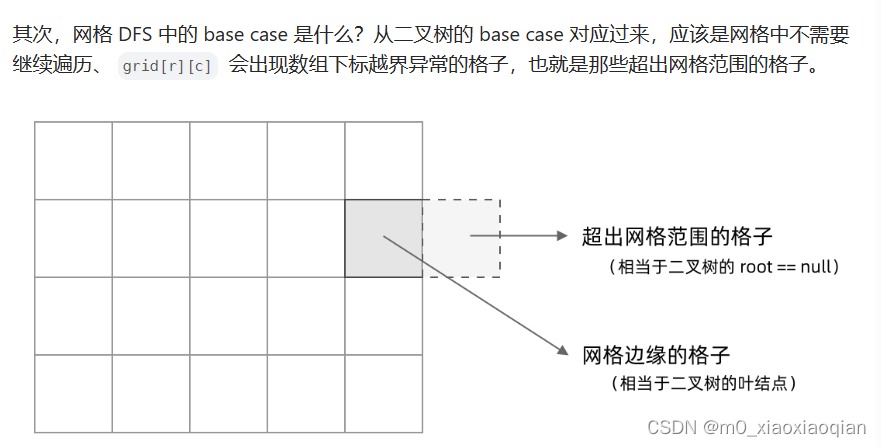
作者:来自 Elastic Tom Grabowski, Akhilesh Pokhariyal

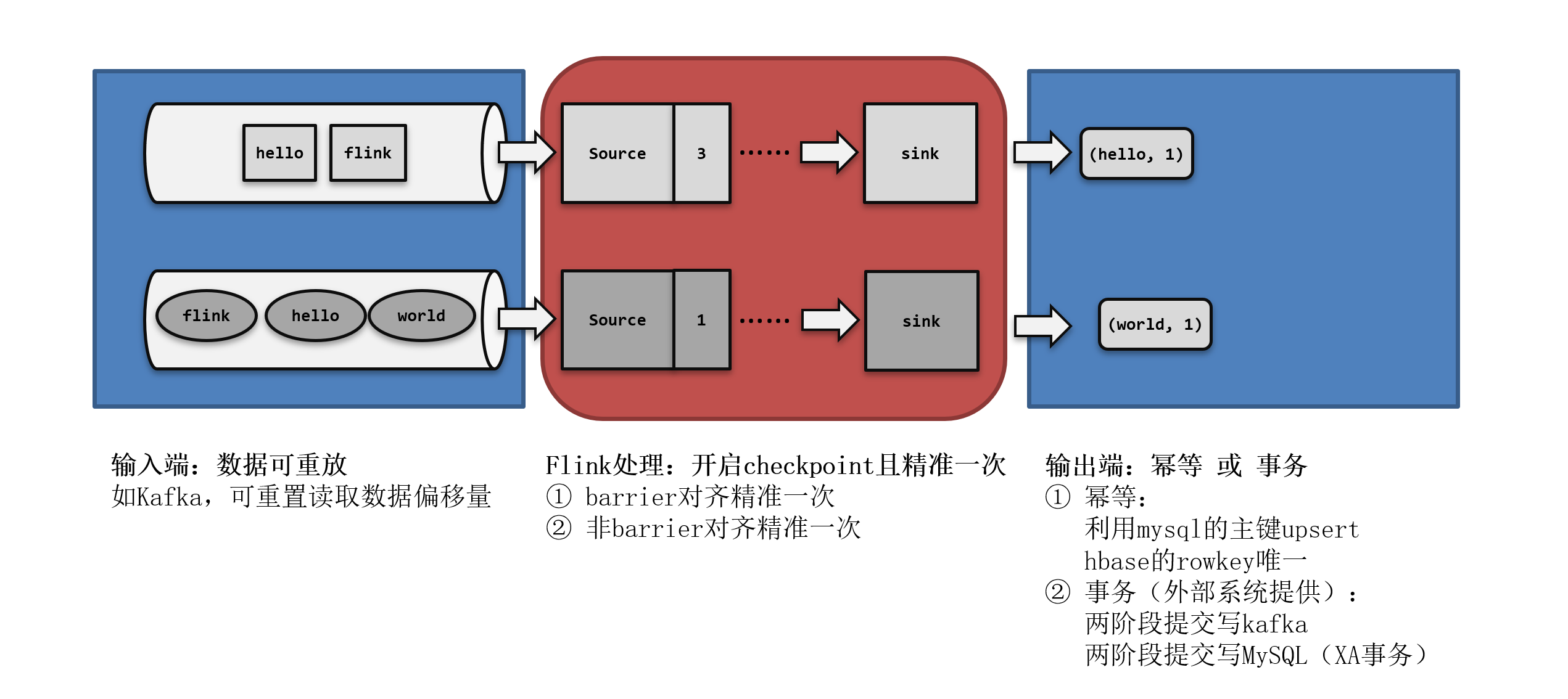
Elastic® Observability 8.12 宣布 AI Assistant 全面上市 (正式发布)、服务级别目标 (SLO) 和移动 APM 支持:
- 服务级别目标 (service level objective - SLO):现在正式发布版允许 SRE 通过跟踪服务性能、错误预算、可靠性和业务目标来监控和管理业务和运营 SLO。
- Observability AI Assistant:现已正式发布,使用户能够使用 RAG 从生成式 AI LLMs 和内部私人信息中获取上下文见解。
- 基于 OpenTelemetry 的移动 APM 支持:现已正式发布,允许监控 iOS 和 Android 本机应用程序,包括用于可视化服务相互依赖性、端到端跟踪瀑布 (waterfall)、错误和崩溃分析的预构建仪表板。
Elastic Observability 8.12 现已在 Elastic Cloud 上推出,这是唯一包含最新版本中所有新功能的托管 Elasticsearch® 产品。 你还可以下载 Elastic Stack 和我们的云编排产品 Elastic Cloud Enterprise 和 Elastic Cloud for Kubernetes,以获得自我管理的体验。
Elastic 8.12 中还有哪些新功能? 查看 8.12 公告帖子了解更多>>
服务级别目标 ( service level objectives - SLO)
服务级别目标 (SLO) 已从测试版更新正式版。它适用于我们的白金级和企业级订阅客户。 作为常规版本的一部分,SLO 功能为我们的 SRE 和 DevOps 用户添加了多项更新。
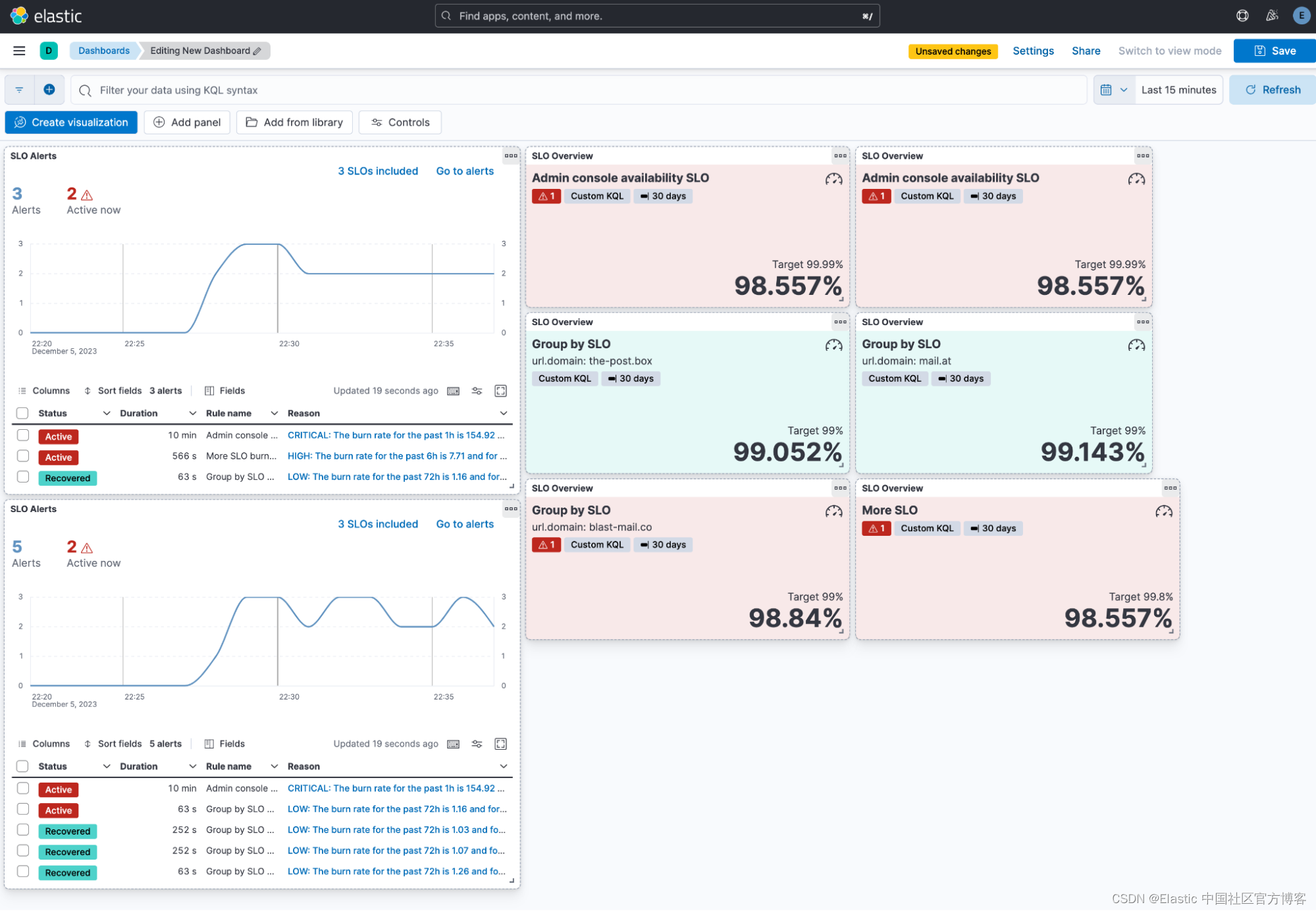
为了更轻松地监控大量 SLO,用户现在可以在 SLO 概述页面上拥有多个查看选项。 现在提供卡片视图和表格视图的新选项。
SLO gif
我们知道许多用户喜欢将他们的 SLO 概述可视化添加到他们的自定义仪表板中。 现在,可以更轻松地在 SLO 详细信息页面中添加 SLO 概述,但你还可以添加警报可视化来查看与仪表板中的特定 SLO 相关的任何消耗率 (burn rate) 警报。 如果用户想要查看其 SLO 警报的摘要和列表,可以添加新的 SLO 警报小部件。 他们可以选择多个 SLO、编辑配置以及与警报小部件交互。
SLO 详细信息页面上有一个新图表,显示过去 24 小时内发生的好事件与坏事件,以便在违反 SLO 时更快地进行调查。

对于 SLO 消耗率 (burn rate) 警报,有一种新方法可以根据消耗的预算金额定义消耗率窗口。 这将允许 SRE 定义他们在收到警报之前愿意花费多少预算。 有一个选项可以使用窗口定义下方的切换按钮在 “burn rate mode” 和 “budget consumed mode” 之间切换。 还有帮助文本可查看为时间窗口定义的预算的燃烧率,以及新的相应帮助文本可显示在 “burn rate mode” 下定义窗口时将消耗多少预算。
8-12-observability-gif-2
在 v8.12 中,SLO 还为时间片指标提供了新的服务级别指示器 (service level indicator - SLI)。 这个新的 SLI 可用于统计聚合,允许使用 avg、max、min、sum、std_devation、last_value、percentile 和 doc_count 等聚合以及自定义方程和阈值。 由于这些聚合是基于窗口大小的,因此它们将根据时间片预算方法进行计算。
使用内部知识库训练你的 AI 助手
Elastic 的可观察性 AI 助手已从技术预览版升级为 v8.12 中的企业客户正式版。 AI 助手现在配备了一个集成知识库,供组织链接其应用程序文档,以训练 AI 助手对可观测性数据的响应。
知识库允许用户将文档添加到 Elasticsearch 索引中,然后助手可以在与用户交互时调用这些文档,以改进对用户查询的推理。 这使得人工智能助手能够将警报与根本原因故障排除指南、错误消息及其含义的上下文、以及它们所依赖的进程或如何优化它们链接起来。
8-12-observability-gif-3
在 8.12 中,我们在堆栈管理中为助手添加了专用的设置页面,其中包括用于管理知识库内容的 UI。 这使管理员能够轻松查看知识库的内容、添加单个条目、通过文件导入多个条目以及编辑和删除条目。
此外,人工智能助手在每次用户提示时都会使用知识库 —— 以前这种情况只发生在对话中的第一个用户提示上。 为了减少噪音和降低 token 使用量,v8.12 还包括一个步骤,其中 LLM 最初对文档的相关性进行评分,并且仅在要求 LLM 回答用户的请求时才包含相关文档。
移动应用性能管理(APM)
对 iOS 和 Android 本机应用程序的移动 APM 支持现已正式发布。 除了数据收集方面的多项增强功能外,该解决方案还包括预构建的仪表板,用于查看服务相互依赖性和端到端跟踪瀑布,并用于探索应用程序版本、操作系统版本、设备品牌/型号和地理位置对性能的影响, 错误和崩溃分析。
在如下所示的服务概览仪表板上,用户可以看到崩溃率、http 请求、平均应用加载时间等 KPI,包括比较视图。

此外,用户流量的地理分布可在国家和地区级别的地图上获得。 服务概览仪表板还显示吞吐量、延迟和失败事务率等指标的趋势。
下面显示的 transactions 仪表板突出显示了不同事务组的性能,包括单个事务的跟踪瀑布以及与相关错误和崩溃的链接。 此外,用户可以一目了然地看到按设备品牌和型号、应用程序版本和操作系统版本划分的流量分布情况。
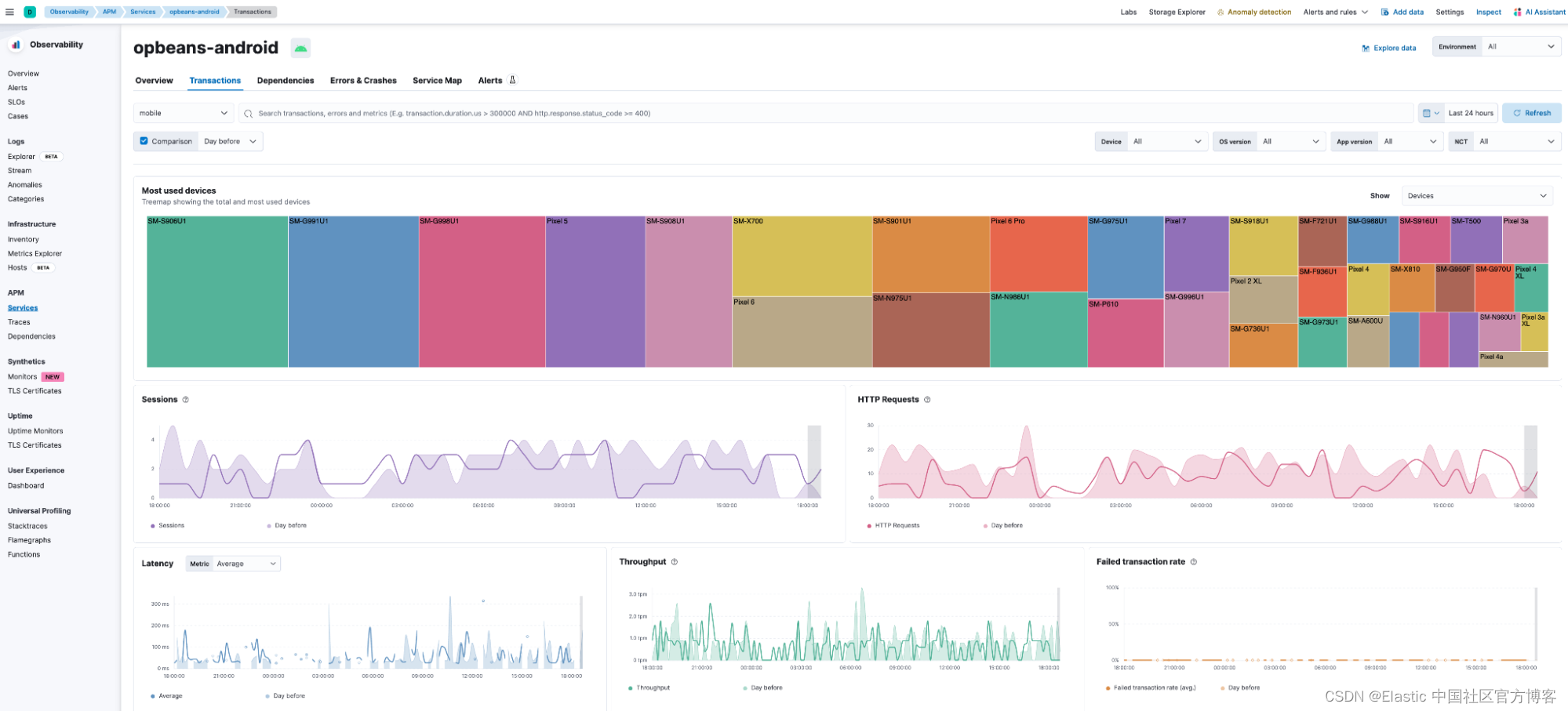
用户还可以查看设备制造商和型号如何影响延迟和崩溃率。

下面显示的 Errors & Crashes 仪表板可用于分析不同的错误和崩溃组,以及查看各个错误或崩溃实例的堆栈跟踪。 在此版本中,用户将不得不依赖其他工具来对堆栈跟踪进行反混淆 (Android) 或符号化 (iOS)。

下面显示的 Service Map 仪表板可用于可视化端到端服务的相互依赖性。
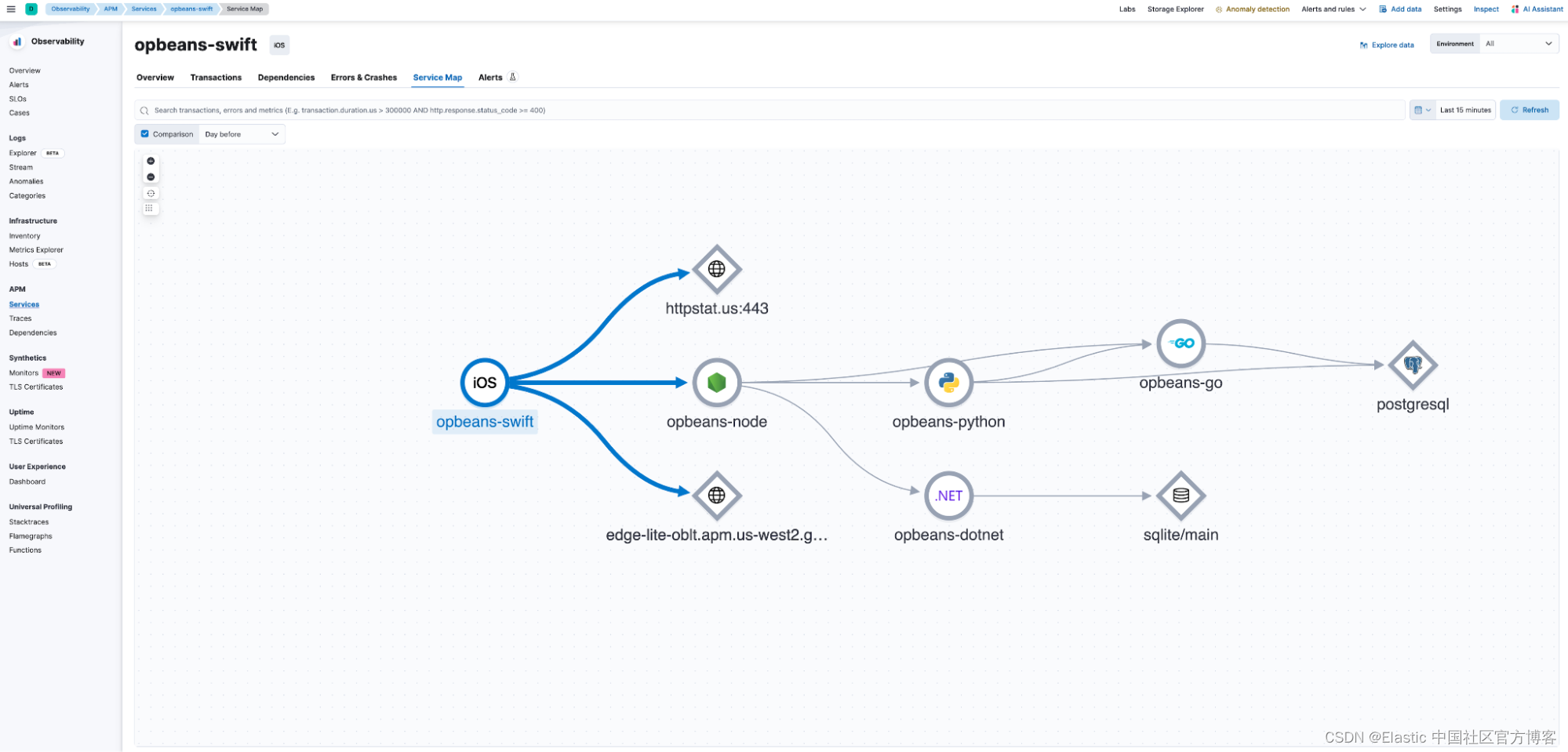
全面的预构建仪表板为 SRE 和开发人员提供了错误来源和瓶颈的可见性,从而缩短了 MTTR 并促进了高创新速度。
试试看
请阅读发行说明中了解这些功能以及更多信息。
现有 Elastic Cloud 客户可以直接从 Elastic Cloud 控制台访问其中许多功能。 没有利用云上的 Elastic? 开始免费试用。
本文中描述的任何特性或功能的发布和时间安排均由 Elastic 自行决定。 当前不可用的任何特性或功能可能无法按时交付或根本无法交付。
原文:Elastic Observability 8.12: GA for AI Assistant, SLO, and Mobile APM support | Elastic Blog