倒排索引:
组成
term index(词项索引 ,存放前后缀指针)
Term Dictionary(词项字典,所有词项经过文档与处理后按照字典顺序组成的一个字典(相关度))
Posting List(倒排表,,包含Term的id数组(int类型有序数组,且不重复)、词频、postion、payload、offset等信息)包含两个压缩算法,FOR,RBM
一句话概括:倒排索引就是某个词项到包含当前这个词项id的映射关系
FOR
Frame Of Reference 又叫增量编码压缩,首先Elasticsearch要求倒排索引是有序的(也就是文档id是有序排列的),es会根据文档id两两计算差值,然后根据计算出来的值进行分块,每一块取最大值计算它是2的几次方,得出该块中每一个数字可以用多少个bit位来存储,另外还需要一个字节来表示每一个数据块是用多少bit位来存储一个数字的
FOR算法的核心是用减法来缩减数值大小
RBM
数组中每个数除以2^16,以商,余数的形式表示出来,将相同商的归在一个Container,如果Contaniner中数值容量超过4096使用bitmap的形式来存储一个Container中的数,如果没有超过那就使用short[]来存储,如果是连续数组那就使用RunContainer来存储,其中container分为 ArrayContainer、BitmapContainer、RunContainer三种
ArrayContainer ArrayContainer采用简单的short数组存储低16位数据,content始终有序且不重复,方便二分查,最大数据量是4096,即8kb, 超过则使用BitmapContainer
BitmapContainer BitmapContainer采用long数组存储低16位数据,BitmapContainer构造方法会初始化一个长度为1024的long数组,因此BitmapContainer无论是存1个数据,10个数据还是最大65536个数据,都始终占据着8kb的内存空间
RunContainer RunContainer主要解决了大量连续数据的问题,原理就是记录初始数字以及连续的数量,但是这种压缩方式对于数据的疏密程度非常敏感,如果Container中所有数据都是连续的,这种压缩方式就会占据优势,如果Container中所有数据都是不连续的且都是偶数或奇数,这种不仅没有压缩反而会膨胀,因此是否选择使用RunContainer是需要判断的,RBM提供了一个转化方法为runOptimize()用于对比和其他两种Container的空间大小,若占据优势则会进行转化
RBM的核心就是通过除法来缩减数值大小
词项索引的检索原理:FST
词项索引数据结构为Trie树,即字典树,又称单词查找树或键树,是一种树形结构,是一种哈希树的变种(基于FST实现)。典型应用是用于统计和排序大量的字符串(但不仅限于字符串),所以经常被搜索引擎系统用于文本词频统计。它的优点是:最大限度地减少无谓的字符串比较。Trie的核心思想是空间换时间,利用字符串的公共前缀来降低查询时间的开销以达到提高效率的目的

前缀树的3个基本性质
1、根节点不包含字符,除根节点外每一个节点都只包含一个字符 2、从根节点到某一节点,路径上经过的字符连接起来,为该节点对应的字符串 3、每个节点的所有子节点包含的字符都不相同
lucene从4开始大量使用的数据结构是FST(Finite State Transducer)。FST有两个优点:
-
空间占用小。通过对词典中单词前缀和后缀的重复利用,压缩了存储空间;
-
查询速度快。O(len(str))的查询时间复杂度
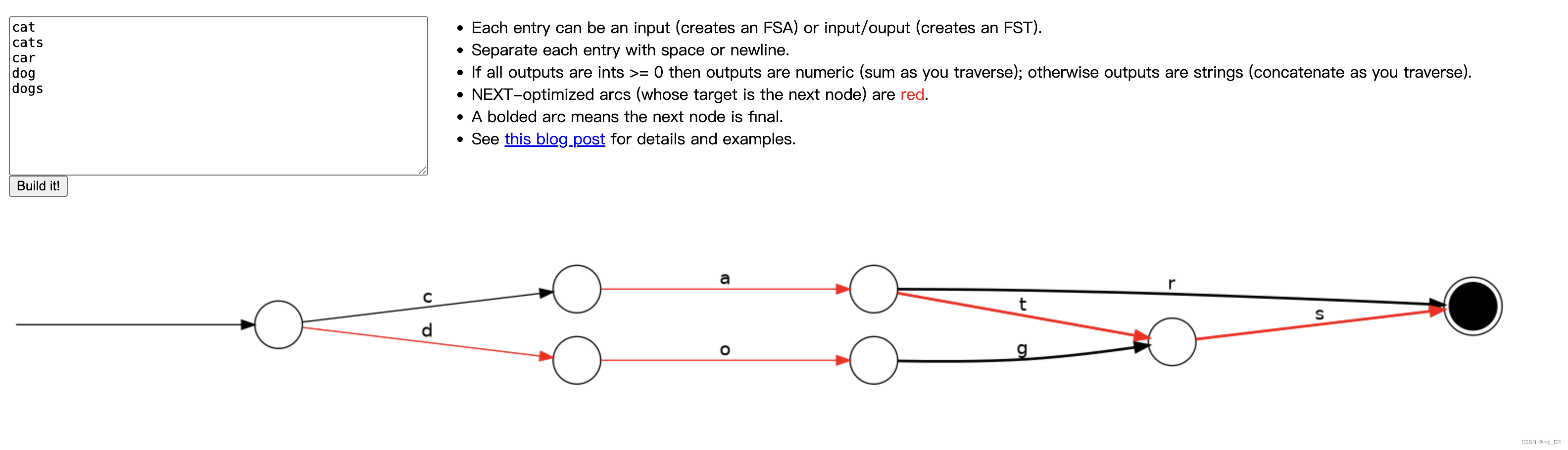
FST网页地址:http://examples.mikemccandless.com/fst.py?terms=cat%0D%0Acats%0D%0Acar%0D%0Adog%0D%0Adogs&cmd=Build+it%21
分词的发生时期
1.创建索引时对元数据进行分词
2.执行搜索时对 搜索词分词
正排索引
排索引是按照文档编号或文档ID等有序的方式将每个文档存储在索引中,通过文档编号或ID进行检索
doc values 是正排索引的基本数据结构之一,其存在是为了提升排序和聚合效率,默认true,如果确定不需要对字段进行排序或聚合,也不需要通过脚本访问字段值,则可以禁用doc values值以节省磁盘空间(不支持 text和annotated_text)


![XCTF:MISCall[WriteUP]](https://img-blog.csdnimg.cn/direct/fc9652c31d384e08b11c7a7209200a53.png)