Day2 - 1.requests第一血_哔哩哔哩_bilibili
requests作用:模拟浏览器发请求
requests流程:指定url -> 发起请求 -> 获取响应数据 -> 持续化存储
爬取搜狗首页的页面数据
import requests# 指定url
url = 'https://sogou.com'
# 发起请求
response = requests.get(url)
# 获取响应数据,text返回字符串形式的响应数据
page_txt = response.text
# 持久化存储
with open('./sogpu.html', 'w', encoding='utf-8') as fp:fp.write(page_txt)简易网页采集器
输入关键词后,爬取搜索结果的页面信息

https://www.sogou.com/web?query=%E8%B5%B5%E6%B5%A9%E7%84%B6&_asf=www.sogou.com&_ast=&w=01019900&p=40040100&ie=utf8&from=index-nologin&s_from=index&sut=2106&sst0=1705812059807&lkt=0%2C0%2C0&sugsuv=1705811188521571&sugtime=1705812059807
把url中多余的参数去掉
https://www.sogou.com/web?query=%E8%B5%B5%E6%B5%A9%E7%84%B6
这里的中文变成了乱码,无需处理,当然想手动换成中文也行
为了使关键词可变,需要处理url携带的参数:封装到字典中
再把url中的参数删干净https://www.sogou.com/web
import requestsurl = 'https://www.sogou.com/web'
keyword = input()
param = {'query': keyword
}
response = requests.get(url, params=param)
page_txt = response.text
filename = keyword+'.html'
with open(filename, 'w', encoding='utf-8') as fp:fp.write(page_txt)UA伪装
此次案例中需要介绍一种反扒机制——UA检测
UA:User-Agent:请求载体的身份标识
UA检测:门户网站的服务器会检测对应请求的载体身份标识,如果检测到载体身份标识为某一款浏览器,则认为是正常的请求;否则认为是不正常的请求
UA伪装:将对应的User-Agent封装到headers字典中
f12或者检查页面,找到网络部分,先清楚网络日志再刷新页面,找到需要的请求对应的UA
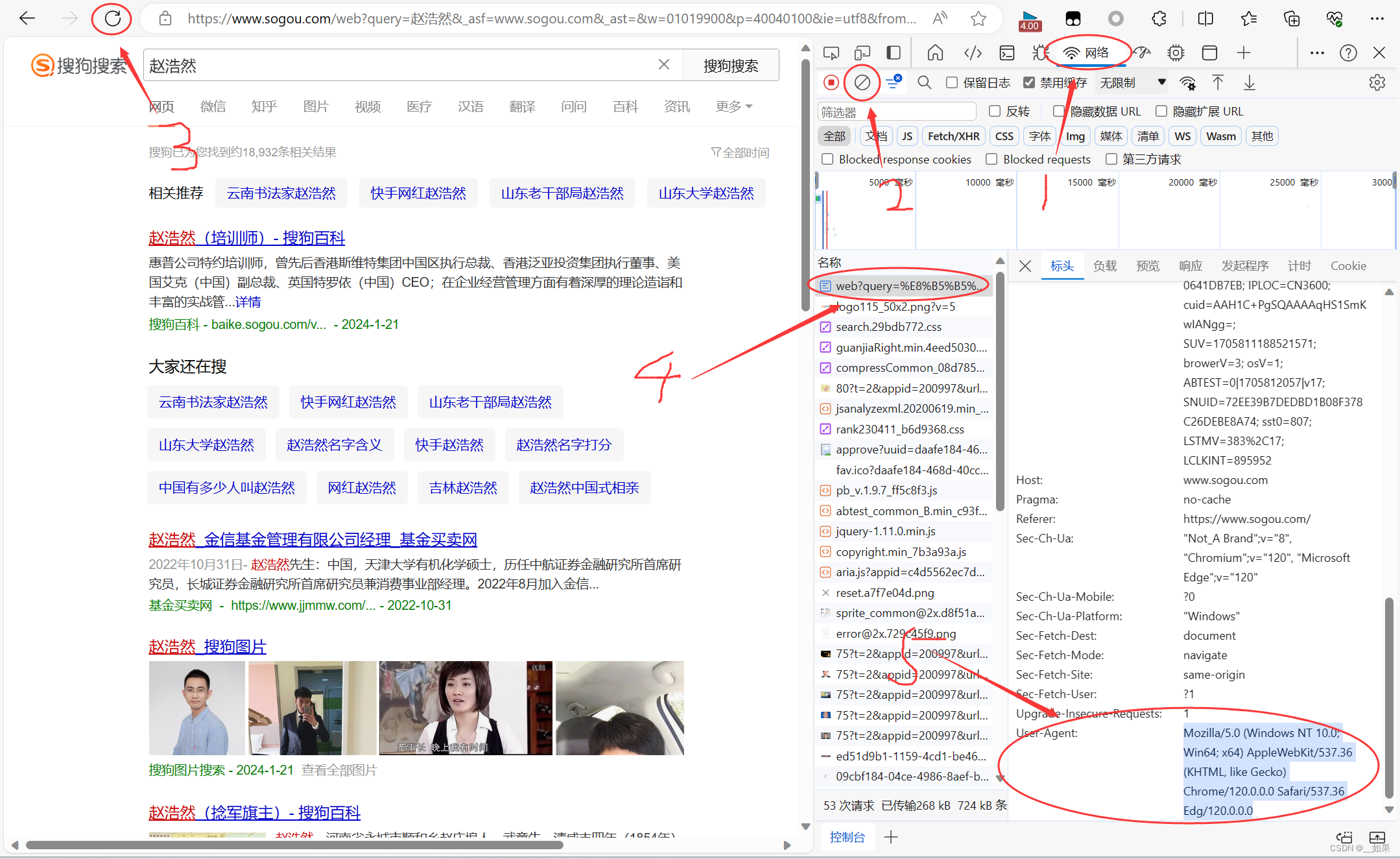
然后把这个headers字典放入get请求中
import requestsheaders = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/120.0.0.0 Safari/537.36 Edg/120.0.0.0'
}
url = 'https://www.sogou.com/web'
keyword = input()
param = {'query': keyword
}
response = requests.get(url, params=param, headers=headers)
page_txt = response.text
filename = keyword+'.html'
with open(filename, 'w', encoding='utf-8') as fp:fp.write(page_txt)破解百度翻译
爬取百度翻译中,对应单词翻译的结果
由于我们不是想要爬取整个页面,而是爬取页面中的部分信息,经常需要用到数据解析
但不使用数据解析也能获取局部信息,这次我们就不使用
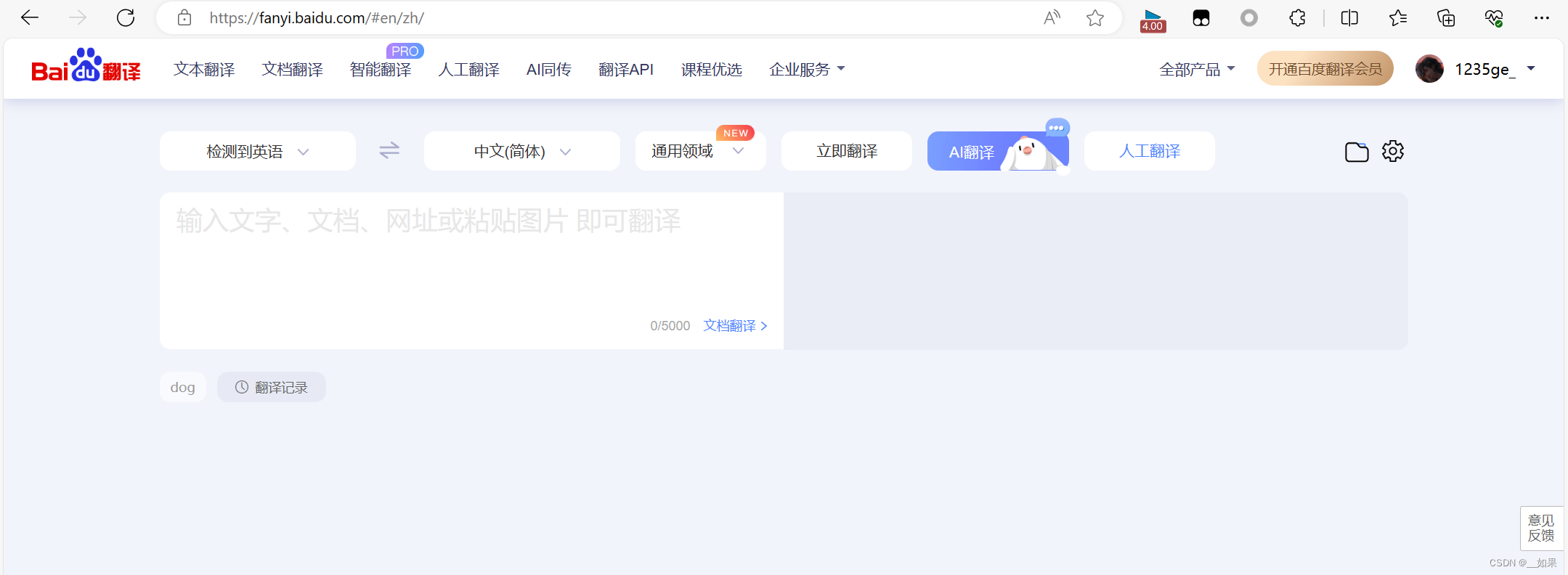
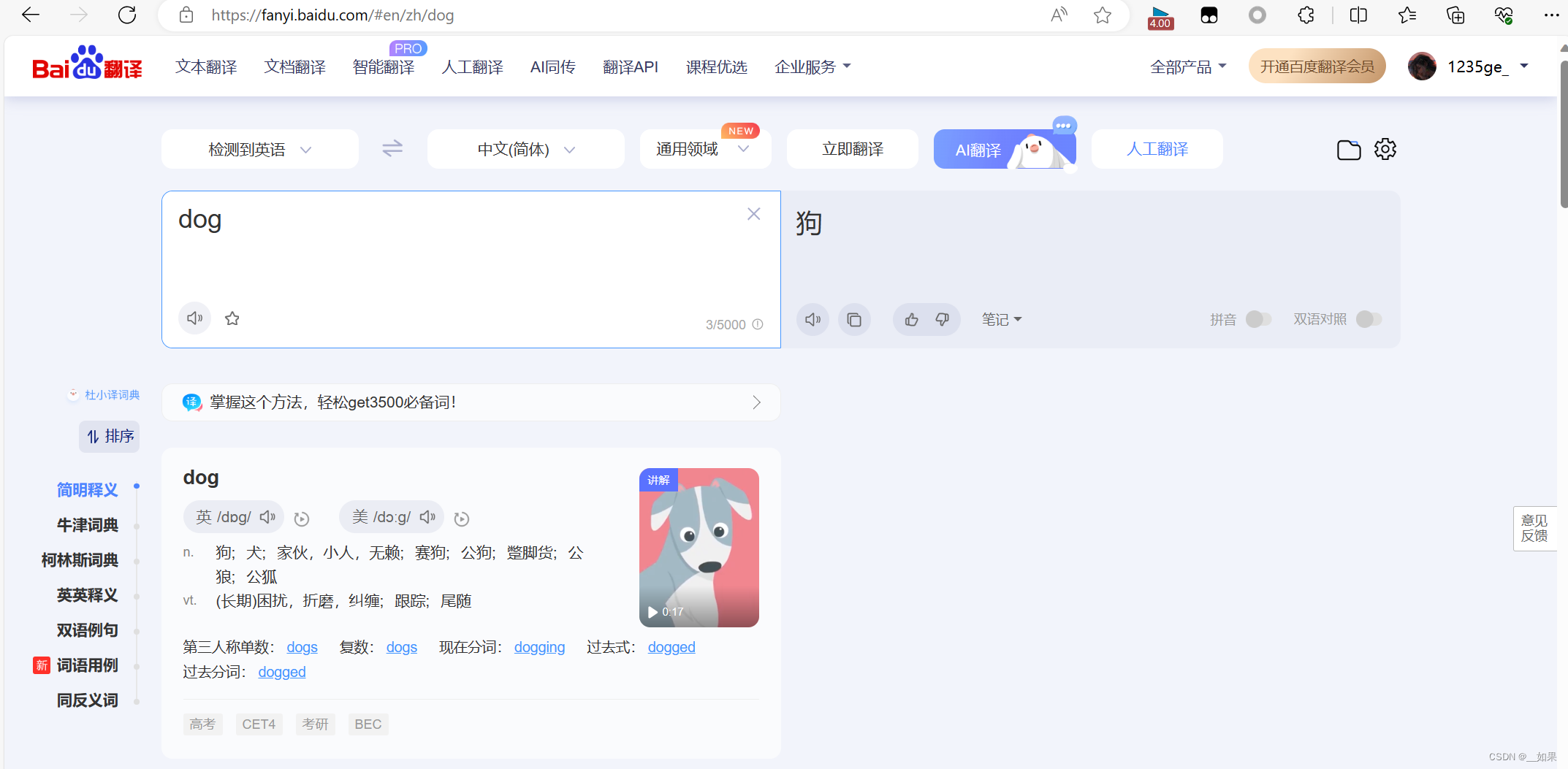
从上面两张图我们可以看出,输入单词后页面做了一个局部的刷新,我们知道局部的刷新是可以通过Ajax实现的,也就意味着我们在文本框中输入字符后,会自动进行Ajax的请求发送,Ajax请求成功后会对页面进行局部刷新
经过分析,我们是不是应该利用抓包工具,捕获一下对应的Ajax请求
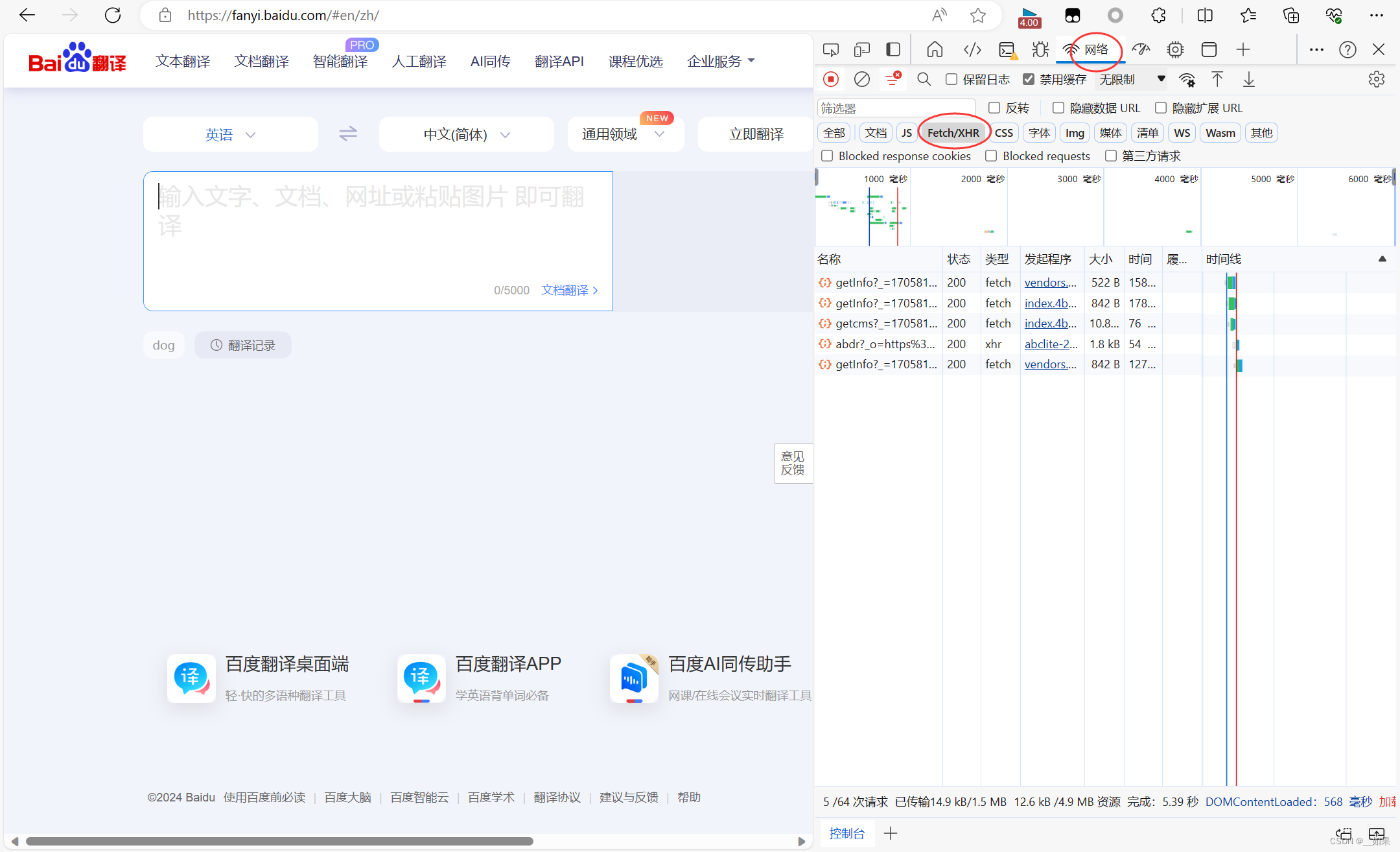
点击XHR,XHR中对应的是Ajax请求的数据包
输入dog
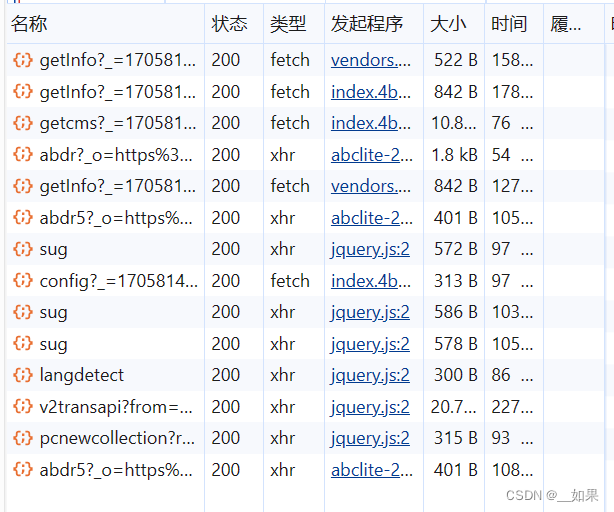
在xhr类型中一个个找
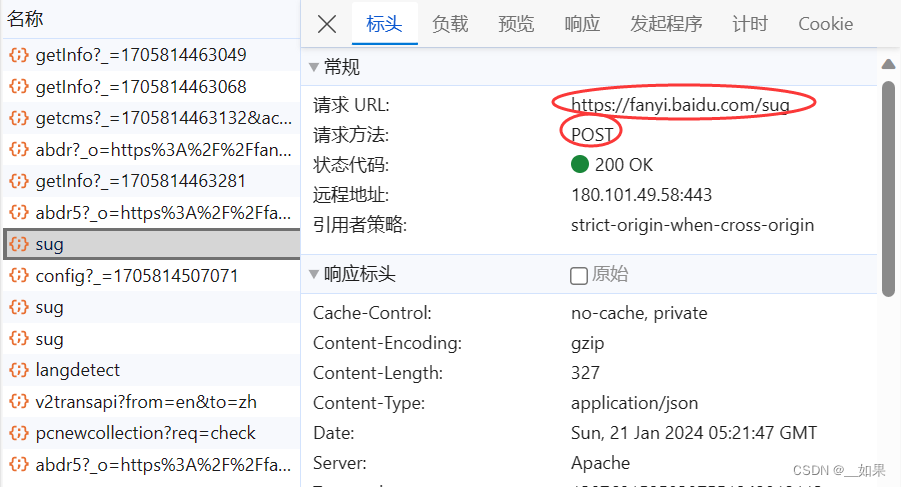
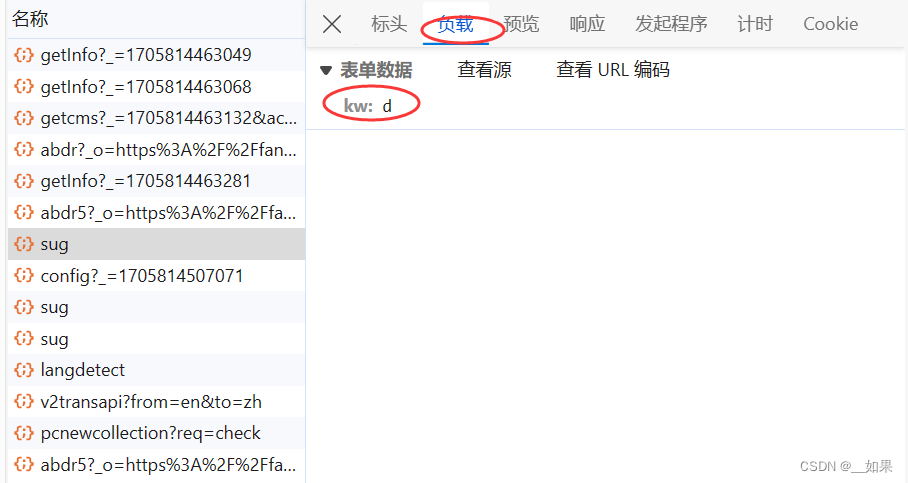
查看post请求携带的参数是d,不清楚是什么东西,所以接着往下看
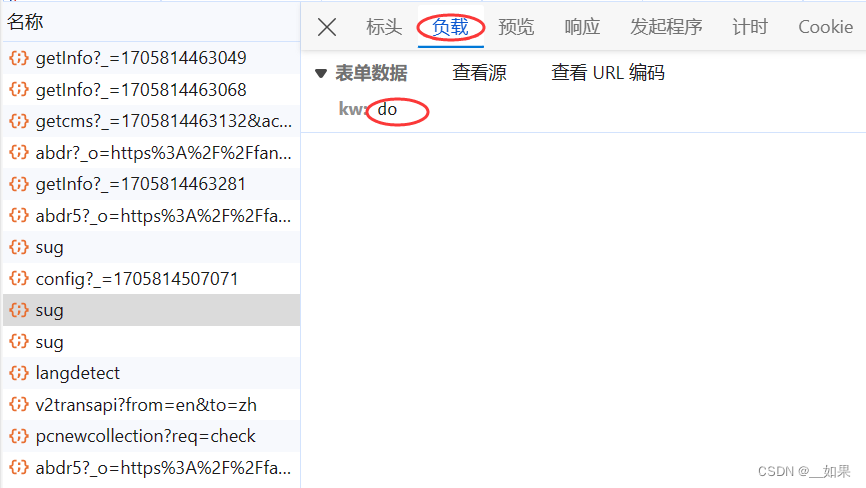
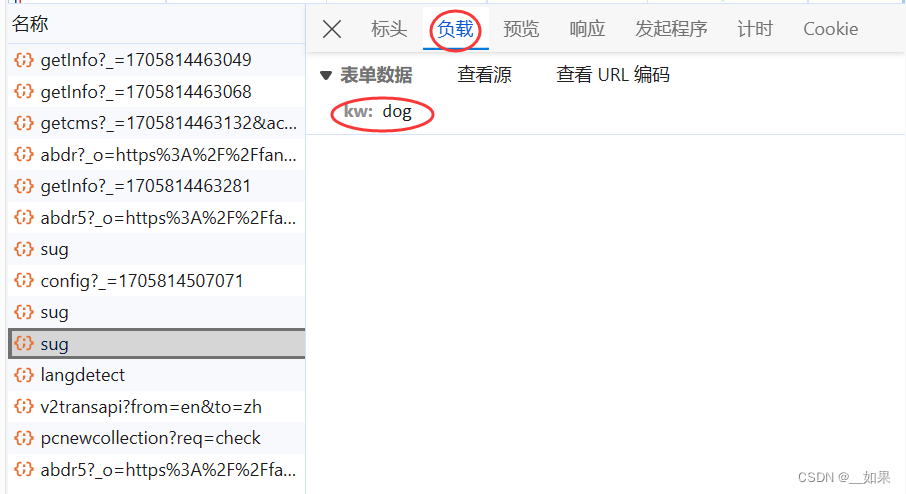
三个sug包对应的是每输入一个字符后的Ajax请求,我们需要的是dog的翻译结果,所以要抓最后一个sug包
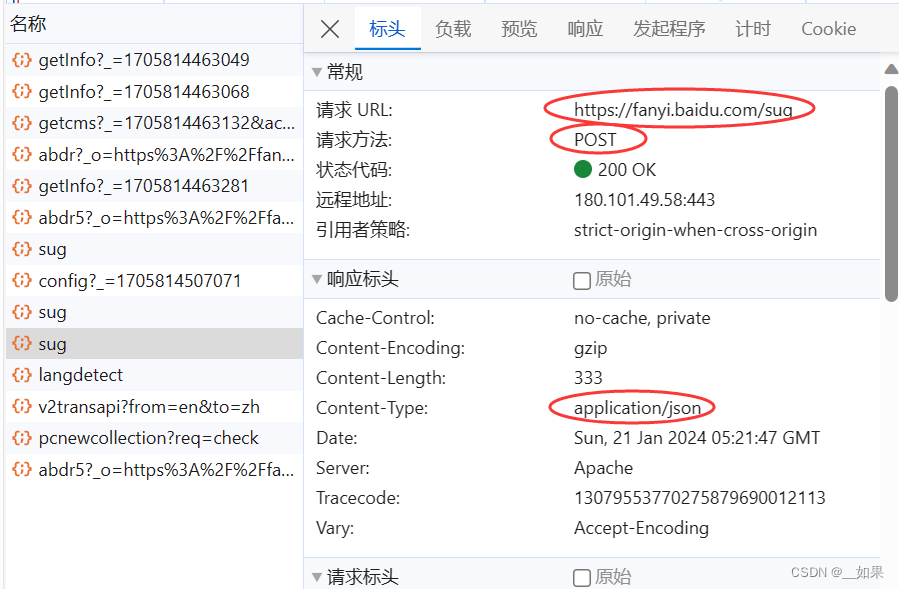
这样我们就拿到了请求的url,Content-Type这里是指我们输入一个字符后,服务器端响应回来的是一组json串
分析总结
(1)post请求(携带了参数)
(2)响应数据是一组json数据
import requests
import jsonpost_url = 'https://fanyi.baidu.com/sug'
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/99.0.4844.84 Safari/537.36 HBPC/12.1.3.303'
}
word = input()
data = {'kw': word
}
response = requests.post(url=post_url, data=data, headers=headers)
# 响应数据是json数据,如果继续使用.text获取的是一组字符串形式的json,而.json返回的是一个obj,json是什么对象就是什么对象,在这里是字典
dict_obj = response.json()
# 由于是字典对象,所以不能直接write
filename = './' + word + '.json'
fp = open(filename, 'w', encoding='utf-8')
json.dump(dict_obj, fp, ensure_ascii=False) # 字典中有中文,不用ascii编码豆瓣电影排名
爬取豆瓣电影某一分区的电影排名,以喜剧片为例
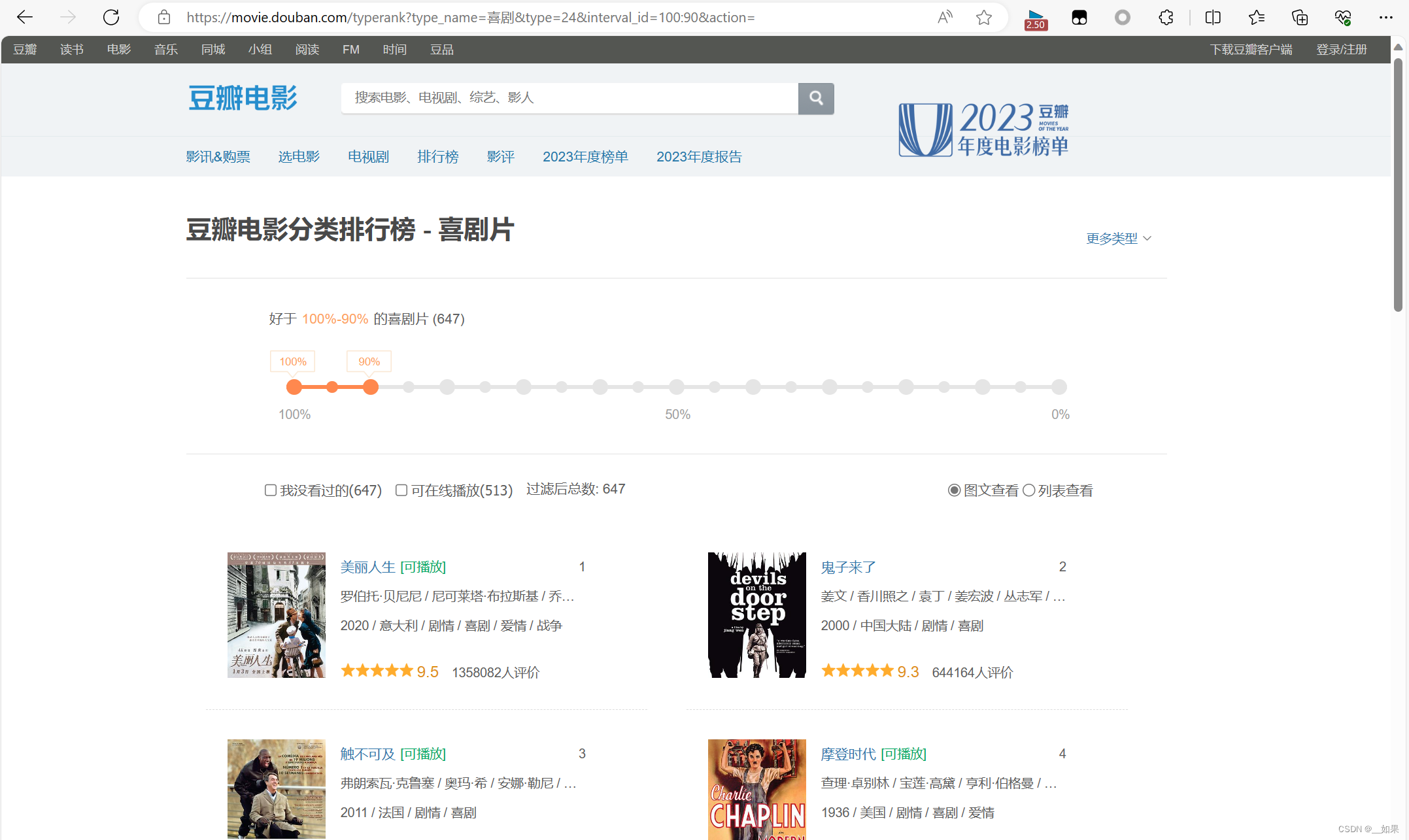
第一种方法:利用数据解析,如果对当前url进行整个页面信息的爬取,则能拿到页面信息,再利用数据解析就可以获取电影名、主演名、上映时间等等信息
第二种方法:思考它会不会像百度翻译一样,使用Ajax请求进行局部刷新呢?我们用滚轮滑到底部
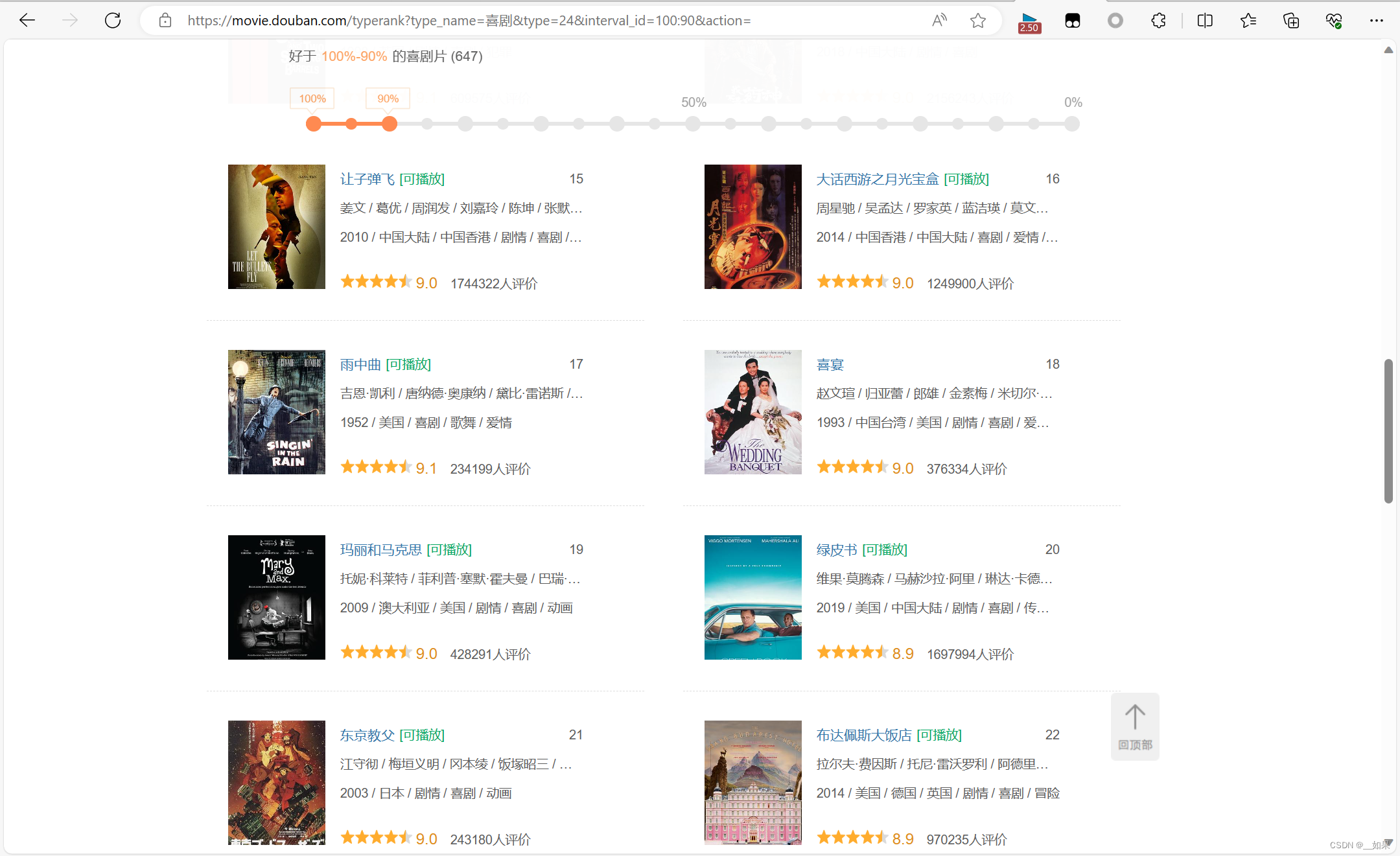
发现新的电源被加载出来了,滚轮回到中间,但是我们的url并没有改变,所以确实是一个Ajax请求

加载新电影时果然捕获了一个Ajax请求,GET请求且携带了5个参数,服务器端返回json串
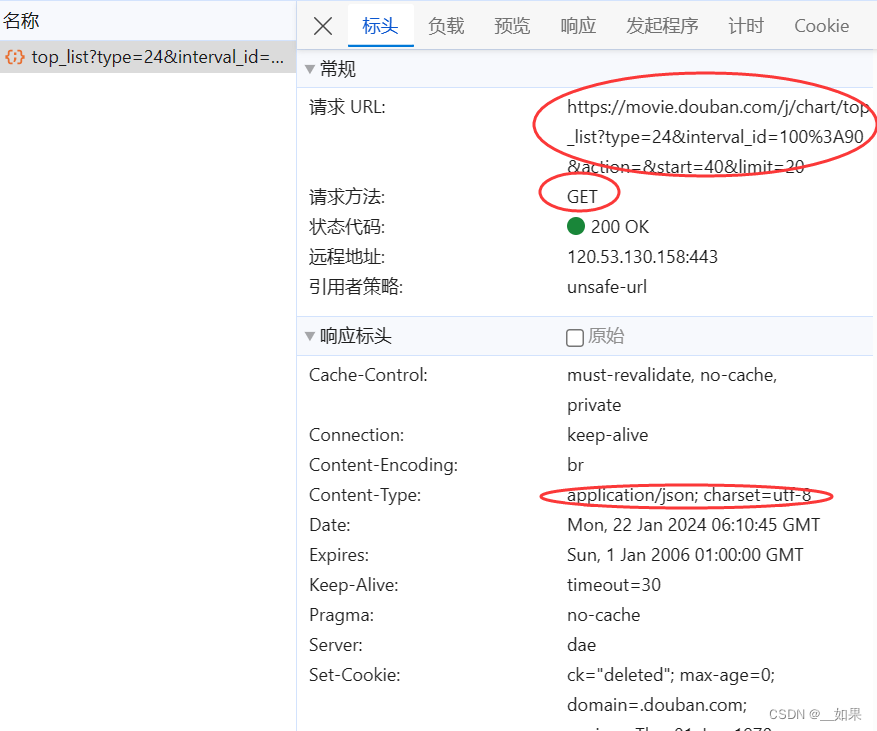
5个参数中,我们大概可以猜测出来start和limit含义:
start:从豆瓣数据库中第几部电源开始取出来
limit:取多少部
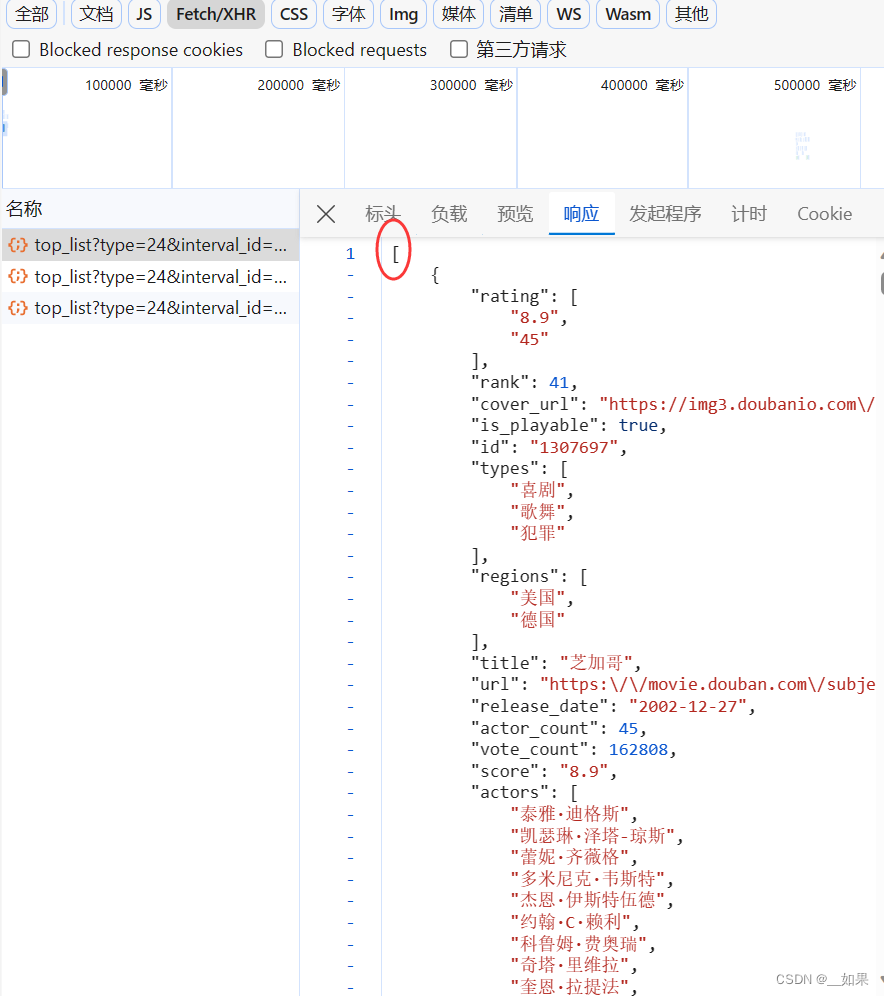
在响应中看到json串是列表对象
import requests
import jsonurl = 'https://movie.douban.com/j/chart/top_list'
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/120.0.0.0 Safari/537.36 Edg/120.0.0.0'
}
param = {'type': '24','interval_id': '100:90','action': '','start': '0', # 从豆瓣数据库中第几部电源开始取出来'limit': '20' # 一次取多少部
}
response = requests.get(url, params=param, headers=headers)list_obj = response.json()fp = open('douban_movie.json', 'w', encoding='utf-8')
json.dump(list_obj, fp, ensure_ascii=False)肯德基餐厅查询
肯德基官方网站 - Welcome to KFC.com.cn
爬取肯德基餐厅位置
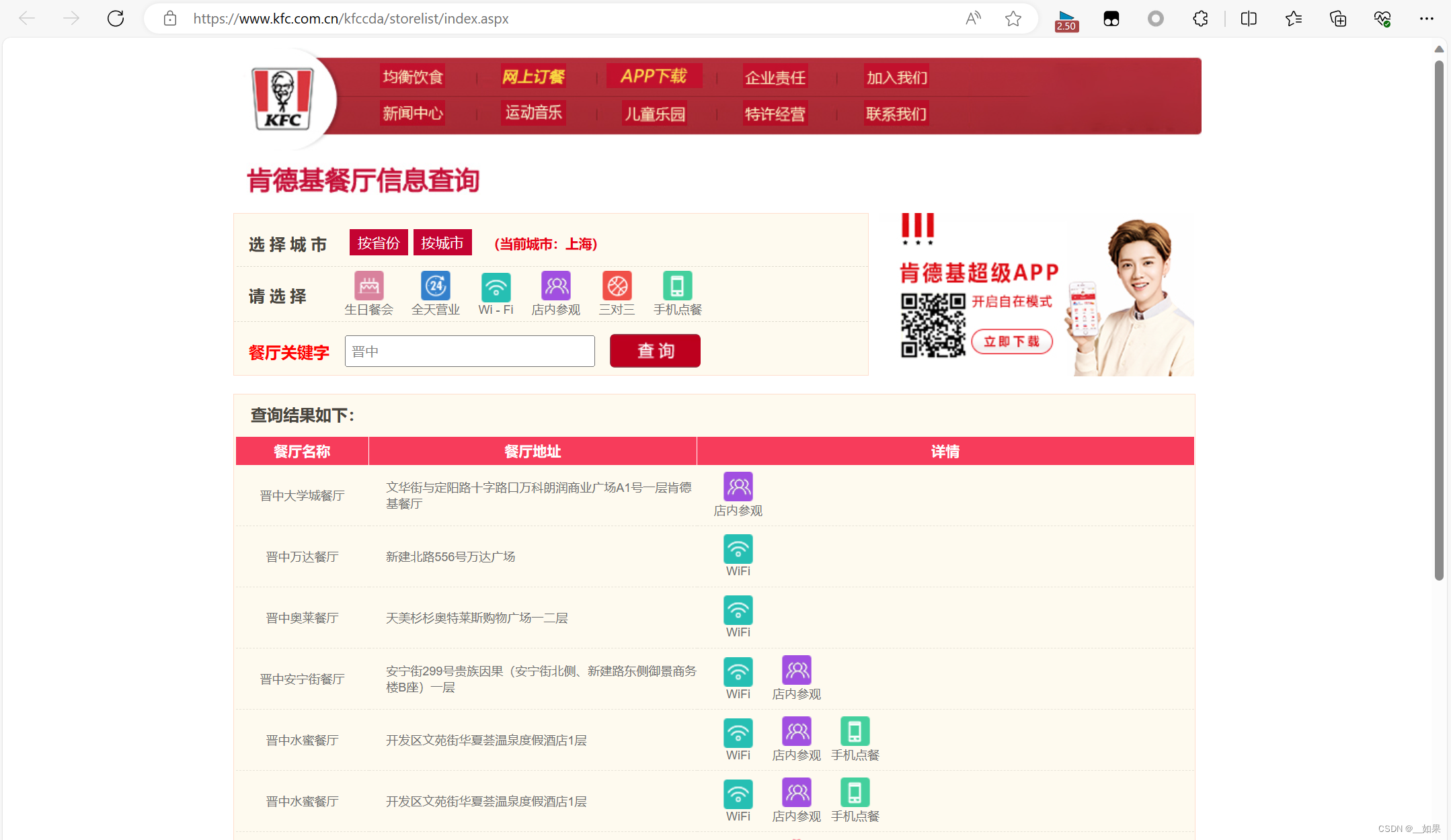
输入关键字后发现url并没有改变,说明是Ajax请求
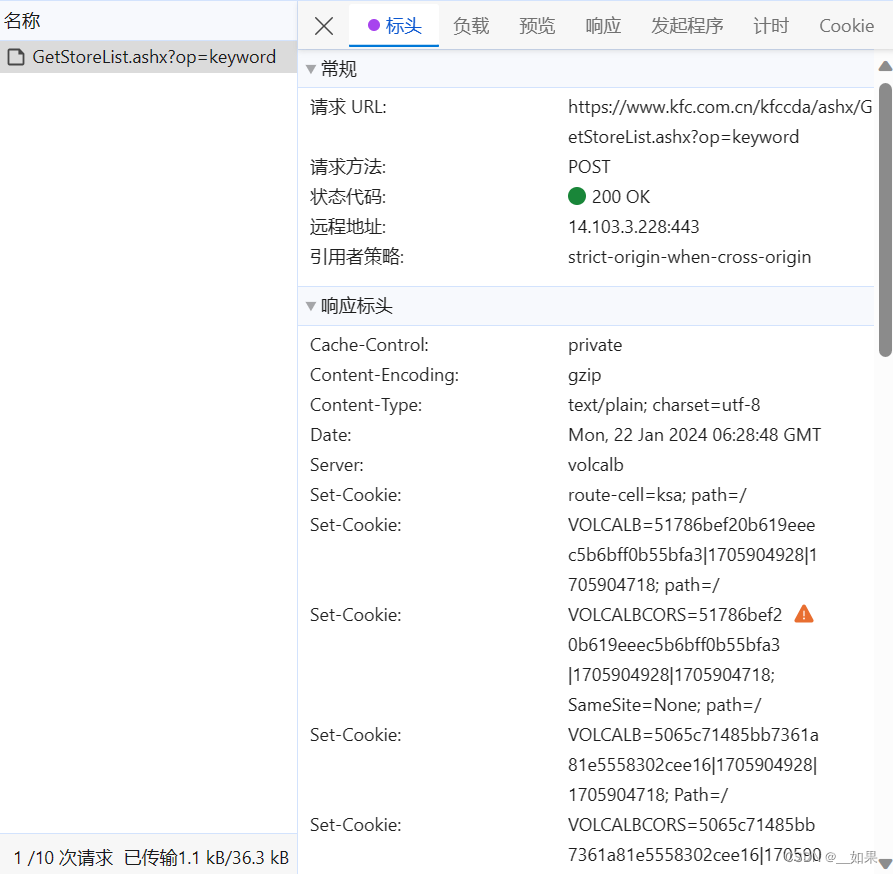
import requests
from bs4 import BeautifulSoupurl = 'https://www.kfc.com.cn/kfccda/ashx/GetStoreList.ashx?op=keyword'
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/120.0.0.0 Safari/537.36 Edg/120.0.0.0'
}
word = input()
data = {'cname': '','pid': '','keyword': word,'pageIndex': '1','pageSize': '10'
}
response = requests.post(url, data=data, headers=headers)
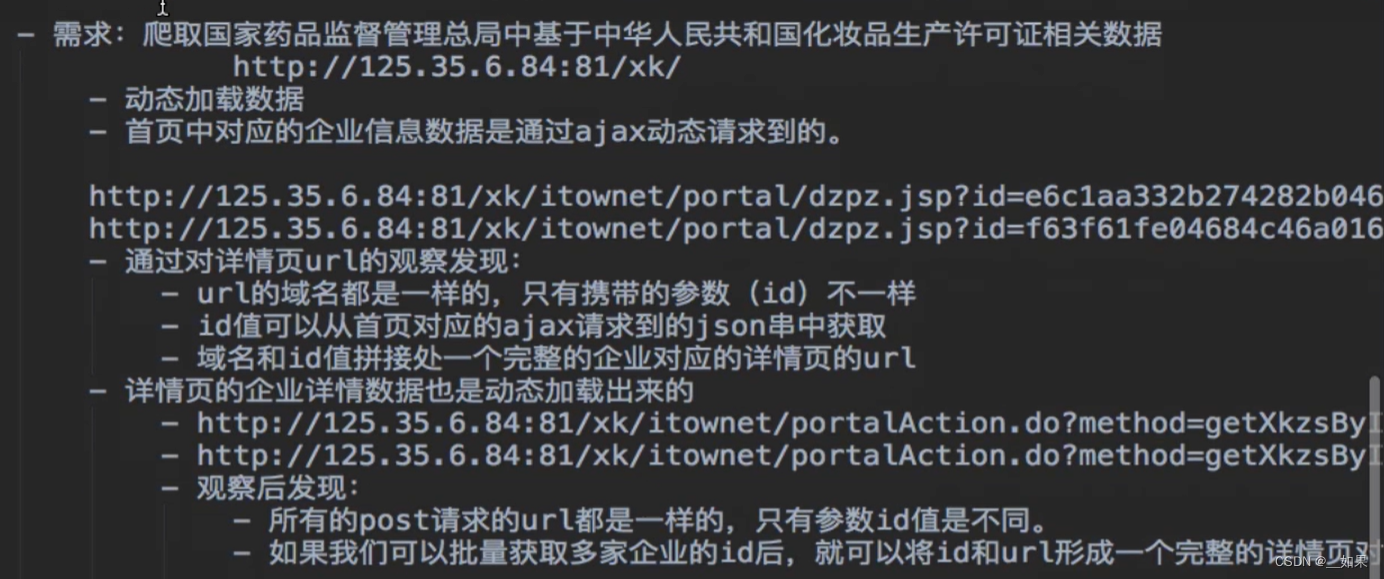
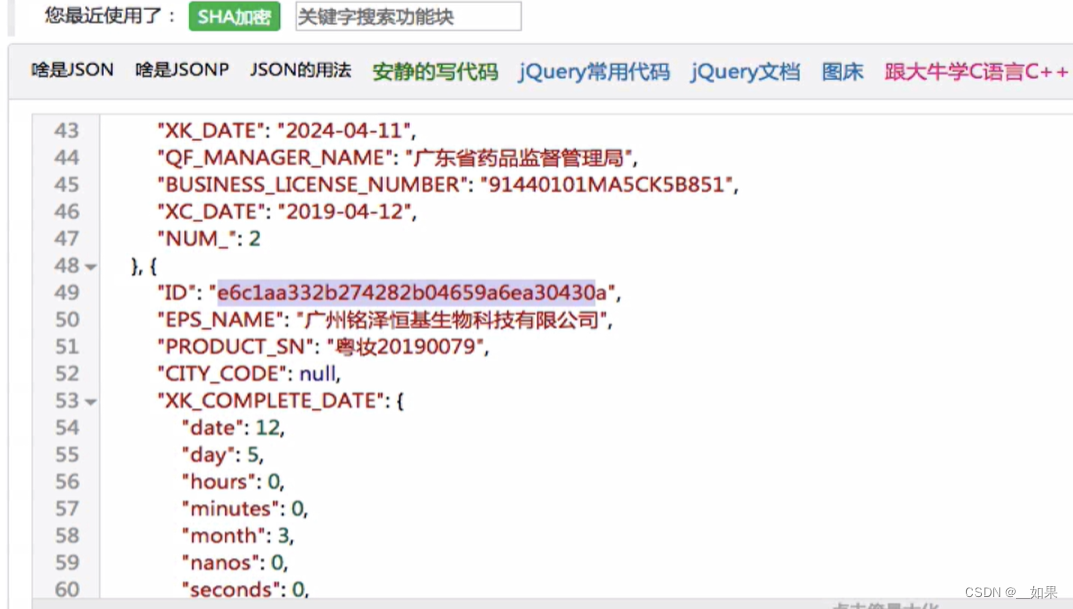
text = response.textwith open('kfc_' + word + '.html', 'w', encoding='utf-8') as fp:fp.write(text)国家药监局化妆品生产许可证
由于找不到网站在哪,所以无法敲代码实战,以下是需求分析: