什么是开源发布工具包?
恭喜你的论文成功发表,这是一个巨大的成就!你的研究成果将为学界做出贡献。
其实除了发表论文之外,你还可以通过发布研究的其他部分,如代码、数据集、模型等,来增加研究的可见度和采用率。这将使更多人能够使用你的研究,并推动研究成果的应用。我们整理了这份文件,让你可以更好的了解和实践开源。希望这份文件对你有所帮助!
什么是开源?
公开研究 - 不仅仅是论文,还包括相关的所有成果,如代码、模型、数据集或在线演示。
为什么要开源?
进行开放获取研究[^1],可以让更多的人了解和使用你的研究或项目成果,促进社区研究人员之间的合作。通过共享机器学习的知识和资源以及社区协作,来推动机器学习领域的发展。
[^1]: 开放获取意味着一个成果是公开可访问的。例如,你可以公开发布一个模型,同时拥有一个不完全符合开源倡议组织 (OSI) 对开源所设定的确切标准的许可证。例如,如果许可证限制了模型的使用方式,它就不被视为开源。不过,它仍然是对社区有价值的开放获取成果!
如何开源?
机器学习发布有很多的形式和规模。你可以根据你的时间线、优先级、内部政策或者其他因素来决定如何开源和开源哪些内容。比如:你可以只公布代码,也可以公布模型等其他成果。
以下是开源的步骤概览:
论文
代码仓库
数据集
模型
构建在线演示 demo
推广应用
你可以自由定义想要发布的内容、如何发布以及什么时间进行发布;本文档会详细介绍上述每项内容的具体步骤和指导。
你会用到什么工具?
分享论文可以使用arXiv :这是一个免费的可以公开发表论文的平台,在机器学习领域中被广泛使用。
分享代码可以使用 GitHub :这是一个代码版本控制平台。在 GitHub 上,你可以分享训练代码、如何加载模型或数据集的示例等。
分享模型权重,数据集及演示则可以使用 Hugging Face Hub :HF 是一个协作式机器学习平台,人们可以在其中轻松地探索、体验并共同创建机器学习。此外它还提供一定的社交功能,如论文讨论。
如何使用这份文档?
这份文档提供了具体的项目和步骤指导,你可以选择按照步骤完成所有项目成果的发布,也可以根据自己的需求来选择想要发布的项目成果。步骤看似很多,但是每一步仅需不到一分钟的时间即可完成。我们建议你复制这份文档,以便随时查阅。文档末尾会有一个核对清单,帮助你核对每一步,为开源你的项目成果做好充分的准备。
热门开源发布示例
Meta 的 Llama 2 (论文, 代码库, 模型, 演示)
EPFL 的 Meditron (论文, 代码库, 模型, 数据)
Adept 的 Fuyu (博客, 模型, 演示)
Meta 的 Seamless (论文, 代码库, 合集)
GitHub 仓库:
https://github.com/facebookresearch/seamless_communication
https://github.com/CompVis/stable-diffusion
研究模型:
https://huggingface.co/microsoft/phi-2
https://huggingface.co/meta-llama/Llama-2-7b
研究数据集:
https://huggingface.co/datasets/epfl-llm/guidelines
https://huggingface.co/datasets/princeton-nlp/SWE-bench
在线演示:
https://huggingface.co/spaces/facebook/seamless_m4t
https://huggingface.co/spaces/andreped/AeroPath
发布论文
可以通过 arXiv 来 上传并与社区分享你的论文。这是一个免费平台,并且不需要同行评审。
撰写并准备论文
第一步是撰写论文。一个常用的协作论文撰写工具是 Overleaf(用于 LaTeX 工作)。如果向会议提交论文,请遵循它们的官方模板和风格指南。
查阅 arXiv 官方的指南,包括格式期望和授权许可。

提交论文
访问你的 用户页面 并点击“提交”即可提交可能需要一些时间来处理,并且只在周日至周四开放。
注意: 首次提交到某个类别时,需要社区中的某人认可它才能发布。但请注意,这不是同行评审!
发布代码库
可以使用 GitHub 来发布和分享代码。GitHub 是一个代码版本控制平台。在 GitHub 上,你可以分享你的代码库(包括推理/建模代码、训练代码等)。
在 https://github.com/new 创建一个带有 README 和你选择的许可证的仓库。

编写 README。
README 是描述项目的文件,一般使用 markdown 编写,这是一种用于文本格式化的相当简单的语言。建议在README中添加描述、成果链接(如你的论文)以及一些代码示例。
示例

上传代码
接下来就是要上传你的代码了!你可以上传包括运行模型的代码、训练脚本或者更多内容!
如果你想同时将你的模型集成到 Hugging Face 库中,以实现即时集成。请随时联系 open-source@huggingface.co,我们会尽快评估并反馈。
发布数据集
Hugging Face Hub 提供数据集的托管、发现和社交功能。HF 还有一个名为 datasets 的开源库,可用于以编程方式加载数据集,并在大型数据集上有效地进行流式处理。此外,HF 还提供查看器,可让用户在浏览器中直接探索数据。
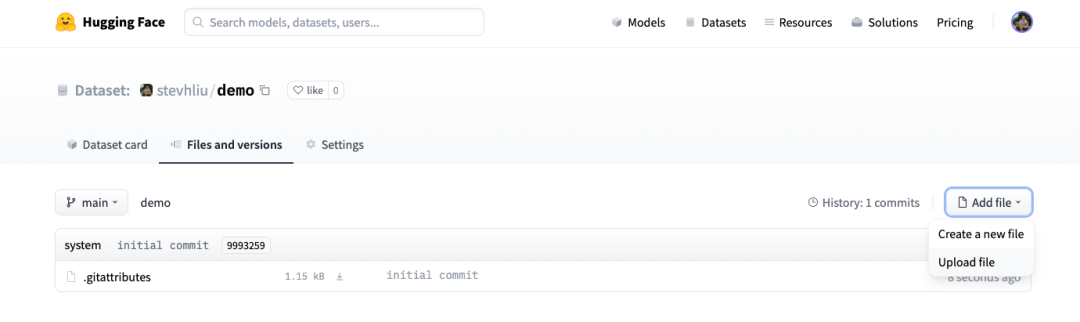
在 https://huggingface.co/new-dataset 创建一个仓库,可以在你的账户或在组织名下进行创建。

向仓库添加文件。
在仓库的 文件和版本 选项卡并点击“上传文件”。支持拖放文件/文件夹或直接上传。

注意:Hub 支持不同的文件格式。这些格式将在浏览器中获得查看器,并自动在 datasets 库中获得支持。对于其他格式,你可以编写自己的加载脚本。查看官方文档。
from datasets import load_datasetdataset = load_dataset("stevhliu/demo")注意: Hugging Face 使用 Git 作为数据和代码的存储库。如果熟悉 Git(例如,如果你使用 GitHub 或 GitLab),你可以使用类似的工作流程,而无需使用 UI。更多详情见指南。你还可以使用datasets 库来推送仓库。
创建数据集卡片
数据集卡片是包含数据集相关信息的文件,通常与数据集一起发布,用于帮助用户更好地理解和使用数据集。数据集卡片对于促进数据集的可发现性、可重复性和共享具有重要作用。
除了主要内容之外,数据集卡片还包含顶部的元数据,例如许可证类型、任务类别等。这些元数据可以帮助用户快速了解数据集的相关信息,从而更好地选择合适的数据集进行研究或开发。
我们强烈建议定义数据集的许可证类型,以便用户了解数据集的使用权限和限制。同时,明确定义数据集的任务类别,可以帮助用户更准确地找到与其研究或开发相关的数据集。数据的可发现性和使用都是数据集的重要属性,数据集卡片可以有效地促进这两项属性的提升。
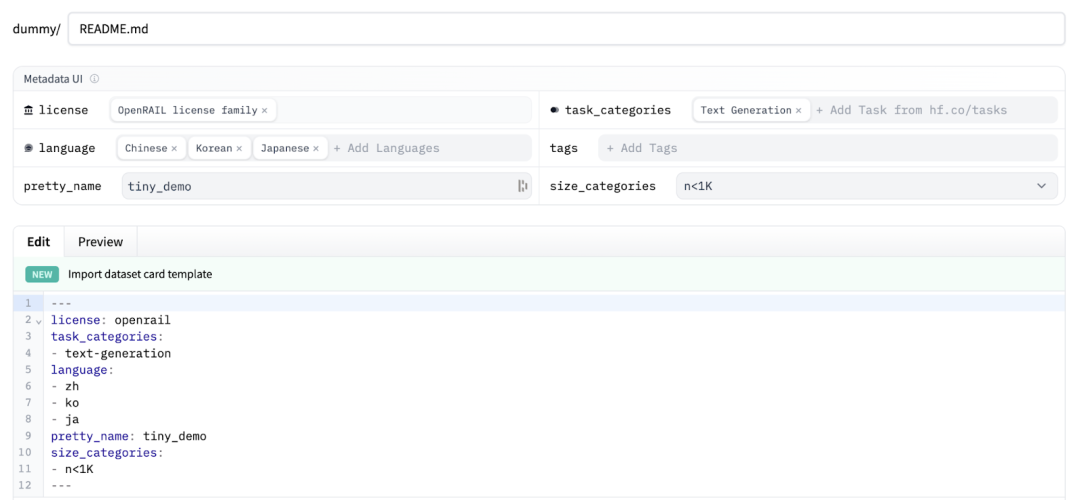
我们建议在数据集卡片内容中添加指向你的 arXiv 论文的链接。HF 会自动将它们链接在一起。你可以在其官方文档中阅读有关数据集卡片的更多信息。
发布模型权重
Hugging Face Hub 为模型提供托管、发现和社交功能。它不局限于 HF 官方库,你可以分享任何 ML 库的模型权重(或分享自己的代码库)。
在 https://huggingface.co/new 创建一个仓库,可以在你的账户或组织名下创建仓库。
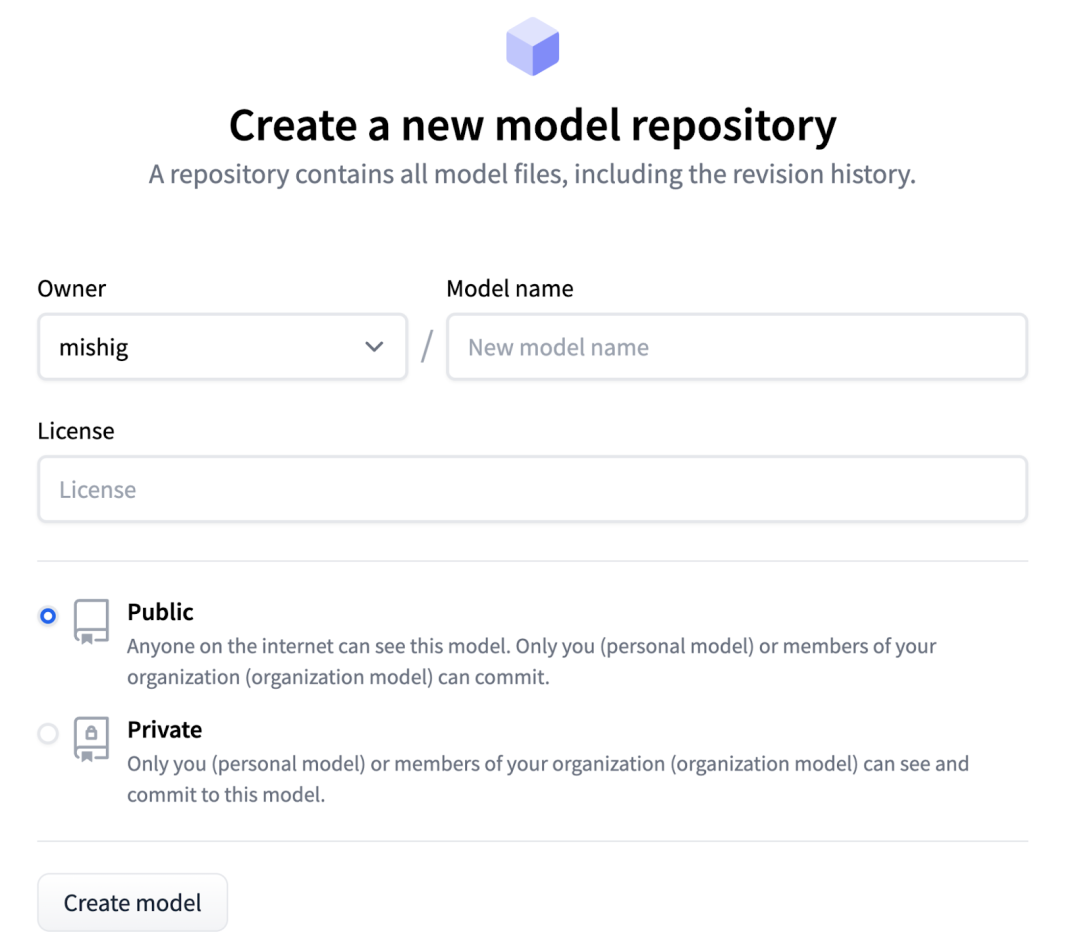
向仓库添加文件。
在仓库的文件选项卡并点击“上传文件”。可以拖放文件/文件夹或直接上传。
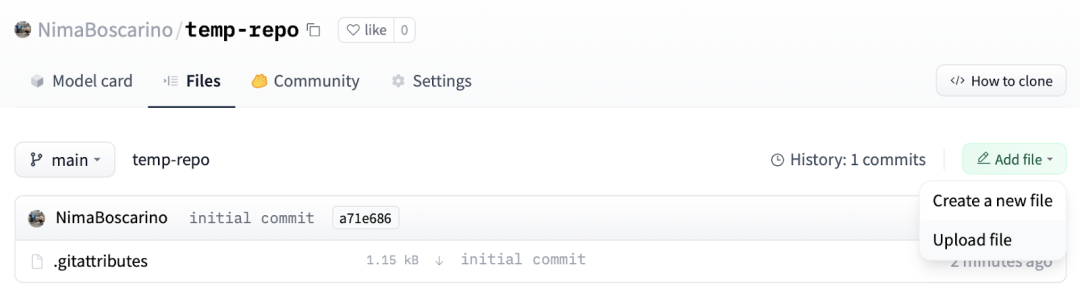
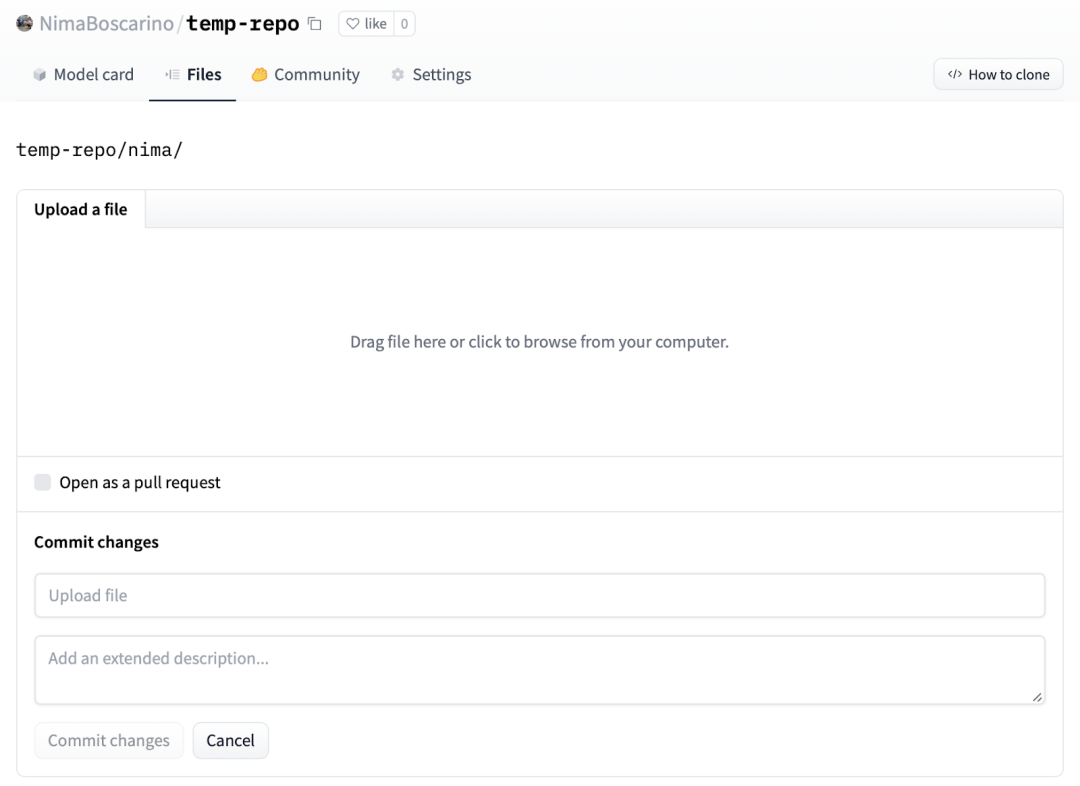
注意:Hugging Face 使用 Git 作为数据和代码的存储库。如果你熟悉 Git(例如,如果你使用 GitHub 或 GitLab),你可以使用类似的工作流程,而无需使用 UI可以使用与 UI 不同的类似工作流程。更多详情见指南。
创建模型卡片
模型卡片是随模型一起提供的文件,主要包含关于模型的实用信息。模型卡片对于发现、可重现性和共享模型来说至关重要!你可以在任何模型仓库中找到名为README.md 的模型卡片。我们强烈建议在其中添加一个代码片段,展示如何加载和使用模型。
除了以上内容外,模型卡片还可以包含顶部的有用元数据。UI 提供了一些工具来帮助你创建。我们强烈建议你指定许可证和管道标签(用于指定模型的任务,如文本到图像)。这两者是发现和使用模型的关键。
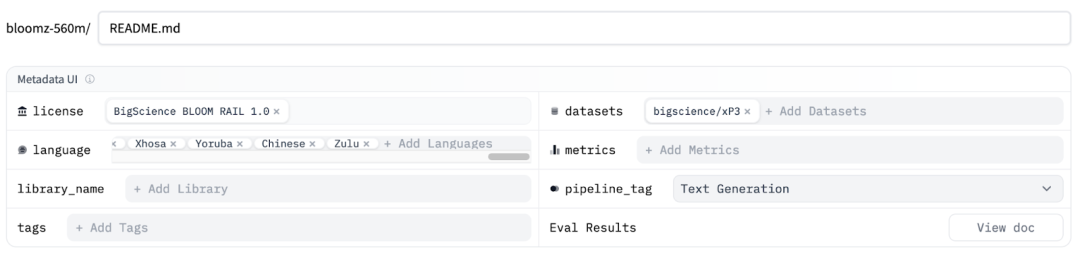
还有其他值得添加的内容。你可以在这里了解更多。比如:
language 语言:模型支持的语言列表
tags 标签:帮助发现模型标签
datasets 数据集:用于训练模型的数据集
base_model 基础模型:如果是微调模型的话使用的基础模型是什么?
library_name 库名称:用来加载模型的库
我们建议在模型卡片内容中添加相关的 arXiv 论文链接。HF 会自动将两者链接在一起。
你可以在其官方文档中了解更多关于模型卡片的信息。
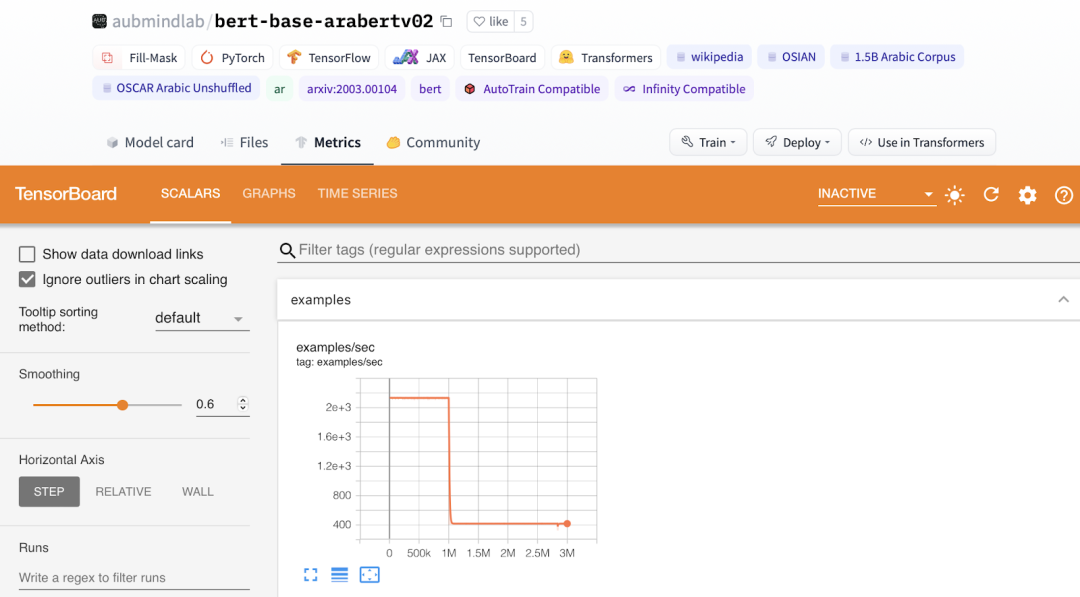
[可选] 添加 TensorBoard 跟踪
TensorBoard 是一个提供用于可视化指标工具的工具。如果你将 TensorBoard 跟踪推送到 Hub,则会自动显示出一个 TensorBoard 实例的” Metrics”选项卡。请在此处相关信息这里信息。
[可选] 编程访问
如果你想在代码库或在线演示中从 Hugging Face 下载模型,可以使用 huggingface_hub Python 库进行编程访问。例如,以下代码将下载指定文件。
from huggingface_hub import hf_hub_downloadhf_hub_download(repo_id="lysandre/arxiv-nlp", filename="config.json")以下代码将下载库中的所有文件:
from huggingface_hub import snapshot_downloadsnapshot_download(repo_id="lysandre/arxiv-nlp", revision="refs/pr/1")创建在线演示
Hugging Face Hub 为在线演示提供托管、发现和社交功能 - 称为 Spaces。Spaces 可以轻松创建和部署ML驱动的在线演示,只需几分钟即可完成。
为什么要做在线演示?
创建在线演示可以让你的研究或项目成果更易于理解和使用,有助于其推广。任何拥有浏览器的人都可以体验你的研究成果,甚至可以让成果一日爆红!
在线演示的展现形式
你可以自由选择在线演示的展现形式!我们在这里提供一些热门在线演示作为参考并分享如何创建在线演示 Spaces。
Stability 的 Stable Diffusion(文本到图像)

Meta 的 MusicGen(文本到音乐生成)
jbilcke 的 AI Comic Factory(漫画生成)

注意:Spaces 在 CPU 上运行时是免费的。如果需要使用 GPU 运行,你可以申请社区资助(在 设置 选项卡中)或购买 T4、A10G 及 A100。
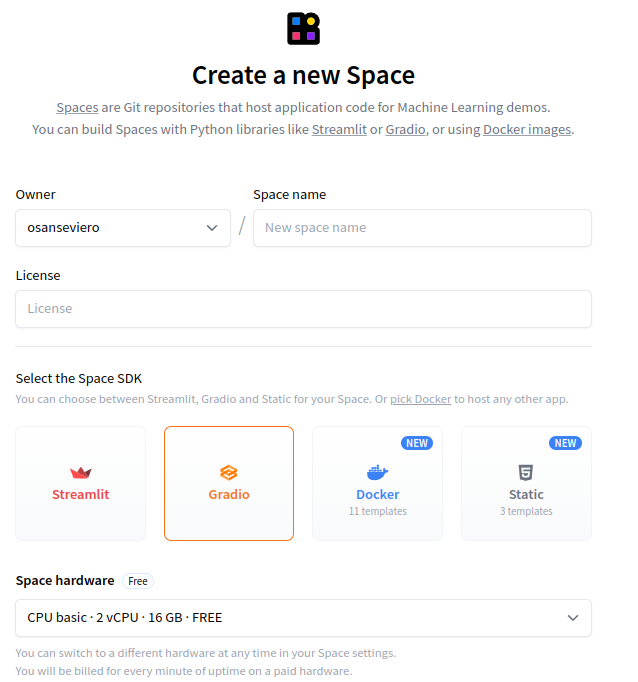
在 https://huggingface.co/new-space 创建一个仓库,可以在你的账户或在组织名下创建。
Spaces 可以使用开源 Python 库(例如:Gradio或Streamlit)创建,也可以使用 Docker 或静态 HTML 页面。我们建议使用 Gradio 进行快速原型制作,当然也可以使用你喜欢的其他工具!
创建应用程序文件
假设你正在创建一个 Gradio 演示。请随意查阅 Gradio Spaces 文档。可以在仓库的”文件”选项卡点击”上传文件”或”创建新文件”。主 Python 脚本应命名为 app.py。

编写你的应用代码
如果你想要加载模型或数据集,你可以使用huggingface_hub Python库
import gradio as grdef greet(name):return f"Hello {name}"}demo = gr.Interface(fn=greet,inputs=["text"],outputs=["text"],
)demo.launch()体验应用!
你的应用已经创建成功!建议在创建之后操作即使体验以保证其运行顺利。

注意:
Hugging Face 使用 Git 作为数据和代码的存储库。如果你熟悉 Git(例如,如果你使用 GitHub 或 GitLab),你可以使用类似的工作流程,而无需使用 UI可以使用与 UI 不同的类似工作流程。更多详情见指南。
Spaces 常见问题汇总
我可以使用哪些模型库?
你可以使用任何你喜欢的库,可以在 requirements.txt 文件中定义你的依赖项。
如何加载模型?
如果你想从 Hub 下载模型到你的Spaces,可以使用 huggingface_hub Python 库进行编程访问。例如,以下代码将下载某个指定文件。
from huggingface_hub import hf_hub_downloadhf_hub_download(repo_id="lysandre/arxiv-nlp", filename="config.json")而以下代码将下载仓库中的所有文件。
from huggingface_hub import snapshot_downloadsnapshot_download(repo_id="lysandre/arxiv-nlp", revision="refs/pr/1")我可以用 Gradio 做什么?
随时查看 Gradio 文档和指南。Gradio 提供了一个简单的 API 来创建在线演示,并可以让你自由定义在线演示的展现方式。
例如添加音频、文本、带注释的图像、聊天机器人、代码、文件、图像画廊、3D 对象、视频等组件,甚至可以创建符合你需求的组件。
热门 Spaces 制作小贴士?
简单的演示更受欢迎。
有标题、描述和简要说明演示的内容。
有模型或论文的链接。
添加偏见和内容认可(参见 SD 演示 作为示例)。
推广宣传:
在公布论文、模型/数据集、GitHub 仓库和在线演示之后,就是要确保你的研究能尽快被社区熟知!这里有一些方法可以帮助提高在社区中推广和宣传你的研究成果。
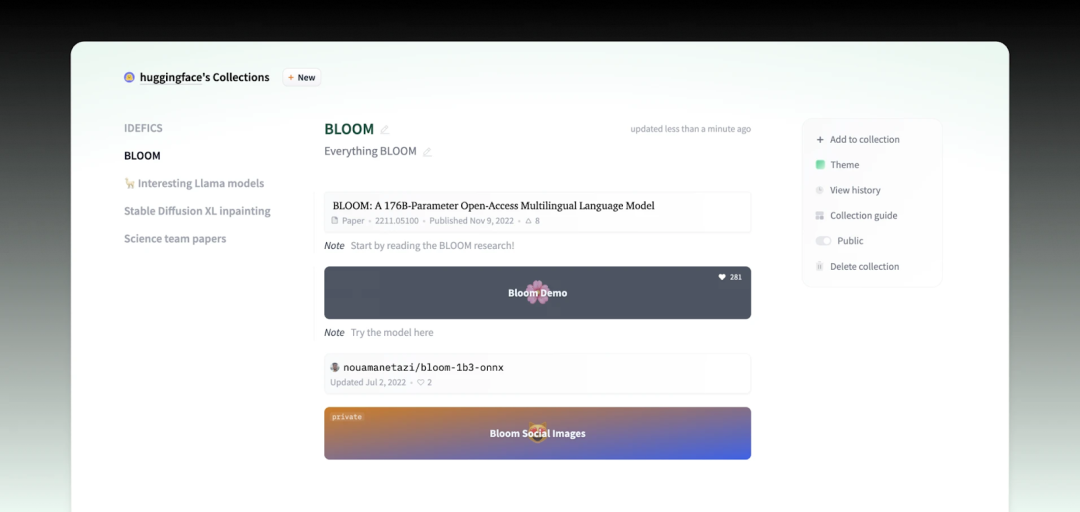
【加分项】Collections
你可以为项目成果(包括模型、数据集、演示、论文)在 Hub 上创建一个合集,你创建的合集会直接显示在个人账户中。更多详情请查看文档。
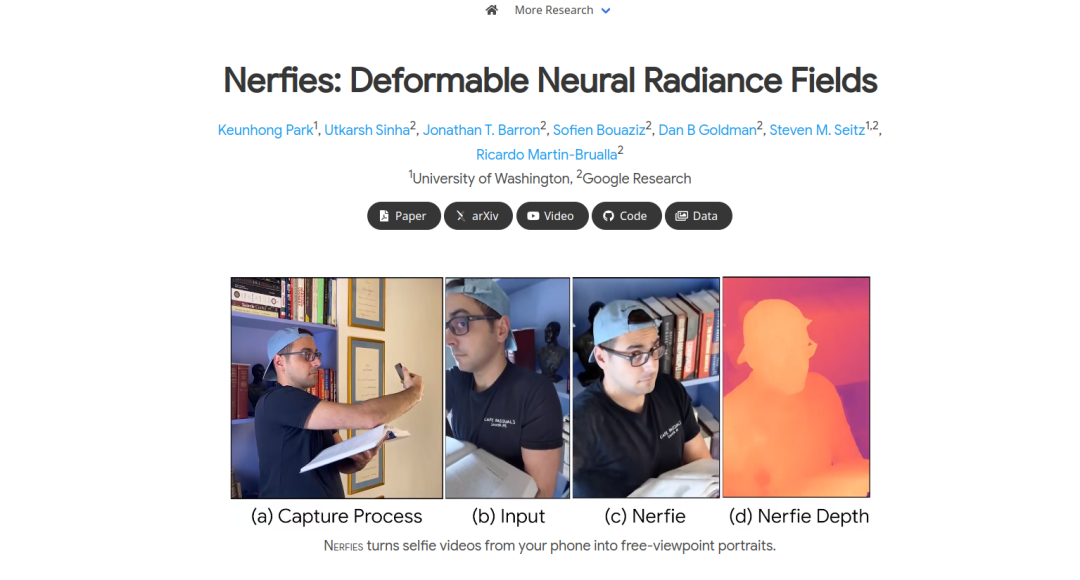
【加分项】Paper Space
通过GitHub Pages 或 Hugging Face Spaces,你可以将所有的项目成果和应用都集中在一个网页中。(例如:(https://nerfies.github.io/))如果你选择使用Spaces, 可以从 Nerfies/Paper Project 模板 中选择喜欢的模版,或者自创模版进行展示。
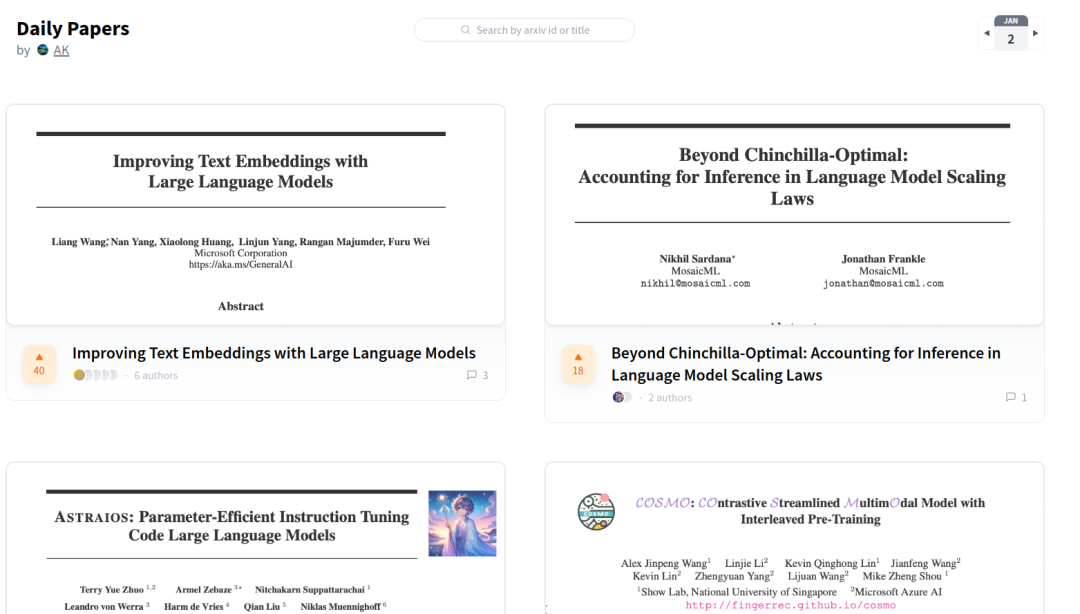
【加分项】Hugging Face Paper 页面
在 HF 论文页面 ,你可以发现和探索与研究论文相关的所有成果(包括:模型,数据集和在线演示demo)。你还可以在喜欢的论文页面和作者或社区一起来进行讨论。论文在 arXiv 上发表之后,你可以在 HF 上进行索引作为作者认领论文,认领之后论文将直接链接到你的账户并在账户中展示。更多详情请查看 文档。
推广
如果你已经完成了以上的步骤,那么恭喜你已经成功发布了你的项目成果!接下来也是最重要的一个环节是要进行推广。使用推特或 Reddit 等社交平台来撰写博客文章,或进行发布公告来为研究的推广助力。
建议你与其他研究人员或开源贡献者等合作伙伴联合发布,这样可以有效的扩大推广受众覆盖率。在开始推广之后,你还需要和与社区进行互动!最好的推广不仅仅是宣传你的项目成果,也需要和你项目的受众建立良好的互动关系。关系和与你的受众互动。
如何使用这份文档?
我们建议复制这份文档,并使用下面的步骤来跟踪进度。每步的操作时间基本只需 1 分钟。,它们会在 你决定做什么时 指导你,并且可以快速完成!下面有文档解释如何做不同的项目。
发布论文
准备好论文并进行排版
在 ArXiv 上发布
在 HF 上索引论文
发布代码库
发布数据集
选择许可证
将数据集上传到 Hub(例如 HF、Kaggle、Zenodo)
创建数据集卡片
添加元数据(任务、许可证、语言等)
添加其他成果的链接(arxiv 链接等)
编写卡片内容
发布模型
选择许可证
将模型上传到 Hub
创建模型卡片
添加元数据(任务、许可证、数据集等)
添加其他成果的链接(arxiv 链接)
编写卡片内容
添加展示如何使用模型的代码片段
构建演示
编写 Colab 或脚本
创建在线演示 Space
准备发布
确保你的项目成果之间相互关联
创建论文页面
构建成果合集
推广宣传
庆祝🎉