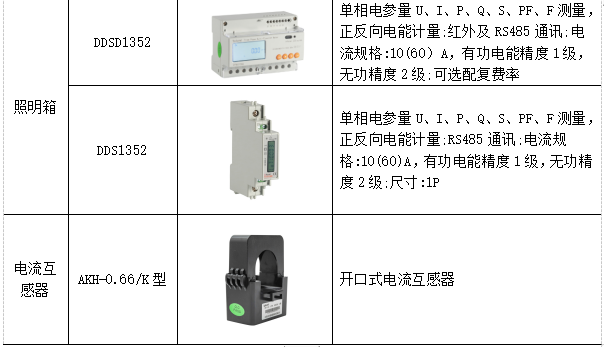
| 试题编号: | 202312-1 |
| 试题名称: | 仓库规划 |
| 时间限制: | 1.0s |
| 内存限制: | 512.0MB |
| 问题描述: | 问题描述西西艾弗岛上共有 n 个仓库,依次编号为 1⋯n。每个仓库均有一个 m 维向量的位置编码,用来表示仓库间的物流运转关系。 具体来说,每个仓库 i 均可能有一个上级仓库 j ,满足:仓库 j 位置编码的每一维均大于仓库 i 位置编码的对应元素。比如编码为 (1,1,1) 的仓库可以成为 (0,0,0) 的上级,但不能成为 (0,1,0) 的上级。如果有多个仓库均满足该要求,则选取其中编号最小的仓库作为仓库 i 的上级仓库;如果没有仓库满足条件,则说明仓库 i 是一个物流中心,没有上级仓库。 现给定 n 个仓库的位置编码,试计算每个仓库的上级仓库编号。 输入格式从标准输入读入数据。 输入共 n+1 行。 输入的第一行包含两个正整数 n 和 m,分别表示仓库个数和位置编码的维数。 接下来 n 行依次输入 n 个仓库的位置编码。其中第 i 行(1≤i≤n)包含 m 个整数,表示仓库 i 的位置编码。 输出格式输出到标准输出。 输出共 n 行。 第 i 行(1≤i≤n)输出一个整数,表示仓库 i 的上级仓库编号;如果仓库 i 没有上级,则第 i 行输出 0。 样例输入
样例输出
样例解释对于仓库 2:(−1,−1) 来说,仓库 1:(0,0) 和仓库 3:(1,2) 均满足上级仓库的编码要求,因此选择编号较小的仓库 1 作为其上级。 子任务50% 的测试数据满足 m=2; 全部的测试数据满足 0<m≤10、0<n≤1000,且位置编码中的所有元素均为绝对值不大于 |
编译环境Dev-cpp(C语言)
#include <stdio.h>int main() {int n=0,m=0;scanf("%d %d",&n,&m); int a[1000][10]={0};int x=0,y=0;int value=0;int ans[10]={0};for(x=0;x<n;x++){for(y=0;y<m;y++){scanf("%d",&value);a[x][y]=value;}}int num=0;int flag=1;for(num=0;num<n;num++){int res=0;for(x=0;x<n;x++){if (x == num) {continue; // 跳过当前仓库}flag=1;for(y=0;y<m;y++){if(a[x][y]<=a[num][y]){flag=0;break;}}if(flag==1){res=x+1;break;}}printf("%d\n",res);}return 0;
}编译环境Dev-cpp(C++语言)
#include <stdio.h>
#include <stdlib.h>int main() {int N = 0, M = 0;scanf("%d %d", &N, &M);int** warehouse = (int**)malloc((N + 1) * sizeof(int*));for (int i = 0; i <= N; i++) {warehouse[i] = (int*)malloc(M * sizeof(int));}for (int i = 1; i <= N; i++) {for (int j = 0; j < M; j++) {scanf("%d", &warehouse[i][j]);}}for (int i = 1; i <= N; i++) {int res = 0;for (int j = 1; j <= N; j++) {if (i != j) {int flag = 1;for (int k = 0; k < M; k++) {if (warehouse[i][k] >= warehouse[j][k]) {flag = 0;break;}}if (flag) {res = j;break;}}}printf("%d\n", res);}for (int i = 0; i <= N; i++) {free(warehouse[i]);}free(warehouse);return 0;
}| 试题编号: | 202312-2 |
| 试题名称: | 因子化简 |
| 时间限制: | 2.0s |
| 内存限制: | 512.0MB |
| 问题描述: | 题目背景质数(又称“素数”)是指在大于 1 的自然数中,除了 1 和它本身以外不再有其他因数的自然数。 问题描述小 P 同学在学习了素数的概念后得知,任意的正整数 n 都可以唯一地表示为若干素因子相乘的形式。如果正整数 n 有 m 个不同的素数因子 小 P 认为,每个素因子对应的指数 试编写程序处理 q 个查询:
输入格式从标准输入读入数据。 输入共 q+1 行。 输入第一行包含一个正整数 q,表示查询的个数。 接下来 q 行每行包含两个正整数 n 和 k,表示一个查询。 输出格式输出到标准输出。 输出共 q 行。 每行输出一个正整数,表示对应查询的结果。 样例输入
样例输出
样例解释查询一:
查询二:
查询三:
子任务40% 的测试数据满足:n≤1000; 80% 的测试数据满足:n≤ 全部的测试数据满足:1<n≤1010 且 1<k,q≤10。 |
编译环境Dev-cpp(C++语言)
#include <stdio.h>long long int simplifyValue(long long int n, int k) {long long int result = 1;int factor = 2;while (n > 1) { // 只要 n 大于 1,就继续进行素数因子的检查和处理if (n % factor == 0) { // 如果 factor 是 n 的因子int count = 0;while (n % factor == 0) { // 计算 factor 在 n 中的出现次数n /= factor;count++;}if (count >= k) { // 如果 factor 的指数大于等于阈值 kint i;for (i = 0; i < count; i++) { // 将 factor 乘以 count 次,累积到结果 result 中result *= factor;}}}factor++; // 检查下一个因子}return result;
}int main() {int q;scanf("%d", &q);int i;for (i = 0; i < q; i++) {long long int n;int k;scanf("%lld %d", &n, &k);long long int result = simplifyValue(n, k);printf("%lld\n", result);}return 0;
}| 试题编号: | 202312-3 |
| 试题名称: | 树上搜索 |
| 时间限制: | 1.0s |
| 内存限制: | 512.0MB |
| 问题描述: | 题目背景西西艾弗岛大数据中心为了收集用于模型训练的数据,推出了一项自愿数据贡献的系统。岛上的居民可以登录该系统,回答系统提出的问题,从而为大数据中心提供数据。为了保证数据的质量,系统会评估回答的正确性,如果回答正确,系统会给予一定的奖励。 近期,大数据中心需要收集一批关于名词分类的数据。系统中会预先设置若干个名词类别,这些名词类别存在一定的层次关系。例如,“动物”是“生物”的次级类别,“鱼类”是“动物”的次级类别,“鸟类”是“动物”的次级类别,“鱼类”和“鸟类”是“动物”下的邻居类别。这些名词类别可以被按树形组织起来,即除了根类别外,每个类别都有且仅有一个上级类别。 下图示意性地说明了标有星号的类别的次级类别和后代类别。
系统向用户提出问题的形式是:某名词是否属于某类别,而用户可以选择“是”或“否”来回答问题。该问题的含义是:某名词是否可以被归类到某类别或其后代类别中。 例如,要确定名词“鳕鱼”的类别,系统会向用户提出“鳕鱼是否属于动物”,当用户选择“是”时,系统会进一步询问“鳕鱼是否属于鱼类”,当用户选择“是”时,即可确定“鳕鱼”可以被归类到“鱼类”这一类别。 此外,如果没有更具体的分类,某一名词也可以被归类到非叶子结点的类别中。例如,要确定“猫”的类别,系统可以向用户提出“猫是否属于动物”,当用户选择“是”时,系统会进一步分别询问“猫”是否属于“鱼类”和“鸟类”,当两个问题收到了否定的答案后,系统会确定“猫”的类别是“动物”。 大数据中心根据此前的经验,已经知道了一个名词属于各个类别的可能性大小。为了用尽量少的问题确定某一名词的类别,大数据中心希望小 C 来设计一个方法,以减少系统向用户提出的问题的数量。 问题描述小 C 观察了事先收集到的数据,并加以统计,得到了一个名词属于各个类别的可能性大小的信息。具体而言,每个类别都可以赋予一个被称为权重的值,值越大,说明一个名词属于该类别的可能性越大。由于每次向用户的询问可以获得两种回答,小 C 联想到了二分策略。他设计的策略如下:
小 C 请你帮忙编写一个程序,来测试这个策略的有效性。你的程序首先读取到所有的类别及其上级次级关系,以及每个类别的权重。你的程序需要测试对于被归类到给定类别的名词,按照上述策略提问,向用户提出的所有问题。 输入格式从标准输入读入数据。 输入的第一行包含空格分隔的两个正整数 n 和 m,分别表示全部类别的数量和需要测试的类别的数量。所有的类别从 1 到 n 编号,其中编号为 1 的是根类别。 输入的第二行包含 n 个空格分隔的正整数 输入的第三行包含 (n−1) 个空格分隔的正整数 接下来输入 m 行,每行一个正整数,表示需要测试的类别编号。 输出格式输出 m 行,每行表示对一个被测试的类别的测试结果。表示按小 C 的询问策略,对属于给定的被测类别的名词,需要依次向用户提出的问题。 每行包含若干空格分隔的正整数,每个正整数表示一个问题中包含的类别的编号,按照提问的顺序输出。 样例1输入
样例1输出
样例解释上述输入数据所表示的类别关系如下图所示,同时各个类别的权重也标注在了图上。
对于归类于类别 5 的某个名词,按照上述询问策略,应当对于树上的每个节点,都计算
对于归类于类别 3 的某个名词,按照上述询问策略,依次对类别 2、5 提问,过程与前述一致。但是由于类别 3 不属于类别 2 的后代类别,用户回答“否”,此时应当去掉类别 5 和其后代类别,仅保留类别 1、3、4。分别计算
子任务对 20% 的数据,各个类别的权重相等,且每个类别的上级类别都是根类别; 对另外 20% 的数据,每个类别的权重相等,且每个类别至多有一个下级类别; 对 60% 的数据,有 n≤100,且 m≤10; 对 100% 的数据,有 n≤2000,m≤100,且 |




(待更)
| 试题编号: | 202312-4 | ||||||||||||||||||||||||
| 试题名称: | 宝藏 | ||||||||||||||||||||||||
| 时间限制: | 1.5s | ||||||||||||||||||||||||
| 内存限制: | 512.0MB | ||||||||||||||||||||||||
| 问题描述: | 问题描述西西艾弗岛上埋藏着一份宝藏,小 C 根据藏宝图找到了宝藏的位置。藏有宝藏的箱子被上了锁,旁边写着一些提示:
经过小 C 的观察,每条指令的形式均为以下三种之一:
小 C 将所有的时刻发生的事件均记录了下来。具体地,共有 m 个时刻,每个时刻可能会发生两种事件:
由于小 C 并不会这个问题,他向你发起了求助。你需要帮助小 C 求出所有类型为 2 的事件所对应的密码。 输入格式从标准输入读入数据。 输入的第一行包含两个正整数 n,m。 接下来 n 行,按顺序给出初始时刻的每条指令:
接下来 m 行,按顺序给出每个时刻发生的事件:
输出格式输出到标准输出。 对于所有类型为 2 的事件,输出一行四个非负整数 样例1输入
样例1输出
样例解释第一次事件发生时,
依次执行第 2∼3 条指令,得到的队列为 第四次事件发生时,
依次执行第 1∼3 条指令,得到的队列为 样例2见题目目录下的2.in 与2.ans。 该样例满足测试数据 1∼3 的限制。 样例3见题目目录下的3.in 与3.ans。 该样例满足测试数据 4∼7 的限制。 样例4见题目目录下的4.in 与4.ans。 该样例满足测试数据 8,9 的限制。 样例5见题目目录下的5.in 与5.ans。 该样例满足测试数据 10,11 的限制。 样例6见题目目录下的6.in 与6.ans。 该样例满足测试数据 12∼15 的限制。 样例7见题目目录下的7.in 与7.ans。 该样例满足测试数据 16,17 的限制。 子任务对于所有测试数据,满足 1≤n,m≤
|
(待更)
| 试题编号: | 202312-5 | ||||||||||||||||||
| 试题名称: | 彩色路径 | ||||||||||||||||||
| 时间限制: | 2.0s | ||||||||||||||||||
| 内存限制: | 512.0MB | ||||||||||||||||||
| 问题描述: | 问题描述西西艾弗岛的路线图可以看作是一个具有 N 个节点和 M 条有向边的图。 对于游客顿顿来说,理想的观光路线应满足以下条件:
具体而言,理想的观光路线是一个节点序列,例如
一条路径的长度定义为边的总长度。你的任务是找到满足游客顿顿所有要求的最长观光路线。 输入格式从标准输入读入数据。 输入共五行。 输入的第一行包含四个正整数 N、M、L 和 K,分别表示图的节点数、边数、理想观光路线的节点数上限和颜色标签范围。 输入的第二行包含 N 个整数 接下来输入边的信息。 输入的第三行包含 M 个整数 输入的第四行包含 M 个整数 输入的第五行包含 M 个整数 输入数据保证不存在起点终点相同的边,如 (u,u);每条有向边 (u,v) 仅会出现一次,但不排除 (u,v) 和 (v,u) 可能同时存在。 输出格式输出到标准输出。 输出一个数,表示理想观光路线的最大长度。 样例输入
样例输出
样例解释以下是示例图,其中黑色和红色数字分别表示节点编号和边的长度。 {{ img('example.pdf', size = 1.0, align = 'middle', inline = False, caption='样例解释', label='fig:sample') }} 如下表所示,在不超过四个节点的限制下,共有五条从节点 0 到节点 5 的彩色路径。其中最长的一条是 (0,1,5),长度为 9。
子任务20% 的测试数据满足:对于每个 i(0≤i<N−1),有 另有 30% 测试数据满足:K≤15。 全部的测试数据满足:
|
(待更)