文章目录
- BasicSR介绍
- 环境
- 数据
- 阶段 I - VQGAN
- 阶段 II - CodeFormer (w=0)
- 阶段 III - CodeFormer (w=1)
代码地址:https://github.com/sczhou/CodeFormer/releases/tag/v0.1.0
论文的一些简略介绍:
https://qq742971636.blog.csdn.net/article/details/134562550
BasicSR介绍
CodeFormer整个项目都沿袭BasicSR,了解一下BasicSR很有必要:
https://mp.csdn.net/mp_blog/creation/success/135674803
环境
# git clone this repository
git clone https://github.com/sczhou/CodeFormer
cd CodeFormer# create new anaconda env
conda create -n codeformer python=3.8 -y
conda activate codeformerconda install pytorch==1.13.1 torchvision==0.14.1 torchaudio==0.13.1 pytorch-cuda=11.7 -c pytorch -c nvidia# install python dependencies
pip3 install -r requirements.txt
python basicsr/setup.py developconda install -c conda-forge dlib (only for face detection or cropping with dlib)数据
找一些高清人脸数据1024*1024。
人脸数据需要对齐,对齐方式为: https://qq742971636.blog.csdn.net/article/details/135521146
阶段 I - VQGAN
训练VQGAN:
python -m torch.distributed.launch --nproc_per_node=8 --master_port=4321 basicsr/train.py -opt options/VQGAN_512_ds32_nearest_stage1.yml --launcher pytorch
CUDA_VISIBLE_DEVICES=0,2,3 python -m torch.distributed.launch --nproc_per_node=3 --master_port=4321 basicsr/train.py -opt options/VQGAN_512_ds32_nearest_stage1.yml --launcher pytorch # 指定三张显卡训练,对应VQGAN_512_ds32_nearest_stage1.yaml也是需要修改的
训练完VQGAN后,可以通过下面代码预先获得训练数据集的密码本序列,从而加速后面阶段的训练过程:
python scripts/generate_latent_gt.py
如果你不需要训练自己的VQGAN,可以在Release v0.1.0文档中找到预训练的VQGAN (vqgan_code1024.pth)和对应的密码本序列 (latent_gt_code1024.pth): https://github.com/sczhou/CodeFormer/releases/tag/v0.1.0
打开日志查看训练过程:
tensorboard --logdir="/ssd/xiedong/CodeFormer/tb_logger/20240116_182107_VQGAN-512-ds32-nearest-stage1" --bind_all
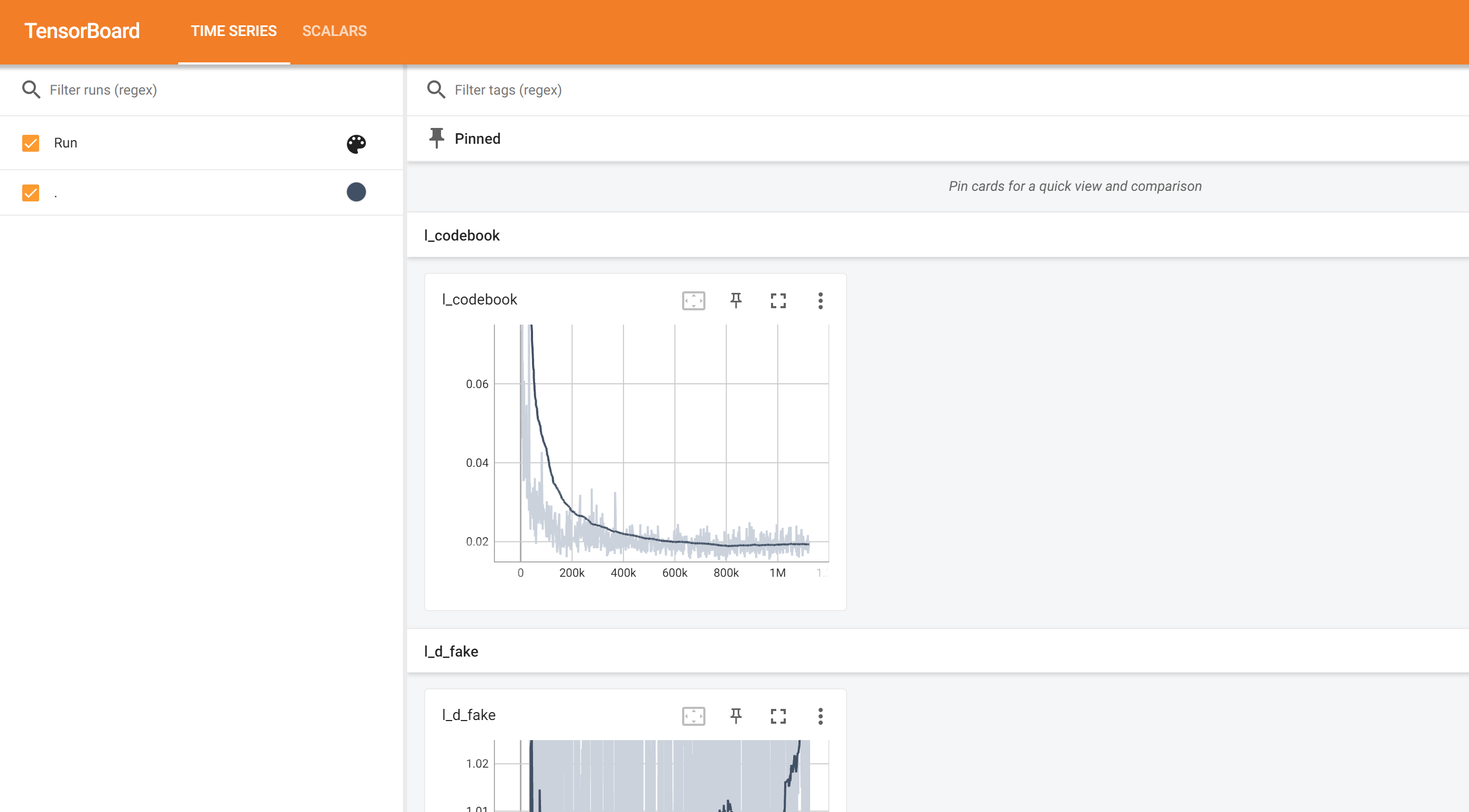
VQGAN本身就是一个图生图的网络,在中间使用transformer将特征图转为embedding. 而 CodeFormer就是要利用这每张图的embedding来进行面部修复。
下面代码里用vqgan_code1024.pth获取训练数据的密码本,vqgan_code1024.pth的encoder输出的是2563232的特征图,由embedding给到1*1024,最终所有图保存为一个pytorch文件。
import argparse
import glob
import numpy as np
import os
import cv2
import torch
from torchvision.transforms.functional import normalize
from tqdm import tqdmfrom basicsr.utils import imwrite, img2tensor, tensor2imgfrom basicsr.utils.registry import ARCH_REGISTRYif __name__ == '__main__':parser = argparse.ArgumentParser()parser.add_argument('-i', '--test_path', type=str, default='/ssd/xiedong/FFHQ/faces_hq_sr')parser.add_argument('-o', '--save_root', type=str, default='/ssd/xiedong/FFHQ/lt_output')parser.add_argument('--codebook_size', type=int, default=1024)parser.add_argument('--ckpt_path', type=str, default='/ssd/xiedong/CodeFormer/weights/vqgan/vqgan_code1024.pth')args = parser.parse_args()if args.save_root.endswith('/'): # solve when path ends with /args.save_root = args.save_root[:-1]dir_name = os.path.abspath(args.save_root)os.makedirs(dir_name, exist_ok=True)device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')test_path = args.test_pathsave_root = args.save_rootckpt_path = args.ckpt_pathcodebook_size = args.codebook_sizevqgan = ARCH_REGISTRY.get('VQAutoEncoder')(512, 64, [1, 2, 2, 4, 4, 8], 'nearest',codebook_size=codebook_size).to(device)checkpoint = torch.load(ckpt_path)['params_ema']vqgan.load_state_dict(checkpoint)vqgan.eval()sum_latent = np.zeros((codebook_size)).astype('float64')size_latent = 32latent = {}latent['orig'] = {}latent['hflip'] = {}for i in ['orig', 'hflip']:# for i in ['hflip']:for img_path in tqdm(sorted(glob.glob(os.path.join(test_path, '*.[jp][pn]g')))):img_name = os.path.basename(img_path)img = cv2.imread(img_path)if i == 'hflip':cv2.flip(img, 1, img)img = img2tensor(img / 255., bgr2rgb=True, float32=True)normalize(img, (0.5, 0.5, 0.5), (0.5, 0.5, 0.5), inplace=True)img = img.unsqueeze(0).to(device)with torch.no_grad():# output = net(img)[0]# x, feat_dict = vqgan.encoder(img, True)x = vqgan.encoder(img)x, _, log = vqgan.quantize(x)# del outputtorch.cuda.empty_cache()min_encoding_indices = log['min_encoding_indices']min_encoding_indices = min_encoding_indices.view(size_latent, size_latent)latent[i][img_name[:-4]] = min_encoding_indices.cpu().numpy()print(img_name, latent[i][img_name[:-4]].shape)latent_save_path = os.path.join(save_root, f'latent_gt_code{codebook_size}.pth')torch.save(latent, latent_save_path)print(f'\nLatent GT code are saved in {save_root}')阶段 II - CodeFormer (w=0)
w=0 是需要模型完全追求抽象美学,w=1 是需要模型完全追求与原图相似。
在第一个阶段,得到了每张图对应的embedding。
训练密码本训练预测模块:
python -m torch.distributed.launch --nproc_per_node=8 --master_port=4322 basicsr/train.py -opt options/CodeFormer_stage2.yml --launcher pytorch
预训练CodeFormer第二阶段模型 (codeformer_stage2.pth)可以在Releases v0.1.0文档里下载: https://github.com/sczhou/CodeFormer/releases/tag/v0.1.0
阶段 III - CodeFormer (w=1)
训练可调模块:
python -m torch.distributed.launch --nproc_per_node=8 --master_port=4323 basicsr/train.py -opt options/CodeFormer_stage3.yml --launcher pytorch
预训练CodeFormer模型 (codeformer.pth)可以在Releases v0.1.0文档里下载: https://github.com/sczhou/CodeFormer/releases/tag/v0.1.0






](https://img-blog.csdnimg.cn/direct/7f634ecff0ce46799c2ddc6dd630a3be.png)