论文名: Towards Semi-Supervised Deep Facial Expression Recognition with An Adaptive Confidence Margin
论文来源: CVPR
发表时间: 2022-04
研究背景:
对大量图片或视频进行手工标注表情是一件极其繁琐的事情,因此现存的数据集并不够丰富。近年来,也有了一些大规模数据集的出现,并促进了深度面部表情识别FER的发展。然而,收集大规模带标签的数据是相当昂贵且困难的。同时,现有的许多数据标签往往无法满足实际细粒度的需求,若需要重新标记数据,还需要聘请相关领域的专家。因此,当下迫切需要开发一种可以在大量未标记数据上进行训练的方法,即半监督深度FER。
目前绝大部分使用到半监督学习方法的FER模型只选择部分未标记的数据来训练,即只选择那些置信度分数高于预定值的数据。这不但对部分数据造成了浪费,并且对所有表情类别设置同样的阈值是不科学的。有些面部表情,例如快乐,通常比某些面部表情具有更高的置信度分数,更容易识别。本文认为,应该对于不同类别的面部表情按其不同程度的学习难度进行分类,自适应地更新其置信度分数。从而使用所有未标记的数据来进一步提高识别性能。
论文的主要工作以及创新点:
本文的主要工作有,第一,提出了一种具有自适应置信区间Ada-CM的半监督DFER算法;第二,利用置信度分数较低的样本增强特征级的相似性,动态学习模型训练的所有未标记数据;第三在四个主流数据集上的大量实验表明,本方法的有效性超过当前完全监督的基线。
本文提出了一种端到端的具有自适应置信区间Ada-CM的半监督DFER算法,是目前第一个探索半监督深度面部表情识别中使用到动态置信度的解决方案。本文先将所有的数据分成两类(具体的分类方法将在下一段单独介绍)。子集I包括置信度分数高的样本,即置信度分数不低于界限阈值;子集II包括置信度分数低的样本,即置信度分数低于界限阈值。对于子集 I 中的样本,Ada-CM利用其用其伪标签对强增广SA的图片进行交叉熵训练;对于子集 II中的样本,用对比学习对弱增广的特征进行约束。
通过上一段的描述不难看出,将数据分成两个子集的依据是其置信度分数是否超过界限阈值。本文中,对于每个表情类别,阈值初始值为0.8。而且随着模型的提升,这个阈值界限会逐步升高,每个表情类别的阈值界限提升度也会有所不同。那么每个图片的置信度分数又是怎么得来的呢?首先,模型先对有表情的数据进行训练,用正确的预测得到阈值。然后,对于无标签的数据,对其进行弱增广 Week Augmentation,送入网络求出两个预测的均值。均值就是我们上文中提到的置信度分数。当均值大于阈值界限时,数据被分到第一个类别中,用其伪标签对强增广SA的图片进行交叉熵训练;当均值小于阈值界限时,数据被分到第二个类别中,用对比学习对弱增广的特征进行约束。
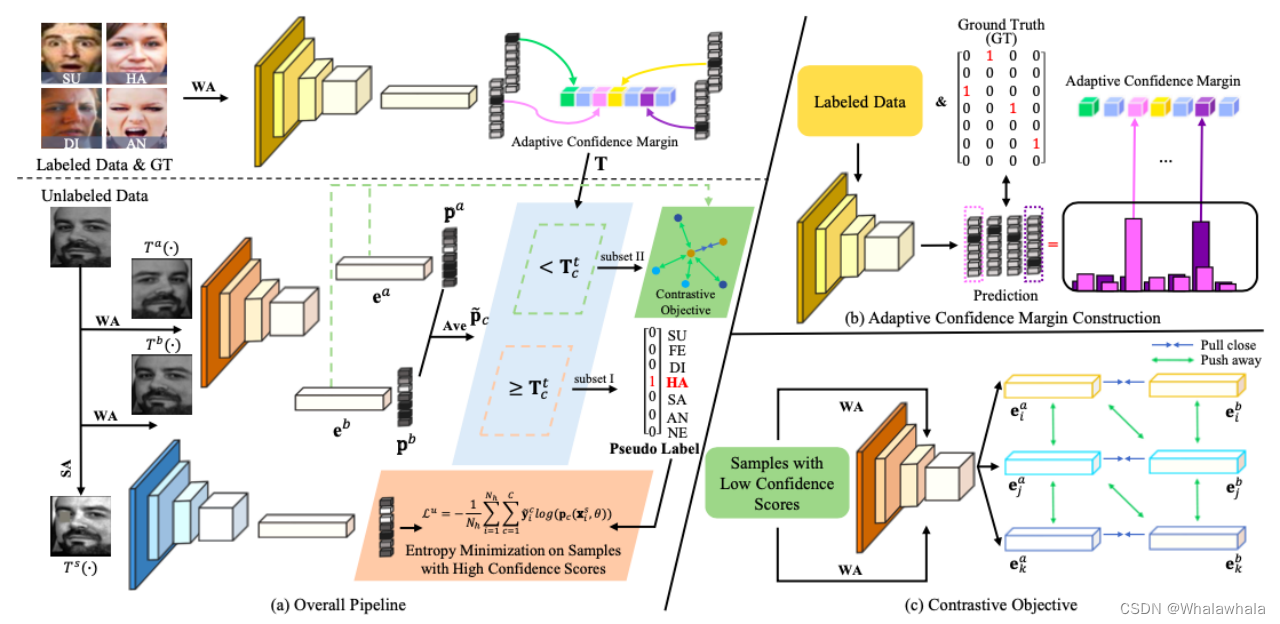 上图是Ada-CM的管道图,分为三个部分,部分a是总体流程设计图,部分b是自适应置信度构造原理图,部分c是对比目标图。在部分a中,最上面的一行是对于有标签数据的学习。每个前向传递都将弱增强WA标记样本输入到模型中以学习自适应置信度。具体来说,当模型的预测等于真实值时,将相应的置信度分数放入置信度中,然后将平均值用作学习的界限。接下来,将两个 WA 未标记样本分别输入到模型中,得到概率分布 pa 和 pb。然后,Ada-CM 根据置信度分数,即平均概率分布中的最大值,和置信界限Tt c 之间的关系将所有未标记的数据划分为两个子集。最后,通过熵最小化和对比目标分别探讨了具有伪标签的子集I中的样本和子集II中样本的特征相似度。
上图是Ada-CM的管道图,分为三个部分,部分a是总体流程设计图,部分b是自适应置信度构造原理图,部分c是对比目标图。在部分a中,最上面的一行是对于有标签数据的学习。每个前向传递都将弱增强WA标记样本输入到模型中以学习自适应置信度。具体来说,当模型的预测等于真实值时,将相应的置信度分数放入置信度中,然后将平均值用作学习的界限。接下来,将两个 WA 未标记样本分别输入到模型中,得到概率分布 pa 和 pb。然后,Ada-CM 根据置信度分数,即平均概率分布中的最大值,和置信界限Tt c 之间的关系将所有未标记的数据划分为两个子集。最后,通过熵最小化和对比目标分别探讨了具有伪标签的子集I中的样本和子集II中样本的特征相似度。
TodoList:
- 阈值固定的缺点
- 高/低置信度数据的使用情况,具体拿来做什么了
- 调查视频领域有没有半监督的
- 无标签的数据从哪来
- 一个表情的确认要多少帧