前言
2024年,愿新年胜旧年!作为AI世界的小白,今天先来从一些概念讲起,希望路过的朋友们多多指教!
正文
AI (人工智能)
提起AI, 大家可能会想起各种机器人,移动手机的“Siri”,"小爱同学", 是语音助手机器人,阿尔法围棋(AlphaGo)是 击败了围棋世界冠军的AI机器人,除此之外,自动驾驶,人脸识别,智能客服,智能家居,物流AGV小车,搜索引擎推送内容和广告,淘宝的以图搜图,美颜相机,ocr文本识别等都是AI的应用场景。

AI (Artificial Intelligence) , AI 即人工智能,让机器的行为看起来就像是人所表现出的智能行为一样,能听懂人类的语音,看懂人类的文字,知道人类的偏好,认识人类世界的生物(猫猫狗狗等),表现出学习、交流、感知、推理、使用工具等和人类一样的能力;再来看官网解释:机器人工智能是指使计算机系统或机器具备像人类一样的智能和能力,能够通过模拟和实现人类智能的各个方面,以改善生活、提高效率和解决复杂的问题。通常分为弱人工智能和强人工智能,弱人工智能专注于特定任务或领域,被用于执行特定的任务,如语音识别、图像分类、自然语言处理等;强人工智能就可以像人类一样具备自主学习、推理、解决问题和创造的能力。我们现在实现的人工智能技术主要是弱人工智能。
人工智能是计算机科学领域的一个分支,研究的领域包括机器学习、深度学习、自然语言处理、计算机视觉、推荐系统等,智能体现在机器可以从经验中学习,适应新的输入完成任务,人工智能的应用以我粗浅的认知认为是通过输入已有内容得到模型,这个模型就是超能力(类似外星人的大脑),可以去预测或判断未知的事情,我们的学习也是在总结规律,人工智能的这个找规律的过程和规律很高级!
机器学习(ML-Machine Learning)
机器学习是一种实现人工智能的方法,可以类比于人类学习知识的过程,我们人类想要获得知识,先对资料进行学习,对经验进行归纳总结得出规律,当出现未知问题时会用已知规律进行推测,机器学习的过程与人类学习的过程相似,也是预先对大量的学习资料进行学习来得到模型,这个根据数据得到模型的过程称作训练,当有了新的场景需要应用知识时,通过模型对新的场景进行判断,输出结果,从而实现对新场景进行预测的功能。
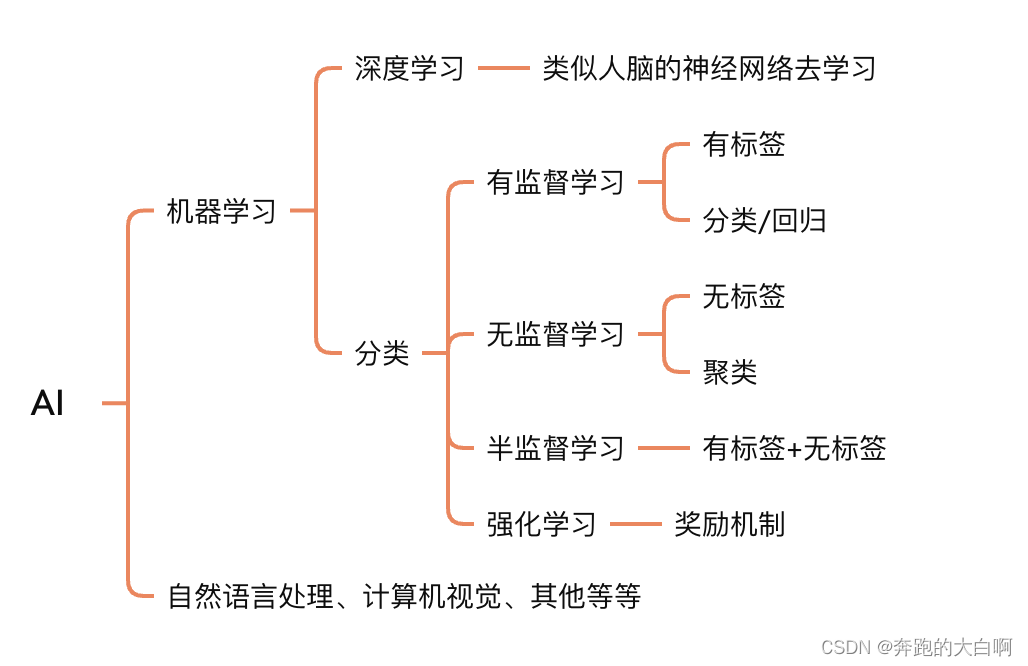
根据学习的方式可以把机器学习主要分为四类:有监督学习、无监督学习、半监督学习和强化学习。
有监督学习
机器会给出数据输入和答案,通过示例进行学习,会给出输入和输出数据对,输入为数据,输出被标记为正确答案,表现为通过带有标签的数据进行训练得到模型,输入一张猫的图片,我们人类知道图片 上是只猫,但是机器不知道,需要打标签告诉机器这是猫, 相当于给出机器预期的正确答案。
学习过程:输入一张橘猫的图片,打标签为猫,再输入一张布偶猫的图片,打标签为猫,再输入一张狸花猫的图片,打标签为猫,通过一些标签为猫的图片输入数据,机器可根据数据的相似性、差异点等特征进行学习(训练)得到一个模型,拥有了认识猫的能力,再输入一张野猫的图片,模型可以给出结论判断野猫图片是猫。
有监督学习主要用于处理回归和分类的任务。
分类:通过一组离散型数据,预测某一样本所属的类型,输出的值是定性的,比如判断性别、是否健康等,分类的结果只有正确或错误,使用正确率作为评价指标。
回归:通过一组连续型数据,预测某一样本可能的值,输出的值是定量的,比如通过过去一周的天气温度,预测明天的温度,是一个范围值,通过这个预测值和真实值之间的误差,进行回归性的分析,如果误差较小,认为是一个好的回归。
无监督学习
对比有监督学习,无监督学习只有输入的数据,没有答案(标签),让机器(算法)自己从数据中发现特征总结规律得到标签,用上面猫的一些图片作为输入,举例机器可能会总结到猫的特征:两只尖耳朵、四条腿、一条尾巴、有胡须、小鼻子等等,学习得到一个模型,再给这个模型输入一个野猫的图片,模型判断同样有两只尖耳朵、四条腿、一条尾巴、有胡须、小鼻子的特征,会给出一个结论,这张图片的内容和之前输入的图片相似度很高,可能属于一类。
无监督学习主要用于处理聚类的任务。
聚类:将一堆数据进行处理,根据数据之间的相似性进行分类。
半监督学习
通过少量的有标签数据和大量的无标签数据进行训练得到模型,减少数据人工标注标签的成本,同时利用无标签的数据尝试提高模型的性能和泛化能力(模型预测新样本值的能力)。
强化学习
为机器的学习过程建立一组奖惩机制,机器会在一些可能性行动下采取动作,每一个动作的执行会有相应的得分,机器通过反复实验得到不同的反馈,最终得到一个总得分,目标是获得最大化奖励。就比如做一件好事会加10分,做一件坏事会扣10分,在机器反复尝试中发现只有不断的做好事才能获得最高分,由此得出一个模型,这个模型的能力是会做好事。
机器学习的过程

准备数据
这时的数据也叫做数据集,可以是带标签的,也可以是不带标签的,用来给算法找特征作进一步判断的 ,数据集一般根据用途分为训练集、验证集和测试集。
训练模型
根据数据集做有限次的试错和优化来构建模型的过程,简单举例: 给定一个输入x和一个输出y, 目标是构建一种函数关系使y = f(x) 通过不断尝试调整x和y之间的参数,使数据集中的x们尽可能贴近输出的y们,模型训练的过程很复杂,训练的输出是模型,也就是x和y之间的映射关系。
验证模型
训练得到初始模型,验证模型使用验证数据集用来评价模型的性能,同时根据模型的性能进行反复模型参数调整和再次验证,直到模型在验证数据集上表现良好。
测试模型
使用测试数据集检测验证后的模型的表现
使用模型
使用训练好的模型在新数据上做预测 ,个人觉得这个过程叫做推理(inference)
调优模型
使用更多数据,不同的特征或调整过的参数来提升模型的性能表现
补充:模型评估:评价模型性能的方法,用于训练、验证、测试的阶段,评估指标有准确率,召回率,精确率等,通常是分类模型的评估指标。
深度学习(DL-Deep Learning)
深度学习是机器学习的一种方法, 目的建立、模拟人脑进行分析学习的神经网络,模仿人脑的机制来解释数据,属于无监督学习。深度学习是为了让机器自己获得学习能力,能够解决某些场景下复杂的难题。
自然语言处理(NLP-Natural Language Processing)
自然语言处理是人工智能的一个研究领域,是一种机器学习技术,使计算机能够解读、处理和理解人类语言。自然语言是指人类之间的交流语言,ChatGPT(Chat Generative Pre-trained Transformer) 就是NLP的一个应用,它是一个预先训练好的NLP模型,可以进行文本生成,比如回答问题,与人对话等。
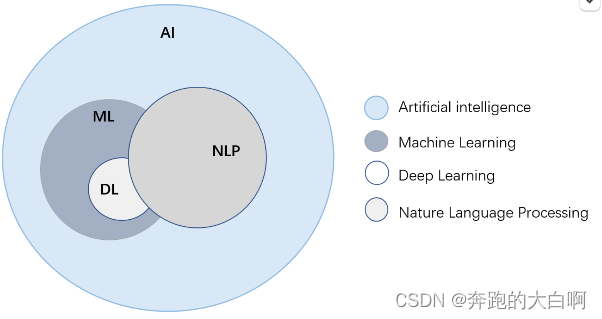
人工智能、机器学习、深度学习、自然语言处理的关系
小结
小白同学持续学习中,如有表达不合适或有误的地方,还请路过的伙伴们及时指出~




![[学习笔记]刘知远团队大模型技术与交叉应用L3-Transformer_and_PLMs](https://img-blog.csdnimg.cn/direct/4caa5dfc10df45ff8266bf7f26f2ff43.png)