目录
1.资源池Pool管理
创建一个Pool资源池
查看集群Pool信息
查看资源池副本的数量
查看PG和PGP数量
修改pg_num和pgp_num的数量
修改Pool副本数量
删除Pool资源池
2.创建CephFS文件系统MDS接口
服务端操作(192.168.88.22)
1.在管理节点创建 mds 服务
2.查看各个节点的 mds 服务
3.创建存储池,启用 ceph 文件系统
4.查看mds状态
5.创建用户
客户端操作(192.168.88.50)
1.在客户端创建工作目录
2.在ceph的管理节点给客户端拷贝ceph的配置文件(192.168.88.22)
3.在客户端安装ceph软件包
4.在客户端制作秘钥文件
5.客户端挂载
3.创建Ceph块存储系统RBD接口
创建并初始化储存池
修改,删除,还原镜像
Linux客户端使用(192.168.88.50)
客户端使用RBD有两种方式
快照管理
快照分层
快照展平
镜像的导出导入
4.创建Ceph对象存储系统RGW接口
对象存储概念
Amazon S3
OpenStack Swift
RadosGW
创建RGW接口
开启http+https ,更改监听端口
5.OSD故障模拟与恢复
模拟OSD故障
将坏掉的osd踢出集群
把原来坏掉的osd修复后重新加入集群
1.资源池Pool管理
- Ceph 客户端向 monitor 请求集群的状态,并向 Pool 中写入数据,数据根据 PGs 的数量,通过 CRUSH 算法将其映射到不同的 OSD 节点上,实现数据的存储。 这里我们可以把 Pool 理解为存储 Object 数据的逻辑单元;当然,当前集群没有资源池,因此需要进行定义。
创建一个Pool资源池
cd /etc/ceph
ceph osd pool create 资源池名 64 64
查看集群Pool信息
ceph osd pool ls
或
ceph osd lspools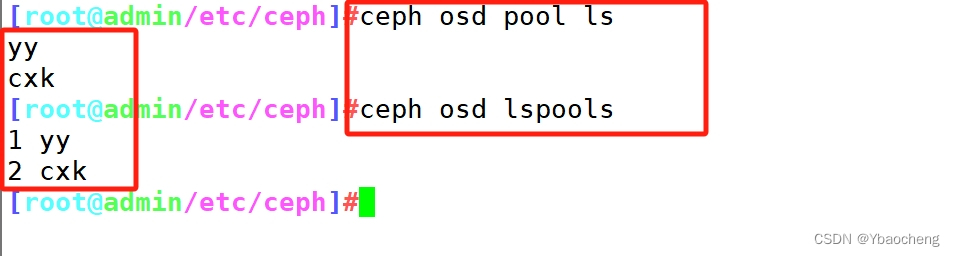
查看资源池副本的数量
ceph osd pool get 资源池名 size
查看PG和PGP数量
ceph osd pool get 资源池名 pg_num
ceph osd pool get 资源池名 pgp_num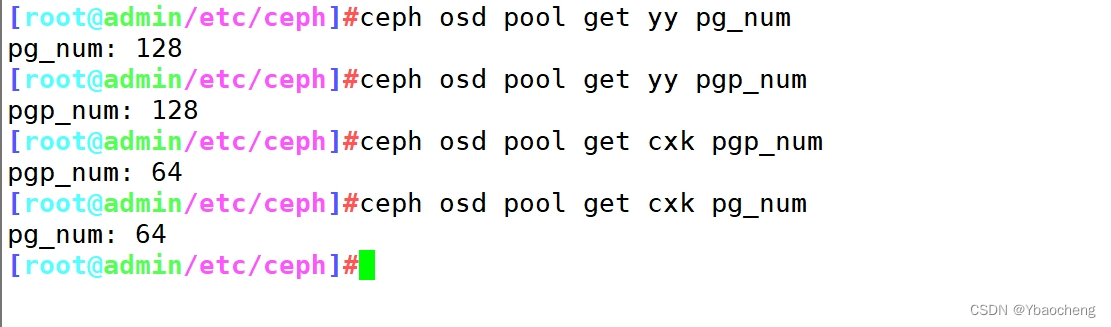
修改pg_num和pgp_num的数量
ceph osd pool set 资源池名 pg_num 128
ceph osd pool set 资源池名 pgp_num 128ceph osd pool get 资源池名 pg_num
ceph osd pool get 资源池名 pgp_num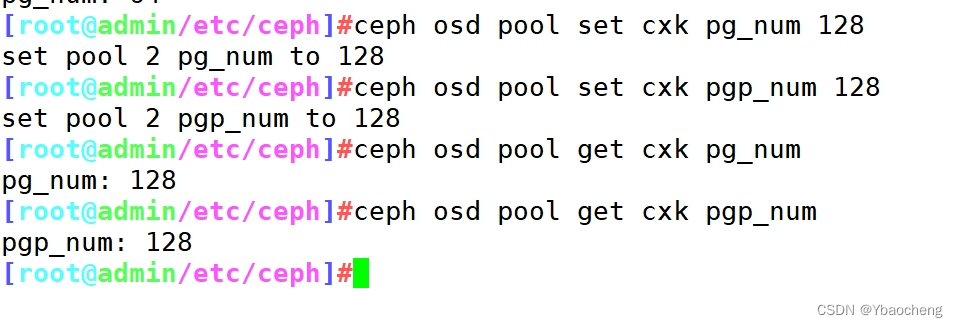
修改Pool副本数量
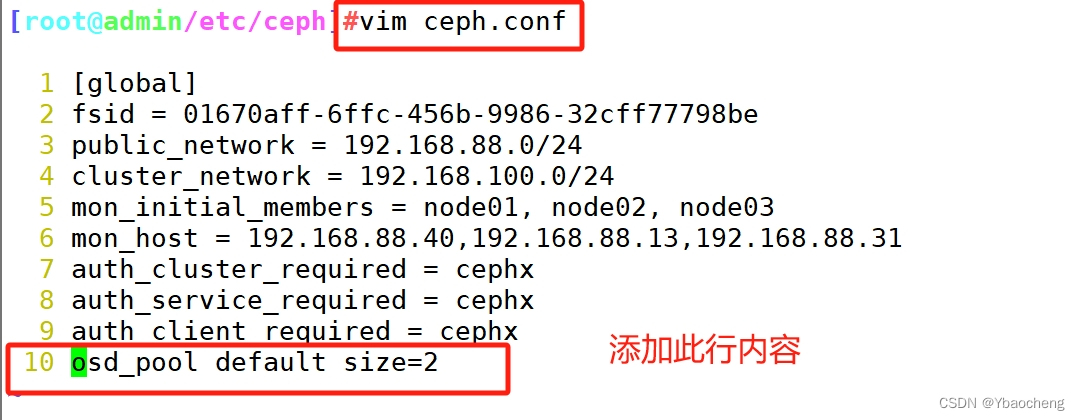
ceph osd pool set mypool size 2ceph osd pool get mypool size#修改默认副本数为 2
vim ceph.conf
......
osd_pool_default_size = 2ceph-deploy --overwrite-conf config push node01 node02 node03

删除Pool资源池
1)删除存储池命令存在数据丢失的风险,Ceph 默认禁止此类操作,需要管理员先在 ceph.conf 配置文件中开启支持删除存储池的操作
vim ceph.conf
......
[mon]
mon allow pool delete = true2)推送 ceph.conf 配置文件给所有 mon 节点
ceph-deploy --overwrite-conf config push node01 node02 node033)所有 mon 节点重启 ceph-mon 服务
systemctl restart ceph-mon.target4)执行删除 Pool 命令
ceph osd pool rm pool01 pool01 --yes-i-really-really-mean-it

2.创建CephFS文件系统MDS接口
服务端操作(192.168.88.22)
1.在管理节点创建 mds 服务
cd /etc/ceph
ceph-deploy mds create node01 node02 node03
2.查看各个节点的 mds 服务
ssh root@node01 systemctl status ceph-mds@node01
ssh root@node02 systemctl status ceph-mds@node02
ssh root@node03 systemctl status ceph-mds@node03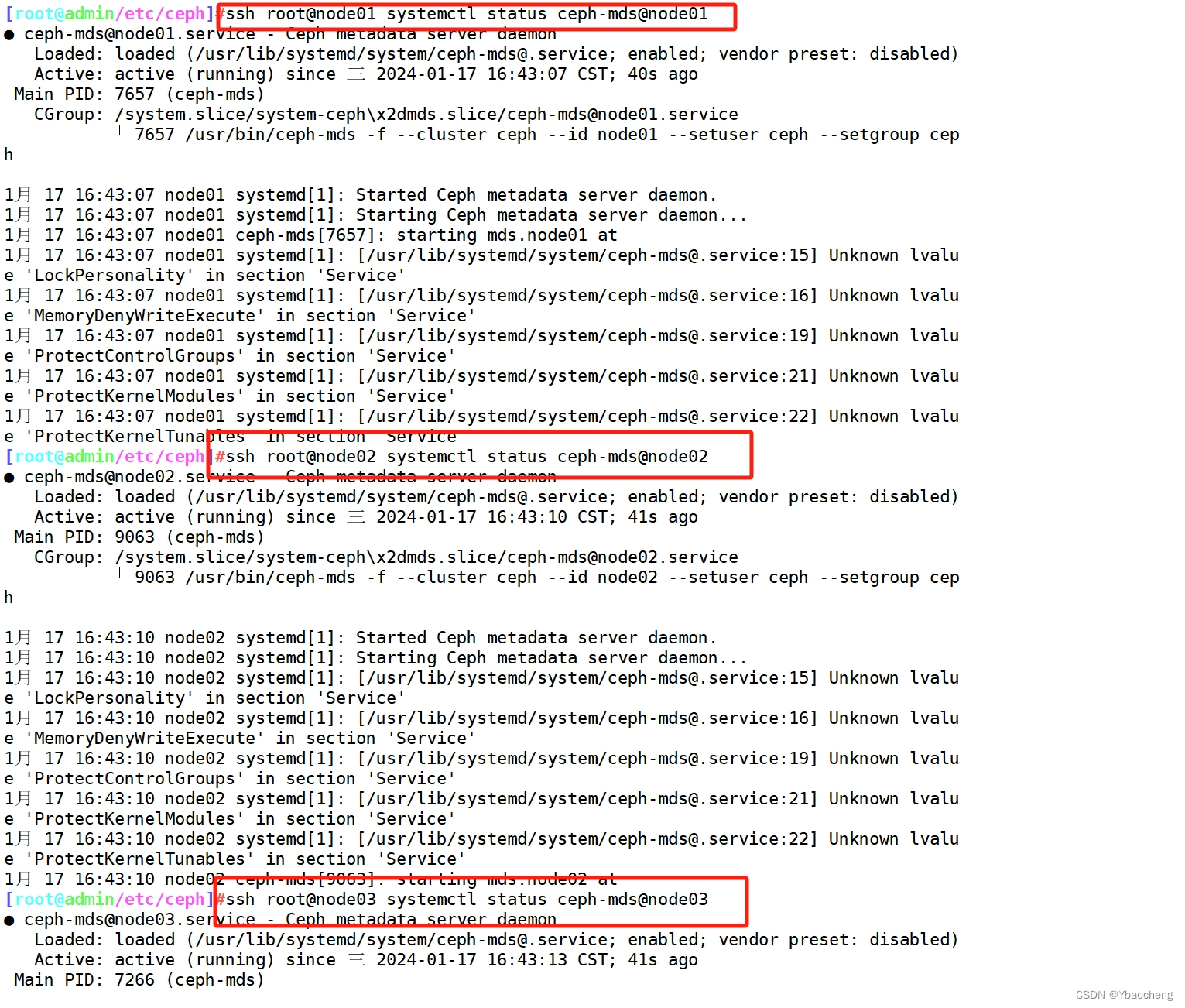
3.创建存储池,启用 ceph 文件系统
ceph 文件系统至少需要两个 rados 池,一个用于存储数据,一个用于存储元数据。此时数据池就类似于文件系统的共享目录。
ceph osd pool create cephfs_data 128 #创建数据Poolceph osd pool create cephfs_metadata 128 #创建元数据Pool#创建 cephfs,命令格式:ceph fs new <FS_NAME> <CEPHFS_METADATA_NAME> <CEPHFS_DATA_NAME>
ceph fs new mycephfs cephfs_metadata cephfs_data #启用ceph,元数据Pool在前,数据Pool在后ceph fs ls #查看cephfs
4.查看mds状态
ceph -s
mds: mycephfs:1 {0=node01=up:active} 2 up:standbyceph mds stat
mycephfs:1 {0=node01=up:active} 2 up:standby
5.创建用户
语法格式:ceph fs authorize <fs_name> client.<client_id> <path-in-cephfs> rw#账户为 client.zhangsan,用户 name 为 zhangsan,zhangsan 对ceph文件系统的 / 根目录(注意不是操作系统的根目录)有读写权限
ceph fs authorize mycephfs client.zhangsan / rw | tee /etc/ceph/zhangsan.keyring# 账户为 client.lisi,用户 name 为 lisi,lisi 对文件系统的 / 根目录只有读权限,对文件系统的根目录的子目录 /test 有读写权限
ceph fs authorize mycephfs client.lisi / r /test rw | tee /etc/ceph/lisi.keyring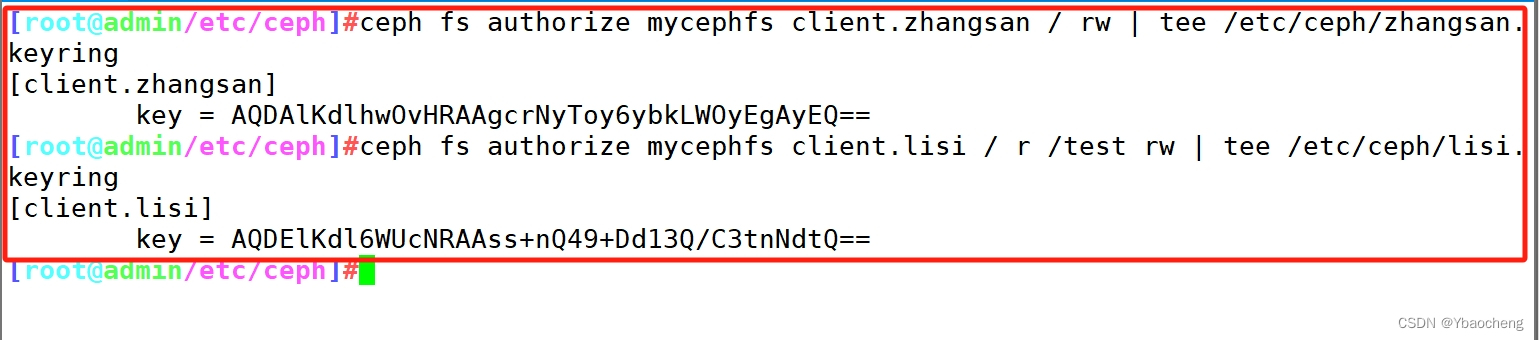
客户端操作(192.168.88.50)
1.在客户端创建工作目录
mkdir /etc/ceph2.在ceph的管理节点给客户端拷贝ceph的配置文件(192.168.88.22)
scp ceph.conf zhangsan.keyring lisi.keyring root@client:/etc/ceph


3.在客户端安装ceph软件包
cd /opt
wget https://download.ceph.com/rpm-nautilus/el7/noarch/ceph-release-1-1.el7.noarch.rpm --no-check-certificate
rpm -ivh ceph-release-1-1.el7.noarch.rpm
yum install -y ceph 4.在客户端制作秘钥文件
cd /etc/ceph
ceph-authtool -n client.zhangsan -p zhangsan.keyring > zhangsan.key #把 zhangsan 用户的秘钥导出到 zhangsan.key
ceph-authtool -n client.lisi -p lisi.keyring > lisi.key #把 lisi 用户的秘钥导出到 lisi.key
5.客户端挂载
在 ceph 的管理节点给客户端拷贝 ceph 的配置文件 ceph.conf 和管理员账号的秘钥环文件 ceph.client.admin.keyring
scp ceph.client.admin.keyring root@client:/etc/ceph在客户端安装 ceph-fuse
yum install -y ceph-fuse客户端挂载
cd /data/aa
ceph-fuse -m node01:6789,node02:6789,node03:6789 /data/aa [-o nonempty] #挂载时,如果挂载点不为空会挂载失败,指定 -o nonempty 可以忽略

3.创建Ceph块存储系统RBD接口
创建并初始化储存池
1.创建一个名为 rbd-demo 的专门用于 RBD 的存储池
ceph osd pool create rbd-demo 64 642.将存储池转换为 RBD 模式
ceph osd pool application enable rbd-demo rbd3、初始化存储池
rbd pool init -p rbd-demo # -p 等同于 --pool4、创建镜像
rbd create -p rbd-demo --image rbd-demo1.img --size 10G
可简写为:
rbd create rbd-demo/rbd-demo2.img --size 10G5、镜像管理
//查看存储池下存在哪些镜像
rbd ls -l -p rbd-demo//查看镜像的详细信息
rbd info -p rbd-demo --image rbd-demo1.img
rbd image 'rbd-demo1.img':size 10 GiB in 2560 objects #镜像的大小与被分割成的条带数order 22 (4 MiB objects) #条带的编号,有效范围是12到25,对应4K到32M,而22代表2的22次方,这样刚好是4Msnapshot_count: 0id: fadbd977a376 #镜像的ID标识block_name_prefix: rbd_data.fadbd977a376 #名称前缀format: 2 #使用的镜像格式,默认为2features: layering, exclusive-lock, object-map, fast-diff, deep-flatten #当前镜像的功能特性op_features: #可选的功能特性flags: 
修改,删除,还原镜像
#修改镜像大小
rbd resize -p rbd-demo --image rbd-demo1.img --size 20Grbd info -p rbd-demo --image rbd-demo1.img
#使用 resize 调整镜像大小,一般建议只增不减,如果是减少的话需要加选项 --allow-shrink
rbd resize -p rbd-demo --image rbd-demo1.img --size 5G --allow-shrink#删除镜像
#直接删除镜像
rbd rm -p rbd-demo --image rbd-demo1.img
rbd remove rbd-demo/rbd-demo1.img#推荐使用 trash 命令,这个命令删除是将镜像移动至回收站,如果想找回还可以恢复
rbd trash move rbd-demo/rbd-demo1.imgrbd ls -l -p rbd-demorbd trash list -p rbd-demo
fb4cbf503b72 rbd-demo1.img#还原镜像
rbd trash restore rbd-demo/fb4cbf503b72rbd ls -l -p rbd-demo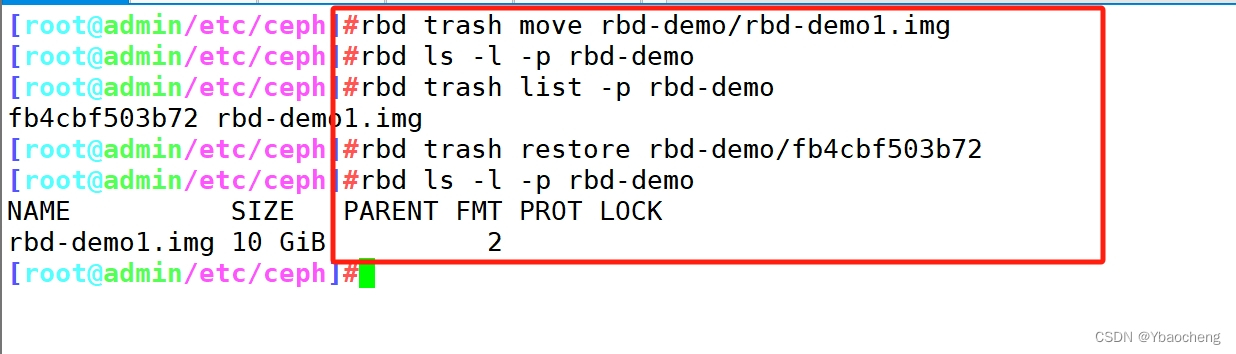
Linux客户端使用(192.168.88.50)
客户端使用RBD有两种方式
- 通过内核模块KRBD将镜像映射为系统本地块设备,通常设置文件一般为:/dev/rbd*
- 另一种是通过librbd接口,通常KVM虚拟机使用这种接口。
//在管理节点创建并授权一个用户可访问指定的 RBD 存储池
#示例,指定用户标识为client.osd-mount,对另对OSD有所有的权限,对Mon有只读的权限
ceph auth get-or-create client.osd-mount osd "allow * pool=rbd-demo" mon "allow r" > /etc/ceph/ceph.client.osd-mount.keyring//修改RBD镜像特性,CentOS7默认情况下只支持layering和striping特性,需要将其它的特性关闭
rbd feature disable rbd-demo/rbd-demo1.img object-map,fast-diff,deep-flatten//将用户的keyring文件和ceph.conf文件发送到客户端的/etc/ceph目录下
cd /etc/ceph
scp ceph.client.osd-mount.keyring ceph.conf root@client:/etc/ceph//linux客户端操作
#安装 ceph-common 软件包
yum install -y ceph-common#执行客户端映射
cd /etc/ceph
rbd map rbd-demo/rbd-demo1.img --keyring /etc/ceph/ceph.client.osd-mount.keyring --user osd-mount#查看映射
rbd showmapped
rbd device list#断开映射
rbd unmap rbd-demo/rbd-demo1.img#格式化并挂载
mkfs.xfs /dev/rbd0mkdir -p /data/bb
mount /dev/rbd0 /data/bb#在线扩容
在管理节点调整镜像的大小
rbd resize rbd-demo/rbd-demo1.img --size 30G在客户端刷新设备文件
xfs_growfs /dev/rbd0 #刷新xfs文件系统容量
resize2fs /dev/rbd0 #刷新ext4类型文件系统容量


快照管理
- 对 rbd 镜像进行快照,可以保留镜像的状态历史,另外还可以利用快照的分层技术,通过将快照克隆为新的镜像使用。
//在客户端写入文件
echo 1111 > /data/bb/11.txt
echo 2222 > /data/bb/22.txt
echo 3333 > /data/bb/33.txt//在管理节点对镜像创建快照
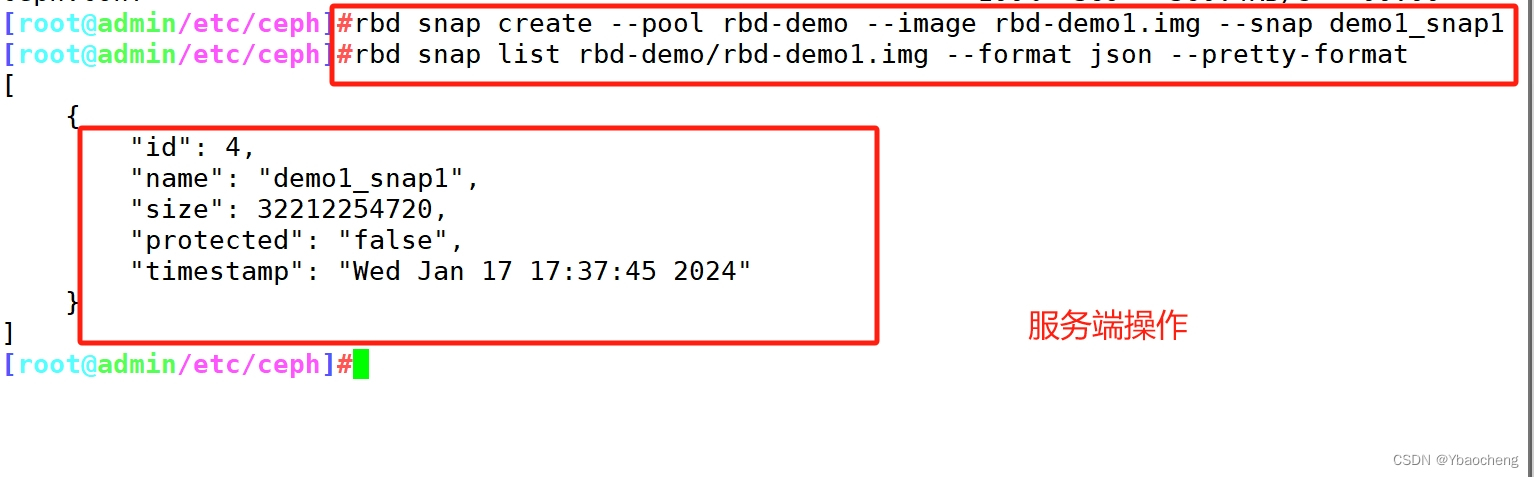
rbd snap create --pool rbd-demo --image rbd-demo1.img --snap demo1_snap1
可简写为:
rbd snap create rbd-demo/rbd-demo1.img@demo1_snap1//列出指定镜像所有快照
rbd snap list rbd-demo/rbd-demo1.img
#用json格式输出:
rbd snap list rbd-demo/rbd-demo1.img --format json --pretty-format//回滚镜像到指定
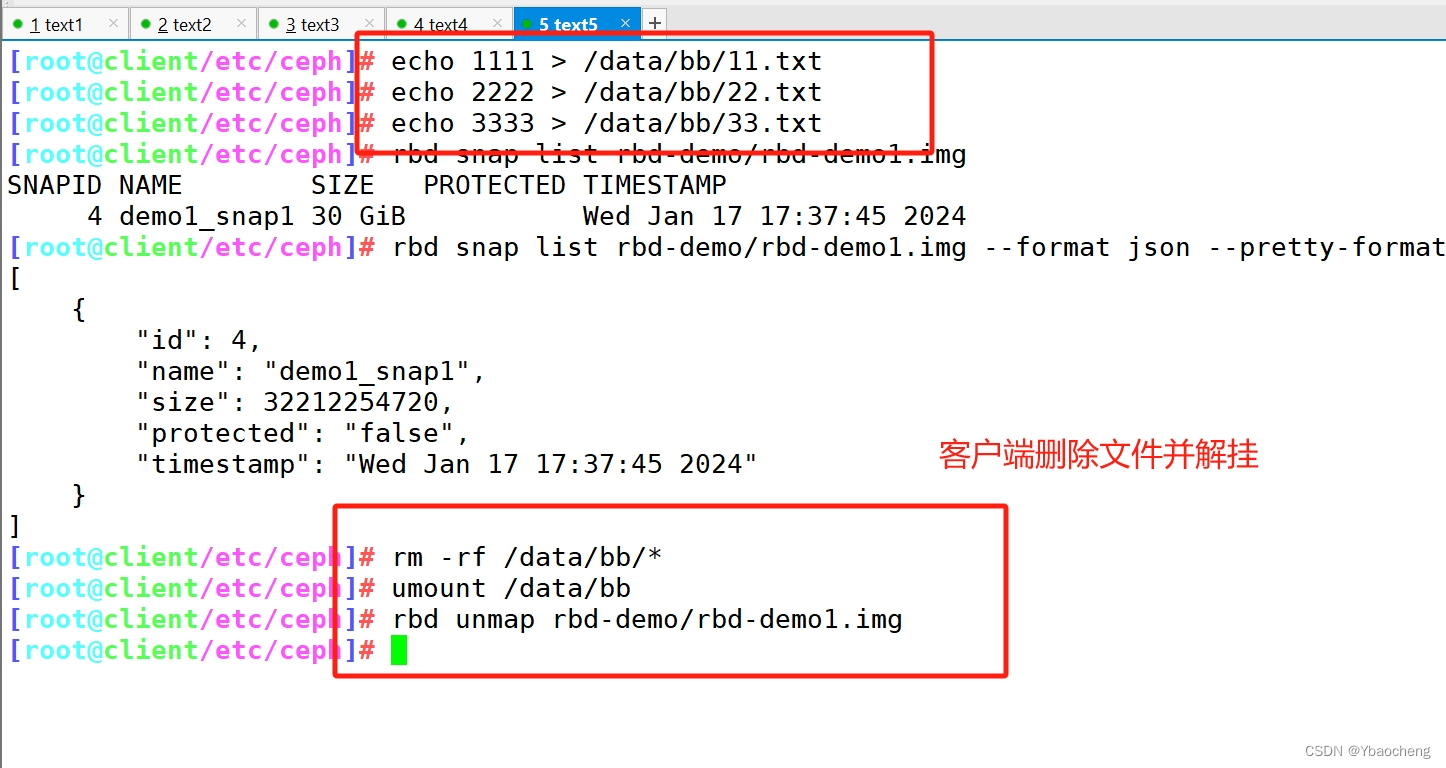
在回滚快照之前,需要将镜像取消镜像的映射,然后再回滚。#在客户端操作
rm -rf /data/bb/*
umount /data/bb
rbd unmap rbd-demo/rbd-demo1.img#在管理节点操作
rbd snap rollback rbd-demo/rbd-demo1.img@demo1_snap1#在客户端重新映射并挂载
rbd map rbd-demo/rbd-demo1.img --keyring /etc/ceph/ceph.client.osd-mount.keyring --user osd-mount
mount /dev/rbd0 /data/bb
ls /data/bb #发现数据还原回来了//限制镜像可创建快照数
rbd snap limit set rbd-demo/rbd-demo1.img --limit 3
#解除限制:
rbd snap limit clear rbd-demo/rbd-demo1.img//删除快照
#删除指定快照:
rbd snap rm rbd-demo/rbd-demo1.img@demo1_snap1
#删除所有快照:
rbd snap purge rbd-demo/rbd-demo1.img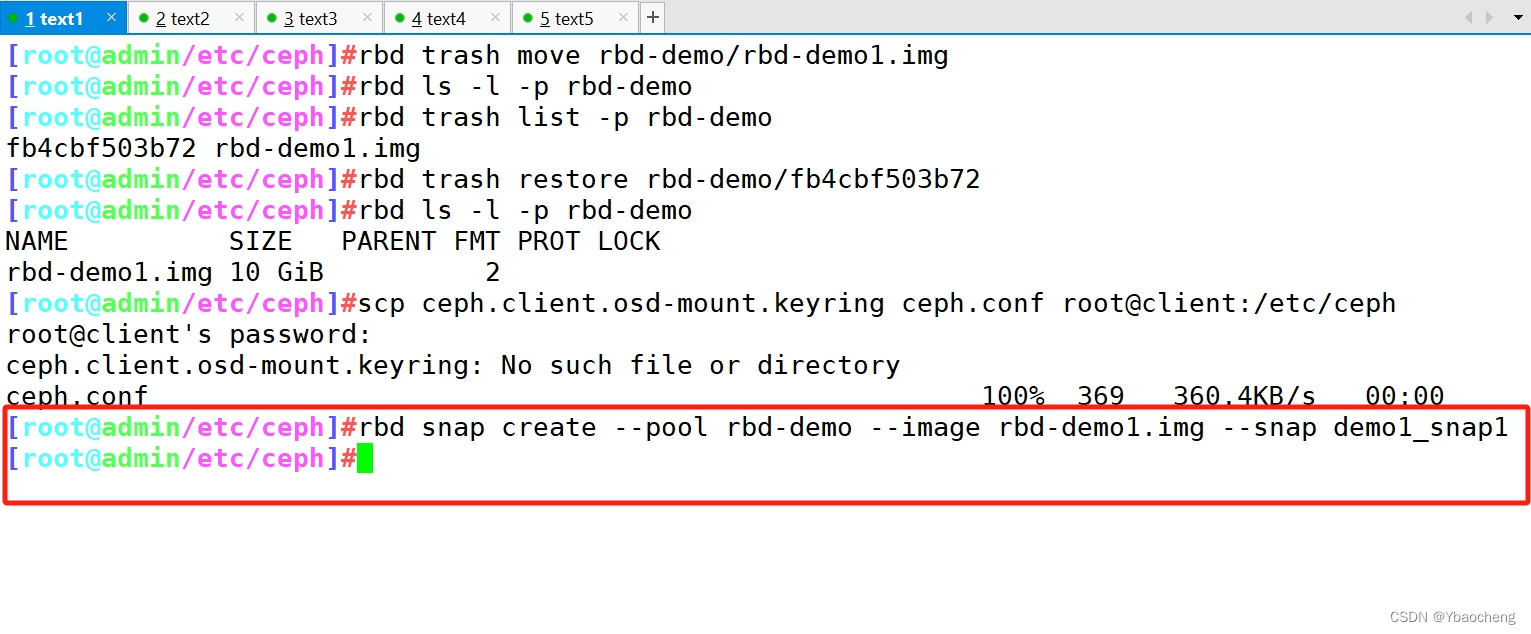


快照分层
- 快照分层支持用快照的克隆生成新镜像,这种镜像与直接创建的镜像几乎完全一样,支持镜像的所有操作。唯一不同的是克隆镜像引用了一个只读的上游快照,而且此快照必须要设置保护模式。
#快照克隆
1)将上游快照设置为保护模式:
rbd snap create rbd-demo/rbd-demo1.img@demo1_snap666
rbd snap protect rbd-demo/rbd-demo1.img@demo1_snap6662)克隆快照为新的镜像
rbd clone rbd-demo/rbd-demo1.img@demo1_snap666 --dest rbd-demo/rbd-demo666.img
rbd ls -p rbd-demo3)命令查看克隆完成后快照的子镜像
rbd children rbd-demo/rbd-demo1.img@demo1_snap666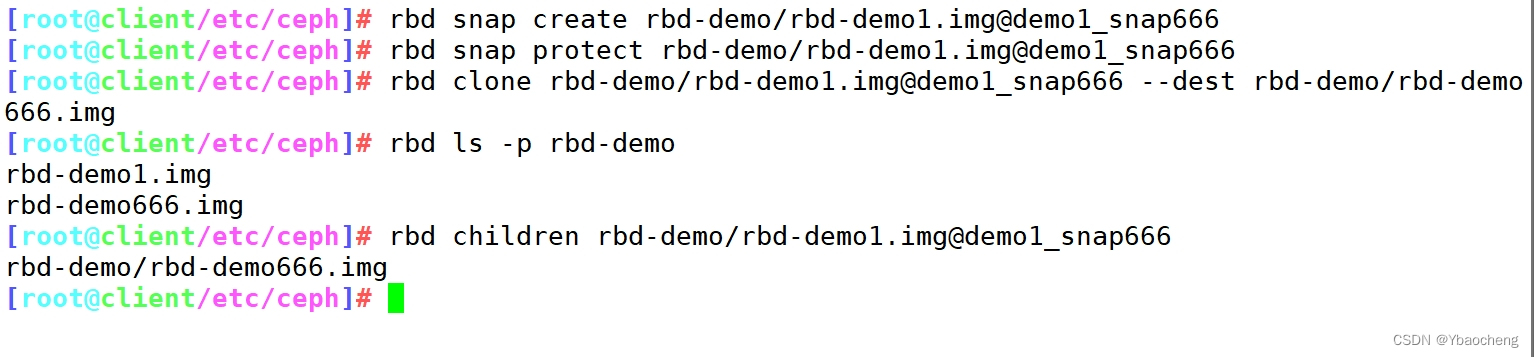
快照展平
- 通常情况下通过快照克隆而得到的镜像会保留对父快照的引用,这时候不可以删除该父快照,否则会有影响。
rbd snap rm rbd-demo/rbd-demo1.img@demo1_snap666
#报错 snapshot 'demo1_snap666' is protected from removal.如果要删除快照但想保留其子镜像,必须先展平其子镜像,展平的时间取决于镜像的大小
1) 展平子镜像
rbd flatten rbd-demo/rbd-demo666.img2)取消快照保护
rbd snap unprotect rbd-demo/rbd-demo1.img@demo1_snap6663)删除快照
rbd snap rm rbd-demo/rbd-demo1.img@demo1_snap666rbd ls -l -p rbd-demo #在删除掉快照后,查看子镜像依然存在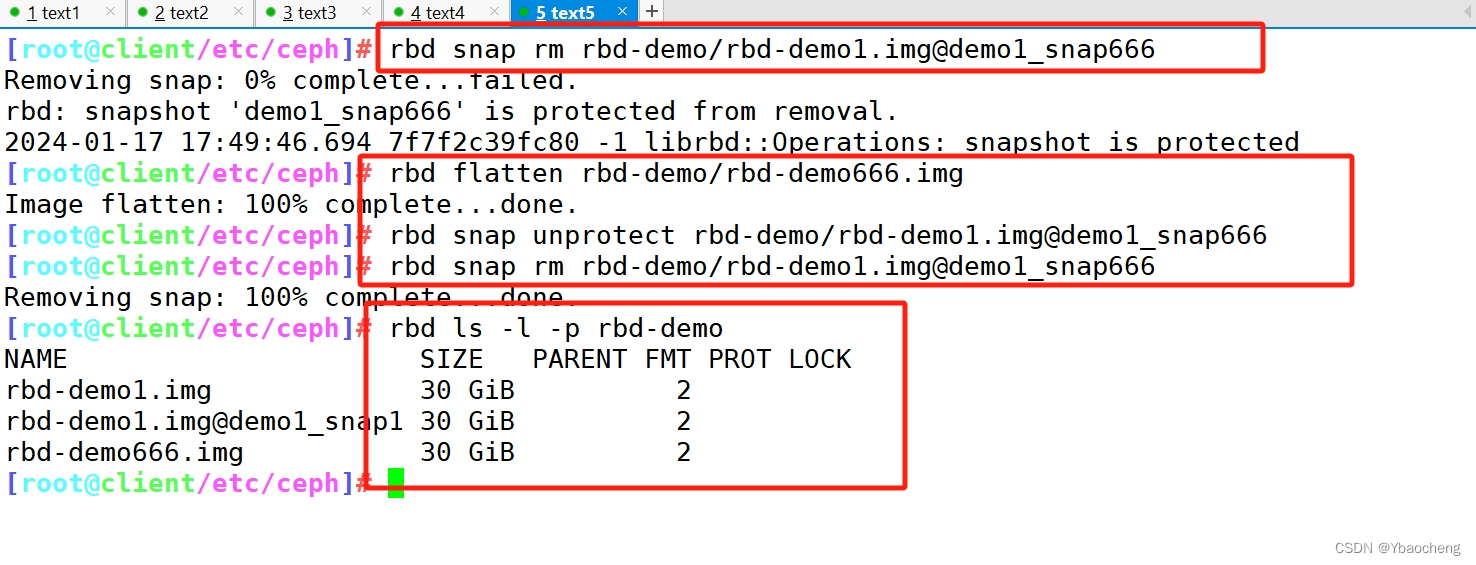
镜像的导出导入
//导出镜像
rbd export rbd-demo/rbd-demo1.img /opt/rbd-demo1.img//导入镜像
#卸载客户端挂载,并取消映射
umount /data/bb
rbd unmap rbd-demo/rbd-demo1.img#清除镜像下的所有快照,并删除镜像
rbd snap purge rbd-demo/rbd-demo1.img
rbd rm rbd-demo/rbd-demo1.imgrbd ls -l -p rbd-demo#导入镜像
rbd import /opt/rbd-demo1.img rbd-demo/rbd-demo1.imgrbd ls -l -p rbd-demo 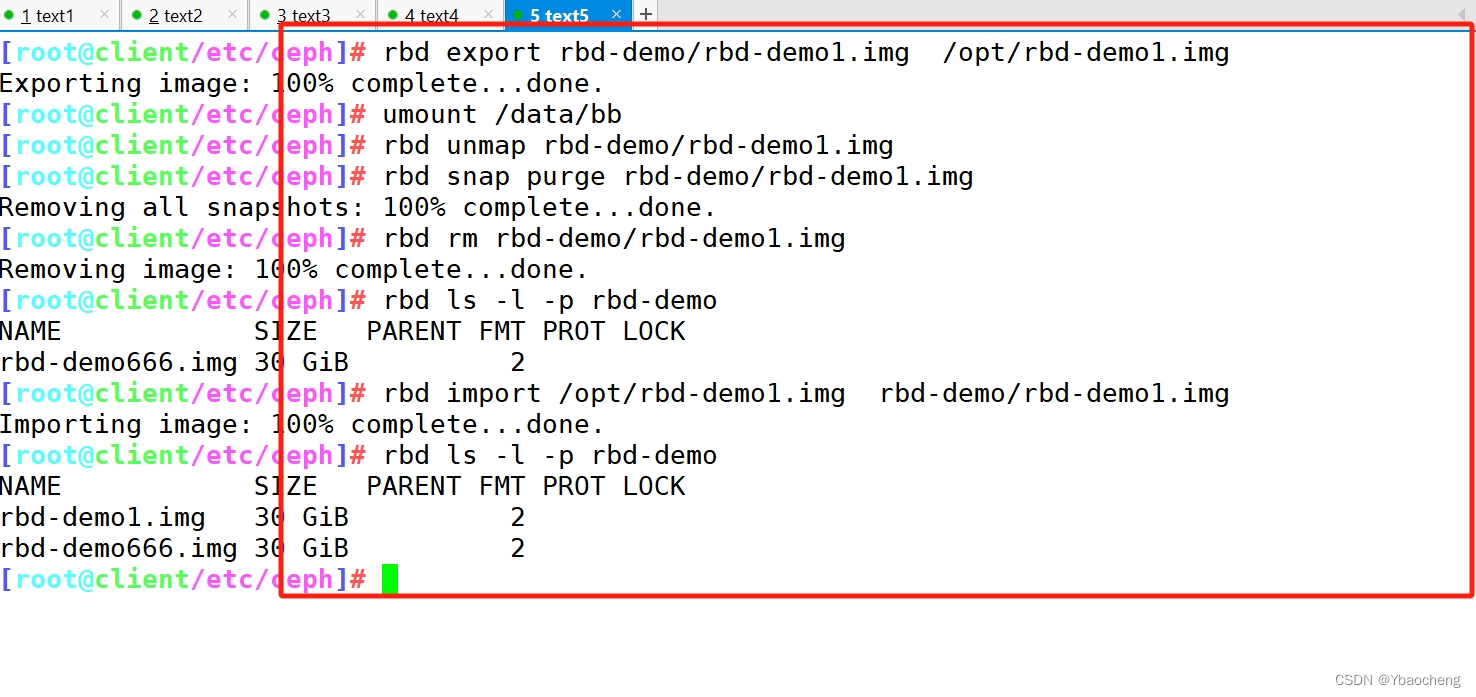
4.创建Ceph对象存储系统RGW接口
对象存储概念
- 对象存储(object storage)是非结构数据的存储方法,对象存储中每一条数据都作为单独的对象存储,拥有唯一的地址来识别数据对象,通常用于云计算环境中。
- 不同于其他数据存储方法,基于对象的存储不使用目录树。
虽然在设计与实现上有所区别,但大多数对象存储系统对外呈现的核心资源类型大同小异。从客户端的角度来看,分为以下几个逻辑单位:
Amazon S3
- 用户(User)
- 存储桶(Bucket)
- 对象(Object)
三者的关系是
- User将Object存储到系统上的Bucket
- 存储桶属于某个用户并可以容纳对象,一个存储桶用于存储多个对象
- 同一个用户可以拥有多个存储桶,不同用户允许使用相同名称的Bucket,因此User名称即可做为Bucket的名称空间
OpenStack Swift
- 提供了user、container和object分别对应于用户、存储桶和对象,不过它还额外为user提供了父级组件account,用于表示一个项目或用户组,因此一个account中可以包含一到多个user,它们可共享使用同一组container,并为container提供名称空间
RadosGW
- 提供了user、subuser、bucket和object,其中的user对应于S3的user,而subuser则对应于Swift的user,不过user和subuser都不支持为bucket提供名称空间,因此不同用户的存储桶不允许同名;不过,自jewel版本起,RadosGW引入了tenant(租户)用于为user和bucket提供名称空间,但他是个可选组件
- 从上可以看出大多数对象存储的核心资源类型大同小异,如 Amazon S3、OpenStack Swift 与 RadosGw。其中 S3 与 Swift 互不兼容,RadosGw 为了兼容 S3 与 Swift, Ceph 在 RadosGW 集群的基础上提供了 RGW(RadosGateway)数据抽象层和管理层,它可以原生兼容 S3 和 Swift 的 API。
- S3和Swift它们可基于http或https完成数据交换,由RadosGW内建的Civetweb提供服务,它还可以支持代理服务器包括nginx、haproxy等以代理的形式接收用户请求,再转发至RadosGW进程。
- RGW 的功能依赖于对象网关守护进程实现,负责向客户端提供 REST API 接口。出于冗余负载均衡的需求,一个 Ceph 集群上通常不止一个 RadosGW 守护进程。
创建RGW接口
管理节点创建一个 RGW 守护进程(生产环境下此进程一般需要高可用,后续介绍)
cd /etc/ceph
ceph-deploy rgw create node01ceph -s#创建成功后默认情况下会自动创建一系列用于 RGW 的存储池
ceph osd pool ls
rgw.root
default.rgw.control #控制器信息
default.rgw.meta #记录元数据
default.rgw.log #日志信息
default.rgw.buckets.index #为 rgw 的 bucket 信息,写入数据后生成
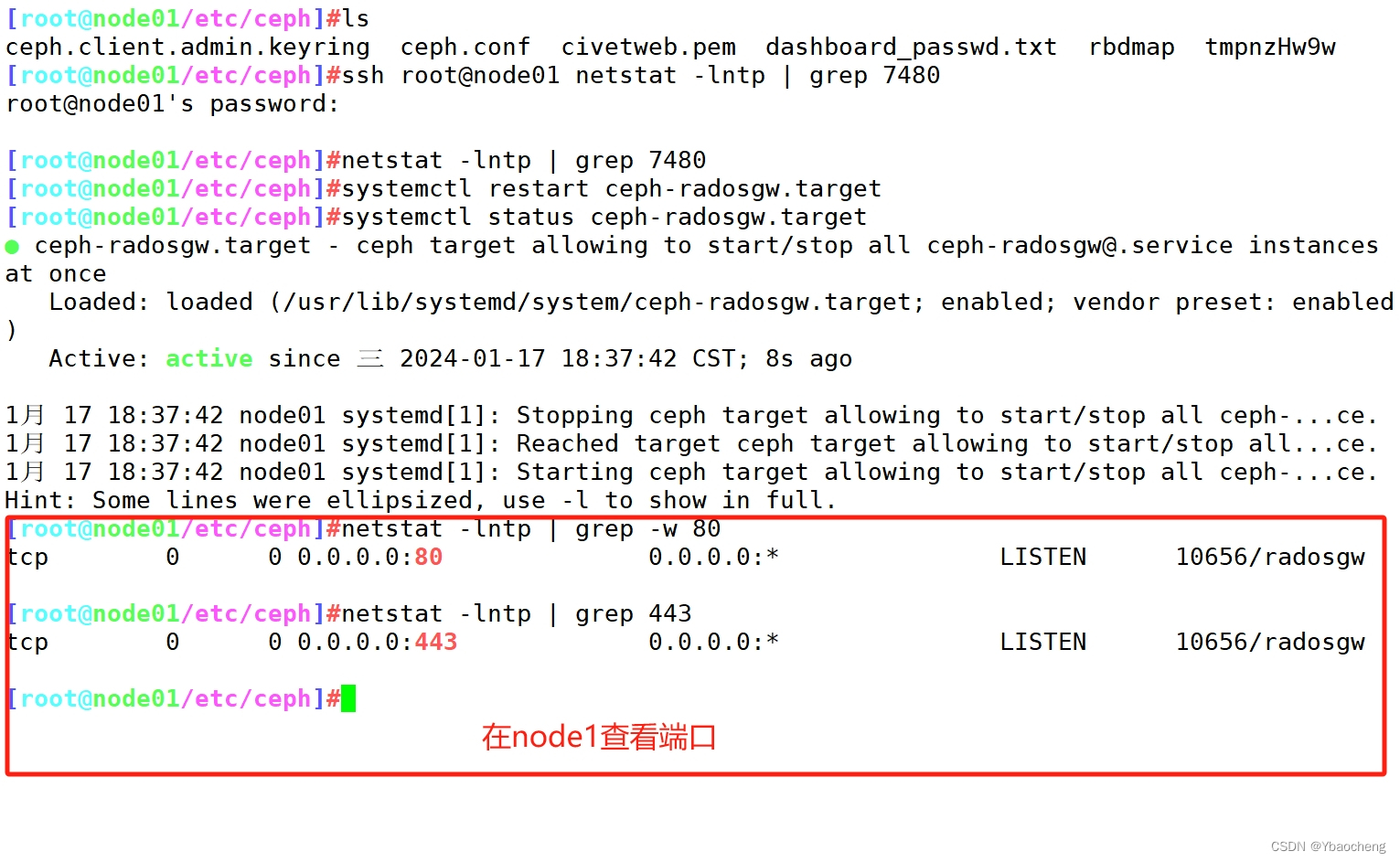
default.rgw.buckets.data #是实际存储的数据信息,写入数据后生成#默认情况下 RGW 监听 7480 号端口
ssh root@node01 netstat -lntp | grep 7480

开启http+https ,更改监听端口
- RadosGW 守护进程内部由 Civetweb 实现,通过对 Civetweb 的配置可以完成对 RadosGW 的基本管理。
#要在 Civetweb 上启用SSL,首先需要一个证书,在 rgw 节点生成证书
1)生成CA证书私钥:
openssl genrsa -out civetweb.key 20482)生成CA证书公钥:
openssl req -new -x509 -key civetweb.key -out civetweb.crt -days 3650 -subj "/CN=192.168.88.40"#3、将生成的证书合并为pem
cat civetweb.key civetweb.crt > /etc/ceph/civetweb.pem#更改监听端口
Civetweb 默认监听在 7480 端口并提供 http 协议,如果需要修改配置需要在管理节点编辑 ceph.conf 配置文件
cd /etc/cephvim ceph.conf
......
[client.rgw.node01]
rgw_host = node01
rgw_frontends = "civetweb port=80+443s ssl_certificate=/etc/ceph/civetweb.pem num_threads=500 request_timeout_ms=60000"------------------------------------------------------------
●rgw_host:对应的RadosGW名称或者IP地址
●rgw_frontends:这里配置监听的端口,是否使用https,以及一些常用配置:
•port:如果是https端口,需要在端口后面加一个s。
•ssl_certificate:指定证书的路径。
•num_threads:最大并发连接数,默认为50,根据需求调整,通常在生产集群环境中此值应该更大
•request_timeout_ms:发送与接收超时时长,以ms为单位,默认为30000
•access_log_file:访问日志路径,默认为空
•error_log_file:错误日志路径,默认为空
------------------------------------------------------------#修改完 ceph.conf 配置文件后需要重启对应的 RadosGW 服务,再推送配置文件
ceph-deploy --overwrite-conf config push node0{1..3}ssh root@node01 systemctl restart ceph-radosgw.target#在 rgw 节点上查看端口
netstat -lntp | grep -w 80
netstat -lntp | grep 443#在客户端访问验证
curl http://192.168.88.22:80
curl -k https://192.168.88.22:443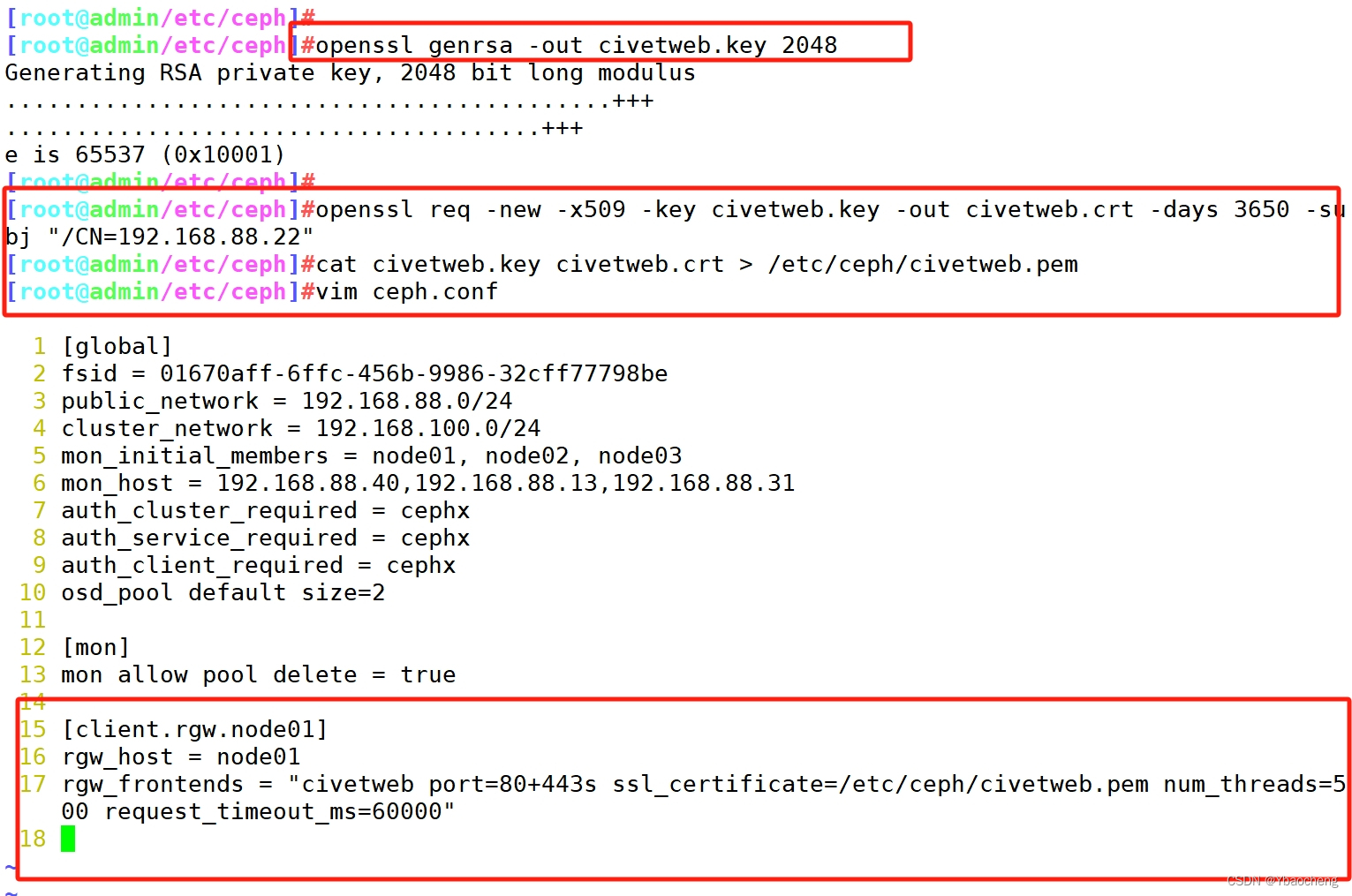

5.OSD故障模拟与恢复
模拟OSD故障
#如果 osd 守护进程正常运行,down 的 osd 会很快自恢复正常,所以需要先关闭守护进程
ssh root@node01 systemctl stop ceph-osd@0#down 掉 osd
ceph osd down 0ceph osd tree
将坏掉的osd踢出集群
//方法一:
#将 osd.0 移出集群,集群会开始自动同步数据
ceph osd out osd.0#将 osd.0 移除 crushmap
ceph osd crush remove osd.0#删除守护进程对应的账户信息
ceph auth rm osd.0
ceph auth list#删掉 osd.0
ceph osd rm osd.0
ceph osd stat
ceph -s//方法二:
ceph osd out osd.0
#使用综合步骤,删除配置文件中针对坏掉的 osd 的配置
ceph osd purge osd.0 --yes-i-really-mean-it


把原来坏掉的osd修复后重新加入集群
#在 osd 节点创建 osd,无需指定名,会按序号自动生成
cd /etc/ceph
ceph osd create#创建账户
ceph-authtool --create-keyring /etc/ceph/ceph.osd.0.keyring --gen-key -n osd.0 --cap mon 'allow profile osd' --cap mgr 'allow profile osd' --cap osd 'allow *'#导入新的账户秘钥
ceph auth import -i /etc/ceph/ceph.osd.0.keyring
ceph auth list#更新对应的 osd 文件夹中的密钥环文件
ceph auth get-or-create osd.0 -o /var/lib/ceph/osd/ceph-0/keyring#加入 crushmap
ceph osd crush add osd.0 1.000 host=node01 #1.000 代表权重#加入集群
ceph osd in osd.0
ceph osd tree#重启 osd 守护进程
systemctl restart ceph-osd@0
ceph osd tree #稍等片刻后 osd 状态为 up //如果重启失败
报错:
Job for ceph-osd@0.service failed because start of the service was attempted too often. See "systemctl status ceph-osd@0.service" and "journalctl -xe" for details.
To force a start use "systemctl reset-failed ceph-osd@0.service" followed by "systemctl start ceph-osd@0.service" again.#运行
systemctl reset-failed ceph-osd@0.service && systemctl restart ceph-osd@0.service