文章目录
- 一、前言
- 二、Visitor 模式
- 1. 介绍
- 2. 应用
- 3. 总结
- 三、Chain of Responsibility 模式
- 1. 介绍
- 2. 应用
- 3. 总结
- 参考内容
一、前言
有时候不想动脑子,就懒得看源码又不像浪费时间所以会看看书,但是又记不住,所以决定开始写"抄书"系列。本系列大部分内容都是来源于《 图解设计模式》(【日】结城浩 著)。该系列文章可随意转载。
二、Visitor 模式
Visitor 模式:访问数据结构并处理数据
1. 介绍
在 Visitor 模式中,数据结构和数据被分离开来。我们需要编写一个“访问者”的类来访问数据结构中的元素,并把对各元素的处理交给访问者类。这样当需要增加新的处理时,我们只需要编写新的访问者,然后让数据结构可以接受访问者的访问即可。
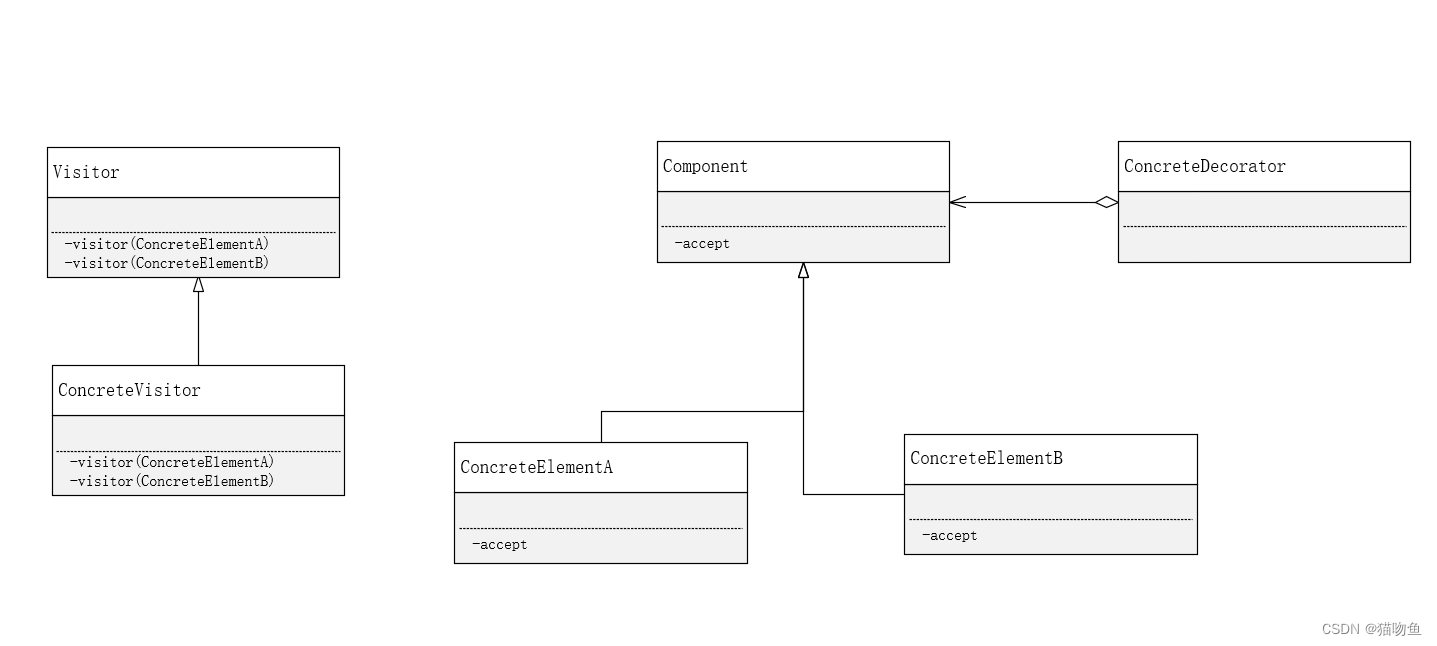
Visitor 模式 中出场的角色:
- Visitor(访问者):该角色负责对数据结构中每个具体的元素(ConcreteElement角色)声明一个用于访问XXX 的 visit(XXX) 方法。visit(XXX) 是用于处理 XXX 的方法,负责实现该方法的是 ConcreteVisitor 橘色。
- ConcreteVisitor(具体的访问者):ConcreteVisitor 角色负责实现 Visitor 角色所定义的接口。他要实现所有的 visit(XXX) 方法,即实现如何处理每个 ConcreteElement 角色。
- Element(元素):Element 角色表示Visitor 角色的访问对象。他声明了接受访问者的 accept 方法。accept 方法接收到的参数是 Visitor 角色。
- ConcreteElement :ConcreteElement 角色负责实现 Element 角色所定义的接口。
- ObjectStructure(对象结构):ObjectStructure 角色负责处理 Element 角色的集合。ConcreteVisitor 角色为每个 Element 角色都准备了处理方法。
类图如下:
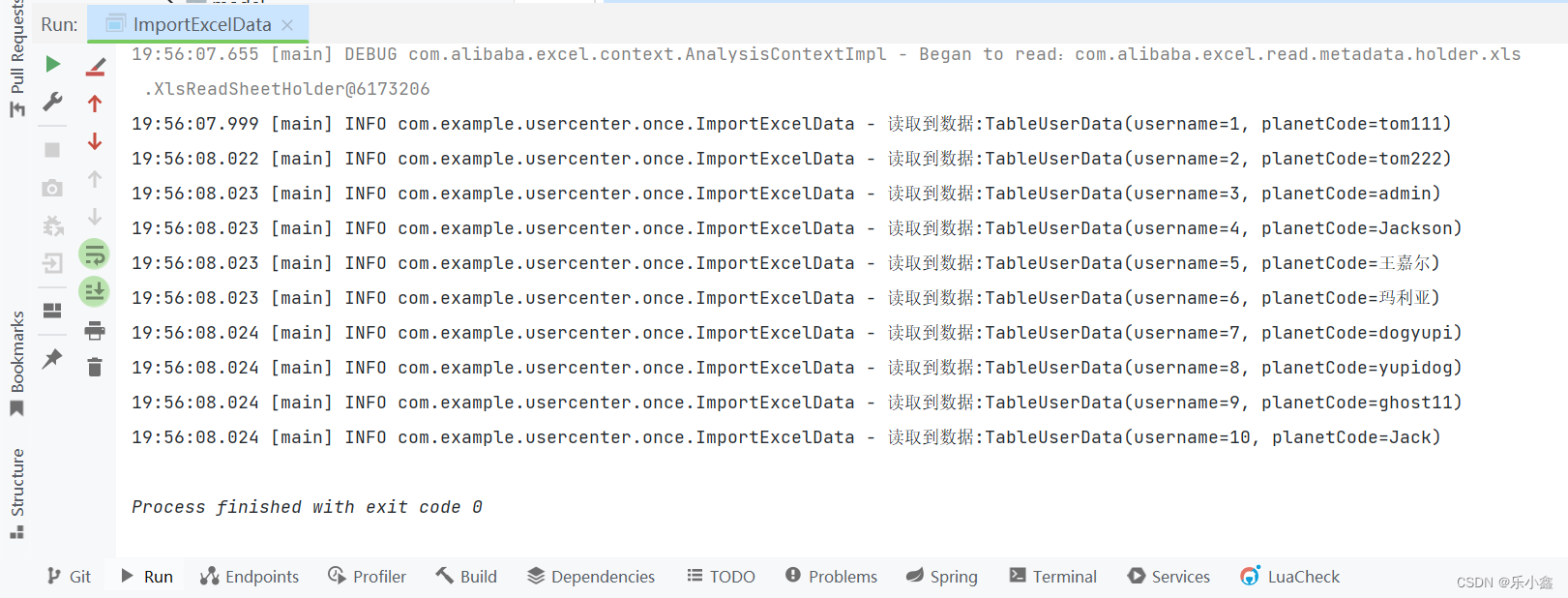
Demo如下:使用 ListVisitor 来访问 rootDir 目录下的资源
public interface Element {void accept(Visitor visitor);
}public interface Entry extends Element {/*** 获取文件名** @return*/String getName();/*** 获取文件大小** @return*/int getSize();/*** 添加目录** @param entry* @return*/default Entry addEntry(Entry entry) {throw new RuntimeException();}/*** 生成迭代器* @return*/default Iterator<Entry> iterator() {throw new RuntimeException();}/*** 输出路径* @return*/default String thisPath() {return getName() + "(" + getSize() + ")";}/*** 暴露出方法供访问者访问* @param visitor*/default void accept(Visitor visitor) {visitor.visit(this);}
}// 访问者接口
public interface Visitor {/*** 访问* @param entry*/void visit(Entry entry);
}// 文件
public class File implements Entry {private String name;private int size;public File(String name, int size) {this.name = name;this.size = size;}@Overridepublic String getName() {return name;}@Overridepublic int getSize() {return size;}
}// 文件夹
public class Directory implements Entry {private String name;private List<Entry> entries = Lists.newArrayList();public Directory(String name) {this.name = name;}@Overridepublic String getName() {return name;}@Overridepublic int getSize() {return entries.stream().mapToInt(Entry::getSize).sum();}@Overridepublic Entry addEntry(Entry entry) {entries.add(entry);return this;}@Overridepublic Iterator<Entry> iterator() {return entries.iterator();}}public class ListVisitor implements Visitor {/*** 当前目录*/private String currentDir = "";@Overridepublic void visit(Entry entry) {System.out.println(currentDir + "/" + entry.thisPath());if (entry instanceof Directory) {String saveDir = currentDir;currentDir = currentDir + "/" + entry.getName();entry.iterator().forEachRemaining(sonEntry ->sonEntry.accept(this));currentDir = saveDir;}}
}public class VisitorDemoMain {public static void main(String[] args) {Entry rootDir = new Directory("root");Entry binDir = new Directory("bin");Entry tmpDir = new Directory("tmp");Entry usrDir = new Directory("usr");Entry hanakoDir = new Directory("hanako");usrDir.addEntry(hanakoDir);rootDir.addEntry(binDir);rootDir.addEntry(tmpDir);rootDir.addEntry(usrDir);hanakoDir.addEntry(new File("memo.tex", 10));binDir.addEntry(new File("vi", 1000));binDir.addEntry(new File("latex", 2000));// ListVisitor 访问者访问rootDir 目录下的文件和文件夹rootDir.accept(new ListVisitor());}
}
输出如下:

2. 应用
印象中在哪看过,但是一时想不起来了。想起来再补
个人使用:该部分内容是写给自己看的,帮助自身理解,因此就不交代项目背景了,读者请自行忽略(◐ˍ◑):
-
项目 A 中,某一数据内容固定,但是存在多处地方会获取该部分数据,可以通过访问者模式来控制不同的访问者来获取不同部分的数据。
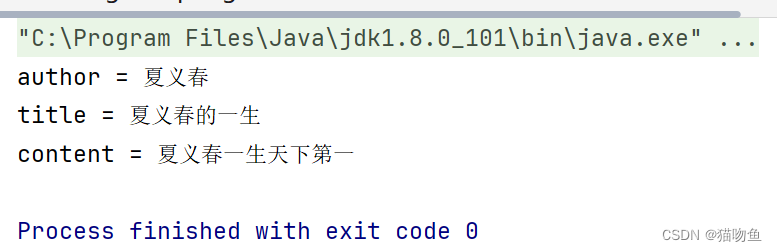
// 书的数据 @Data public class BookData {/*** 作者*/private String author;/*** 表体*/private String title;/*** 内容*/private String content;/*** 接受访问者访问** @param bookVisitor*/public void accept(BookVisitor bookVisitor) {if (bookVisitor instanceof TitleBookVisitor) {bookVisitor.visit(title);} else if (bookVisitor instanceof AuthorBookVisitor) {bookVisitor.visit(author);} else if (bookVisitor instanceof ContentBookVisitor) {bookVisitor.visit(content);} else {throw new RuntimeException("未知的访问者");}} }// 书籍访问者 public interface BookVisitor {/*** 访问数据* @param data*/void visit(String data); }// 作者访问 public class AuthorBookVisitor implements BookVisitor {@Overridepublic void visit(String data) {System.out.println("author = " + data);} } // 标题访问 public class TitleBookVisitor implements BookVisitor {@Overridepublic void visit(String data) {System.out.println("title = " + data);} } // 内容访问 public class ContentBookVisitor implements BookVisitor {@Overridepublic void visit(String data) {System.out.println("content = " + data);} }public class DemoMain {public static void main(String[] args) {final BookData bookData = new BookData();bookData.setAuthor("夏义春");bookData.setTitle("夏义春的一生");bookData.setContent("夏义春一生天下第一");bookData.accept(new AuthorBookVisitor());bookData.accept(new TitleBookVisitor());bookData.accept(new ContentBookVisitor());} }输入内容
3. 总结
数据结构是单一一个接口或实例,而数据是一个实例,当需要访问数据时,将 数据结构 API 传给数据就可以,这样的话对后面切换数据结构访问非常容易。当需要增加新的处理时,只需要编写新的访问者,然后让数据结构可以接受访问者访问即可。但是相对的,对于数据结构的设计需要具有一定前瞻性。
通常在以下情况可以考虑使用访问者(Visitor)模式:
- 对象结构相对稳定,但其操作算法经常变化的程序。
- 对象结构中的对象需要提供多种不同且不相关的操作,而且要避免让这些操作的变化影响对象的结构。
- 对象结构包含很多类型的对象,希望对这些对象实施一些依赖于其具体类型的操作。
扩展思路:
-
双重分发:
我们来整理下 Visitor 模式中方法的调用关系
accept(接受)方法的调用方式如下:element.accept(visitor);visit(访问)方法的调用方式如下:
visitor.visit(elemnt)对比一下就会发现,上面两个方法是相反的关系。element 接受 visitor, 而 visitor 又访问 element。在Visitor 模式中 ConcreteElement 和 ConcreteVisitor 这两个角色共同决定了实际进行的处理。这种消息分发的方式一般被称为双重分发。
-
为什么如此复杂:
Visitor 把简单的问题复杂化了吗?如果需要循环处理,在数据结构的类中直接编写循环语句不就解决了吗?为什么要搞出 accept 方法 和 visit 方法之间那样复杂的调用关系呢?Visitor 模式的目的是将处理从数据结果中分离出来。数据结构很重要,它能将元素集合和关联在一起,但是需要注意的是,保存数据结构与以数据结构为基础进行处理是两个不同的东西。
在示例程序中我们创建了 ListVisitor 类作为显示文件夹内容的 ConcreteVisitor 角色。通常,ConcreteVisitor 角色的开发可以独立于 File 类 和 Directory 类,也就是说 Visitor 模式提高了File类和 Directory 类作为组件的独立性。如果将进行处理的方法定义在 File 类和 Directory 类作为组件的独立性。如果将进行处理的方法定义在 File类和 Directory 类中,当每次要扩展功能,增加新的处理时就不得不去修改 File 类和 Directory类。
-
易于增加 ConcreteVisitor 角色
使用 Visitor 模式可以很容易地修改 ConcreteVisitor 角色,因为具体的处理被交给 ConcreteVisitor角色负责,因此完全不用修改 ConcreteElement 角色。 -
难以增加 ConcreteElement 角色
虽然使用 Visitor 模式可以很容易地增加 ConcreteVisitor 角色,不过他却很难应对 ConcreteElement 角色的增加。 -
Visitor 工作所需的条件 : Element 角色必须向 Visitor 角色公开足够多的信息。不过也可以基于此限制访问者能获取到的数据
相关设计模式:
- Iterator 模式 :Iterator 模式 和 Visitor 模式都是在某种数据结构上进行处理。Iterator 模式用于逐个遍历保存在数据结构中的元素。Visitor 模式用于对保存在数据结构中的元素进行某种特定的处理。
- Composite 模式 :有时访问者所访问的数据结构会使用 Composite 模式
- Interpret 模式 : 在 Interpret 模式汇总,有时会使用 Visitor 模式。例如在生成了语法树后可能会使用 Visitor 模式访问语法树的各个节点进行处理。
一时的小想法,仅仅个人理解,无需在意 :
- 访问者模式的最主要的作用是将数据和处理二者分离开,对于同一数据可以存在多种处理结果。而如果是为了完成这个目标有很多种其他模式可以选择(如策略模式、处理器模式等),而其中的关系就是主动和被动的区别,策略模式时,数据是被动的,只能被对应策略获取;而访问者模式下,数据则是主动的,由数据来确定暴露什么内容给访问者。
- 访问者模式还可以通过Element 来控制 Visitor 的数据访问权限,通过暴露出的数据不同来控制 Visitor 获取的数据内容的范围。如上面的例子中 BookData 对于所有的访问者 BookVisitor,可以自由控制暴露的内容,甚至是抛出异常。
在权限控制的场景是否适用?如每个角色都是一个访问者,去访问目录内容,根据角色不同会给于不同的可访问的内容?
三、Chain of Responsibility 模式
Chain of Responsibility 模式 : 推卸责任
1. 介绍
当外部请求程序进行某个处理,但程序暂时无法直接决定由哪个对象负责处理时,就需要推卸责任,在这种情况下,我们可以考虑将多个对象组成一条职责链。然后按照他们在职责链上的顺序一个一个地找出到底应该谁负来负责处理。这种模式称之为 Chain of Responsibility 模式。
Chain of Responsibility模式 中出场的角色:
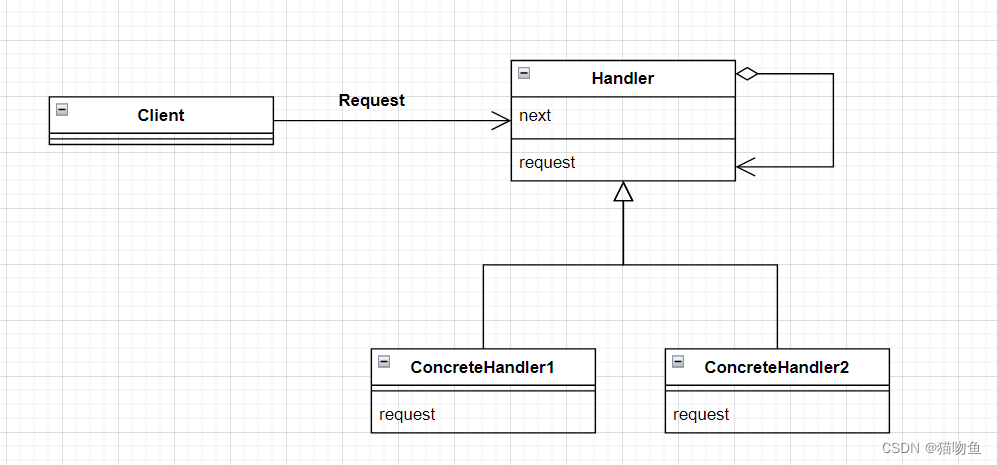
- handler (处理者) :Handler 角色定义了处理请求的接口(API),Handler 角色知道下一个处理者是谁,如果自己无法处理请求,会将请求转发给下一个处理者,下一个处理着也是 Handler角色。
- ConcreteHandler(具体的处理者):ConcreteHandler角色是处理请求的具体角色。
- Client(请求者):该角色是向第一个 ConcreteHandler角色发送请求的角色。
类图如下:
Demo 如下:可以看到不同的问题会交由不同的 Support 来解决,当一个 Support 不能解决时会交由 next 来处理
public abstract class Support {/*** 下一个解决器*/private Support next;/*** 设置下一个解决器* @param next* @return*/public Support setNext(Support next) {this.next = next;return this;}/*** 直接解决问题* @param trouble*/public final void support(String trouble) {if (resolve(trouble)) {done(trouble);} else if (next != null) {next.support(trouble);} else {fail(trouble);}}/*** 解决问题** @param trouble* @return*/protected abstract boolean resolve(String trouble);/*** 问题已解决** @param trouble*/protected void done(String trouble) {System.out.println(trouble + " 问题已被 " + this.getClass().getSimpleName() + " 解决");}/*** 问题未解决** @param trouble*/protected void fail(String trouble) {System.out.println(trouble + " 问题未解决");}
}// 解决特定编号的问题
public class SpecialSupport extends Support {@Overrideprotected boolean resolve(String trouble) {return "夏义春".equals(trouble);}
}// 解决小于指定长度的问题
public class LimitSupport extends Support {@Overrideprotected boolean resolve(String trouble) {return StringUtils.length(trouble) < 10;}
}// 不解决任何问题
public class NoSupport extends Support {@Overrideprotected boolean resolve(String trouble) {return false;}
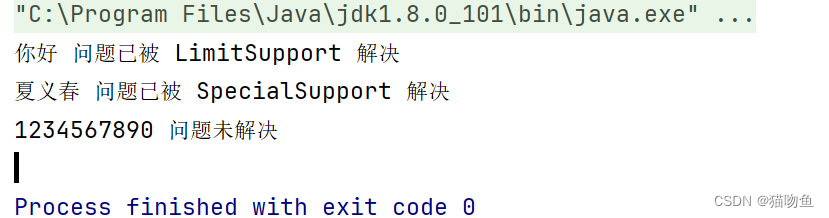
}public class ChainDemoMain {public static void main(String[] args) {Support noSupport = new NoSupport();Support limitSupport = new LimitSupport();Support specialSupport = new SpecialSupport();// 构建责任链specialSupport.setNext(limitSupport.setNext(noSupport));specialSupport.support("你好");specialSupport.support("夏义春");specialSupport.support("1234567890");}
}
输出如下:
2. 应用
-
责任链模式在很多地方都有所使用,如 Spring中的过滤器、拦截器、Dubbo中的 Filter, Spring Cloud Gateway 中的 GlobalFilter 等等。这里以Spring的 拦截器为例。HandlerInterceptorAdapter 定义如下,
public abstract class HandlerInterceptorAdapter implements HandlerInterceptor {/*** This implementation always returns <code>true</code>.*/public boolean preHandle(HttpServletRequest request, HttpServletResponse response, Object handler)throws Exception {return true;}/*** This implementation is empty.*/public void postHandle(HttpServletRequest request, HttpServletResponse response, Object handler, ModelAndView modelAndView)throws Exception {}/*** This implementation is empty.*/public void afterCompletion(HttpServletRequest request, HttpServletResponse response, Object handler, Exception ex)throws Exception {}}在 DispatcherServlet#doDispatch 中,Spring 在分发请求的前后都会将请求交由 HandlerInterceptor 的责任链来执行一遍,具体的代码在 HandlerExecutionChain 中,如下是其中一小部分:
... boolean applyPreHandle(HttpServletRequest request, HttpServletResponse response) throws Exception {// 遍历所有注册的拦截器并依次触发for (int i = 0; i < this.interceptorList.size(); i++) {HandlerInterceptor interceptor = this.interceptorList.get(i);if (!interceptor.preHandle(request, response, this.handler)) {triggerAfterCompletion(request, response, null);return false;}this.interceptorIndex = i;}return true;}void applyPostHandle(HttpServletRequest request, HttpServletResponse response, @Nullable ModelAndView mv)throws Exception {for (int i = this.interceptorList.size() - 1; i >= 0; i--) {HandlerInterceptor interceptor = this.interceptorList.get(i);interceptor.postHandle(request, response, this.handler, mv);}}...
个人使用:该部分内容是写给自己看的,帮助自身理解,因此就不交代项目背景了,读者请自行忽略(◐ˍ◑):
-
在项目A 中,需要对客户进行计费,客户可以自定义计费规则组合,因此对于每种计费规则都是一个实现类,这里实现则是将每个多个客户的计费规则组成成一个链路,即责任链。和上面的区别在于,上面的场景当某一个 Support 处理完成后就不再执行下面的Support,而这里的情况则是需要将链路中所有可以处理当前情况的Support 全部执行,得到最终结果。Demo如下:
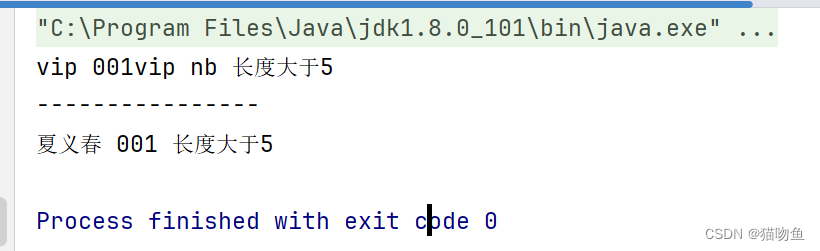
public abstract class Rule {/*** 下一个规则*/@Setterprivate Rule next;/*** 处理费用** @param fee*/public final String handle(String fee) {fee = doHandle(fee);if (next != null) {return next.handle(fee);}return fee;}/*** 处理** @param fee*/protected abstract String doHandle(String fee); }public class VipRule extends Rule {// 处理 VIP 逻辑@Overrideprotected String doHandle(String fee) {return fee.contains("vip") ? fee + "vip nb" : fee;} }public class SpecialRule extends Rule {// 客户定制化逻辑@Overrideprotected String doHandle(String fee) {return fee.length() > 5 ? fee + " 长度大于5" : fee + " 长度小于5";} }public class DefaultRule extends Rule {@Overrideprotected String doHandle(String fee) {return fee;} }public class DemoMain {public static void main(String[] args) {final Rule vipRule = new VipRule();final Rule specialRule = new SpecialRule();final Rule defaultRule = new DefaultRule();vipRule.setNext(specialRule);specialRule.setNext(defaultRule);System.out.println(vipRule.handle("vip 001"));System.out.println("----------------");System.out.println(vipRule.handle("夏义春 001"));} }输出如下:
-
在项目B中,每个客户可以定制各自的单证处理逻辑,多个逻辑可以组成,形成链路后,依次执行逻辑,基本同项目 A 的情况,这里不再赘述。
3. 总结
扩展思路
- 弱化了发起请求方和处理请求的人之间的关系 :即弱化了发出请求的人(Client)与处理请求的人(ConcreteHandler)的之间的关系,当 Client 向第一个 ConcreteHandler 发出请求后,请求会在责任链中传播,最终处理请求的可能并不是第一个 ConcreteHandler,而是责任链中的某一个或者几个 Handler。
- 可以动态改变职责链 :我们可以很轻易的增加或减少责任链中的逻辑。
- 专注于自己的工作 :责任链模式可以让每个 Handler 专注自身的逻辑,而无需考虑一些额外的场景逻辑。
相关设计模式
- Composite 模式:Handler 角色经常会使用 Composite 模式
- Command 模式: 有时候会使用 Command 模式向 Handler 角色发送请求
一时的小想法,仅仅个人理解,无需在意 :
- 责任链模式有两种情况,一种是执行即结束,即链路中的某个 Handler 可以处理这个请求后则阻断后续链路,另一种是责任链中所有支持当前请求的Handler都会将结果处理,并返回最终结果。两种情况需要考虑自己的业务场景去选择。
参考内容
https://www.cnblogs.com/yb-ken/p/15084837.html