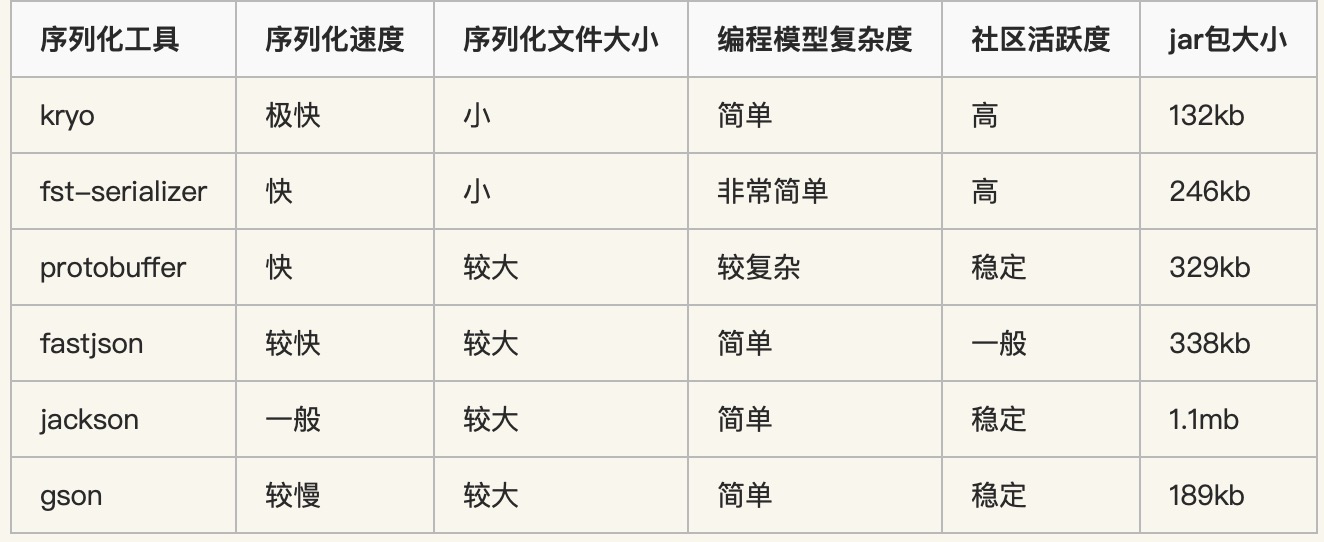
解开缺省参数与函数重载的衣裳
- 代码是如何由编译器变为可执行文件?
- 预处理 ->编译->汇编->链接
- 预处理
- 编译
- 汇编
- 链接
- 语法了解
- 缺省参数
- 语法实践
- 语法探究
- 函数重载
- 语法实践
- 语法探究
- 结语
本期和大家一起探究C++中的缺省函数与重载函数的语法说明与汇编过程

代码是如何由编译器变为可执行文件?
预处理 ->编译->汇编->链接
代码在由编译器变为可执行文件时,要经过编译和链接在这两个大过程,其中编译又可分为预处理,编译,汇编三个过程。
预处理
在预处理阶段,源文件和头文件会被处理为.i为后缀的文件,在gcc环境中将test.c预处理为test.i的命令如下:
gcc -E test.c -o test.i
预处理的规则如下:
- 将所有的
#define删除,同时展开所有宏定义 - 处理所有的条件编译指令,如:
#if , #ifdef , #elif , #else , #endif - 处理
#include预编译指令,将包含的头文件内容插入到该预编译指令的位置,这个过程是递归实现的,所以说被包含的头文件也可能包含其他的文件 - 删除所有注释
- 添加行号和文件名标识,方便后续编译器生成调试信息
- 保留所有的
#pragma的编译器指令,编译器后续会使用
编译
编译是将预处理后的文件进行词法分析、语法分析、语义分析及优化(检查语法)后,生成汇编代码,也就是.s文件
gcc中命令如下:
gcc -S test.i -o test.s
汇编
汇编器是将汇编代码转转变成机器可执⾏的指令,每⼀个汇编语句⼏乎都对应⼀条机器指令,所以在汇编就是将汇编码转成二进制机器码
gcc中指令如下:
gcc -c test.s -o test.o
链接
链接是将一堆文件链接到一起生成可执行文件,其主要过程包括:地址和空间分配,符号决议和重定位等这些步骤。解决了一个项目多文件,多模块之间相互调用的问题。
在了解 预处理 ->编译->汇编->链接 过程之后,我们来以缺省参数与函数重载来实践性的了解了解。
语法了解
缺省参数
概念:缺省参数是声明或定义时为函数的参数指定一个缺省值(默认值),在调用函数值,若没有指定实参则采用该形参的缺省值,否则使用指定的实参。
注意:
- 半缺省参数,缺省值必须从右往左给出,不能间隔着给。
- 当函数的声明与定义分离时,缺省值以该文件声明时的为主,若在同一文件下则只能声明。
- 缺省值必须是常数或者全局变量。
- C语言不支持。
语法实践
参考代码如下:
#include<iostream>int add(int a = 0, int b = 1)
{return a + b;
}int main()
{std::cout << add() << std::endl;std::cout << add(2) << std::endl;std::cout << add(2,2) << std::endl;return 0;
}
根据上述代码,我们可以看到当我们使用add函数时,
- 在全无实参的情况下,形参a,b使用缺省值,所以输出结果应为
1(0+1); - 在只有一个实参的情况下,传值从左到右,唯一的实参
1传给了a,b继续使用缺省值,所以输出结果应为3(2+1); - 在实参都没缺少的的时候,就相当于普通的函数实现一般,所以输出结果应为
4(2+2);
测试结果如下:

语法探究
我们可以看到如下定义的函数参数为全缺省参数
int add(int a = 0, int b = 1)
{return a + b;
}
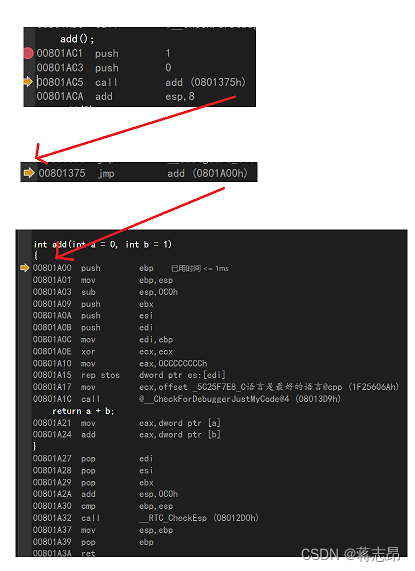
我们再来看看在main函数中调用该函数语句的汇编码,如下:
add();
00801AC1 push 1
00801AC3 push 0
00801AC5 call add (0801375h)
00801ACA add esp,8 add(2);
00801ACD push 1
00801ACF push 2
00801AD1 call add (0801375h)
00801AD6 add esp,8 add(2,2);
00801AD9 push 2
00801ADB push 2
00801ADD call add (0801375h)
00801AE2 add esp,8
我们可以看到由于栈的特性,在缺少实参时向栈中压入的缺省参数是由右到左的。
以add()为例,先push1即b=1在push0即a=0
这是否就可以间接地解释为什么半缺省参数,缺省值必须从右往左给出,不能间隔着给?
在调用函数时所开辟的栈帧中,先传参在调用,在缺少实参时就向栈中压入(push)缺省值,然后再调用add函数。
我们再来想想为什么当函数的声明与定义分离时,push的缺省值以该文件声明时的为主?
这就不得不来看看编译阶段了。
- 在编译阶段,首先扫描器会对代码进行词法分析,将代码中的字符分割为一系列的记号
(关键字、标识符、字⾯量、特殊字符等);- 接下来语法分析器,将对扫描产⽣的记号进⾏语法分析,从⽽产⽣
语法树。- 由语义分析器来完成语义分析,即对表达式的语法层⾯分析,这个阶段会报告错误的语法信息。
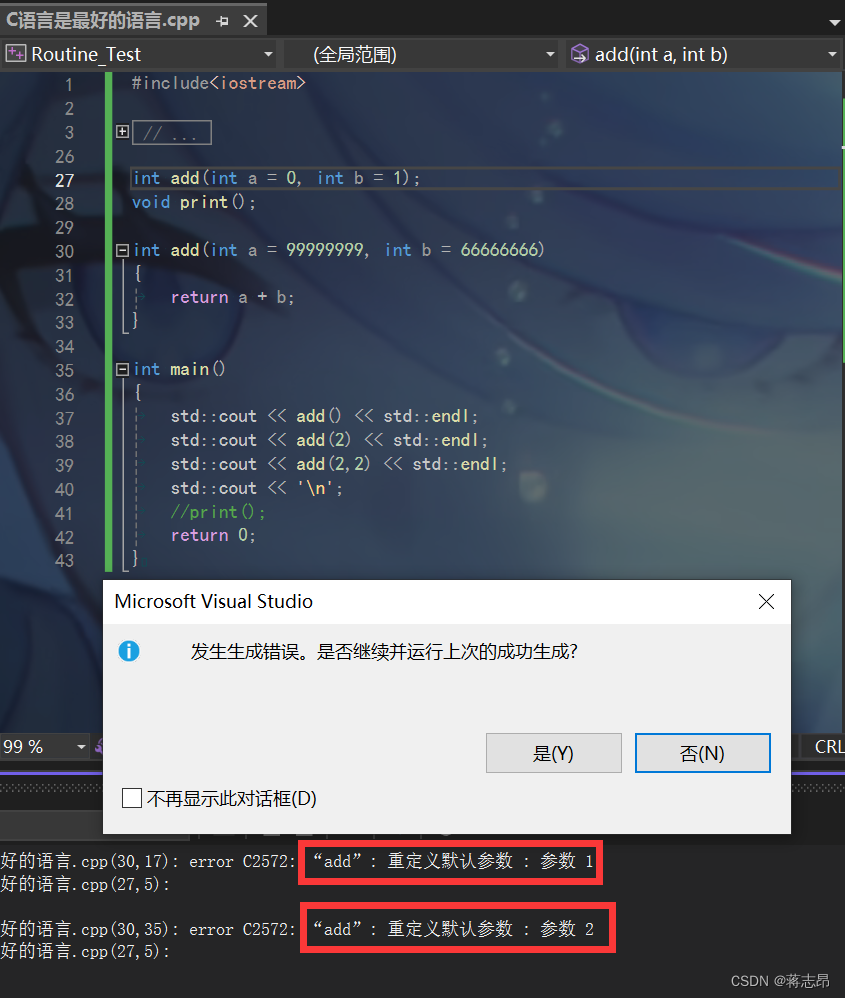
如果声明与定义分离,例如将add函数定义在test.cc中,而add函数的声明在C语言是最好的语言.cpp中
我们先来看看两段有意思的运行代码:
1.在不同文件下函数的声明与定义分离缺省值以该文件声明时的为主。
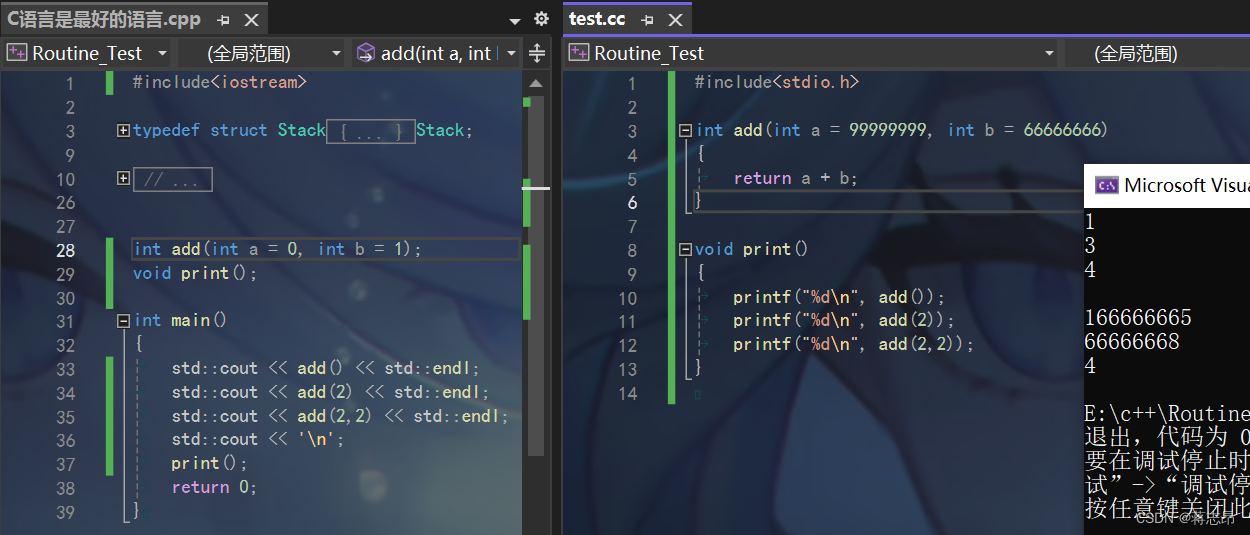
2.在同一文件下,函数的声明与定义分离,缺省值只能在声明中。
看着这两组图片,我不禁陷入沉思,为什么会是这样的运行结果呢?
- 对于第一种情况,不同文件下函数的声明与定义分离,编译器并不是对整个项目组同时一起进行检查,而是对每个文件进行检查(即每个文件独立检查)所以在第一种情况下,
test.cc的add函数中可以理解为函数的声明和定义并没有分离,而在C语言是最好的语言.cpp中,可以看做add函数只是做了声明。而在后续调用该函数进行计算时能够运行,是因为编译器。在进行了。编译和汇编之后生成了与机器指令对应的汇编码,编译器将一个项目的多个文件链接在一起生成可执行程序,所以才有了如图的输出结果。- 而对于第二种情况,在同一文件下,缺省值在函数的声明与定义中同时定义,所以在编译阶段的语法检查时,就直接报错,并且中断了程序。
如下图就是一个add函数的调用过程:
函数重载
概念:函数重载是一种特殊的情况,C++允许在同一作用域中声明几个功能不同函数名相同,但是要求形参类型或个数或类型顺序不同。
实践作用:常用来处理功能类似数据类型不同的问题。
语法实践
参考代码如下:
#include<iostream>int add(int a, int b)
{return a + b;
}double add(double a, double b)
{return a + b;
}double add(double a, int b)
{return a + b;
}int main()
{std::cout << add(2.2,2.2) << std::endl;std::cout << add(2,2) << std::endl;std::cout << add(2.2,2) << std::endl;return 0;
}
根据上述代码,我们可以看到当我们使用add函数时,
- 当两个实参为
2.2时,调用double add(double a, double b)返回4.4 - 当两个实参为
2时,调用int add(int a, int b)返回4 - 当一个实参为
2.2,另一个实参为2时,调用double add(double a, int b)返回4.2
测试结果如下:

语法探究
对于一个同名文件为什么可以通过参数的不同来进行调用呢?编译器又是如何区分的呢?
面对着这两个问题,我不经陷入沉思,于是打开了我的Linux来对其一趟究竟。
我们依旧使用上一个举例的代码。
输入Linux指令
g++ -S explore.cc -o explore.s
得到汇编码如下:
.file "explore.cc".local _ZStL8__ioinit.comm _ZStL8__ioinit,1,1.text.globl _Z3addii.type _Z3addii, @function
_Z3addii:
.LFB971:.cfi_startprocpushq %rbp.cfi_def_cfa_offset 16.cfi_offset 6, -16movq %rsp, %rbp.cfi_def_cfa_register 6movl %edi, -4(%rbp)movl %esi, -8(%rbp)movl -8(%rbp), %eaxmovl -4(%rbp), %edxaddl %edx, %eaxpopq %rbp.cfi_def_cfa 7, 8ret.cfi_endproc
.LFE971:.size _Z3addii, .-_Z3addii.globl _Z3adddd.type _Z3adddd, @function
_Z3adddd:
.LFB972:.cfi_startprocpushq %rbp.cfi_def_cfa_offset 16.cfi_offset 6, -16movq %rsp, %rbp.cfi_def_cfa_register 6movsd %xmm0, -8(%rbp)movsd %xmm1, -16(%rbp)movsd -8(%rbp), %xmm0addsd -16(%rbp), %xmm0movsd %xmm0, -24(%rbp)movq -24(%rbp), %raxmovq %rax, -24(%rbp)movsd -24(%rbp), %xmm0popq %rbp.cfi_def_cfa 7, 8ret.cfi_endproc
.LFE972:.size _Z3adddd, .-_Z3adddd.globl _Z3adddi.type _Z3adddi, @function
_Z3adddi:
.LFB973:.cfi_startprocpushq %rbp.cfi_def_cfa_offset 16.cfi_offset 6, -16movq %rsp, %rbp.cfi_def_cfa_register 6movsd %xmm0, -8(%rbp)movl %edi, -12(%rbp)cvtsi2sd -12(%rbp), %xmm0addsd -8(%rbp), %xmm0movsd %xmm0, -24(%rbp)movq -24(%rbp), %raxmovq %rax, -24(%rbp)movsd -24(%rbp), %xmm0popq %rbp.cfi_def_cfa 7, 8ret.cfi_endproc
.LFE973:.size _Z3adddi, .-_Z3adddi.globl main.type main, @function
main:
.LFB974:.cfi_startprocpushq %rbp.cfi_def_cfa_offset 16.cfi_offset 6, -16movq %rsp, %rbp.cfi_def_cfa_register 6subq $16, %rspmovabsq $4612136378390124954, %rdxmovabsq $4612136378390124954, %raxmovq %rdx, -8(%rbp)movsd -8(%rbp), %xmm1movq %rax, -8(%rbp)movsd -8(%rbp), %xmm0call _Z3addddmovsd %xmm0, -8(%rbp)movq -8(%rbp), %raxmovq %rax, -8(%rbp)movsd -8(%rbp), %xmm0movl $_ZSt4cout, %edicall _ZNSolsEdmovl $_ZSt4endlIcSt11char_traitsIcEERSt13basic_ostreamIT_T0_ES6_, %esimovq %rax, %rdicall _ZNSolsEPFRSoS_Emovl $2, %esimovl $2, %edicall _Z3addiimovl %eax, %esimovl $_ZSt4cout, %edicall _ZNSolsEimovl $_ZSt4endlIcSt11char_traitsIcEERSt13basic_ostreamIT_T0_ES6_, %esimovq %rax, %rdicall _ZNSolsEPFRSoS_Emovabsq $4612136378390124954, %raxmovl $2, %edimovq %rax, -8(%rbp)movsd -8(%rbp), %xmm0call _Z3adddimovsd %xmm0, -8(%rbp)movq -8(%rbp), %raxmovq %rax, -8(%rbp)movsd -8(%rbp), %xmm0movl $_ZSt4cout, %edicall _ZNSolsEdmovl $_ZSt4endlIcSt11char_traitsIcEERSt13basic_ostreamIT_T0_ES6_, %esimovq %rax, %rdicall _ZNSolsEPFRSoS_Emovl $0, %eaxleave.cfi_def_cfa 7, 8ret.cfi_endproc
.LFE974:.size main, .-main.type _Z41__static_initialization_and_destruction_0ii, @function
_Z41__static_initialization_and_destruction_0ii:
.LFB981:.cfi_startprocpushq %rbp.cfi_def_cfa_offset 16.cfi_offset 6, -16movq %rsp, %rbp.cfi_def_cfa_register 6subq $16, %rspmovl %edi, -4(%rbp)movl %esi, -8(%rbp)cmpl $1, -4(%rbp)jne .L9cmpl $65535, -8(%rbp)jne .L9movl $_ZStL8__ioinit, %edicall _ZNSt8ios_base4InitC1Evmovl $__dso_handle, %edxmovl $_ZStL8__ioinit, %esimovl $_ZNSt8ios_base4InitD1Ev, %edicall __cxa_atexit
.L9:leave.cfi_def_cfa 7, 8ret.cfi_endproc
.LFE981:.size _Z41__static_initialization_and_destruction_0ii, .-_Z41__static_initialization_and_destruction_0ii.type _GLOBAL__sub_I__Z3addii, @function
_GLOBAL__sub_I__Z3addii:
.LFB982:.cfi_startprocpushq %rbp.cfi_def_cfa_offset 16.cfi_offset 6, -16movq %rsp, %rbp.cfi_def_cfa_register 6movl $65535, %esimovl $1, %edicall _Z41__static_initialization_and_destruction_0iipopq %rbp.cfi_def_cfa 7, 8ret.cfi_endproc
.LFE982:.size _GLOBAL__sub_I__Z3addii, .-_GLOBAL__sub_I__Z3addii.section .init_array,"aw".align 8.quad _GLOBAL__sub_I__Z3addii.hidden __dso_handle.ident "GCC: (GNU) 4.8.5 20150623 (Red Hat 4.8.5-44)".section .note.GNU-stack,"",@progbits汇编码虽然有点长,但是我们可以看到在Linux下,采用g++编译完成后,函数名字的修饰发生改变,编译器将函数参数类型信息添加到修改后的名字中。
在该例子中代码与修饰后的名字如下:int add(int ,int ) --> _Z3addii int add(double ,double ) -->_Z3adddd int add(double ,int ) -->_Z3adddi所以这就是为什么有函数重载
Linux下g++的命名修饰规则:
_z+ 后面接的数字表示函数名字的字符个数 + 函数名字 + 从左到右参数类型的依次缩写
这就很好的说明了形参类型或个数或类型顺序不同,可以支持函数重载。
同时,我们也可以看到Linux下g++的命名修饰规则并没有对函数的返回类型进行修饰,所以函数的返回类型不同不能理解为函数重载。
结语
以上就是本期的全部内容,若有错误请务必指出,喜欢就请多多关注吧!!!


](https://img-blog.csdnimg.cn/direct/7f634ecff0ce46799c2ddc6dd630a3be.png)