Update1
2024.1.0更新:
Go 团队将修改 for 循环变量的语义,Go1.21 新版本即可体验!
今天看见了这篇文章,Go的1.22版本将更新,大致理解未会默认进行v:=v这个操作,因此此文所概述的许多坑,在1.22之后都可能会更新。
2024.2就会发布新版本,到时候再测试一下看看情况。
前言
基础语法不再赘述,写这个原因是之前的某次面试被问道了,我知道会导致问题但具体答下来不是很通顺。再回想自己开发过程中,很多地方都是使用到了for/for range,但是却从没注意过一些细节,因此专门学习一下进行记录。
对一个数组循环,for range,使用kv时候有什么要注意的吗?
这个是当时面经记录的问题。因此顺着这里开始进行学习。

for和for range基本语法
for的用法大概可以类比C++里面的for和while
//类似C++的for
for i := 0; i < 10; i++ {fmt.Println(i)
}
//类似C++的while
j := 0
for j < 10 {fmt.Println(j)j++
}//死循环
for {fmt.Println("无限循环")
}
fo range用法大概可以类比python的range。但是golang中他的用法更多,大致四种
//遍历数组:
numbers := [3]int{1, 2, 3}
for index, value := range numbers {fmt.Printf("索引:%d 值:%d\n", index, value)
}
//遍历切片:
names := []string{"Alice", "Bob", "Charlie"}
for index, name := range names {fmt.Printf("索引:%d 值:%s\n", index, name)
}
//遍历 map:
ages := map[string]int{"Alice": 25, "Bob": 30, "Charlie": 35}
for name, age := range ages {fmt.Printf("%s 的年龄是 %d 岁\n", name, age)
}
//遍历字符串:
sentence := "Hello, 世界"
for index, char := range sentence {fmt.Printf("索引:%d 字符:%c\n", index, char)
}
for和for range的区别
对于一个数组,例如a[3]={3.2.1},可以通过两种方式进行遍历:
func main() {fmt.Println("下面是for range遍历")var m = []int{1, 2, 3}for k, v := range m {fmt.Println(k, v)fmt.Println(&k, &v)}fmt.Println("下面是for遍历")for i := 0; i < 3; i++ {fmt.Println(i, m[i])fmt.Println(&i, &m[i])}
}其结果如下:
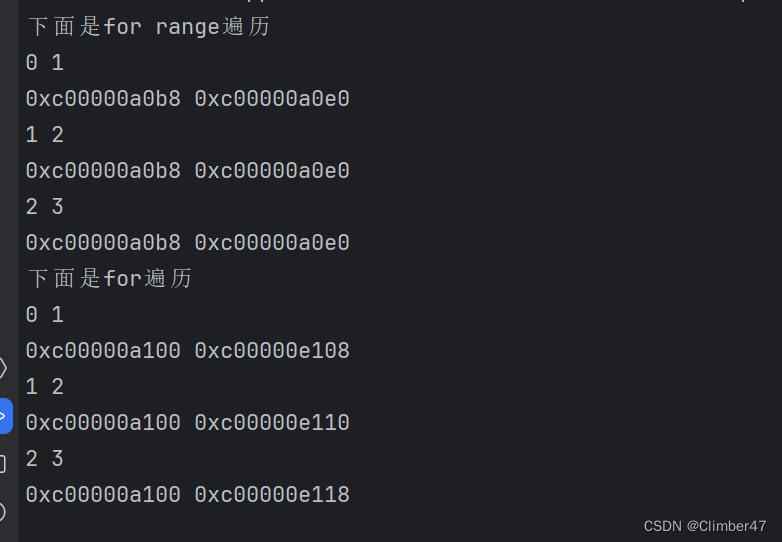
我们可以发现,输出的结果是一样的,但地址却不一样:
因此这便是二者的本质区别——
1、range遍历在开始遍历数据之前,会先拷贝一份被遍历的数据。所以在遍历过程中去修改被遍历的数据,只是修改拷贝的数据,不会影响到原数据。
2、range在遍历值类型时,其中的v是一个局部变量,只会声明初始化一次,之后每次循环时重新赋值覆盖前面的。
常见的坑
通过指针取值
//此代码来自`https://zhuanlan.zhihu.com/p/105435646`
arr := [2]int{1, 2}
res := []*int{}
for _, v := range arr {res = append(res, &v)
}
//expect: 1 2
fmt.Println(*res[0],*res[1])
//but output: 2 2
这个是由于上述的区别2——v是一个只声明一次的局部变量。
修改方案两种:1、通过arr[k]获取值,而不是v。
2、使用一个局部变量:tmp :=v,之后对tmp处理。
循环中添加元素是否会导致死循环
func main() {s := []int{0, 1}for _, v := range s {s = append(s, v)}fmt.Printf("s=%v\n", s)
}
大致意思是这样会不会死循环?
这个是上面的性质1。range因为是对复制的数据在操作,所以不会影响。普通的for则会影响。
https://cloud.tencent.com/developer/article/1925475
此部分具体参考此例即可。
对大数据的操作
对于很大数据的数组,若采取range遍历,因为复制的缘故,所以会导致开销巨大。(具体见下的性能分析)
但是在大数据的数组下,使用range去重置(全部赋值为0),效率是高的。原因是内存是连续的,编译器会直接清空这一片的内存。具体讲解见此
demo和源码看这里的3和4
对于map的操作
具体来说,就是边遍历边新增/删除。删除了的不可能再遍历到,新增的可能再遍历到(不一定)。
原因:map内部实现是一个链式hash表,为了保证无顺序,初始化时会随机一个遍历开始的位置,所以新增的元素被遍历到就变的不确定了,同样删除也是一个道理,但是删除元素后边就不会出现,所以一定不会被遍历到。
具体参考此文的最后部分
range中开goroutine
func main() {var m = []int{1, 2, 3}for i := range m {go func() {fmt.Print(i)}()}time.Sleep(time.Millisecond)}
会发现输出结果有随机性:发现结果是222。原因是上述的那个,k、v是同一值,他并没有保存到goroutine的栈中。
解决方法还是局部变量,但可能出现012、210、102这样的值…原因是运行太快了,所以顺序不一定…
附1:range遍历的性能分析
for range需要进行一步复制操作,因此显然需要比for更多的性能开销。但是对于切片来说,因为切片的副本和原切片都是指向数组的地址,所以性能一样。
具体见此文。
https://blog.csdn.net/EDDYCJY/article/details/124701572
附2:一个坑中坑——map的range遍历并不是随机
具体参考此文
结论是:第一位的元素会有更高的概率被首先选中。因此不可用map遍历的随机性,作为随机选择map中元素的方法。
参考资源
Go 处理大数组:使用 for range 还是 for 循环?
Go的循环遍历使用小坑
Go 中for range的一个坑
Go语言中for-range使用踩坑指南
Dig101 - Go之for-range排坑指南
Golang 语言 for 和 for-range 的区别
5.1 for 和 range #

![[NSSCTF Round#16 Basic] CPR](https://img-blog.csdnimg.cn/direct/806f9c55dccc4ba58f809ee984bc272e.png)