字幕和视觉问答任务中,PTP的表现优于大多数先进的方法。这些结果证明了PTP在提高视觉语言模型的视觉定位能力方面的有效性和普适性。 |
| 阅读心得 |
这篇论文主要是提出了一种提高预训练性能的prompt方法,这种方法是: 先将图片分块,上图所示,对每一块给出一个结论格式为:The block N has a C. 就是借助于检测模型和现有的caption模型对各个block进行简单的caption并生成这种固定格式的 prompt,帮助模型生成完备准确的描述,这种方法尤其对提高方位相关的描述有用。 注意⚠️这种方法只是用来做预训练,在下游任务或者推理阶段会去掉物体检测模型。 |
【PaperReading】3. PTP
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如若转载,请注明出处:http://www.rhkb.cn/news/235610.html
如若内容造成侵权/违法违规/事实不符,请联系长河编程网进行投诉反馈email:809451989@qq.com,一经查实,立即删除!相关文章
爬虫01-爬虫原理以及爬虫前期准备工作
文章目录 1 爬虫基本原理什么是爬虫爬虫功能详解爬虫基本流程两个概念:request和response 2 一些问题爬虫能抓取什么样的数据?抓取的数据怎么提取部分内容?数据解析方式。为什么我爬虫抓取的数据和浏览器看到的不一样怎样解决JavaScript渲染的…

计算数学表达式的程序(Java课程设计)
1. 课设团队介绍 团队名称 团队成 员介绍 任务分配 团队成员博客 XQ Warriors 徐维辉 负责计算器数据的算法操作,如平方数、加减乘除,显示历史计算记录 无 邱良厦(组长) 负责计算器的图形设计,把输入和结果显…
公共用例库计划--个人版(二)主体界面设计
1、任务概述 计划内容:完成公共用例库的开发实施工作,包括需求分析、系统设计、开发、测试、打包、运行维护等工作。
1.1、 已完成: 需求分析、数据库表的设计:公共用例库计划–个人版(一)
1.2、 本次待完…
2024新年烟花代码完整版
文章目录 前言烟花效果展示使用教程查看源码HTML代码CSS代码JavaScript 新年祝福 前言
在这个充满希望和激动的2024年,新的一年即将拉开帷幕,而数字科技的创新与发展也如火如荼。烟花绚丽多彩的绽放,一直以来都是新年庆典中不可或缺的元素。…

微信小程序 组件component ts用法
还在为 使用了ts 但是组件内显示this.setData/this.data.xxx ts报错 觉得难看吗?
还在为明明定义了applyInfo,明明应该有setData为何报错?
还在为不知道如何写类型而烦心吗? 不如转变思路将methods看成为一个对象 增加断言 as a…
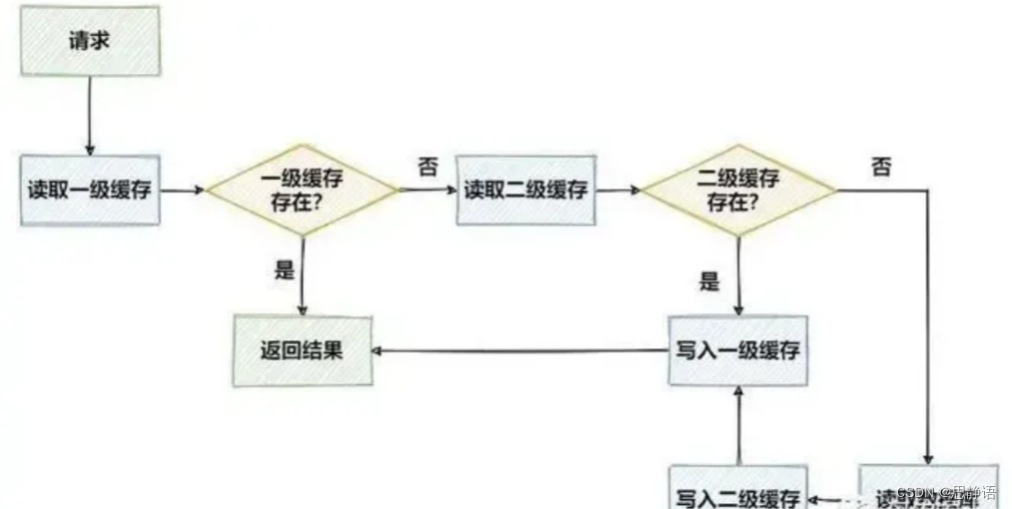
实现多级缓存(Redis+Caffeine)
文章目录 多级缓存的概述多级缓存的优势 多级缓存的概述
在高性能的服务架构设计中,缓存是一个不可或缺的环节。在实际的项目中,我们通常会将一些热点数据存储到Redis或MemCache这类缓存中间件中,只有当缓存的访问没有命中时再查询数据库。在…

公网环境使用移动端设备+cpolar远程访问本地群晖nas上的影视资源
文章目录 1.使用环境要求:2.下载群晖videostation:3.公网访问本地群晖videostation中的电影:4.公网条件下使用电脑浏览器访问本地群晖video station5.公网条件下使用移动端(搭载安卓,ios,ipados等系统的设备…
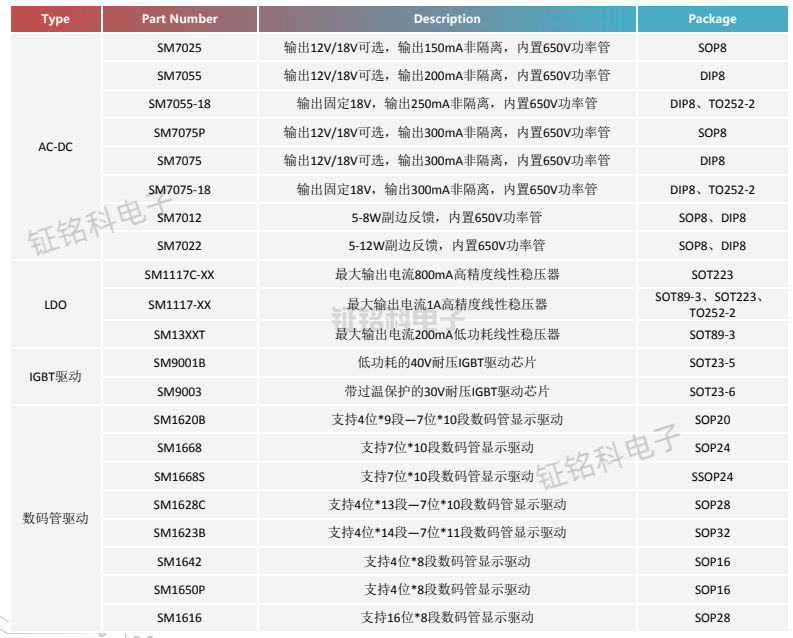
小家电应用解决方案以及选型指南
电磁炉是现代厨房中常见的一种小家电产品,它利用电磁感应加热原理,可以快速、高效地进行烹饪。在电磁炉的设计和制造过程中,功率开关芯片的选择对于产品的性能和成本有着重要的影响。
针对电磁炉的应用需求,推荐采用LED驱动芯片S…
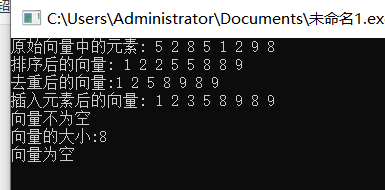
蓝桥杯省赛无忧 STL 课件12 vector
01 vector的定义和特性 02 vector的常用函数 03 vector排序去重 示例:
#include<bits/stdc.h>
using namespace std;
int main(){vector<int> vec {5,2,8,1,9};sort(vec.begin(),vec.end());for(const auto& num : vec){cout<<num<<&q…

Centos7升级openssl到openssl1.1.1
Centos7升级openssl到openssl1.1.1
1、先查看openssl版本:openssl version 2、Centos7升级openssl到openssl1.1.1 升级步骤 #1、更新所有现有的软件包列表并安装最新的软件包: $sudo yum update #2、接下来,我们需要从源代码编译和构建OpenS…
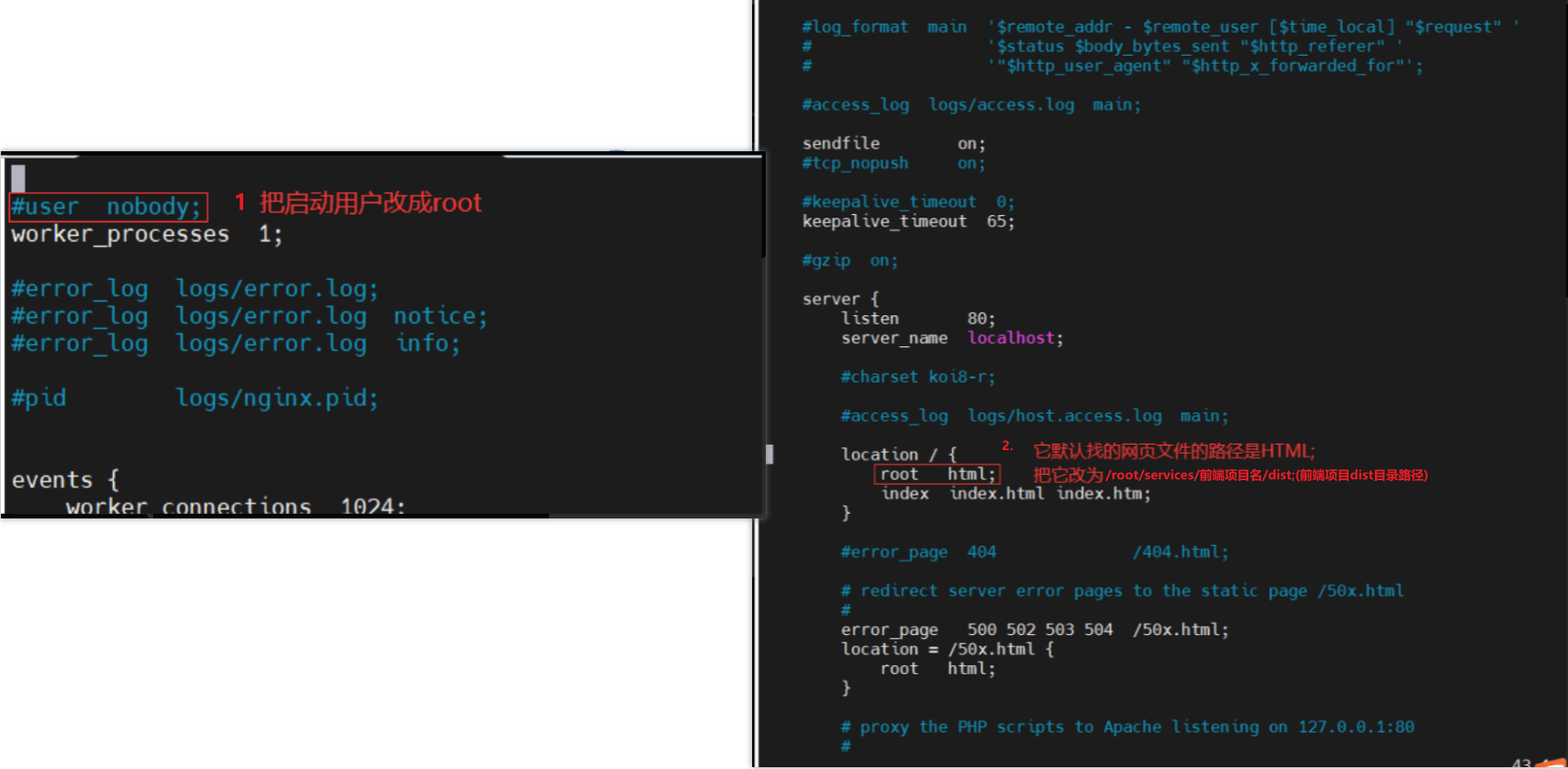
【原生部署】SpringBoot+Vue前后端分离项目
本次主要讲解SpringBootVue前后端完全分离项目在CentOS云服务器上的环境搭建与部署过程,我们主要讲解原生部署。
一.原生部署概念
原生部署是指将应用程序(一般是指软件、应用或服务)在底层的操作系统环境中直接运行和部署,而不…
微软Office 2019 批量授权版
软件介绍
微软办公软件套件Microsoft Office 2019 专业增强版2024年1月批量许可版更新推送!Office2019正式版2018年10月份推出,主要为多人跨平台办公与团队协作打造。Office2019整合对过去三年在Office365里所有功能,包括对Word、Excel、Pow…
Docker的介绍及安装基本操作命令
前言
Docker 是一个开源的应用容器引擎,基于 Go 语言 并遵从 Apache2.0 协议开源。
Docker 可以让开发者打包他们的应用以及依赖包到一个轻量级、可移植的容器中,然后发布到任何流行的 Linux 机器上,也可以实现虚拟化。
容器是完全使用沙箱…
基于Selenium+Python的web自动化测试框架
一、什么是Selenium? Selenium是一个基于浏览器的自动化测试工具,它提供了一种跨平台、跨浏览器的端到端的web自动化解决方案。Selenium主要包括三部分:Selenium IDE、Selenium WebDriver 和Selenium Grid。
Selenium IDE:Firefo…
阿里云和AWS之间的应用程序防火墙比较及选择建议!
对于大多数开发人员来说,托管在云中的 Web 应用程序或 REST API 是一种常见方案。但是,并非每个应用程序都具有相同的安全级别。将 Web 应用程序防火墙 (WAF) 添加到 Web 应用程序是提高安全性的有用方法。
在本文中,…

Python实用小工具(4)——邮件轰炸机,给朋友搞点乐子(附源码+exe文件)
欢迎来到MatpyMaster!今天我们将使用Python来批量发送邮件,让你的邮件推送变得更加高效。废话不多说,直接开搞!使用声明: 请确保你的邮箱开启了SMTP服务,并获取了授权码。 选择合适的发送间隔,…

VBA中类的解读及应用第八讲:实现定时器功能的自定义类事件
《VBA中类的解读及应用》教程【10165646】是我推出的第五套教程,目前已经是第一版修订了。这套教程定位于最高级,是学完初级,中级后的教程。
类,是非常抽象的,更具研究的价值。随着我们学习、应用VBA的深入࿰…
【PaperReading】5. Open-Vocabulary SAM
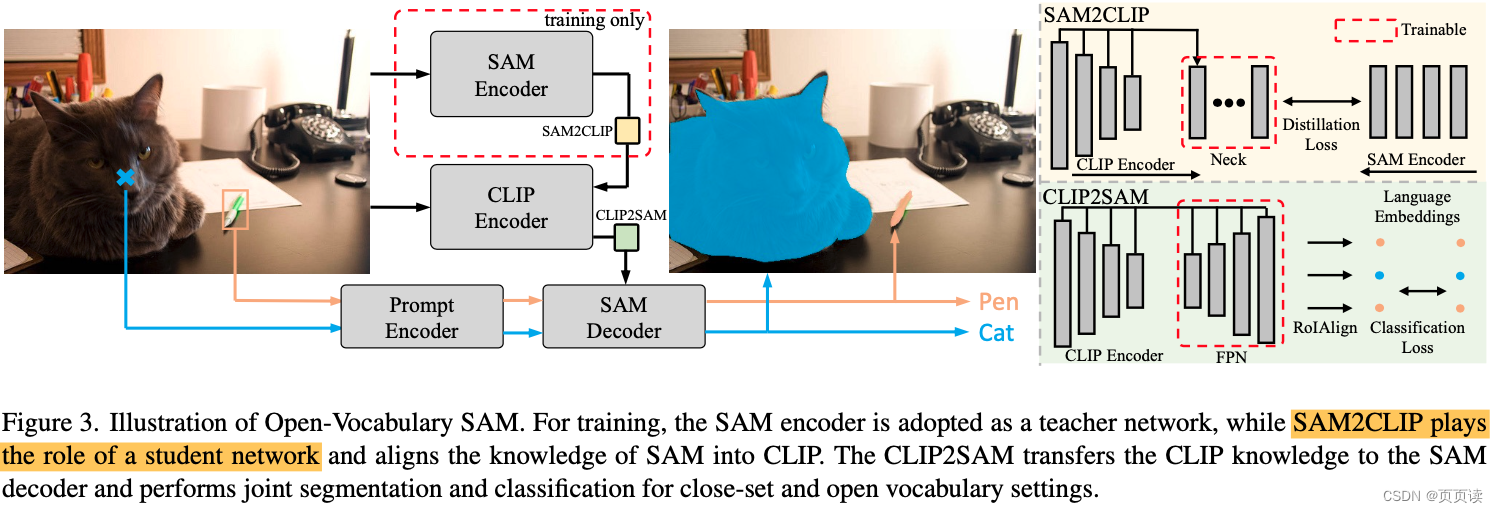
Category Content 论文题目 Open-Vocabulary SAM: Segment and Recognize Twenty-thousand Classes Interactively 作者 Haobo Yuan1 Xiangtai Li1 Chong Zhou1 Yining Li2 Kai Chen2 Chen Change Loy1 1S-Lab, Nanyang Technological University 2Shanghai Artificial In…
找不到msvcr120.dll怎样修复,分享4种修复方法
msvcr120.dll是Microsoft Visual C 2012 Redistributable Package的一个关键组件,负责提供C运行时库。许多应用程序在运行时都需要依赖这个库文件。然而,在日常使用过程中,不少用户会遇到msvcr120.dll丢失的问题,导致程序无法正常…
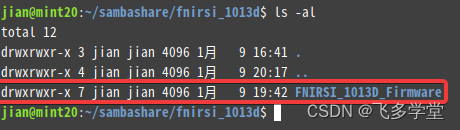
Linux 文件(夹)权限查看
命令 : ls -al
ls -al 是一个用于列出指定目录下所有文件和子目录的命令,包括隐藏文件和详细信息。其中,-a 选项表示显示所有文件,包括以 . 开头的隐藏文件,-l 选项表示以列表的形式显示文件的详细信息。 本例中:drwxrwxr-x 为权限细节。
权限细节(Permission detail…
最新文章
- wordpress 如何审核文章/b站视频未能成功转码
- wordpress机械主题/信息流广告优化
- 网站怎样优化关键词好/石家庄网络推广优化
- wordpress文本块/怎样做网站卖自己的产品
- 医院网站建设步骤/网络营销岗位有哪些
- 网站公安备案 多久/天津短视频seo
- 【信息系统项目管理师】高分论文:论信息系统项目的成本管理(车站设备智能化管理平台)
- windows安装Elasticsearch及增删改查操作
- 在 Go 中利用 ffmpeg 进行视频和音频处理
- aws(学习笔记第十九课) 使用ECS和Fargate进行容器开发
- 电脑使用CDR时弹出错误“计算机丢失mfc140u.dll”是什么原因?“计算机丢失mfc140u.dll”要怎么解决?
- Set集合进行!contains判断IDEA提示Unnecessary ‘contains()‘ check
推荐文章
- 软考-高级-系统架构设计师教程(清华第2版)【第18章 安全架构设计理论与实践(P648~690)-思维导图】
- 软考-高级-信息系统项目管理师教程 第四版【第19章-配置与变更管理-思维导图】
- 运行paddlehub报错,提示:UnicodeDecodeError: ‘gbk‘ codec can‘t decode byte…**
- !力扣70. 爬楼梯
- # wps必须要登录激活才能使用吗?
- #C++ enum枚举
- (09)Hive——CTE 公共表达式
- (13)Hive调优——动态分区导致的小文件问题
- (18)线程的实例认识:线程的控制,暂停,继续,停止,线程相互控制,协作
- (2024,预训练扩散模型,参考 UNet,创建引导数据集)BootPIG:在预训练扩散模型中引导零样本个性化图像生成
- (Qt5Gui.dll)处(位于 xxx.exe 中)引发的异常: 0xC0000005: 读取位置 XXXXXXXX 时发生访问冲突
- (React/Vue+BPMN.js)前端项目——BPMN工作流设计器