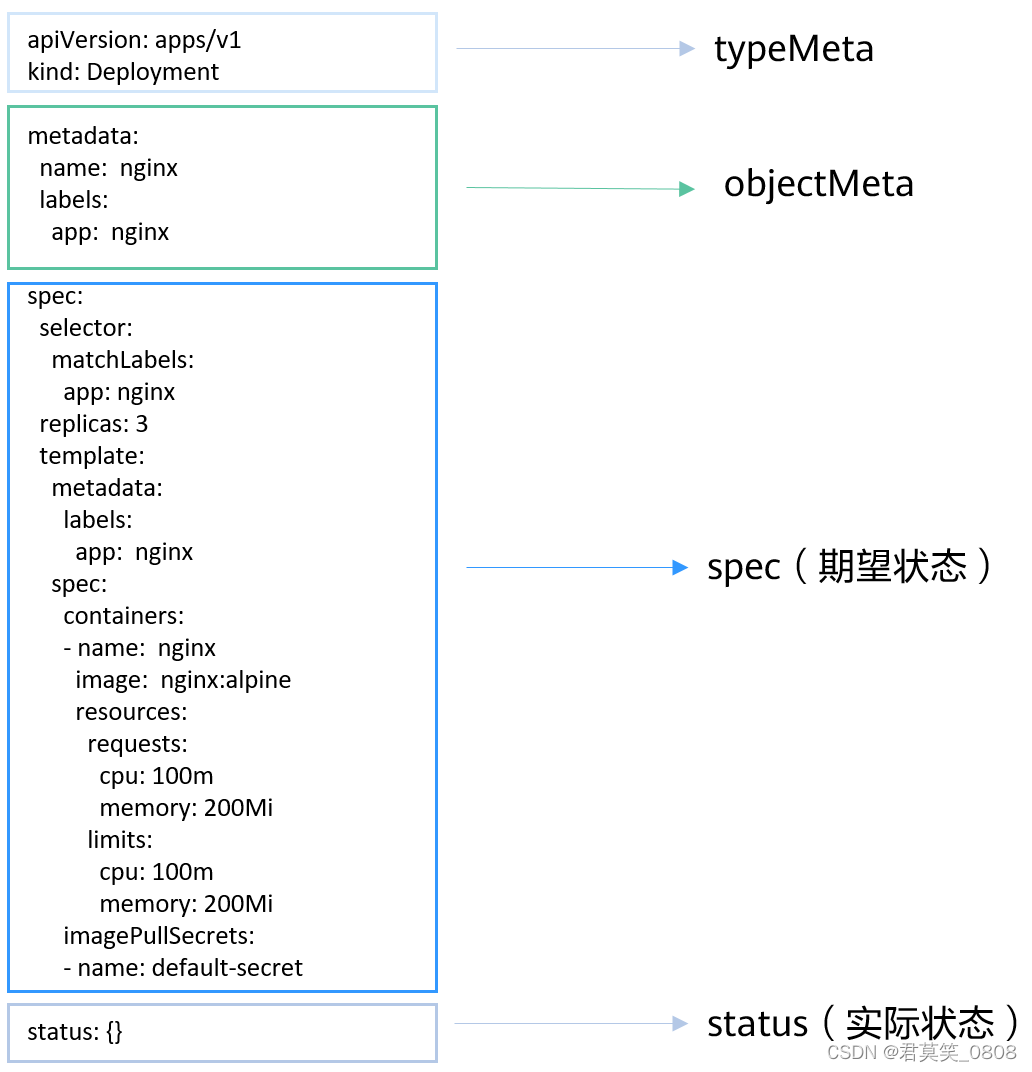
目录
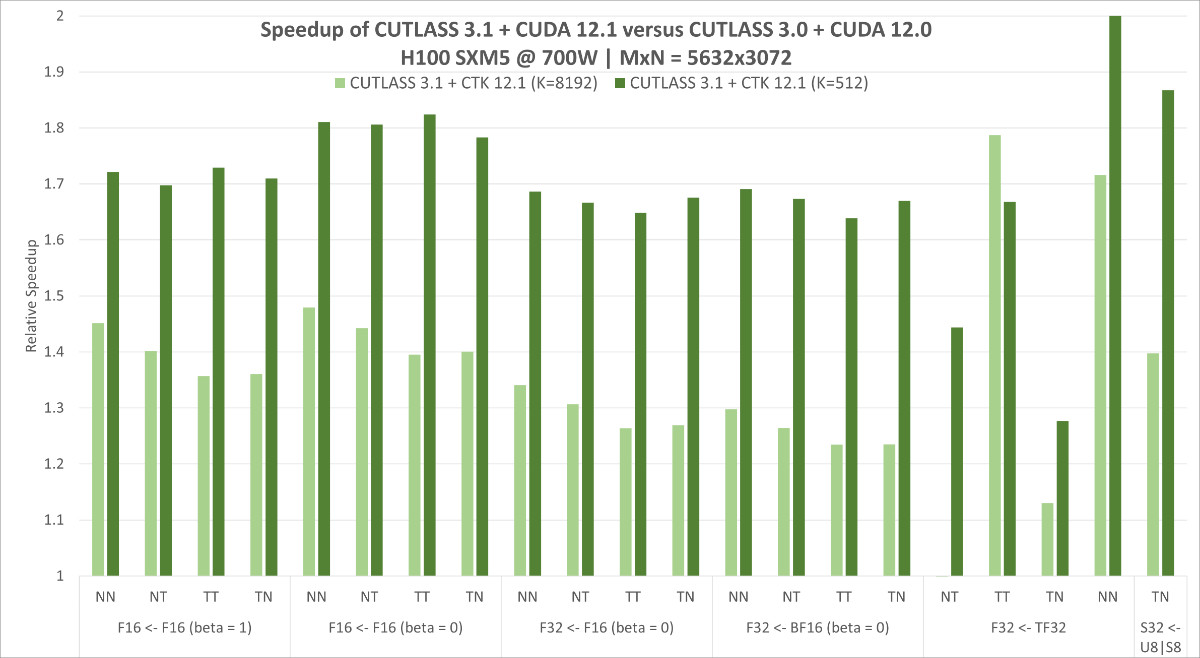
- 一、CNN存在的问题:
- 二.Transformer整理架构分析:
- 1.Linear Projection of Flattened Patches层形成Patch:
- 2.对每个Patch进行位置编码Position Embedding:
- 3.Transformer Encoder:
- 三.公式解读:
一、CNN存在的问题:
- 过拟合问题。
- 需要堆叠大量卷积层才能识别图片的整体特征,每层卷积层需要重复的实验和证明。而Transformer的Encoder只需要堆叠少量层就能识别图片的整体。
二.Transformer整理架构分析:
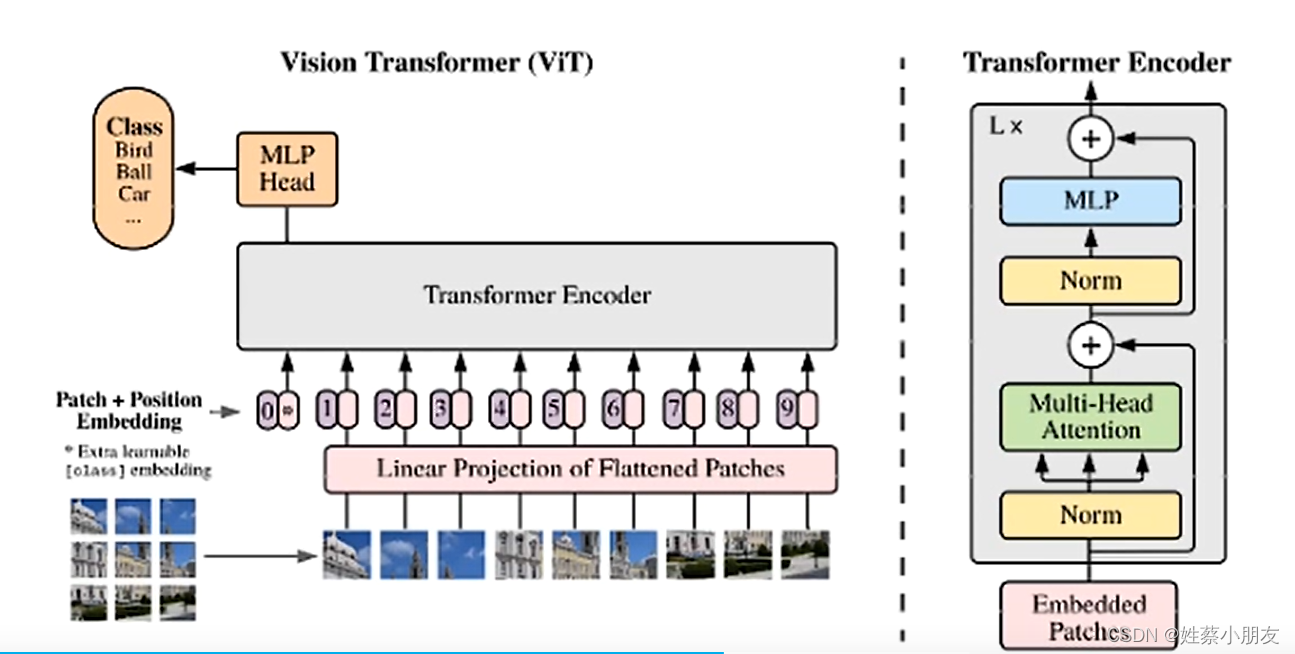
- 首先将图片分隔成小的图片,对每个小图片的矩阵(10103)进行拉长形成一个向量(300*1),作为输入序列。
- Linear Projection of Flattened Patches层对输入的向量(300*1)做一个特征整合形成多个新维度的向量Patch。
1.Linear Projection of Flattened Patches层形成Patch:
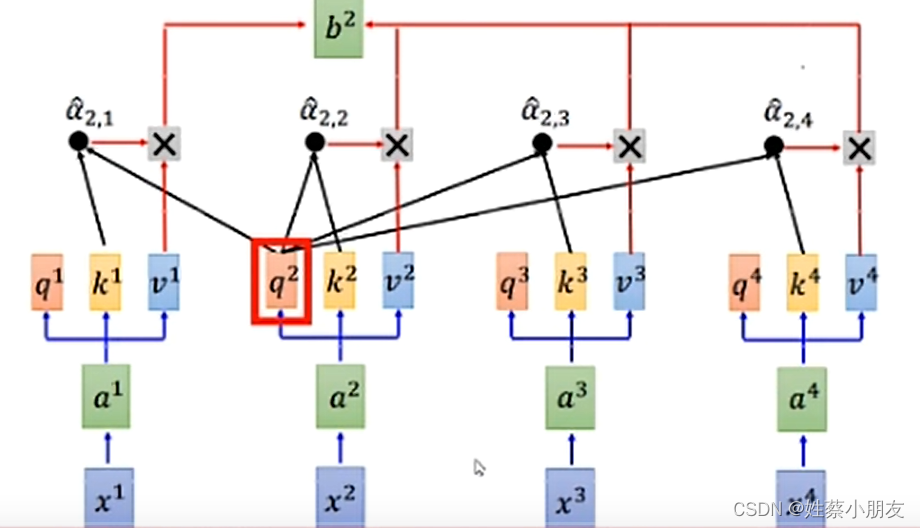
- 因为x1,x2,x3,x4之间是有联系的,首先对输入向量x1,x2,x3,x4进行特征提取,即把输入序列中的每个单元组合成比较好的新的特征。
- x1与x2,x3,x4之间的关系式由q1,k1,v1给出。
- q1为x1的查询向量,通过查询向量可以获得x1与x2,x3,x4之间的关系。
- k1为其他的xi调用qi查询x1时为qi提供的自身信息。
- v1为x1特征的代表,后续使用的是v1而不再使用x1。
- Transformer执行过程:首先各向量通过qi查询其余向量的k,获取自己与其余向量的关系,通过关系实际上得到了一组权重项,根据权重项把输入特征进行重新组合,形成比较好的新的特征。
2.对每个Patch进行位置编码Position Embedding:
- 有2种编码方式:
- 对小图片进行从上至下,从左至右进行1,2,3,4,5,6,7,8,9编码
- 对小图片进行(1,1),(1,2),(1,3),(2,1),(2,2),(2,3),(3,1),(3,2),(3,3)编码
3.Transformer Encoder:
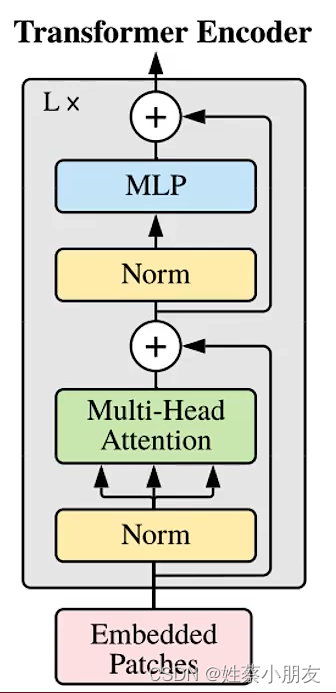
- Lx表示Transformer做了多次
- Embedded Patches输入序列
- Norm规划层
- ⊕为残差连接
- Multi-Head Attention多头注意力机制
- MLP全连接
三.公式解读:

- E为向量编码
- PP表示向量的个数,C为每个向量的维度(C,1)。特征图大小为PP*C
- D为全连接映射,xD即把(C,1)维向量映射为(D,1)维向量的规模
- Epos为位置编码,即对每个向量在位置上进行编码
- N+1中的1即为整体架构图中的0号patch,它的作用是方便对各个输入向量进行整合。
- z0作用是将各个向量与自身的位置进行组合(相加实现)
- xpE表示对E中每个向量,xclass为0号patch
- MSA为多头注意力机制
- LN表示对输入数据进行规划
- +为残差连接
- MLP为全连接
- LN为对上述操作执行n次