1.点积注意力机制简介
点积注意力机制(Dot-Product Attention)是一种常用的注意力机制之一,通常与Seq2Seq模型中的自注意力(Self-Attention)机制一起使用。它用于计算查询(Query)和键(Key)之间的相关性,并利用相关性来加权求和值(Value)。
点积注意力机制可以分为三个主要步骤:
1.1查询、键和值的线性变换
在这一步骤中,我们首先对查询向量Q、键向量K和值向量V进行线性变换,将其投射到低维空间以进行计算。变换后的查询向量记作Q',变换后的键向量记作K',变换后的值向量记作V'。
1.2计算注意力权重
在这一步骤中,我们计算查询向量Q'与每个键向量K'之间的相关性得分,通过计算点积(内积)来衡量它们之间的相似度。利用softmax函数,我们可以将这些得分归一化为注意力权重,确保它们总和为1。计算得到的注意力权重与值向量V'相乘,就得到了加权求和后的上下文向量。
1.3上下文向量的计算
最后一步,我们将注意力权重与值向量V'进行加权求和,得到最终的上下文向量。这个上下文向量将包含与查询向量Q'最相关的信息,用于后续的任务。
点积注意力机制的优势在于计算简单高效,因为向量的点积运算具有并行计算的特点,适合在大规模计算中使用。另外,点积注意力还可以更好地保留输入的整体结构信息,因为它直接通过点积来度量查询和键之间的关联性。
需要注意的是,点积注意力机制在一些情况下可能会存在缩放问题。为了解决这个问题,可以通过对点积结果进行缩放操作,常用的缩放因子为1 / 根号d_k,其中d_k表示查询和键的维度。这样能够减小点积结果的大小,避免梯度消失或爆炸的问题。
下图是transformer中的自注意力机制:

2.点积注意力机制代码实现
2.1创建两个张量
import torch # 导入 torch
import torch.nn.functional as F # 导入 nn.functional
# 1. 创建两个张量 x1 和 x2
x1 = torch.randn(2, 3, 4) # 形状 (batch_size, seq_len1, feature_dim)
x2 = torch.randn(2, 5, 4) # 形状 (batch_size, seq_len2, feature_dim)print("x1:", x1)
print("x2:", x2)
2.2计算点积,得到原始权重,形状为 (batch_size, seq_len1, seq_len2)
# 计算点积,得到原始权重,形状为 (batch_size, seq_len1, seq_len2)
raw_weights = torch.bmm(x1, x2.transpose(1, 2))
print(" 原始权重:", raw_weights) 
2.3应用 softmax 函数,使权重的值在0和1之间,且每一行的和为1
import torch.nn.functional as F # 导入 torch.nn.functional
# 应用 softmax 函数,使权重的值在 0 和 1 之间,且每一行的和为 1
attn_weights = F.softmax(raw_weights, dim=-1) # 归一化
print(" 归一化后的注意力权重:", attn_weights)
2.4与 x2 相乘,得到注意力分布的加权和,形状为 (batch_size, seq_len1, feature_dim)
# 与 x2 相乘,得到注意力分布的加权和,形状为 (batch_size, seq_len1, feature_dim)
attn_output = torch.bmm(attn_weights, x2)
print(" 注意力输出 :", attn_output) 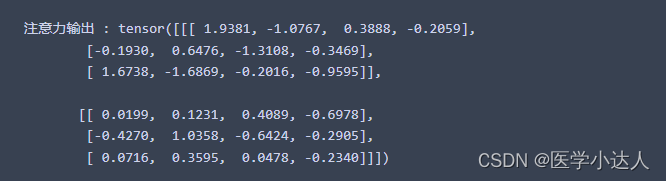
2.5总结
点积注意力机制是一种常用的注意力机制,用于计算查询和键之间的相关性,并利用相关性进行加权求和操作。它具有计算简单高效的优势,适合处理大规模计算,并可以更好地保留输入的整体结构信息。