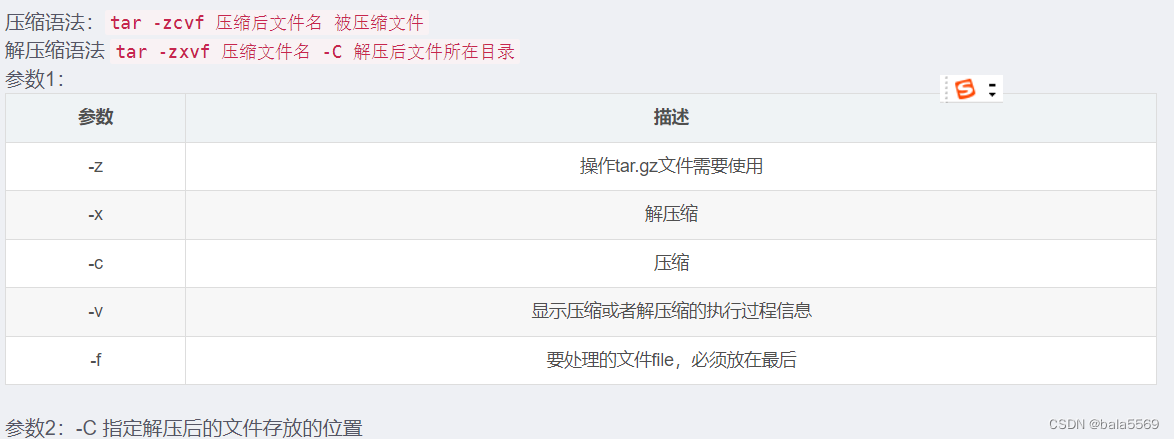
目录
简单使用
参数
异常处理
OCR,光学文字识别,对文本资料进行扫描,然后对图像文件进行分析处理,获取文字及版面信息的过程。easyocr是一个比较流行的库,支持超过80种语言。安装的时候注意会附带安装torch库(一个深度学习框架,大小600多M)
安装: pip install easyocr -i https://pypi.mirrors.ustc.edu.cn/simple/
执行easyocr.Reader()时需要将模型加载到内存中,需要一定时间,只需要运行一次(会先下载列表中相关的语言包)。
简单使用
识别图片:
import easyocrreader = easyocr.Reader(['ch_sim', 'en']) result = reader.readtext(r'D:\zhuomian\test_file\33.png') print(result)打印结果:[([[4, 4], [92, 4], [92, 28], [4, 28]], '弧独的我', 0.30187690258026123), ([[2, 32], [92, 32], [92, 58], [2, 58]], '信号好强', 0.291224867105484)]
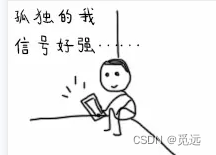
识别返回结果是一个列表,列表中包含多个元素,每个元素都是一个包含文本、位置坐标和置信度的元组。
设置简单输出,只返回识别到的文本:添加参数 detail=0
result = reader.readtext(r'D:\zhuomian\test_file\33.png',detail=0) print(result)输出结果:['弧独的我', '信号好强']
参数
easyocr.Reader()
gpu:如果设备上没有GPU,或者GPU内存较小,可以通过添加gpu=False以仅在CPU模式下运行模型。
lang_list:语言模型包,首次使用会先下载列表中相关的语言包(ch_tra--繁体中文,ch_sim--中文简体,两种汉语包不可同时使用)。
reader.readtext()
image:除了本地图片文件路径,还可以传递一个OpenCV图像对象(numpy数组)、图像文件的字节、网络图片的URL。


异常处理
1、下载语言包报错:raise ContentTooShortError(urllib.error.ContentTooShortError: <urlopen error retrieval incomplete: got only 2209389 out of 209821039 bytes>,
网络不稳定,需要重新下载
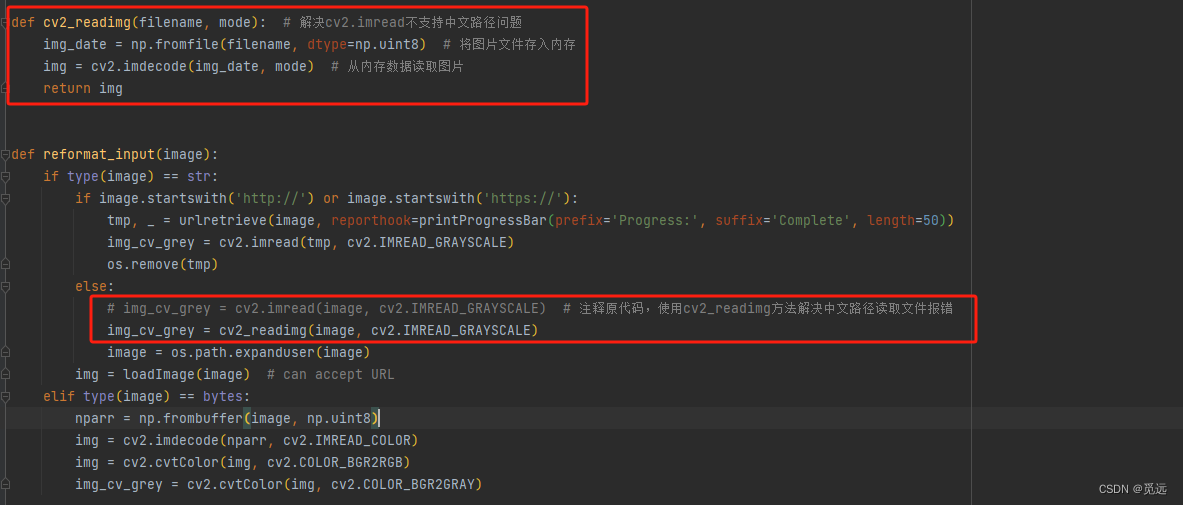
2、easyocr源码中cv2.imread方法不支持中文路径报错:AttributeError: 'NoneType' object has no attribute 'shape'
修改报错文件,在报错文件中添加一个自定义的方法,将原来的方法替换
def cv2_readimg(filename, mode): # 解决cv2.imread不支持中文路径问题img_date = np.fromfile(filename, dtype=np.uint8) # 将图片文件存入内存img = cv2.imdecode(img_date, mode) # 从内存数据读取图片return imgimg_cv_grey = cv2_readimg(image, cv2.IMREAD_GRAYSCALE)