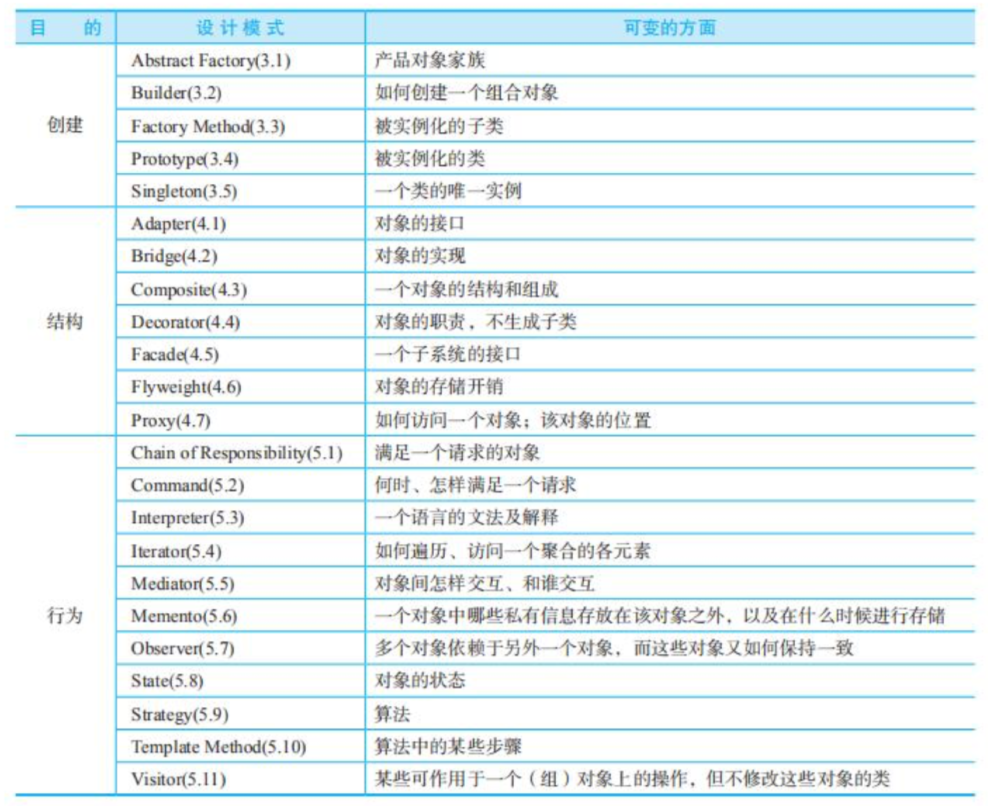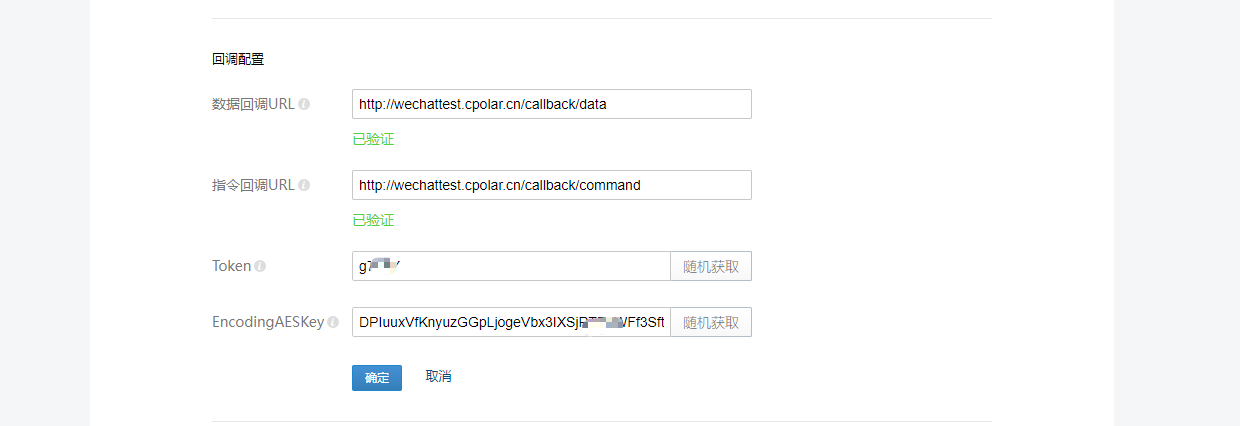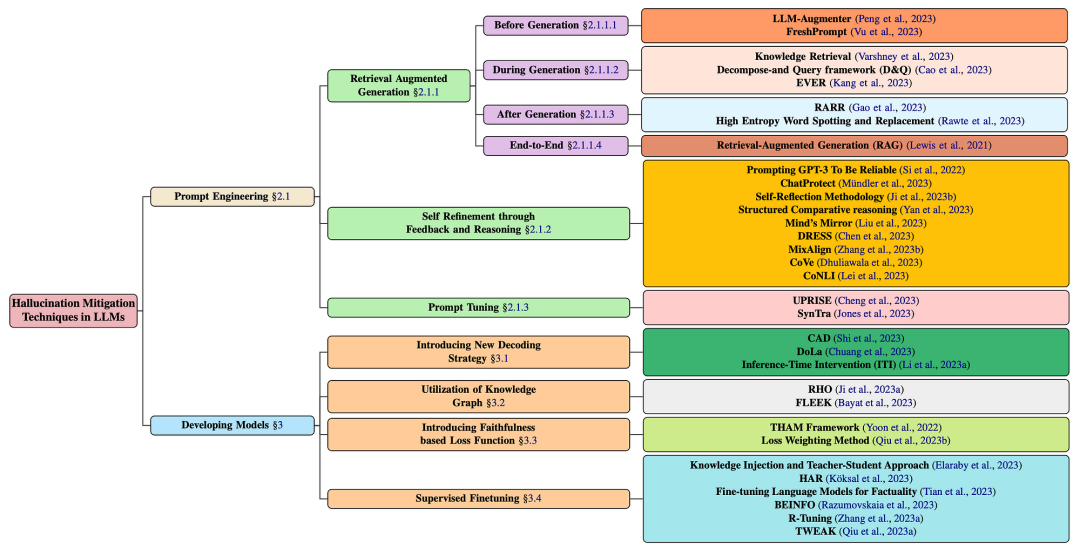
LLM幻觉缓减技术分为两大主流,梯度方法和非梯度方法。梯度方法是指对基本LLM进行微调;而非梯度方法主要是在推理时使用Prompt工程技术。LLM幻觉缓减技术,如下图所示:
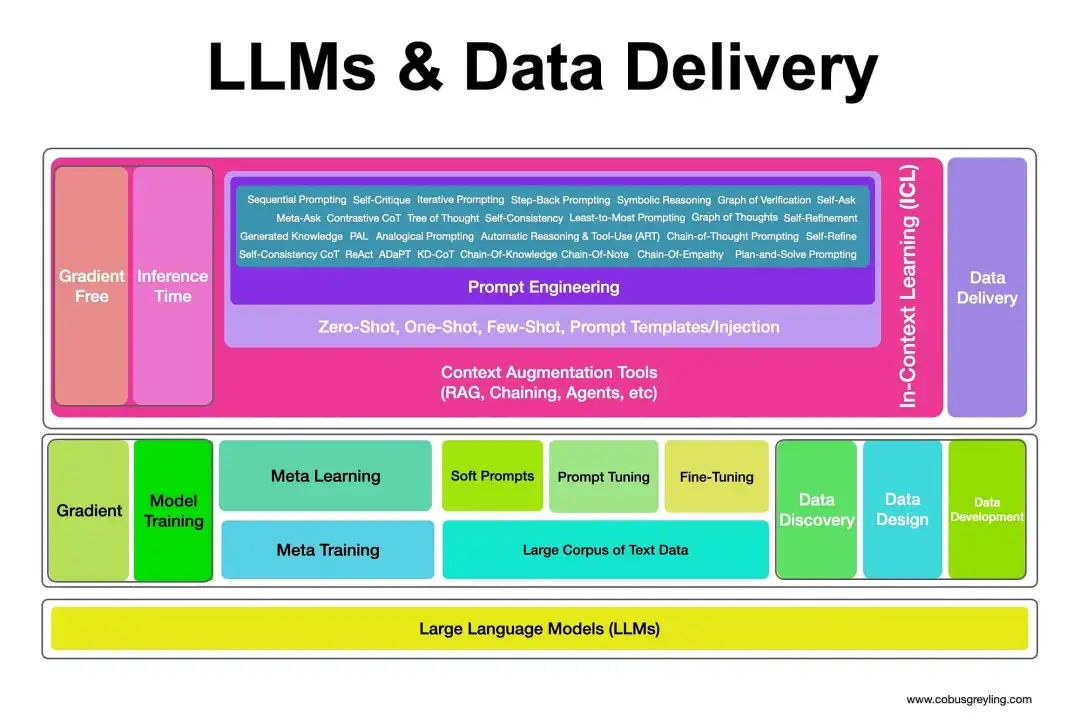
LLM幻觉缓减技术值得注意的是:
- 检索增强生成(RAG)
- 知识检索(https://arxiv.org/abs/2307.03987)
- CoNLI(https://arxiv.org/abs/2310.03951)
- CoVe(https://cobusgreyling.medium.com/chain-of-verification-reduces-hallucination-in-llms-20af5ea67672)
与专注于有限任务的传统人工智能系统不同,LLM在训练过程中使用了大量的在线文本数据。当大模型语言生成功能应用在要求严格的应用程序时,LLM幻觉就变得非常令人担忧,例如:
-
总结医疗记录;
-
客户支持对话;
-
财务分析报告,并提供错误的法律建议。
一、幻觉缓解分类法
这项研究对LLM幻觉缓解技术进行了总结,分类为:梯度方法和非梯度方法。
梯度方法包括复杂和不透明的解码策略、知识图谱、微调策略等。
非梯度方法包括RAG、自我优化和Prompt微调。
值得注意的是,RAG方法分为四个部分;
- 生成之前;
- 生成期间;
- 生成后;
- 端到端
Prompt工程缓解幻觉的原理在于定义:
- 特殊上下文&;
- 预期输出
二、最佳预防幻觉
预防幻觉的最佳方法不是单一的方法,需要综合多种方法。
缓减幻觉需要考虑以下因素:
-
在多大程度上依赖标签数据?
-
引入无监督或弱监督学习技术以提高可扩展性和灵活性的可能性是什么?
-
考虑梯度和非梯度方法,以产生连贯和上下文相关的信息。
-
收集到的缓解幻觉的工作揭示了一系列不同的策略,每种策略都有助于解决LLM中幻觉的细微差别。
-
通过反馈和推理的自我完善会产生有影响力的策略。
-
结构化比较推理引入了一种结构化的文本偏好预测方法,增强了连贯性,减少了幻觉。
-
监督微调可以通过知识注入和师生方法进行探索。
-
特定领域的知识被注入到较弱的LLM和使用反事实数据集来提高真实性的方法中。
参考文献:
[1] https://cobusgreyling.medium.com/large-language-model-hallucination-mitigation-techniques-a75b6f873318