授人以鱼不如授人以渔
解决步骤
记录下解决步骤…cuda报错真要人命
首先根据终端的提示

他说让你加这个来定位具体的python代码错哪了,所以咱们就加。
我这里启动命令是:
accelerate launch --config_file "utils/acc_configs/accelerate_config_${ARNOLD_ID}.yaml" llava/train/train_mem.py
加上就是:
CCL_P2P_DISABLE=1 TORCH_USE_CUDA_DSA=1 CUDA_LAUNCH_BLOCKING=1 accelerate launch --config_file "utils/acc_configs/accelerate_config_${ARNOLD_ID}.yaml" llava/train/train_mem.py
你如果是:
python3 xxx.py
就改成
CCL_P2P_DISABLE=1 TORCH_USE_CUDA_DSA=1 CUDA_LAUNCH_BLOCKING=1 python3 xxx.py
加上了之后,终端打印的东西巨巨巨长,不好定位报错代码,所以再加定向输出到文件内!
本来的运行命令:
bash scripts/v1_5/finetune.sh
改成:
bash scripts/v1_5/finetune.sh > test.log 2>&1
然后把test.log用记事本打开:
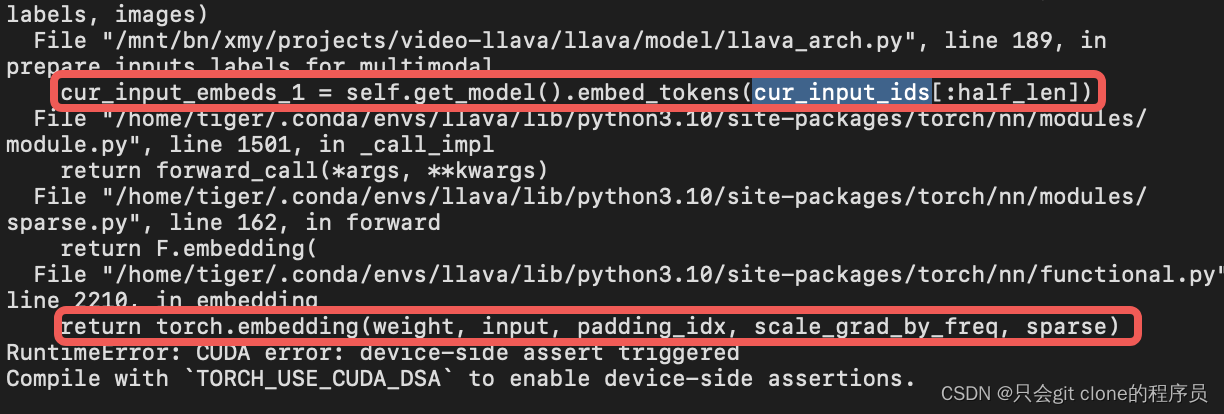
经过一行行的过目,发现在我的代码里是用这个embed_token报错了!所以非常好办!
先查这个embedding层的长度:
直接print模型就可以看了:(print(model))
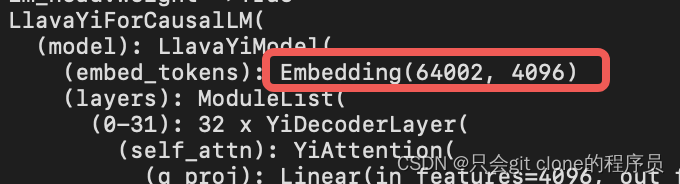
发现我的是最大支持输入为64001(注意下标从0开始),所以要判断我们输入的tensor的范围是不是在0-64001!

直接在报错的代码上一行加上一行写死的代码,判断输入的范围是否有异常!!!验证猜想。

果然被我抓到了,传了个-201进去,人家cuda怎么能不报错呢???还不是你自己写的bug…
具体fix这里不再展开了,我这写了点小bug导致的,还有什么原因呢,比如你加了speical token之后没调用model.resize_token_embeddings(len(tokenizer))重置embedding层的长度也会。
解决办法
- 如果是加了speical token,之后没调用model.resize_token_embeddings(len(tokenizer))重置embedding层的长度就会数组越界。