时间序列也称动态序列,是指将某种现象的指标数值按照时间顺序排列而成的数值序列。时间序列分析大致可分成三大部分,分别是描述过去、分析规律和预测未来,本讲将主要介绍时间序列分析中常用的三种模型:季节分解、指数平滑方法和ARIMA模型,并将结合Spss软件对时间序列数据进行建模。
注:本文源于数学建模学习交流相关公众号观看学习视频后所作
时间序列
时间序列数据:
对同一对象在不同时间连续观察所取得的数据。

例如:
(1)从出生到现在,你的体重的数据(每年生日称一次)。
(2)中国历年来GDP的数据。
(3)在某地方每隔一小时测得的温度数据。
时间序列概念
时间序列也称动态序列,是指将某种现象的指标数值按照时间顺序排列而成的数值序列。
时间序列由两个组成要素构成:
(1)第一个要素是时间要素: 年、季度、月、周、日、小时、分钟、秒
(2)第二个要素是数值要素。
时间序列根据时间和数值性质的不同,可以分为时期时间序列和时点时间序列。
时期序列中,数值要素反映现象在一定时期内发展的结果;
时点序列中,数值要素反映现象在一定时点上的瞬间水平。
区分时期和时点时间序列
例如:
(1)从出生到现在,你的体重的数据(每年生日称一次)。
(2)中国历年来GDP的数据。
(3)在某地方每隔一小时测得的温度数据。
(1)和(3)是时点时间序列;(2)是时期时间序列
时期序列可加,时点序列不可加。
时期序列中的观测值反映现象在一段时期内发展过程的总量,不同时期的观测值可以相加,相加结果表明现象在更长一段时间内的活动总量; 而时点序列中的观测值反映现象在某一瞬间上所达到的水平,不同时期的观测值不能相加,相加结果没有实际意义。
(灰色预测模型里面有一个累加的过程)
时间序列分解
因为时间序列是某个指标数值长期变化的数值表现,所以时间序列数值变化背后必然蕴含着数值变换的规律性,这些规律性就是时间序列分析的切入点。
一般情况下,时间序列的数值变化规律有以下四种:

一个时间序列往往是以上四类变化形式的叠加。
长期趋势:T
长期趋势 (Secular trend,T) 指的是统计指标在相当长的一段时间内,受到长期趋势影响因素的影响,表现出持续上升或持续下降的趋势,通常用字母 T 表示。例如,随着国家经济的发展,人均收入将逐渐提升;随着医学水平的提高,新生儿死亡率在不断下降。
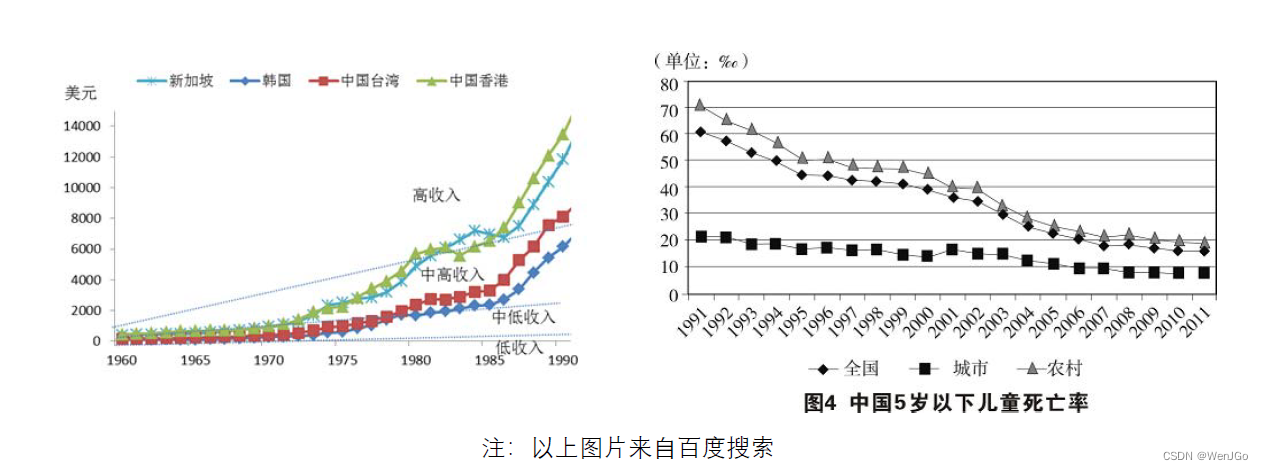
季节趋势:S
季节趋势(Seasonal Variation,S)是指由于季节的转变使得指标数值发生周期性变动。这里的季节是广义的,一般以月、季、周为时间单位,不能以年作单位。例如雪糕和棉衣的销量都会随着季节气温的变化而周期变化。每年的长假(五一、十一、春节)都会引起出行人数的大量增加。
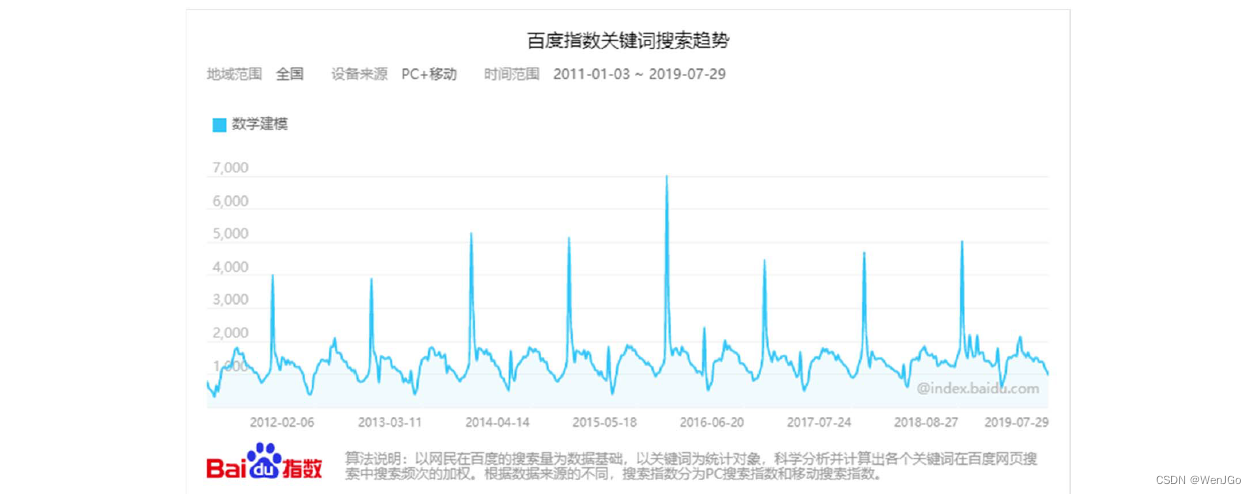
百度指数 (baidu.com)
循环变动:C
循环变动(Cyclical Variation,C)与季节变动的周期不同,循环变动通常以若干年为周期,在曲线图上表现为波浪式的周期变动。这种周期变动的特征表现为增加和减少交替出现,但是并不具严格规则的周期性连续变动。最典型的周期案例就是市场经济的商业周期和的整个国家的经济周期。

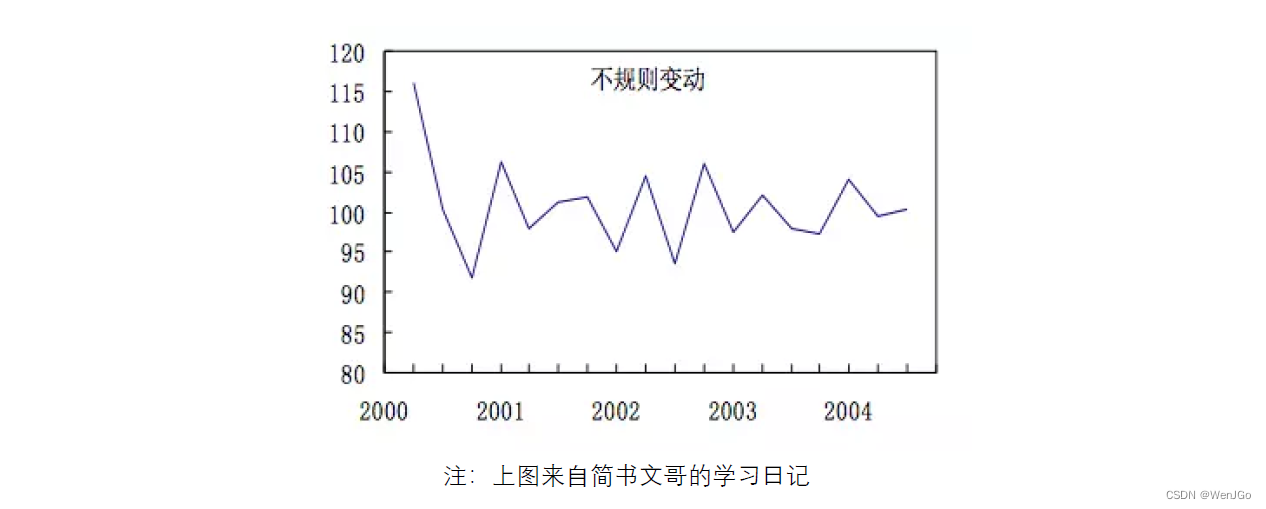
不规则变动:I
不规则变动(Irregular Variation,I)是由某些随机因素导致的数值变化,这些因素的作用是不可预知和没有规律性的,可以视为由于众多偶然因素对时间序列造成的影响(在回归中又被称为扰动项)。
以上四种变动就是时间序列数值变化的分解结果。有时这些变动会同时出现在一个时间序列里面,有时也可能只出现一种或几种,这是由引起各种变动的影响因素决定的。正是由于变动组合的不确定性,时间序列的数值变化才那么千变万化。
四种变动与指标数值最终变动的关系可能是叠加关系,也可能是乘积关系。
叠加模型和乘积模型
(1)如果四种变动之间是相互独立的关系,那么叠加模型可以表示为:
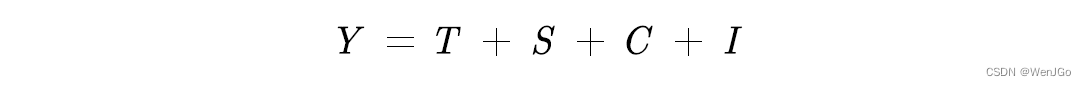
(2)如果四种变动之间存在相互影响关系,那么应该使用乘积模型:


注意:
(1)数据具有年内的周期性时才能使用时间序列分解,例如数据是月份数据(周期为12)、季度数据(周期为4) ,如果是年份数据则不行。
(2)在具体的时间序列图上,如果随着时间的推移,序列的季节波动变得越来越大,则反映各种变动之间的关系发生变化,建议使用乘积模型;反之,如果时间序列图的波动保持恒定,则可以直接使用叠加模型;当然,如果不存在季节波动,则两种分解均可以。
小例子

随着时间变化,搜索美赛数据的季节波动越来越大,那么使用乘积模型会更精确。

随着时间变化,销售数据的季节波动越来越大,那么使用乘积模型会更精确。
Spss操作
Spss处理时间序列中的缺失值
(1) 缺失值发生在时间序列的开头或者尾部,可采用直接删除的方法。
(2)缺失值发生在序列的中间位置,则不能删除(删除后原有的时间序列会错位),可采用替换缺失值的方法。

替换缺失值的五种方法

Spss定义时间变量
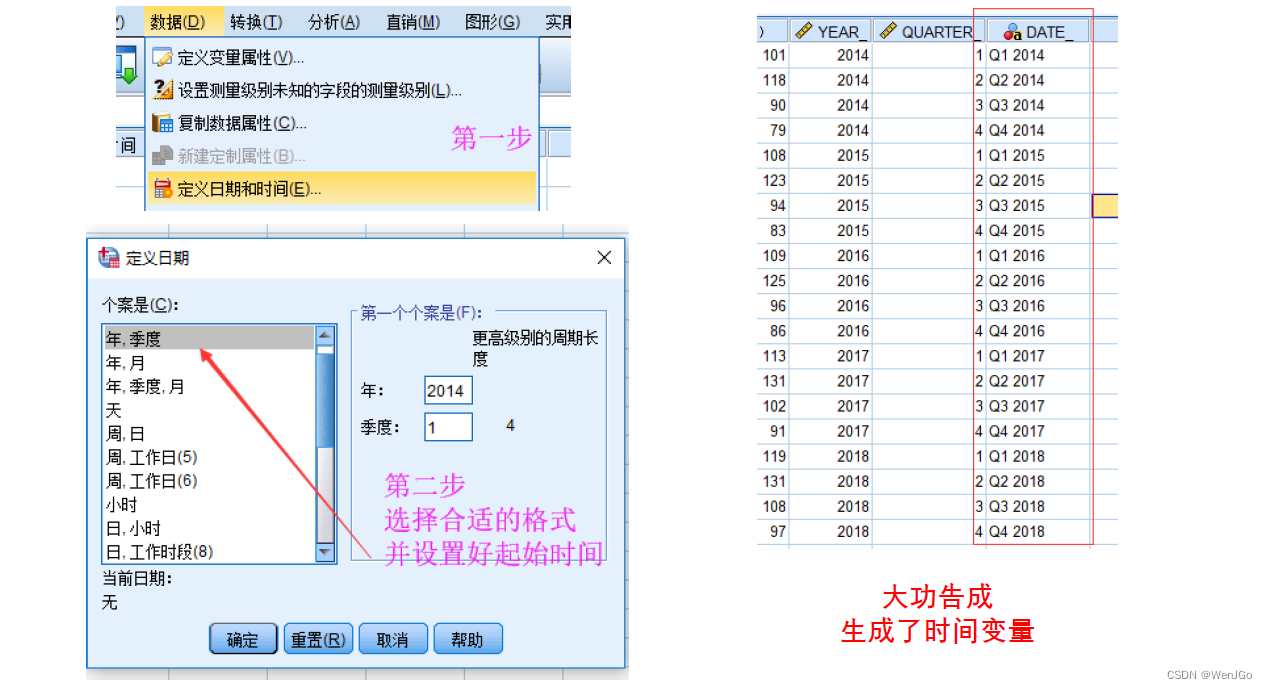
时间序列图(时序图)
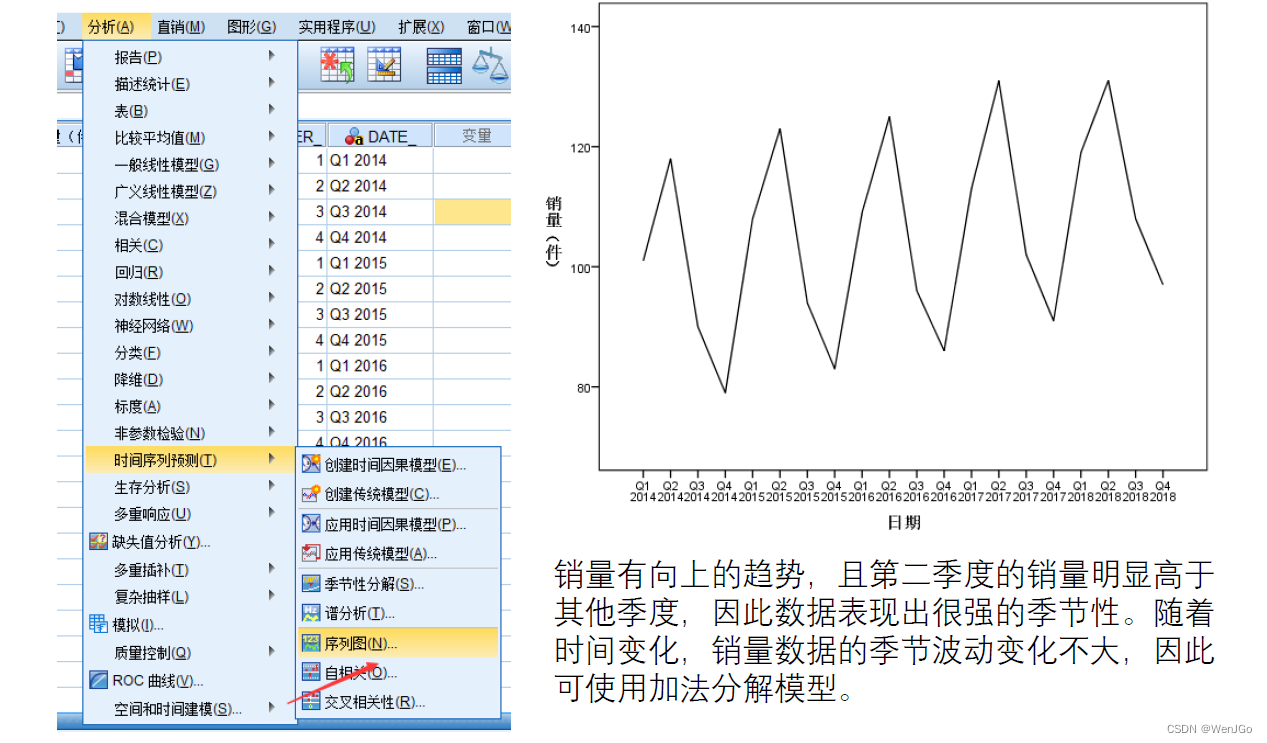
季节性分解

结果解读

画出分解后的时序图

时间序列分析
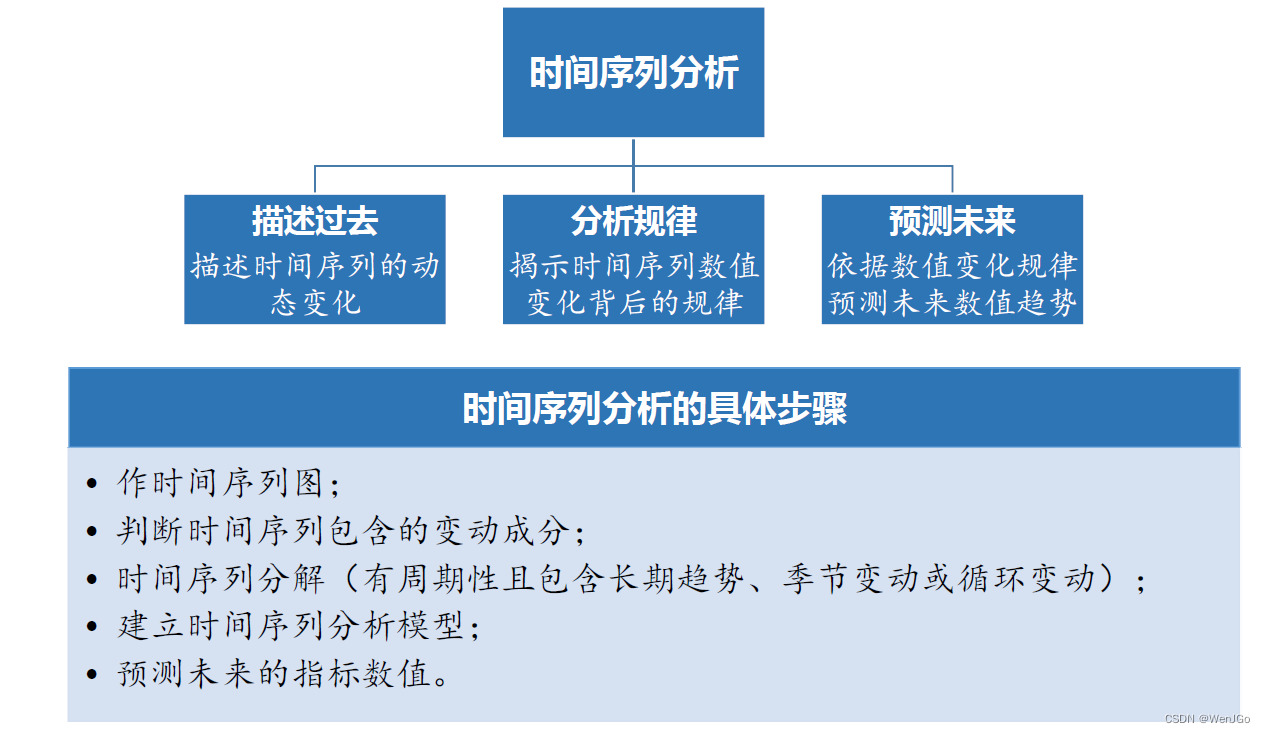
建立时间序列分析模型

指数平滑模型(Spss官方文档)

Simlpe模型

关于平滑系数𝛼的选取原则:
(1)如果时间序列具有不规则的起伏变化,但长期趋势接近一个稳定常数,α值一般较小(取0.05‐0.02之间)
(2)如果时间序列具有迅速明显的变化倾向,则α应该取较大值(取0.3‐0.5)
(3)如果时间序列变化缓慢,亦应选较小的值(一般在0.1‐0.4之间)实际上,Spss的专家建模如果选择了Simple模型用来估计,那么软件会帮我们自动选取一个适合的平滑系数使得预测误差最小。
简单指数平滑法预测

线性趋势模型(linear trend)

参考:7.2 Trend methods | Forecasting: Principles and Practice (2nd ed) (otexts.com)
阻尼趋势模型(Damped trend)

霍特趋势和阻尼趋势预测
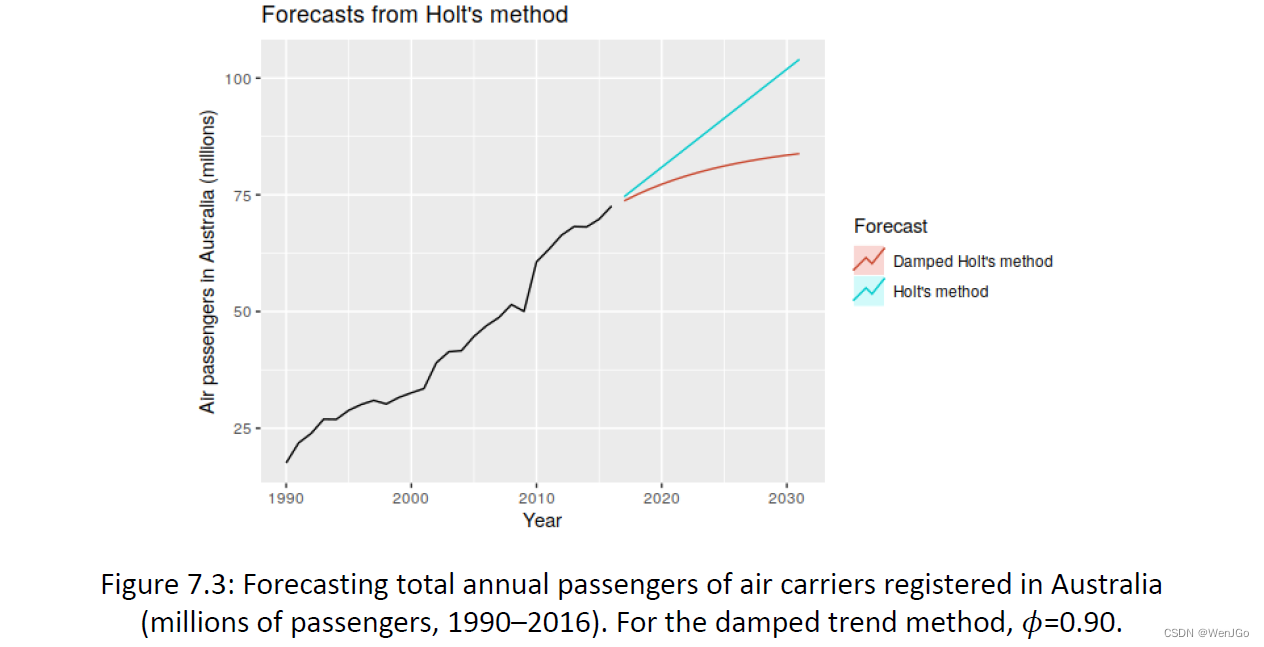
7.2 Trend methods | Forecasting: Principles and Practice (2nd ed) (otexts.com)
简单季节性(Simple seasonal)

7.4 A taxonomy of exponential smoothing methods | Forecasting: Principles and Practice (2nd ed) (otexts.com)
温特加法模型(Winters' additive)

Forecasting: Principles and Practice (otexts.com)
温特乘法模型(Winters' multiplicative)

Forecasting: Principles and Practice (otexts.com)
温特加法和乘法预测
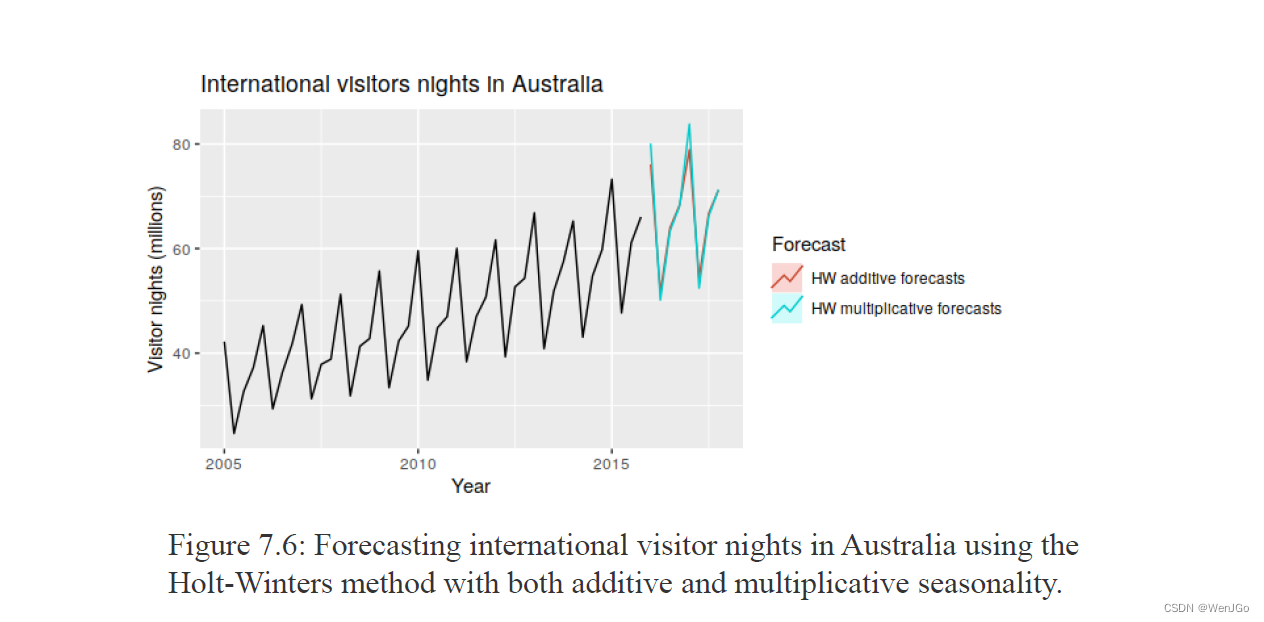
Forecasting: Principles and Practice (otexts.com)
一元时间序列分析的模型
下面的这些概念只介绍一个大概,要完全弄懂还需要大家课后自己努力。如果实在学习这小部分有困难,大家可以选择放弃理论部分,不用细究每一个细节和概念,我们的重心可以放在运用上。
(1)平稳时间序列和白噪声序列
(2)差分方程和滞后算子
(3)AR模型
(4)MA模型
(5)ARMA模型
(6)ACF和PACF
(7)ARMA模型的估计
(8)AIC和BIC准则
(9)ARIMA模型
(10)SARIMA模型
时间序列的平稳性(stationary series)

一些时间序列的图形
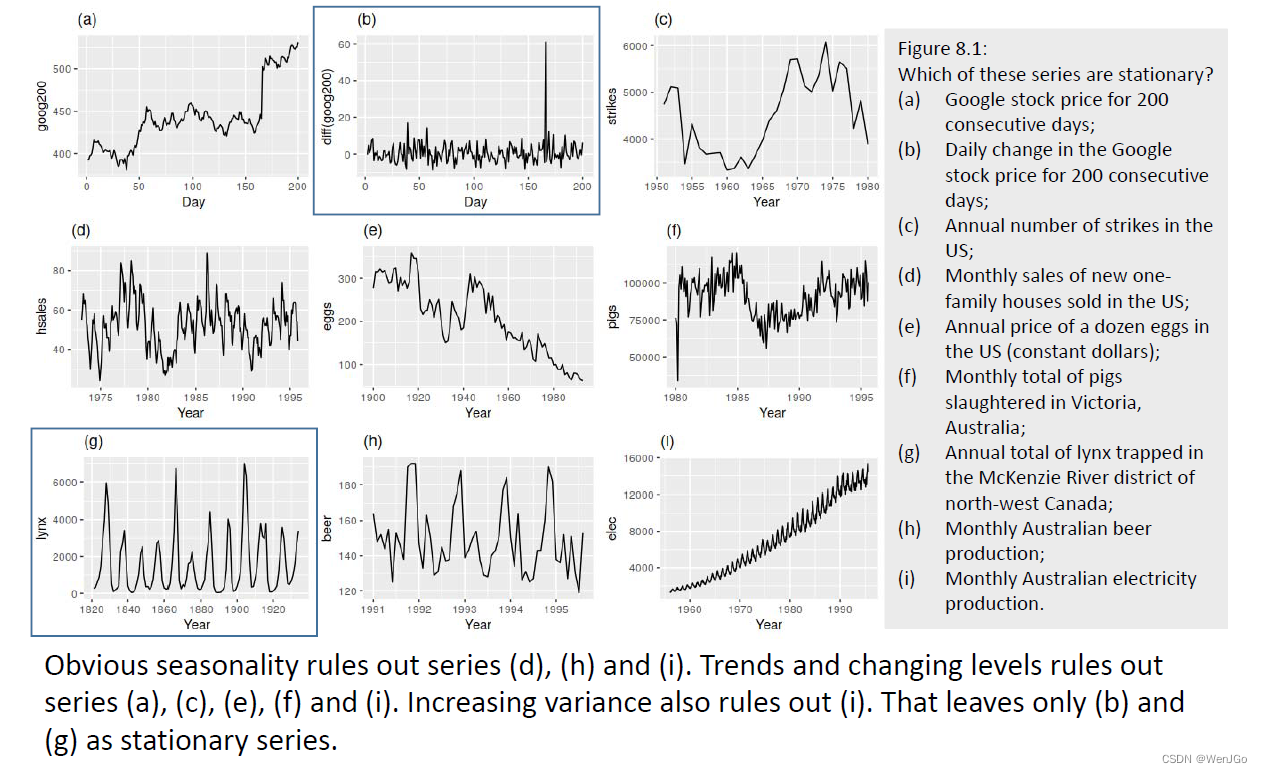
差分方程
将某个时间序列变量表示为该变量的滞后项、时间和其他变量的函数,这样的一个函数方程被称为差分方程。

差分方程的齐次部分:只包含该变量自身和它的滞后项的式子。
差分方程的特征方程
差分方程的齐次部分:只包含该变量自身和它的滞后项的式子。

这p个解的模长(实根取绝对值,虚根取模)的大小决定了形为ARMA(p,q)模型的{}是否平稳
滞后算子

MA模型、AR模型和ARMA(p,q)模型
AR(p)模型(auto regressive)
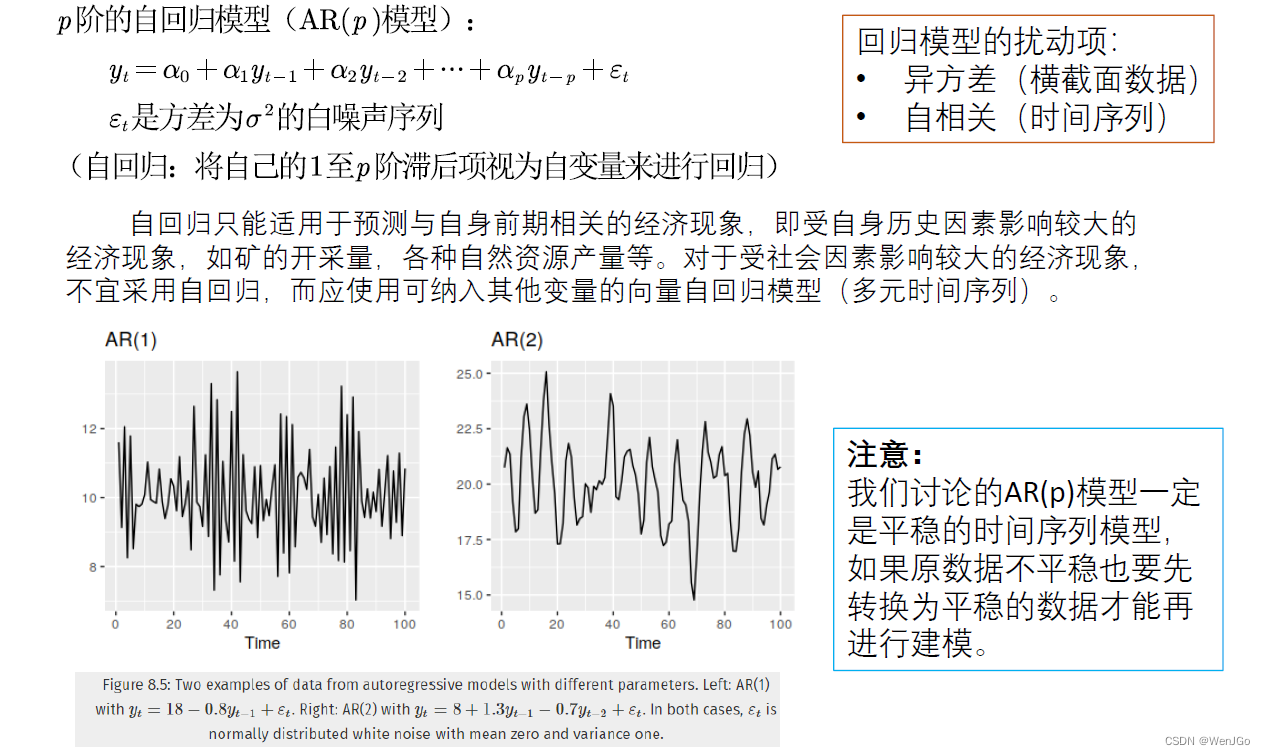
AR(p)模型平稳的条件

小例子

MA(q)模型(moving average)
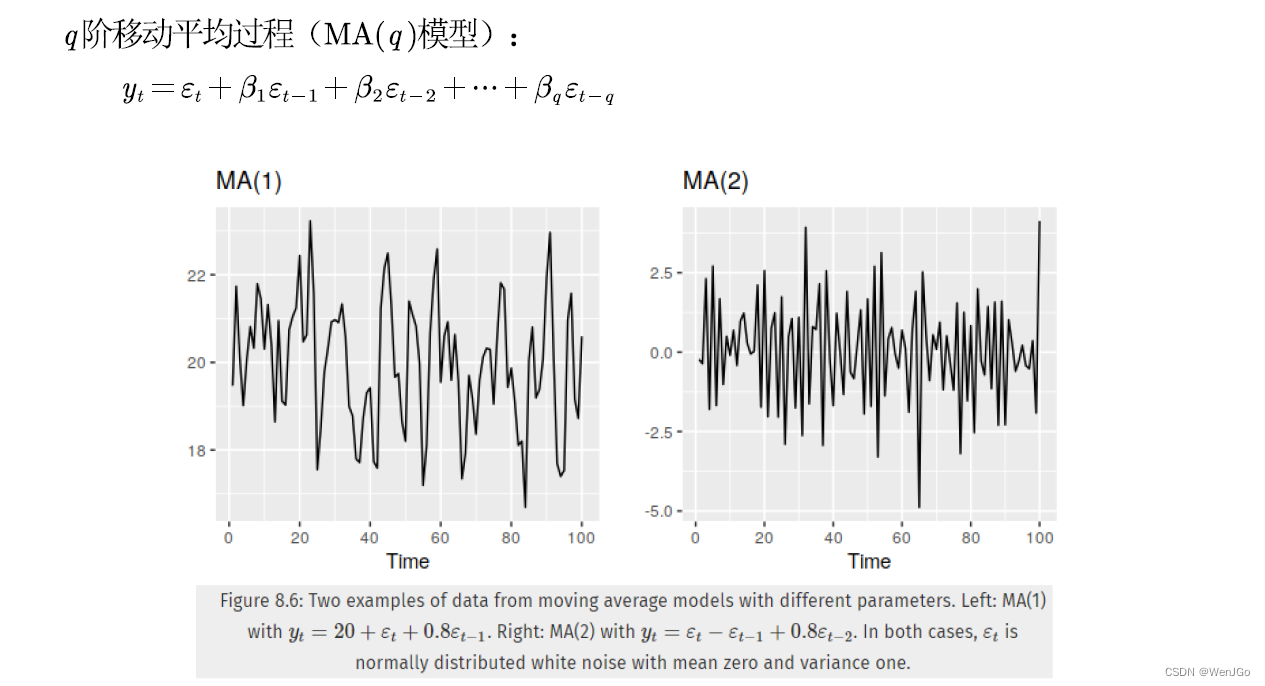
MA模型和AR模型的关系

MA(q)模型的平稳性

只要q是常数,那么MA(q)模型一定是平稳的。
ARMA(p,q)模型
自回归移动平均模型(Autoregressive Moving Average,ARMA),就是设法将自回归过程AR和移动平均过程MA结合起来,共同模拟产生既有时间序列样本数据的那个随机过程的模型。

ARMA(p,q)模型的平稳性

ACF自相关系数

PACF偏自相关函数

AR(1)模型(系数符号相反)
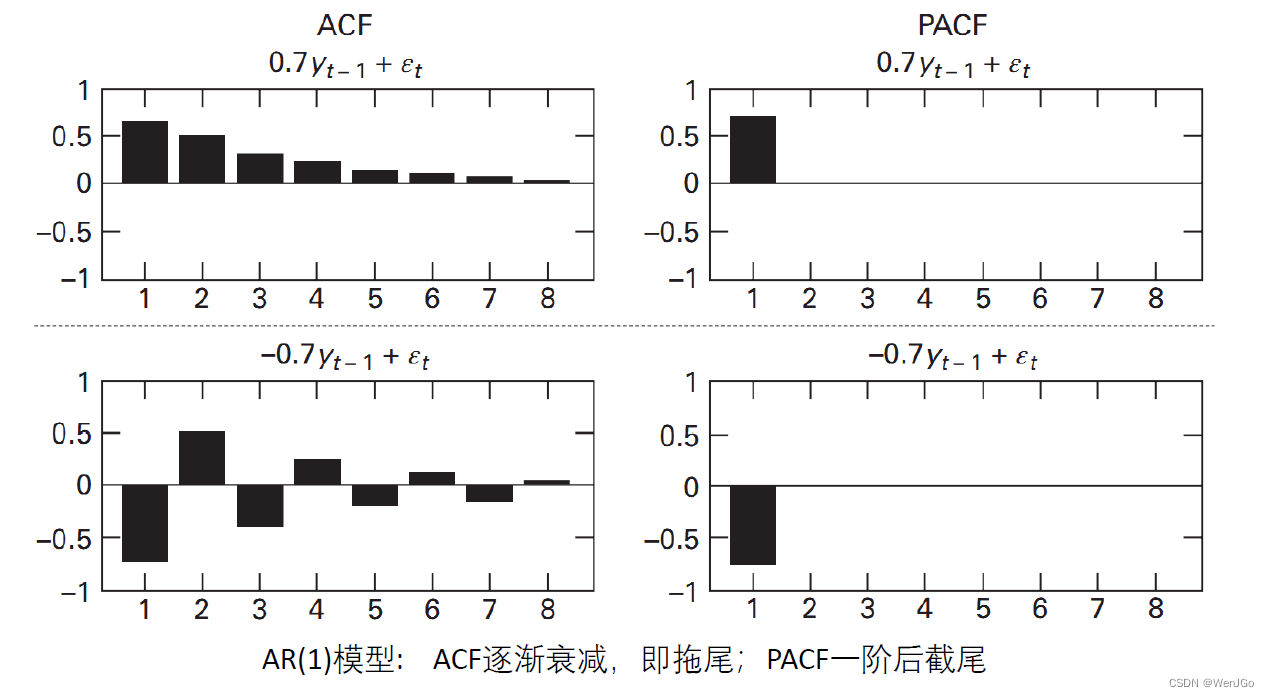
Walter Enders《Applied Econometric Time Series Fourth Edition》
MA(1)和AR(2)模型

ARMA(1,1)模型和总结表格
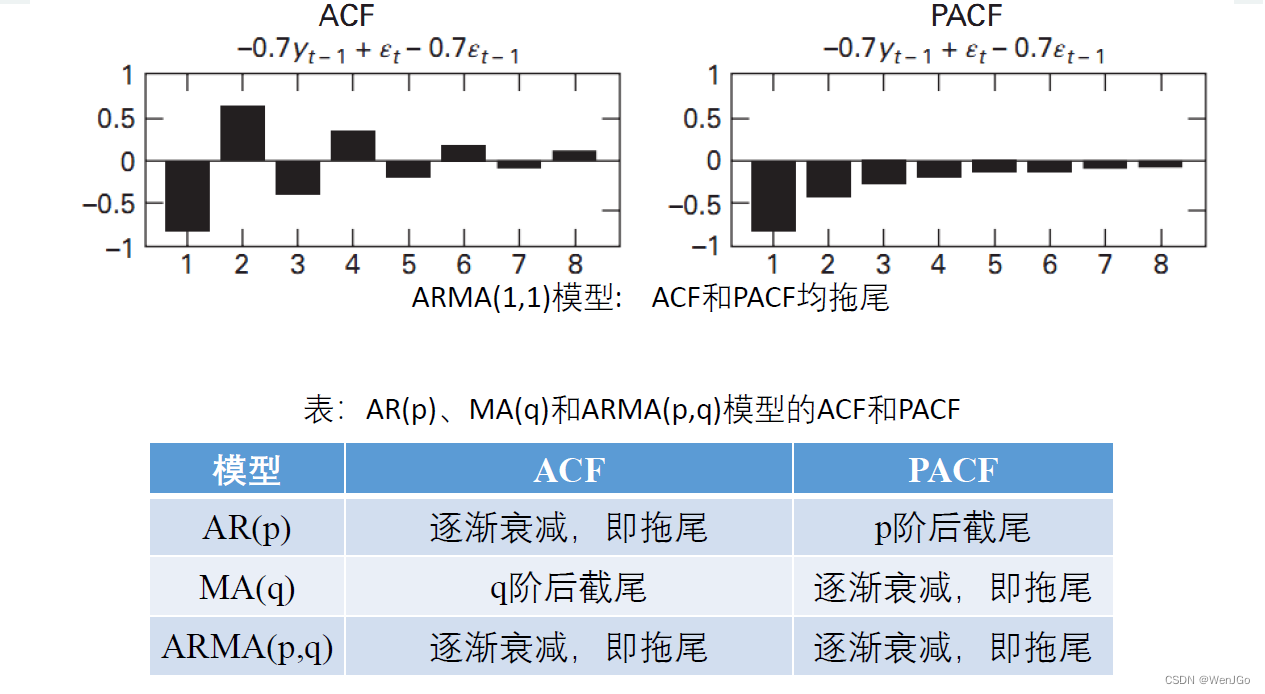
ARMA模型的识别
图1和图2上均有两条蓝色的线,其表示假设检验对应的上下临界值,如果自相关系数或偏自相关系数位于这两条线内,则认为它们与0没有显著的差异。

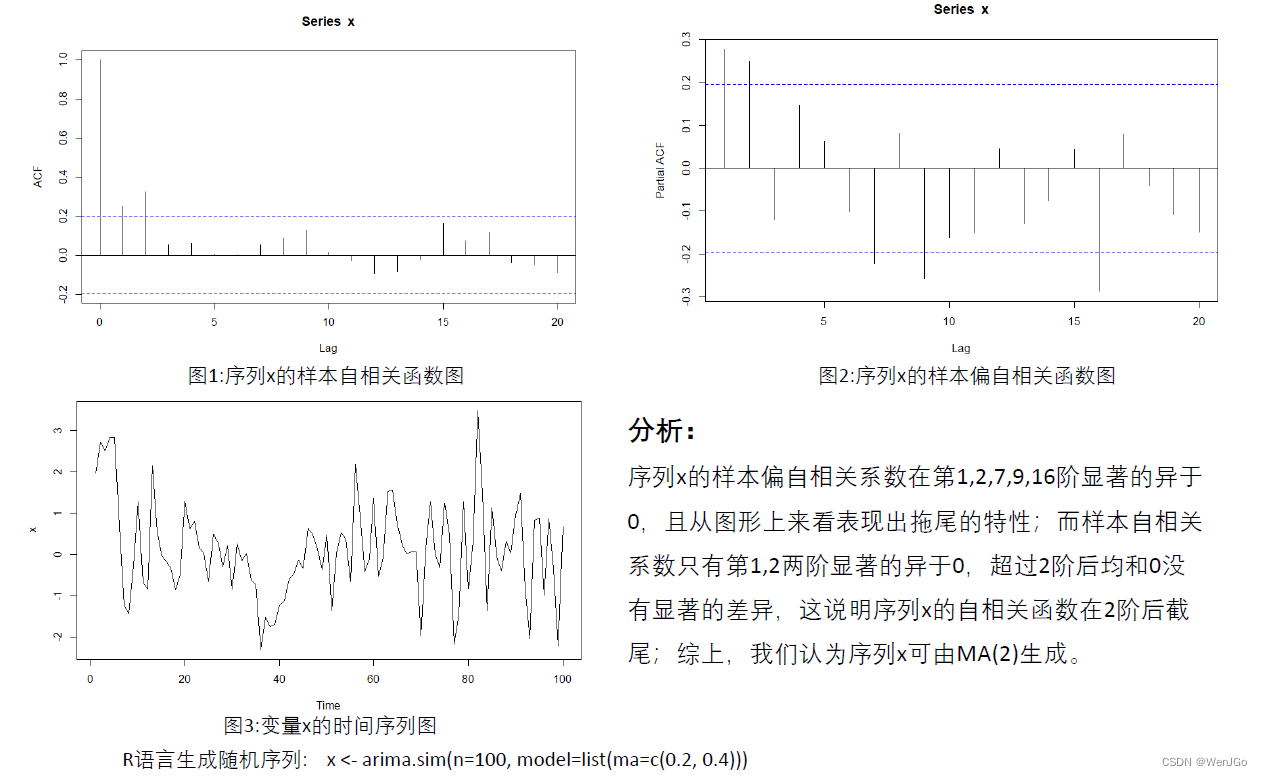


正确识别ARMA模型的阶数太难了
ARMA模型的估计

ARMA模型的极大似然估计:第四章 极大似然估计 - 百度文库 (baidu.com)
模型选择:AIC和BIC准则(选小原则)
过拟合问题:加入的参数个数越多,模型拟合的效果越好,但这却是以提高模型复杂度为代价的。因此,模型选择要在模型复杂度与模型对数据的解释能力之间寻求最佳平衡。

AIC和BIC是选小原则,我们要选择使得AIC或BIC最小的模型。
(BIC对于模型的复杂程度的惩罚系数更大,因此BIC往往比AIC选择的模型更简洁)
检验模型是否识别完全
估计完成时间序列模型后,我们需要对残差进行白噪声检验,如果残差是白噪声,则说明我们选取的模型能完全识别出时间序列数据的规律,即模型可接受;如果残差不是白噪声,则说明还有部分信息没有被模型所识别,我们需要修正模型来识别这一部分的信息。


ARIMA(p,d,q)模型

ARIMA(1,1,1)时间序列图

x <‐ arima.sim(list(order = c(1,1,1), ar = 0.6, ma=‐0.5), n = 100)
ARIMA(1,2,1)时间序列图
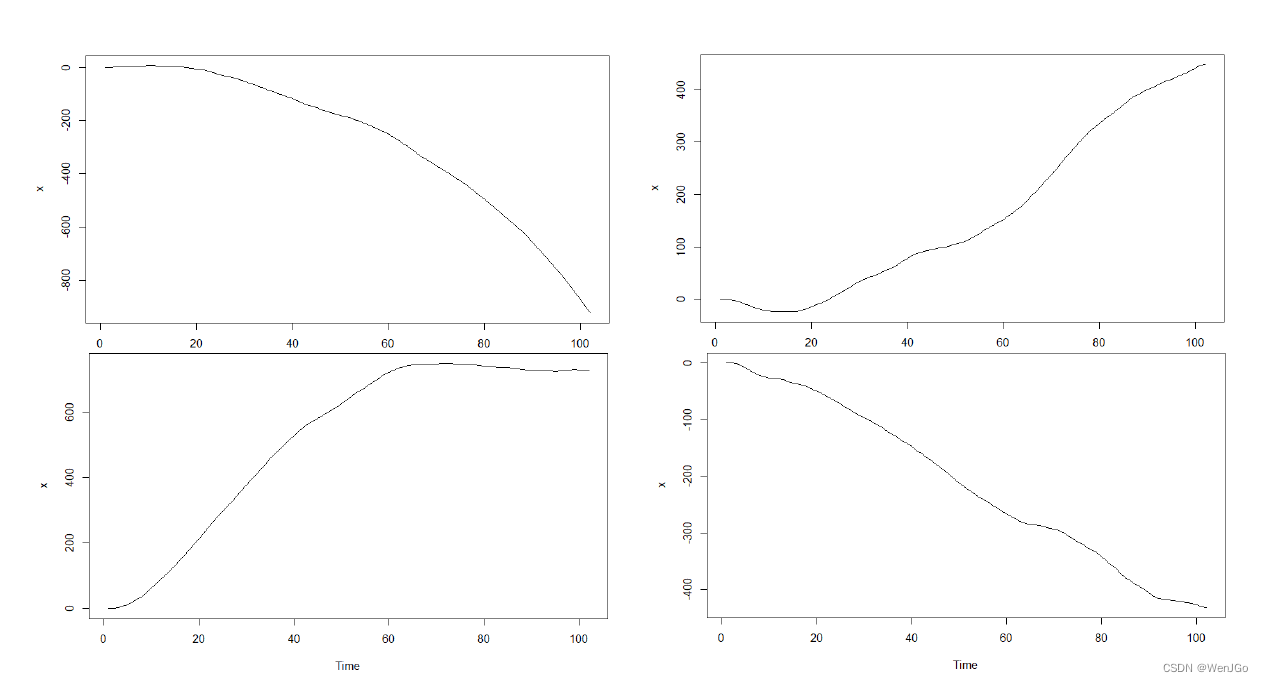
x <‐ arima.sim(list(order = c(1,2,1), ar = 0.6, ma=‐0.5), n = 100)
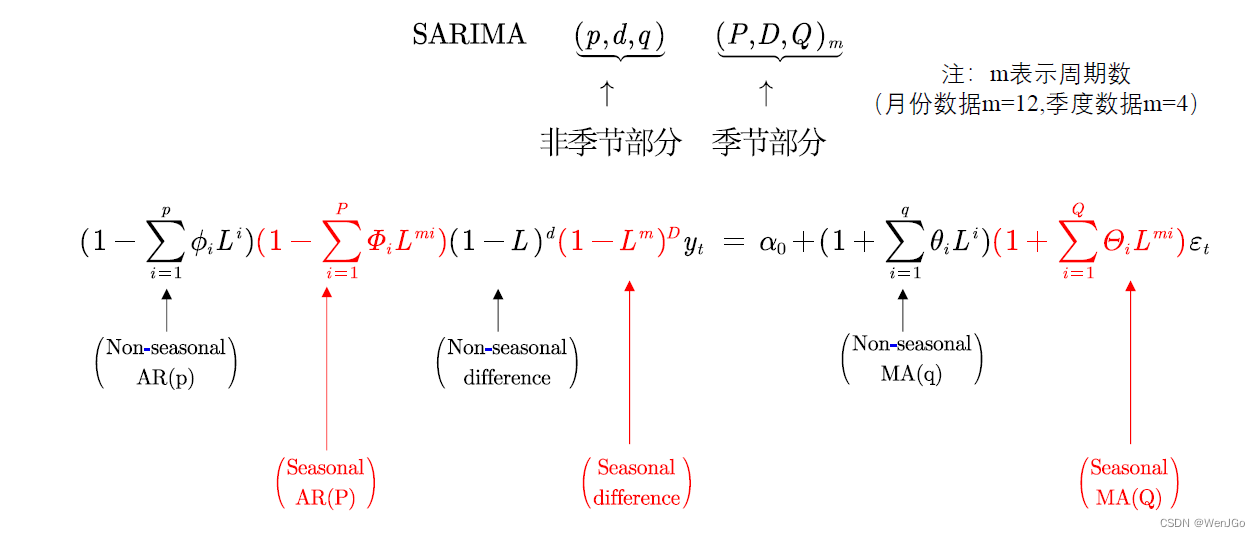
SARIMA(Seasonal ARIMA)模型
到目前为止,我们只关注非季节性数据和非季节性ARIMA模型。然而,ARIMA模型也能够对广泛的季节数据进行建模。
季节性ARIMA模型是通过在ARIMA模型中包含额外的季节性项而生成的,其形式如下:
Spss时间序列建模的思路
下面的步骤是自己在思考建模的过程,不是写在论文中的:
(1)处理数据的缺失值问题、生成时间变量并画出时间序列图;
(2)数据是否为季度数据或者月份数据(至少有两个完整的周期,即两年),如果是的话则要观察图形中是否存在季节性波动。
(3)根据时间序列图大致判断数据是否为平稳序列(数据围绕着均值上下波动,无趋势和季节性)
(4)打开Spss,分析‐‐时间序列预测—创建传统模型(高版本的Spss可能才有这个功能),看看Spss专家建模器得出的最优的模型类型。
(5)如果最后的结果是ARIMA(p,0,q)模型,那么我们就可以画出时间序列的样本ACF和PACF图形进行分析;如果得到的是ARIMA(p,1,q)模型,我们可以先对数据进行1阶差分后再用ACF和PACF图形分析;如果得到的结果与季节性相关,那么我们可以考虑使用时间序列分解。
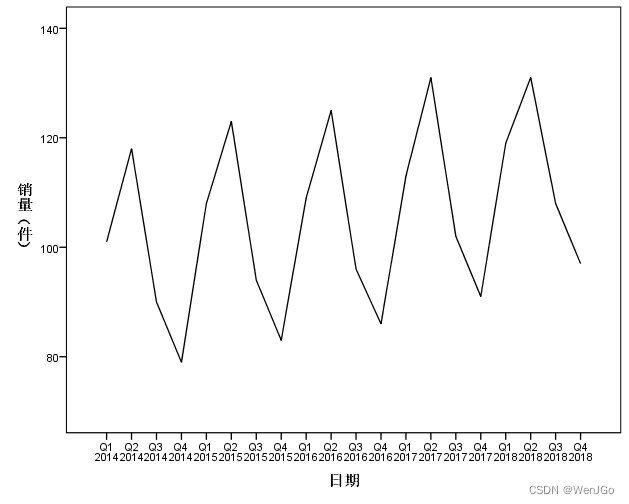
例题1:销量数据预测

前期准备工作
下面的步骤是自己在思考建模的过程,不是写在论文中的:
(1)数据为季度数据(有四个周期),从图中看出也有季节性波动,即第二季度的销量较高,第四季度较低;
(2)根据时间序列图可知数据不平稳,有向上的趋势;
(3)Spss的专家建模给出的最合适的模型是温特加法模型;
(4)温特加法模型意味着原时间序列数据含有线性趋势和稳定的季节成分,我们可以使用加法时间序列分解;
(5)利用Spss我们可以对未来两年的销售数据进行预测。

Spss时间序列建模器

默认在所有的指数平滑模型和ARIMA模型中选择合适的模型。
自动检测异常值的方法

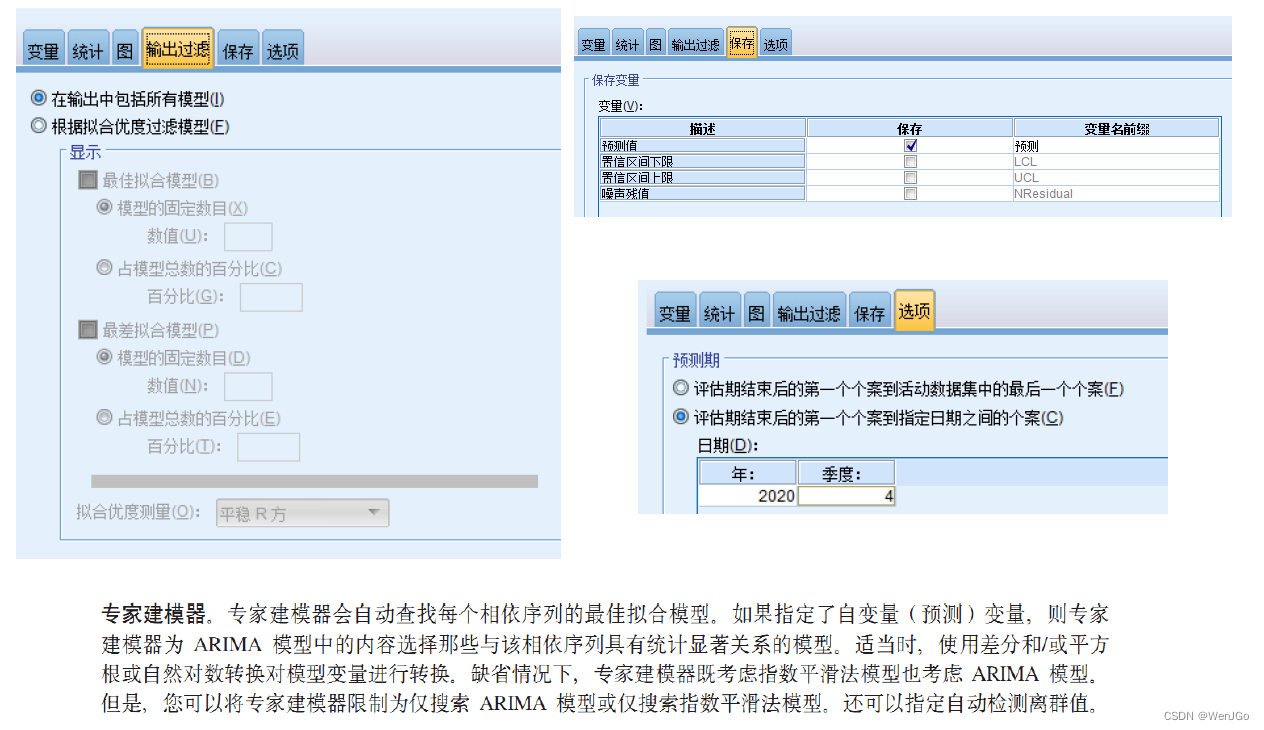
操作步骤

注:
(1)预测值和拟合值是不相同的,预测值是将样本外年份的数据带入模型计算得到的,而拟合值是将样本的年份重新带入模型计算得到的。
(2)这里保留残差的ACF和PACF图形可以帮助我们判断残差是否为白噪声,即该时间序列是否能被模型识别完全。
常用的评价指标

参数估计值表格

白噪声进行残差检验

预测的结果和效果图

例题2:人口数据预测
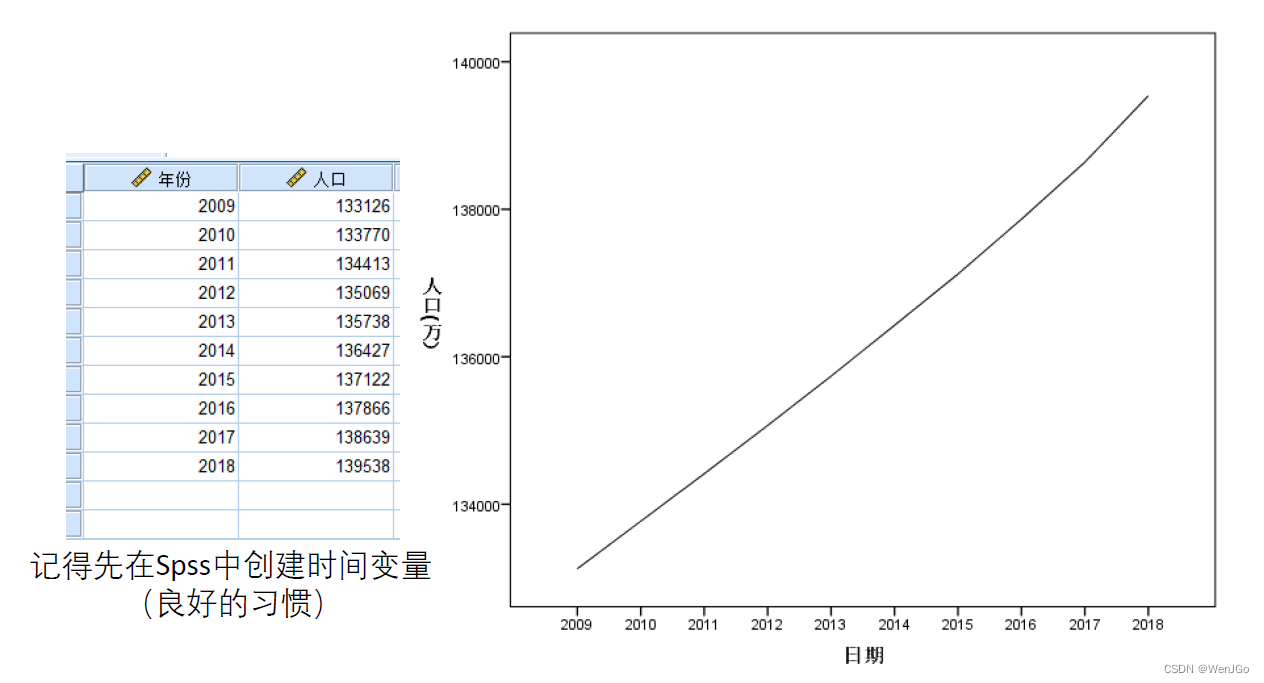
预测结果

残差的白噪声检验
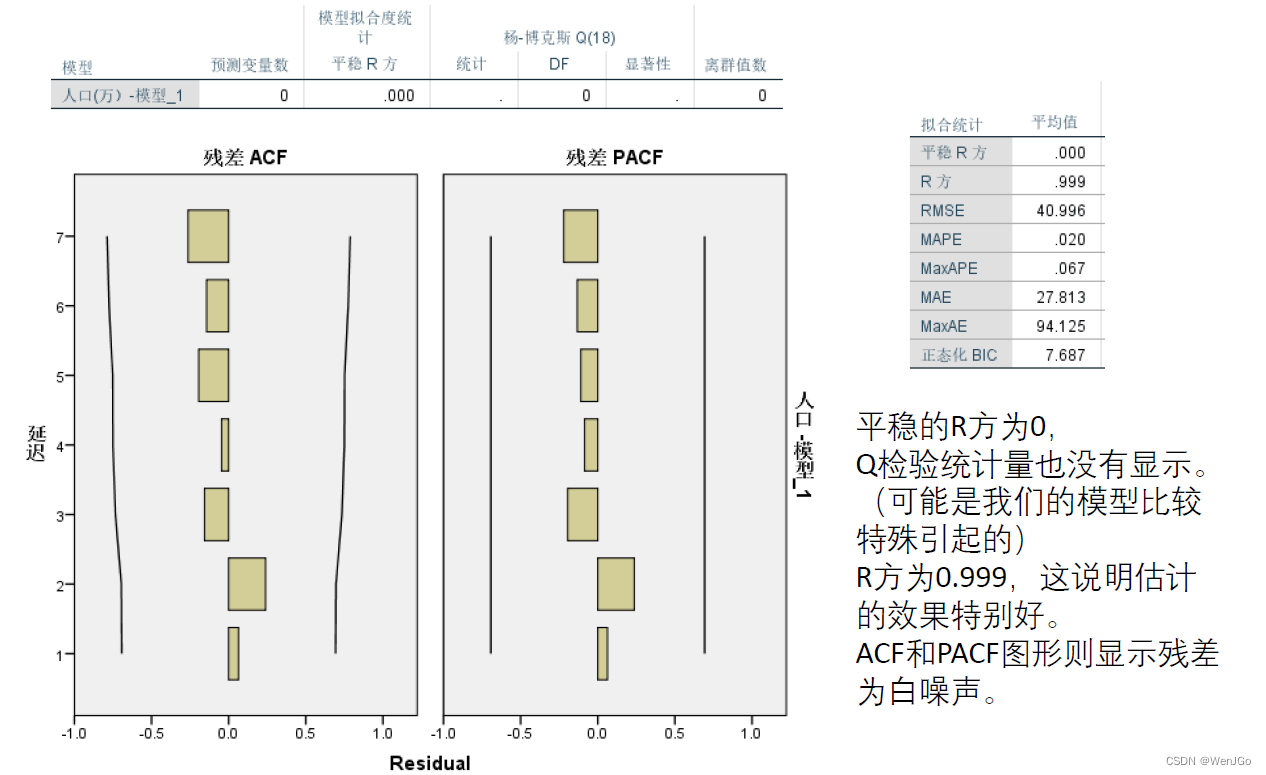
预测效果图形

例题3:上证指数预测
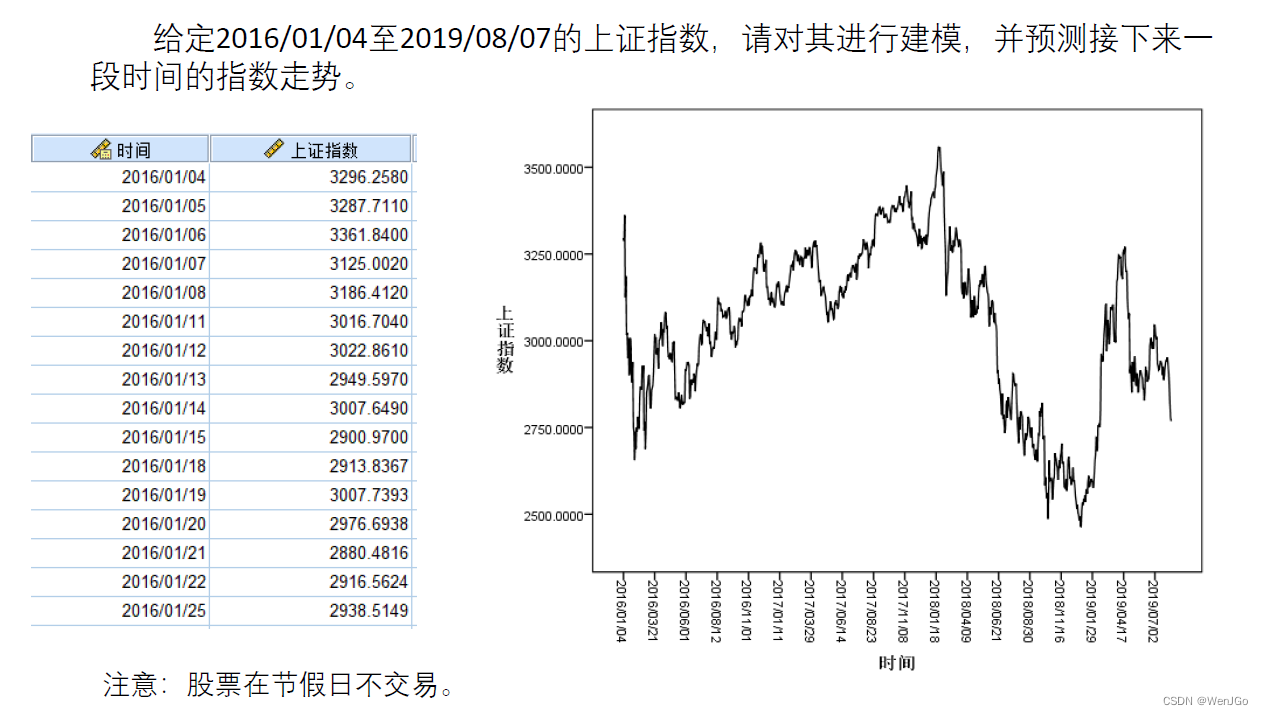
直接进行专家建模的结果


剔除异常值后重新建模

预测效果

例题4:GDP增速预测
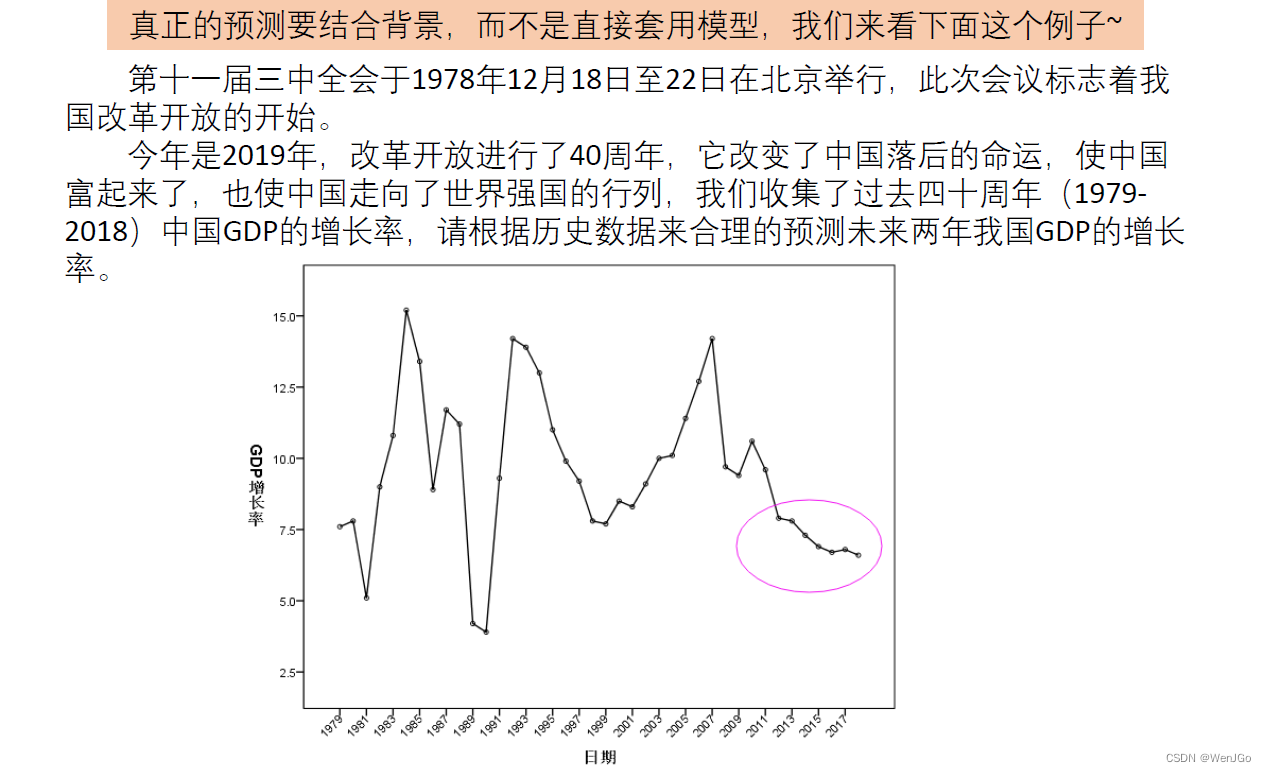
用所有数据进行预测(剔除异常值)
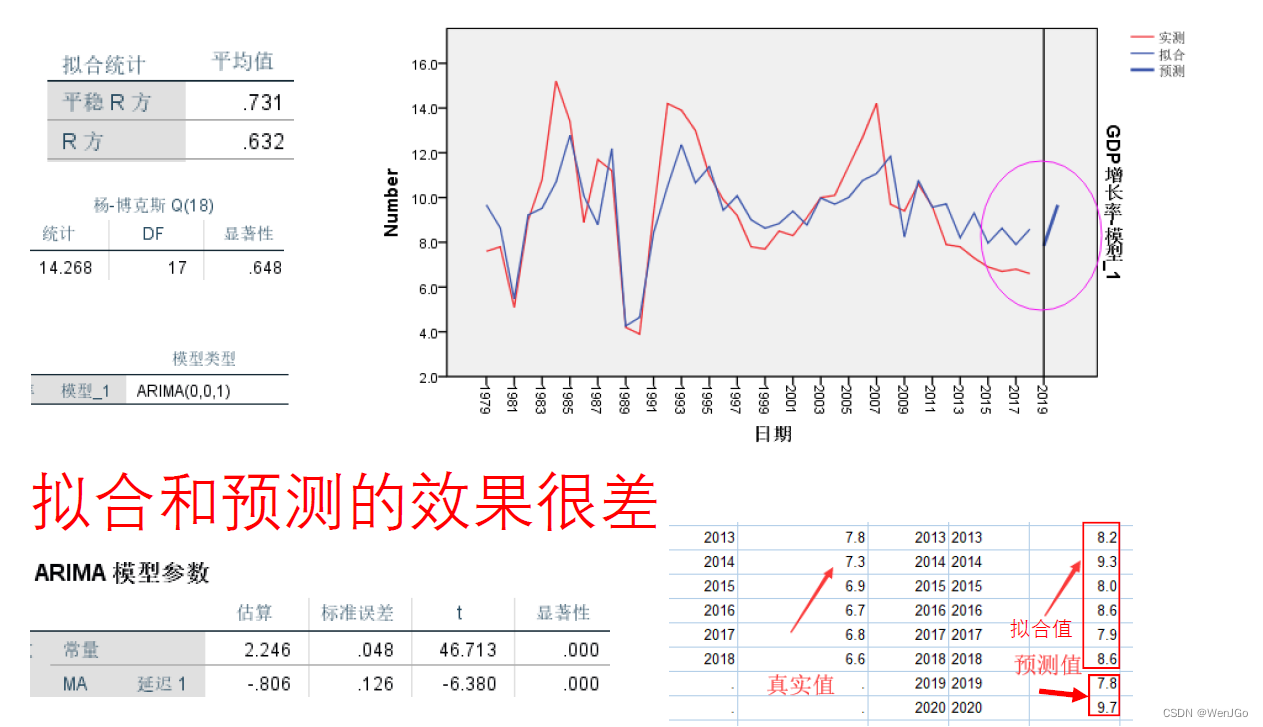
出错的原因

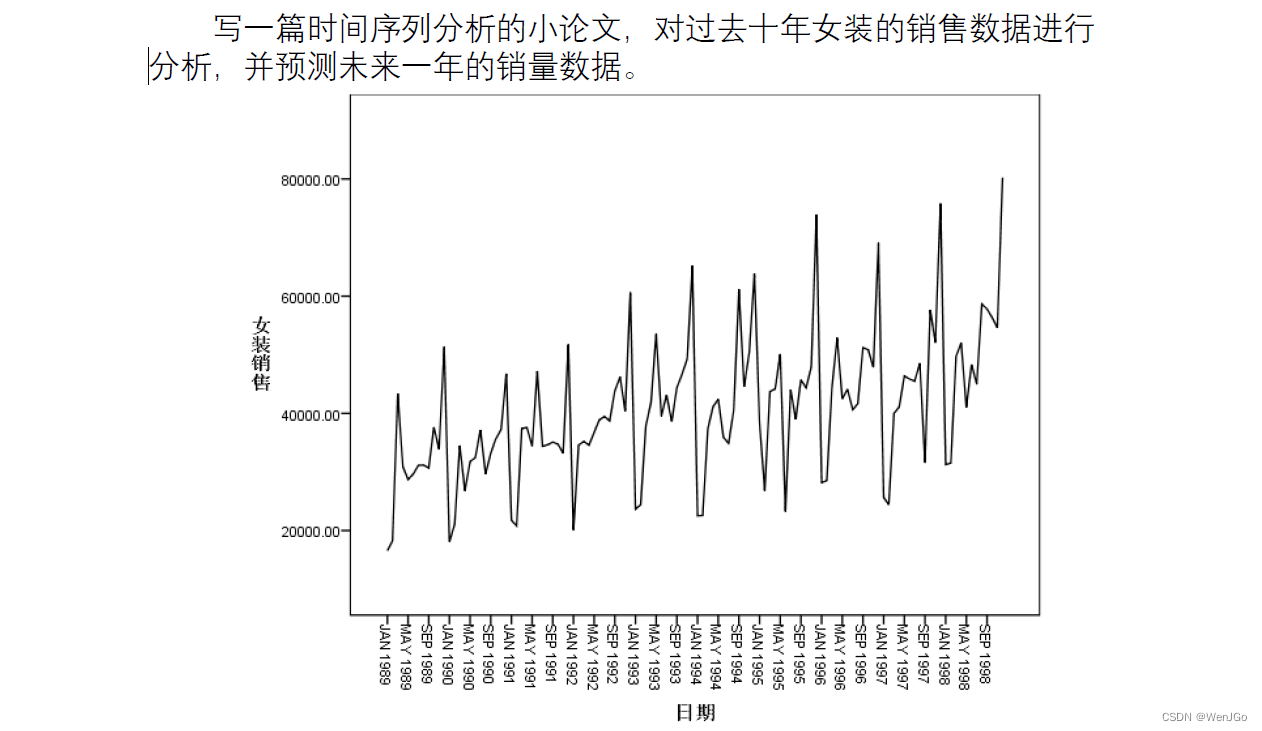
课后作业
结语
没有结语,挺多的今天,好好看好好学ヾ( ̄▽ ̄)Bye~Bye~







![[足式机器人]Part2 Dr. CAN学习笔记-Advanced控制理论 Ch04-8 状态观测器设计 Linear Observer Design](https://img-blog.csdnimg.cn/direct/3ae9839c835048658a5f7b85342012d0.png#pic_center)