2 Chromium的硬件加速机制
2.1 GraphicsLayer的支持
GraphicsLayer对象是对一个渲染后端存储中某一层的抽象,同众多其他WebKit所定义的抽象类一样,在WebKit移植中,它还需要具体的实现类来支持该类所要提供的功能。为了完成这一功能,Chromium提供了更为复杂的设施类,这一节主要介绍从GraphicsLayer类到合成器这一过程中所涉及的众多内部结构。
图(Chromium对GraphicsLayer的支持)描述了从WebCore的同移植无关的GraphicsLayer,到WebKit的Chromium移植,再训Chromium浏览器所设计的Chromium合成器的LayerImpl类这一过程。读者可以看到,中间有好几层,原因在于抽象和合成机制的复杂性,以及性能等众多方面的考虑,下面从上到下介绍这些主要类。
图(Chromium对GraphicsLayer的支持)
- GraphicsLayerChromium: GraphicsLayer的子类,实现了GraphicsLayer需要的一个功能,并且加入了Chromium的所需信息。
- WebLayer: WebKit的Chromium移植的抽象接口类,它被GraphicsLayerChromium等调用,主要目的是将Chromium的实际后端存储类抽象出来,以便WebCore使用它们。
- WebLayerlmpl: WebLayer类的实现类,具体作用是将合成器的层能力暴露出来,跟Layer类一一对应。
- Layer: 合成器的层表示类,是Chromium合成器的接口类,用于表示合成器的合成层,它会形成一棵合成树。
- Layerlmpl: 同Layer对象一一对应,是实际的实现类,包含后端存储,可能跟Layer树在不同的线程,具体在后面介绍。
由上面的介绍可以看出,这个过程基本上就是各种类的映射,从GraphicsLayer类到LayerImpl类,目的是将WebKit的合成层映射到合成器中的合成层,合成器最终合成这些层。不过在新的Blink中,图中WebKit的Chromium移植部分的类被移除掉了,原因是Blink不需要多层次的接口,因为Blink仅被Chromium所用。合成过程在合成器小节中介绍。
2.2 框架
在Chromium中,有个比较特别的设计,就是所有使用GPU硬件加速(也就是调用OpenGL编程接口)的操作都是由一个进程(称为GPU进程)负责来完成的,这其中包括使用GPU硬件来进行绘图和合成。Chromium是多进程架构,每个网页的Renderer进程都是将之前介绍的3D绘图和合成操作通过IPC传递给GPU进程,由它来统一调度并执行。在Chrome的Android版本中,GPU进程并不存在,Chrome是将GPU的所有工作放在Browser进程中的一个线程来完成,这得益于结构设计的灵活性。但是本质上,GPU进程和GPU线程并无太大区别。
图(Chromium的GPU进程)描述了Chromium的多进程架构中GPU进程同其他进程之间的联系,事实上每个Renderer进程都依赖GPU进程来渲染网页,当然Browser进程也会同GPU进程进行通信,其作用是创建该进程并提供网页渲染过程最后绘制的目标存储。例如,在Windows和Linux上它是一个窗口对应的“Surface”,在Android系统中则是SurfaceView对应的后端(实际上也是一个GPU的缓冲区)。

图(Chromium的GPU进程)
GPU进程也被使用在其他用途中,例如后面介绍到的Pepper插件,该机制由Chromium提供,并且提供了绘制3D图形能力的接口给Pepper插件使用,这里同样也需要GPU进程的统一管理。
在介绍完GPU进程之后,下面主要描述WebKit渲染引擎是如何使用GPU来渲染网页的。图8-11描述了具体的调用栈。根据前面的介绍可以知道,WebKit定义了两种类型的图形上下文,它们都可以使用GPU来加速,加速机制最后都是调用OpenGL/OpenGLES库。不过,在Chromium中,这一过程比较复杂。
3D和2D图形上下文在Chromium中分别对应Chromium的3D图形上下文实现和Skia画布(canvas),它们在调用(GL操作)之后会被转换成IPC消息传给GPU进程,该进程中的解释器对这些消息进行解释后,调用GL函数指针表中的函数,这些函数指针是从GL库中获取的,至于为什么是这样,原因是这样更灵活。对于Windows来说,3D图形库是D3D而不是OpenGL接口,Chromium的做法是通过开源项目ANGLE,使用D3D来封装成OpenGL方式的接口,这样,Chromium就可以从ANGLE提供的接口读入函数地址,如 图(Chromium的3D图形上下文和2D图形上下文的硬件加速调用栈)所示。

图(Chromium的3D图形上下文和2D图形上下文的硬件加速调用栈)
下面以Chromium的3D图形上下文为例,详细说明它的调用经过哪些Chromium具体类最后调用操作系统的3D图形库, 图(Chromium的GPU加速设施类)描述了中间使用到的各种主要类。

图(Chromium的GPU加速设施类)
同前面的调用栈一样,图中也是分成Renderer进程和GPU进程,首先来了解Renderer进程的主要类。
- WebGraphicsContext3DCommandBufferlmpl: 继承自WebKit::WebGraphics-Context3D类,它实际上是WebKit的Chromium移植中的PlatformGraphics-Context3D类。这个类主要转接自WebKit的调用到Chromium的具体实现,同时将这些3D图形操作调用转换成GL命令(Command,后面介绍),主要包括一个RenderGLContext对象。
- RendererGLContext: Renderer进程对GLContext的一个封装,包括所有用于跟GPU进程交互的类,有一个GLES2Implementation对象、一个CommandBufferProxy对象和一个GPUChannelHost对象。
- GLES2lmplementation: 该类模拟OpenGL ES2的编程接口,但是不直接调用GLES2的实现,而是将这些调用转换成特定格式的命令存入CommandBuffer中。
- CommandBufferHelper: 该类是一个辅助类,包括一个CommandBuffer代理类和一个共享内存。
- CommandBufferProxy: CommandBuffer的一个代理类,实现CommandBuffer的接口,用于和CommandBufferStub之间的通信。
- GPUChannelHost: 用于传递GL命令的IPC消息辅助类。
接下来自然是GPU进程中各个主要类的依次介绍。
- GPUChannel: 用于接收GL命令并发送回复的辅助类。
- GPUCommandBufferStub: CommandBuffer的桩,接收来自于CommandBufferProxy的消息,将请求交给CommandBufferService处理。
- CommandBufferService: CommandBuffer的具体实现类,但其实它并不具体解析和执行这些命令,而是当有新的命令到达时,调用注册的回调函数来处理。
- GPUScheduler: 负责调度执行Commandbuffer的命令,它会检查该Commandbuffer是否应该被执行,并适时将命令交给CommandParser来处理。
- CommandParser: 仅检查CommandBuffer中的命令头部,其余部分则交给具体的命令解码器来解释,所以它同GL命令的理解是独立的。
- GLES2Decoderlmpl: 针对GLES命令的命令解释器,它解析每条具体的命令并执行调用GL相应的函数。
- GL lmplementation Wrapper: 一组GL相关的函数指针,通过设定的3D图形库来读取库中相应函数的地址。
- GL Libraries: 具体的函数库,在Chromium中,它可以设置为OpenGL、OpenGL ES、Mesa GL、Mock、ANGLE等,得益于设计上的灵活性,不同的3D图形库都可以被Chromium所使用而不需要修改任何代码。
通过上面每个模块类的具体介绍,相信读者大概已经知道Chromium跨进程的硬件加速机制的工作过程了。那么,GPU进程和Renderer进程是如何同步这些命令的呢? (2) 答案是,GPU进程处理一些命令后,会向Renderer进程报告自己当前的状态,Renderer进程通过检查状态信息和自己的期望结果来确定是否满足自己的条件。GPU进程最终绘制的结果不再像软件渲染那样通过共享内存传递给Browser进程,而是直接将页面的内容绘制在浏览器的标签窗口内。
2.3 命令缓冲区
命令缓冲区(Command Buffer)主要用于GPU进程(以后称为GPU服务端)和GPU的调用者进程(且称GPU客户端进程,如Renderer进程、Pepper插件进程)传递GL操作命令。从接口上来讲,这一设计只提供一些基本的接口来管理缓冲区,它并没有对缓冲区的具体方式和命令的类型进行任何限制,不过目前Chromium只有GLES一种实现方式。
现有的实现是基于共享内存的方式来完成的,因而命令是基于GLES编码成特
定的格式存储在共享内存中 (3) 。共享内存方式采用了环形缓冲区(RingBuffer)的方式来管理,这表示内存可以循环使用,旧的命令会被新的命令所覆盖。
一条命令可以被分成两个部分:命令头和命令体。命令头是命令的原数据信息,包含两个部分:一个是命令的长度,一个是命令的标识。命令体包含该命令所需要的其他信息,例如命令的立即操作数。命令是可以固定长度的,也可以是变化的,一切取决于该命令。具体的结构如 图(命令结构)所示。

图(命令结构)
上面说到,命令缓冲区本身没有定义具体的命令格式,所以GLES实现可以根据自己的需要来定义。GLES实现所使用的命令也可以大致分成两类:第一类是基本命令,主要用来操作桶(Bucket)、跳转、调用和返回等指令;第二类是跟GLES2的函数相关的命令,主要用来操作GLES2的函数。
命令本身是保存在共享内存中的,而且每条命令的长度不能超过(1<<21-1)。另外共享内存的大小也是固定的,如果命令太长,可存储的命令就很少。那么问题就出来了,如何解决需要传输较大数据的命令呢?对于这样类型的数据,Chromium可以对它们使用独立的共享内存来实现,典型的命令例如TexImage2D(传输大量数据到GPU内存)。但是,当共享内存大小超过系统的限制时,这种方式就行不通了。Chromium提供了一种新的机制来解决这个问题。
这个机制就是桶(Bucket)机制。解决问题的原理是:通过共享内存机制来分块传输,而后把分块的数据保存在本地的桶内,从而避免了申请大块的共享内存。前面提到的公共命令就是用来处理桶相关的数据。当数据传输完成之后,对该数据进行操作的命令就可以执行了。桶机制也可用来传输字符串类型的变长数据:接收端首先获取桶内字符串的长度,然后通过共享内存的方式来分块传输,最后合并在接收端的桶内。
2.4 Chromium合成器(Chromium Compositor)
2.4.1 架构
合成器的作用就是将多个合成层合成并输出一个最终的结果,所以它的输入是多个待合成的合成层,每个层都有一些属性(如3D变形等)。它的输出就是一个后端存储,例如一个GPU的纹理缓冲区。
Chromium合成器是一个独立并且复杂的模块,顾名思义,它的作用是合成网页划分后的合成层,但是,这里的合成器同网页没有必然的绑定关系,它既可以合成网页,也可合成用户界面,或者多个标签页。其实,按照笔者的理解,如果你的项目中需要合成器,可以尝试移植该合成器为自己所用,当然,该合成器有一些依赖关系需要解除,难度也很大,这些都是题外话。
在架构设计上,合成器采用的是表示和实现分离的原则,也就是前面介绍合成器Layer层(同GraphicsLayer类一一对应)同具体合成器所要合成的操作分离的原则,图8-15描述了这一思想。WebKit对合成层的各种设置,最后都使用Layer树来表示,每个Layer节点包含3D变形、剪裁等属性,但是Chromium将这些属性应用到后端存储并合成这一过程并不是在Layer树中进行,而是将这些功能委托LayerImpl树来完成,两者之间通过代理来同步,代理的作用是协调和同步两者之间的这些操作。Layer树所有的信息都会拷贝到LayerImpl树中。

图(合成器表示和实现分离架构)
图(合成器表示和实现分离架构)中描述的Layer树工作在主线程,实际指的是渲染引擎工作的线程,不一定是Renderer进程的主线程。但是LayerImpl树都是工作在“实现部分”的线程,实现部分的线程可以是主线程也可以是单独的一个线程(Chromium Thread),两者在Chromium中目前都被使用。实现部分作为单独一个线程是在Renderer进程中用来合成网页的,通常也称为合成器(Compositor)线程,后者也称为线程化合成(Threaded Compositing)。在Chrome的Android版本,合成还有些复杂,网页的合成器工作在Renderer进程,同时还有另外的合成器工作在Browser进程,用于将网页结果和浏览器用户界面合成起来。
2.4.2 基础设施
为了支持Chromium合成器的线程化合成和线程内合成等众多机制,Chromium引入了一些类来支持它们,下面结合合成器的架构来逐步分析它们。首先来看合成器的主要组成,大致可以分成以下几个部分。
- 事件处理部分。主要是接收WebKit或者其他的用户事件,例如网页滚动、放大缩小等事件,这些事件会请求合成器重新绘制每一个合成层,然后合成器再合成这些层的绘制结果。
- 合成层的表示和实现。主要定义各种类型的合成层,包括它们的位置、滚动位置、颜色等属性。
- 合成层组成两种类型的树,以及它们之间的同步等机制。
- 合成调度器(Scheduler)主要调度来自用户的请求,它包括一个状态用于调度当前队列中需要执行的请求,目的当然是协调合成层的绘制和合成、树的同步等操作。
- 合成器的输出结果。在Chromium合成器中,结果可以是一个GPU Surface或者是一个CPU的存储空间(听起来很吃惊,对吧)。同时,当然也包括GL操作类可以让合成器使用GL来合成这些合成层。
- 各种后端存储等资源。合成器需要能够创建各种类型的GL缓冲区、纹理等,因为每个合成层都需要这些资源。
- 支持动画和3D变形这些功能所需要的基础设施。
这些主要部分构成了Chromium合成器,后面逐一介绍它们。首先看两种树,以及它们之间是如何同步的。图(合成器的线程内和线程化合成使用到的主要设施) 描述了它们使用到的主要类。

图(合成器的线程内和线程化合成使用到的主要设施)
先看Layer树所在的线程。每一层都是一个Layer对象,而Layer树则由LayerTreeHost类来维护。LayerTreeHost类的作用一是根据调用者的需求创建和更新Layer树,另外就是将这些变动通过代理拷贝给实际的实现者,也就是LayerTreeImpl,这可能需要跨线程,拷贝的作用就是使得合成器能够不依赖于WebKit渲染所在的线程而独立工作。
代理起的作用很重要。在合成器中,代理是一个抽象类,定义了Layer树和LayerImpl树之间完成合成所需要的转接工作。它有两个子类,分别是SingleThreadProxy类和ThreadProxy类,它们分别用于线程内合成和线程化合成两种情况。以ThreadProxy为例(因为它更复杂),代理的一些接口由主线程调用,也就是由LayerTreeHost调用,用来复制信息到实现类LayerImpl。另外的就是使用调度器来调度合成的过程。
再看实现部分。实现的主要逻辑由LayerTreeHostImpl来负责,如调度、复制信息到LayerImpl树等,它包含至少一个LayerImpl树对象。在线程化的绘图模式中,它可能至少包含有三个树。而LayerTreeImpl就维护一个LayerImpl树,包括为树中的层创建后端存储、为整个树创建输出结果、合成该树各个节点的实际过程等。
类Layer和LayerImpl是两种基类,它们各自都有多个子类,它们和它们的子类基本上是一一对应的,这里以Layer类和它的子类为例说明合成器中的合成层。图(合成器中的Layer类和它的子类们)描述了Layer类和它的子类们。

图(合成器中的Layer类和它的子类们)
每个类都有各自的应用场景,例如VideoLayer类是表示视频播放的,SolidColorLayer类可以表示单一颜色的背景层,而TextureLayer类则表示该合成层直接接收一个纹理,该纹理已经由其他部分处理,不需要合成器触发任何绘图操作。在Chromium中,一些插件是能够使用硬件绘图并输出纹理结果的。
图(合成器中的Layer类和它的子类们)中,有两个类被标记为灰色,其一是Layer类,它是所有类的基类;第二个是TiledLayer,这个类是一个中间类,它被ContentLayer类和ImageLayer类继承,它的含义是一个层的后端存储被分割成瓦片状(Tiles),由多个小后端存储共同存储而成。图8-18描述了一个合成层的后端存储被分割成多个大小相同的瓦片状的小存储空间,每个瓦片可以理解为OpenGL中的一个纹理对象,合成层的结果被分开存储在这些瓦片中。

图(合成层的瓦片化)
什么样的合成层会被瓦片化呢?TiledLayer的两个子类告诉了我们,其一是ContentLayer,它表示合成层使用Skia画布将内容绘制到结果中,对应到网页中就是常见的HTML元素,例如DOM树中的html、div等所在的层,在Chromium中,它们使用Skia图形库的SkCanvas类来绘图。其二是图片元素,如果一个合成层仅仅包含一个图片,那么该图片也会使用该技术。
为什么使用瓦片化的后端存储呢?自然是因为一些限制或者好处所以才采用该技术,概括起来有以下几点:其一,DOM树中的html元素所在的层可能会比较大,因为网页的高度很大,如果只是使用一个后端存储的话,那么需要一个很大的纹理对象,但是实际的GPU硬件可能只支持非常有限的纹理大小;其二,在一个比较大的合成层中,可能只是其中一部分发生变化,根据之前的介绍,需要重新绘制整个层,这样必然产生额外的开销,使用瓦片化的后端存储,就只需要重绘一些存在更新的瓦片;其三,当层发生滚动的时候,一些瓦片可能不再需要,然后WebKit需要一些新的瓦片来绘制新的区域,这些大小相同的后端存储很容易重复利用,可以做到非常简洁漂亮。
在线程内合成模式下,Chromium是不需要调度器的,仅仅在线程化的合成模式下Chromium才会使用,所以调度器是在合成器线程中,因而不能访问主线程中的资源。调度器需要考虑整个合成器系统的状态,它需要考虑何时更新树、何时绘图、何时运行动画、何时上传内容到纹理对象等。
合成器中的调度器和状态机如图(调度器类和状态机类)所示。Scheduler类就是调度器类,任何合成的相关操作都需要设置到该调度器中,例如ThreadProxy类会调用SetNeedsCommit函数来触发Commit操作,该操作的含义是将Layer树的属性等改变同步到LayerImpl树。任务的发起者只是告诉调度器希望执行该任务,通过接口设置标记,Scheduler类本身不直接处理这些状态设置,而是将它转给SchedulerStateMachine类处理,该状态机设置相应的状态位。一个任务一般不会被立即执行,而是等到调度器调度到该任务的时候才会执行。

图(调度器类和状态机类)
当调用Scheduler类的ProcessScheduleActions时,调度器会通过状态机获取当前需要执行的任务,状态机根据之前设置的各种信息来决定下面的任务是什么。一旦确定了任务,调度器通过SchedulerClient来执行实际的任务,ThreadProxy类就是一个SchedulerClient子类,它会桥接到Layer树、LayerImpl树或者其他设施。
调度器Scheduler的基本原则是一切请求都是设置状态机中的状态,这些请求什么时候被执行由调度器来决定。调度任务的主要函数是ProcessScheduleActions,它的工作方式如图(调度器调度任务)所示。原理不是很复杂,它首先调用状态机的NextAction函数,由状态机来计算和决定下一个要执行的任务。前面描述过,在此之前,任务的发起者是设置这些状态,它表示之后希望执行一些任务,而不是立即要求执行。状态机计算出下一个任务,调度器获得任务的类型并执行该任务,然后再接着计算下一个任务,如此循环,直到空闲为止。

图(调度器调度任务)
下面以同步Layer树到LayerImpl树(commit)为例说明任务的调度过程以及调度器在这一过程中的作用,图8-21描述了“commit”任务的调度过程。

图(“commit”任务的调度过程)
首先,当Layer树有变动的时候,它需要调用ThreadProxy::SetNeedsCommit,这些任务是在渲染线程中的,随后它会提交一个请求到“Compositor”线程。
其次,当该“Compositor”线程处理到该请求的时候,它会通过调度器的SetNeedsCommit函数设置状态机的状态。
再次,调度器的SetNeedsCommit会调用ProcessScheduleActions函数,它检查后面需要执行的任务。
然后,如果没有其他任务或者时间合适的话,状态机决定下面立刻执行该任务,它调用ThreadProxy的ScheduledActionCommit函数,该函数实际执行“commit”任务需要的具体流程。
最后在ScheduledActionCommit函数中,它会调用LayerTreeHostImpl和LayerTreeHost中的相应函数来完成同步两个树的工作。同步结束后,它需要通知渲染线程,因为事实上这一过程需要阻止该线程。
2.4.3 合成过程
在了解完合成器的各个主要部分之后,下面来看看合成工作是如何完成的。根据之前描述的过程,合成工作主要有四个步骤,这些步骤都是由调度器调度,需要各个类参与来共同完成。
- 创建输出结果的目标对象“Surface”,也就是合成结果的存储空间。
- 开始一个新的帧(Begin Frame),包括计算滚动和缩放大小、动画计算、重新计算网页的布局、绘制每个合成层等。
- 将Layer树中包含的这些变动同步到LayerImpl树中,也就是图 图(“commit”任务的调度过程)所说的“commit”任务的调度过程。
- 合成LayerImpl树中的各个层并交换前后帧缓冲区,完成一帧的绘制和显示动作。
在这四个步骤中,步骤1只是在最开始的时候调用,而且只是一次性的动作。当后面网页出现动画或者JavaScript代码修改CSS样式和DOM等情况的时候,一般会执行后面三个步骤,当然也可能只需要步骤4。
图(合成器的工作过程)是合成器工作的典型过程,结合上面描述的四个步骤,笔者特地将它们作了一一对应,图中已经做下了标记,下面依次来分析这四个步骤。

图(合成器的工作过程)
在步骤一中,“Compositor”线程首先创建合成器需要的输出结果的后端存储,在调度器执行该任务时,该线程会将任务交给主线程来完成。主线程会创建后端存储并把它传回给“Compositor”线程。
在步骤二中,“Compositor”线程告诉主线程需要开始绘制新的一帧,同样是通过线程间通信来传递任务。主线程接收到该任务后,需要做的事情非常多,读者可以看到从4.1到4.6步骤之间做的这些操作,实际上还省略了一些次要操作。这里面主要是执行动画操作、重新计算布局,以及绘制需要更新的合成层等。在这之后主线程会等待第三个步骤,当第三个步骤完成后,它通知主线程的LayerHost等类,这是因为步骤三需要阻塞主线程,需要同步Layer树。
在步骤三中,基本的过程如图(“commit”任务的调度过程)所示,这里不再赘述。
在步骤四中,主要就是合成工作了。经过第三步之后,“compositor”线程实际上已经不再需要主线程的参与就能够完成合成工作了,这时该线程有了合成这些层需要的一切资源。图中调用过程5.1.1到5.1.6这些子步骤就是合成各个层并交换前后缓冲区,读者会看到这些并不需要主线程的参与。这样就能够解释渲染线程在做其他事情的时候,网页滚动等操作并不会受到渲染线程的影响,因为这时候合成器的工作线程仍然能够正常进行,合成器线程继续合成当前的各个合成层生成网页结果,虽然此时可能有些内容没有更新,但用户根本感觉不到网页被阻塞等问题,浏览网页的用户体验更好。
Chromium的最新设计为了合成网页(网页中也可以包含iframe等内嵌网页)和浏览器的用户界面(典型的是在Android系统上,但是在桌面系统上,用户界面通常不需要同网页内容合成)可能需要多个合成器。每个网页可能需要一个合成器,网页中的iframe也需要一个合成器,整个网页同浏览器的合成也需要一个合成器,这些合成器构成一个层次化的合成器结构,如图(层次化合成器)所示。图中的根合成器是浏览器最高层的合成器,该合成器负责网页和浏览器用户界面的合成,它有一个子女就是“合成器2”,根合成器会将“合成器2”的结果同用户界面合成起来。“合成器2”就是网页的合成器,而它也包含一个合成iframe内容的“合成器3”子合成器。这里,“合成器2”和“合成器3”按理是在Renderer进程中进行的,因为它们是网页相关的合成,而根合成器是在Browser进程中的,这样会增加内存带宽的使用。目前Chromium的设计使用“mailbox”机制将Renderer进程中的合成器结果同步到Browser进程,根合成器可以使用这些结果。
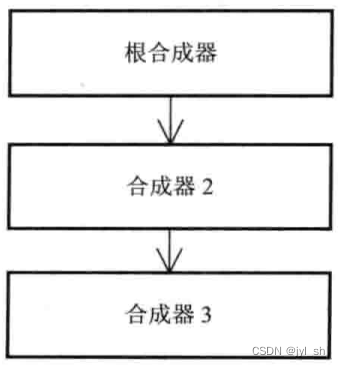
图(层次化合成器)
2.5 实践:减少重绘
网页加载后,每当重新绘制新的一帧的时候,一般需要三个阶段,也就是前面说的计算布局、绘图和合成三个阶段。如果想减少每一帧的时间,提高性能 (4) ,当然要着重减少这三个阶段的时间。
这三个阶段中,计算布局和绘图比较费时间,而合成需要的时间相对要少一些。而且,当布局的变化越多,WebKit通常需要越多的绘图时间。例如当使用JavaScript的计时器来控制动画的时候,WebKit可能需要修改布局和比较多的绘图操作,这会明显增加WebKit绘制每帧的时间,是否有什么办法来避免这一情况呢?办法有很多,这里介绍WebKit两种典型的方法,第一种是使用合适的网页分层技术以减少需要重新计算的布局和绘图;第二种是使用CSS 3D变形和动画技术。
首先是网页的分层问题。假设读者需要设计一款游戏,例如闯关之类的HTML5网页游戏。游戏中的画面可能有背景,背景之前是各种各样的障碍物,人物就是要闯过各种各样的关卡。假设Web开发者希望使用canvas 2D技术来实现它,并且假设开发者使用一个canvas元素,当人物在前面运动的时候,根据canvas 2D的特性,WebKit需要将该元素内部的内容都重新绘制一遍以显示人物的一个工作,这样的做法导致WebKit开销太大,因为WebKit需要重新绘制整个canvas元素,然后再使用合成器。一个比较好的做法是,使用多个canvas元素,将它们按照前后顺序叠放在一起。前面canvas元素的背景为透明,这样后面的元素能够显示出来。每一个canvas元素都是一个合成层,每一帧的变化都只是一个或者部分合成层,而不是所有的canvas元素。
以前面的游戏继续说明,Web开发者可以使用一个canvas元素来绘制游戏的背景,用另外第二个canvas元素来绘制障碍物,用第三个canvas元素来绘制炸弹、金钱等,使用第四个canvas元素来绘制人物。这样,当人物不动的时候,如果炸弹和金钱在变化,WebKit仅需要重新绘制第三个元素。当人物走动的时候,WebKit只需要重新绘制第四个元素。与此同时,第一个和第二个元素则仅在很少的情况下会被WebKit重新绘制,这样能够有效地减少开销,图(使用多个canvas元素分层示意图)描述了这一概念。

图(使用多个canvas元素分层示意图)
当然这只是一个基本的思路,也就是说,Web开发者实际上可以将这一思想应用在很多其他的场景。详细的情况请读者参阅层次化canvas渲染优化技术:http://www.ibm.com/developerworks/library/wa-canvashtml5layering/index.html,该文章很好地描述了这一思想。现有的一些设计同样可以将这些思想应用在同一个canvas元素内部以获得较好的性能,这里面可以挖掘的地方还很多。
其次是使用CSS 3D变形技术,它能够让浏览器仅仅使用合成器来合成所有的层就可以达到动画效果,而不是通过重新设置其他CSS属性并触发计算布局、重新绘制图形、重新合成所有层这一非常复杂的过程。实际上,开发者如果需要网页中有一些动画或者特殊效果,可以给这些元素设置3D变形属性,然后通过CSS3引入的动画能力,网页就可以达到很多匪夷所思的效果。更重要的是,WebKit不需要大量的布局计算,不需要重新绘制元素,只需要修改合成时候的属性即可。当合成器需要合成的时候,每个合成层都可以设置自己的3D变形属性,这些属性仅仅改变合成层的变换参数,而不需要布局计算和绘图操作,可以极大地节省时间。图(famo.us网站展示的效果和性能分析结果)显示的是famo.us网站展示的效果和使用Chrome的开发者工具收集的性能分析结果数据,根据前面的描述来解释一下这一结果。
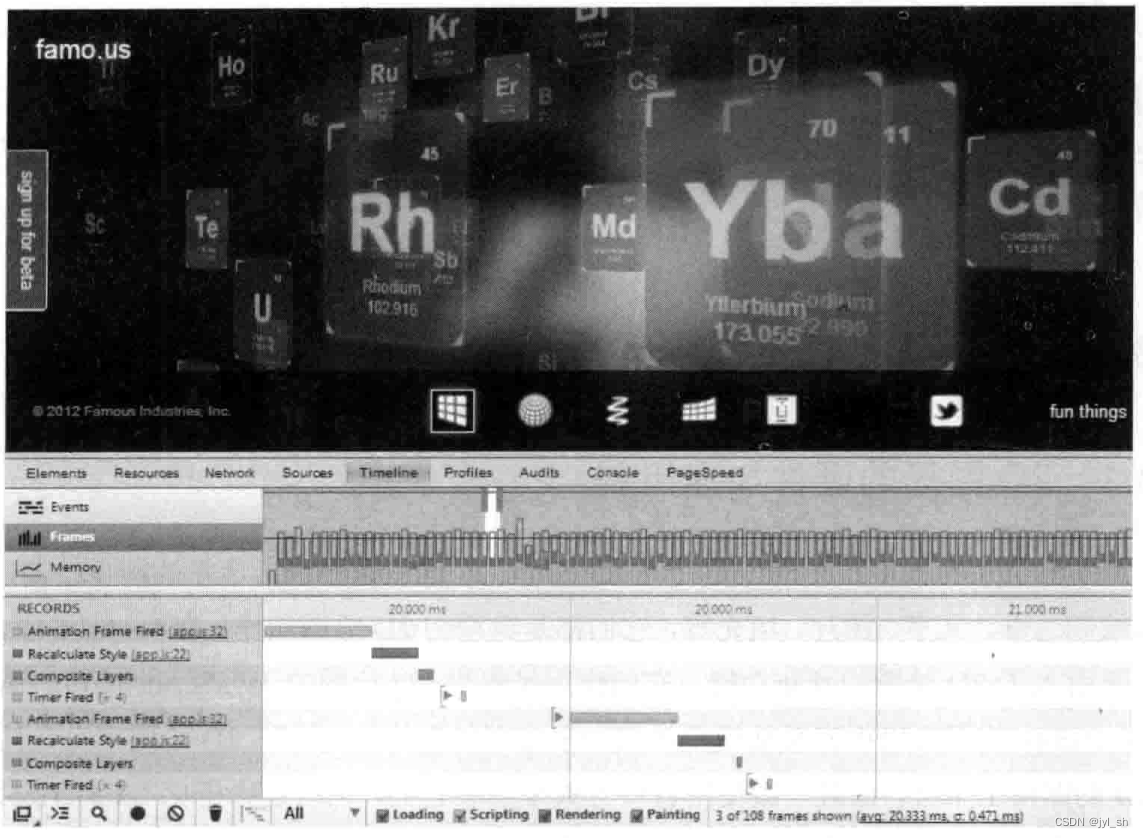
图(famo.us网站展示的效果和性能分析结果)
该网站实际上显示的是多个“div”元素,每个元素就是元素周期表中的一个化学元素,每个元素都设置了3D的效果,它们有各式各样的动画效果,非常吸引人。更奇特的是,该网页能够在手机和平板等性能较弱的设备上达到很好的性能,为什么呢?
在这里,笔者通过Chrome的开发者工具为读者解开谜团。该工具能为开发者分析出Chrome浏览器为计算每一帧所花费的时间和这些时间的分布情况。在计算每一帧的时候JavaScript代码首先设置元素的3D属性,然后设置样式信息,但是Chrome浏览器不需要重新布局,也不需要重新绘图,只是在随后使用合成功能,读者发现合成阶段所花费的时间非常少,几乎可以忽略不计,这使得计算图中每一帧都相对比较省时间,因为每一帧的生成没有了费时的布局计算和绘图操作。
这一网页设计给大家带来的启示是,尽量在每一帧中减少布局和绘图的时间,它们会极大地降低生成每一帧的性能,当然很多情况下布局计算和绘图操作是不可避免的,所以开发者需要合理地设计网页,希望这里的一些例子能够给大家带去更多的思考。