XTuner 大模型单卡低成本微调实战

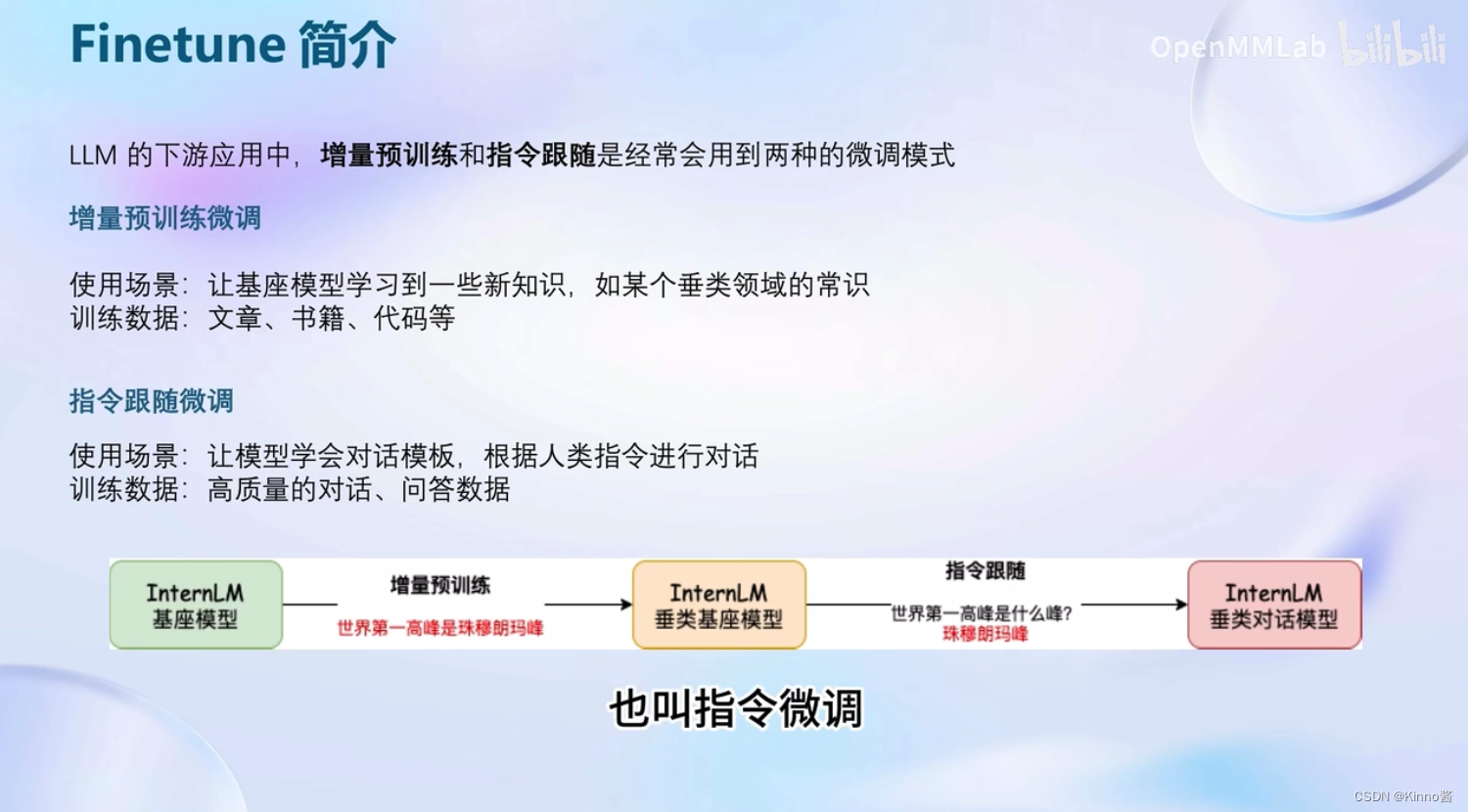
Finetune简介
常见的两种微调策略:增量预训练、指令跟随
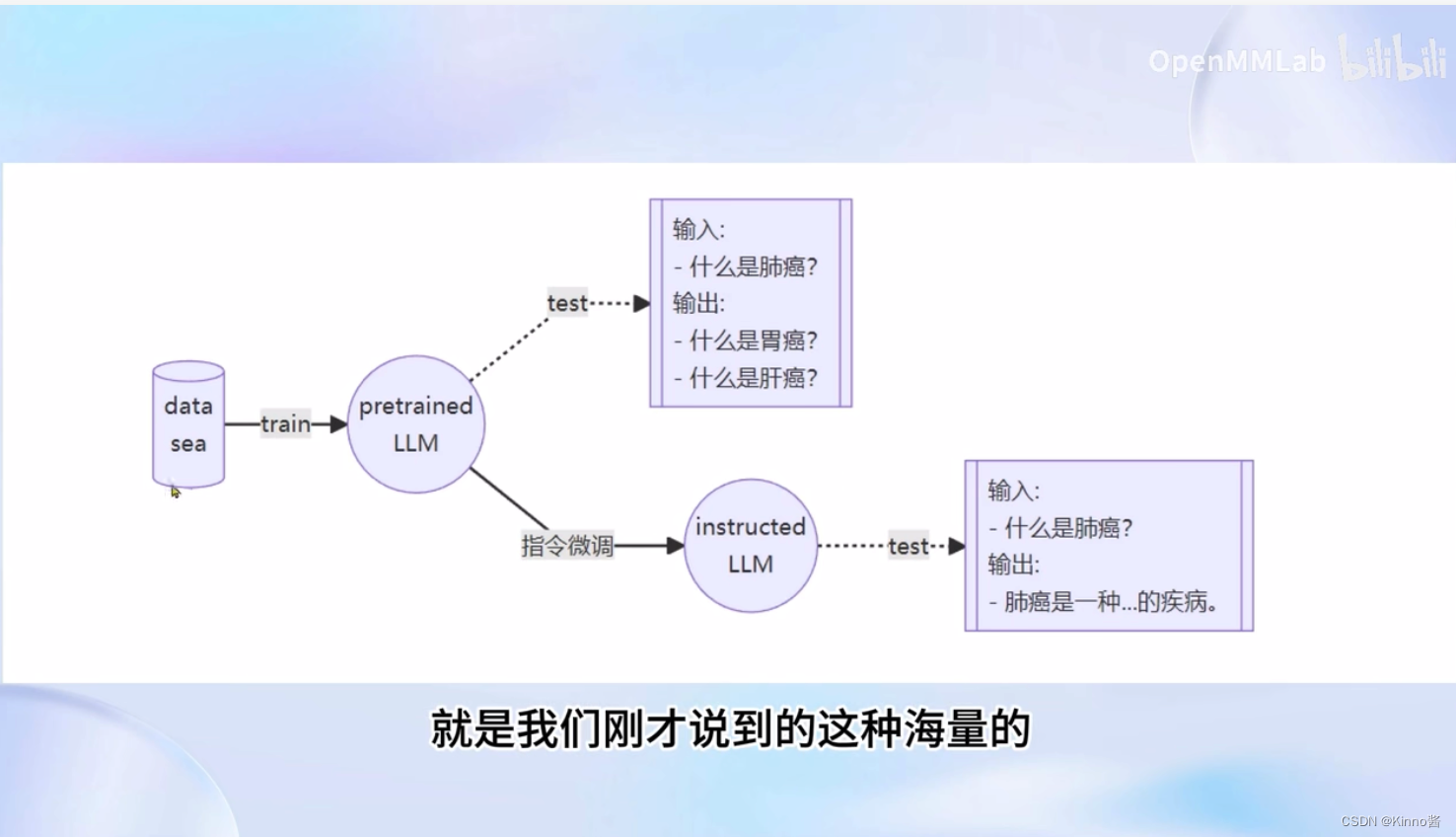
指令跟随微调
数据是一问一答的形式
对话模板构建
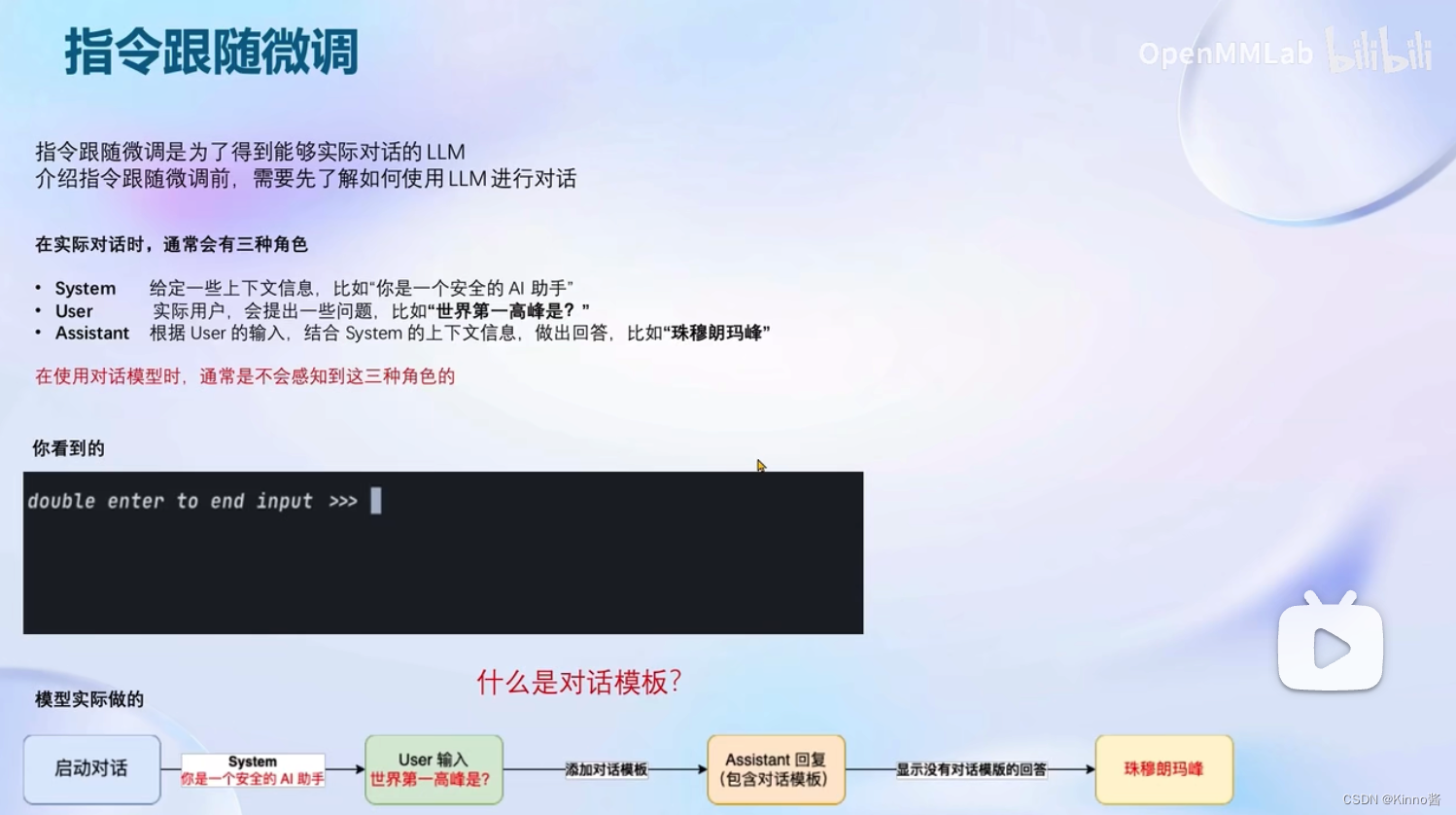
每个开源模型使用的对话模板都不相同
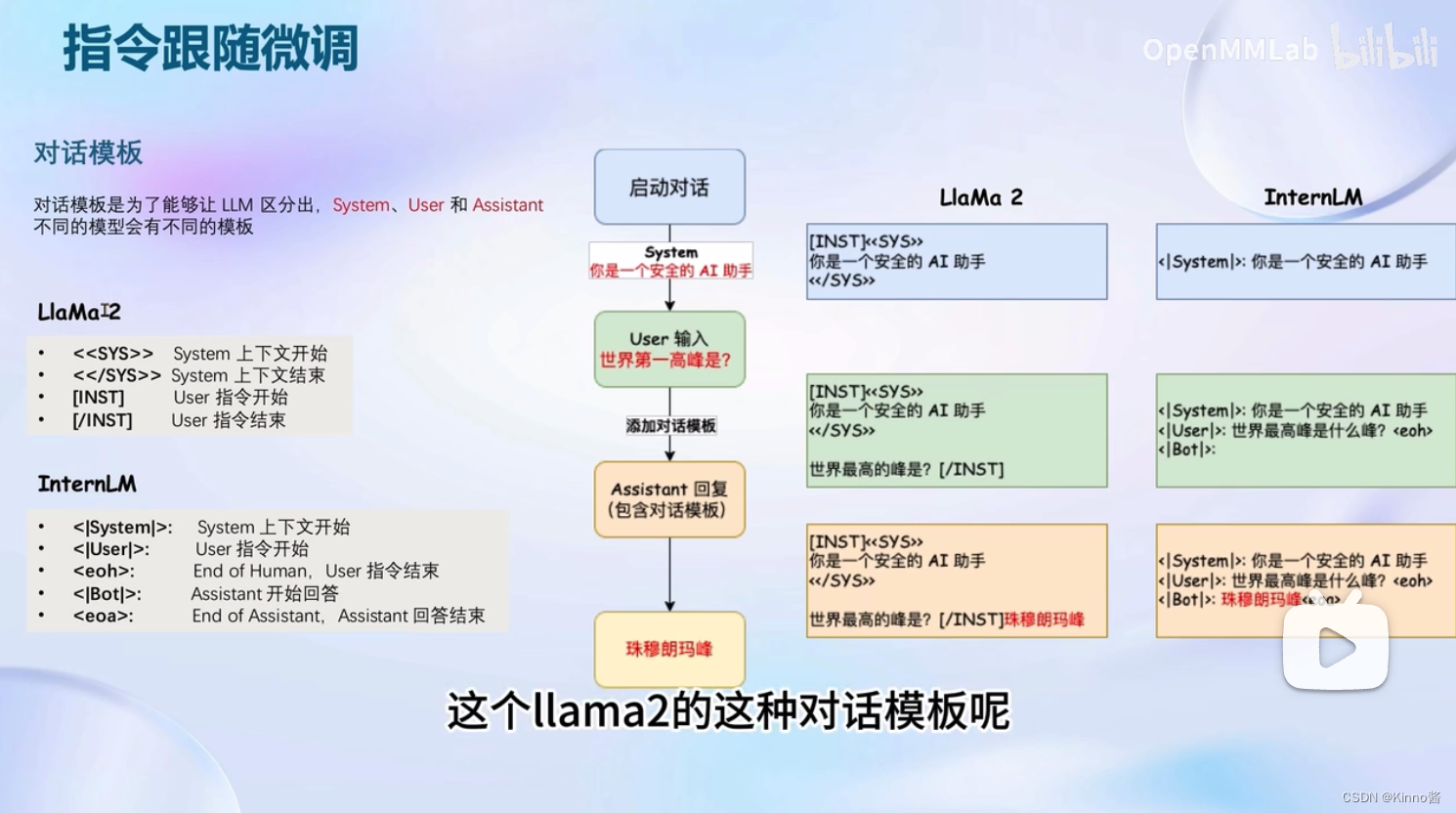
指令微调原理:
由于只有答案部分是我们期望模型来进行回答的内容,所以我们只对答案部分进行损失的计算

增量预训练微调
数据都是陈述句,没有问答形式


LoRA & QLoRA
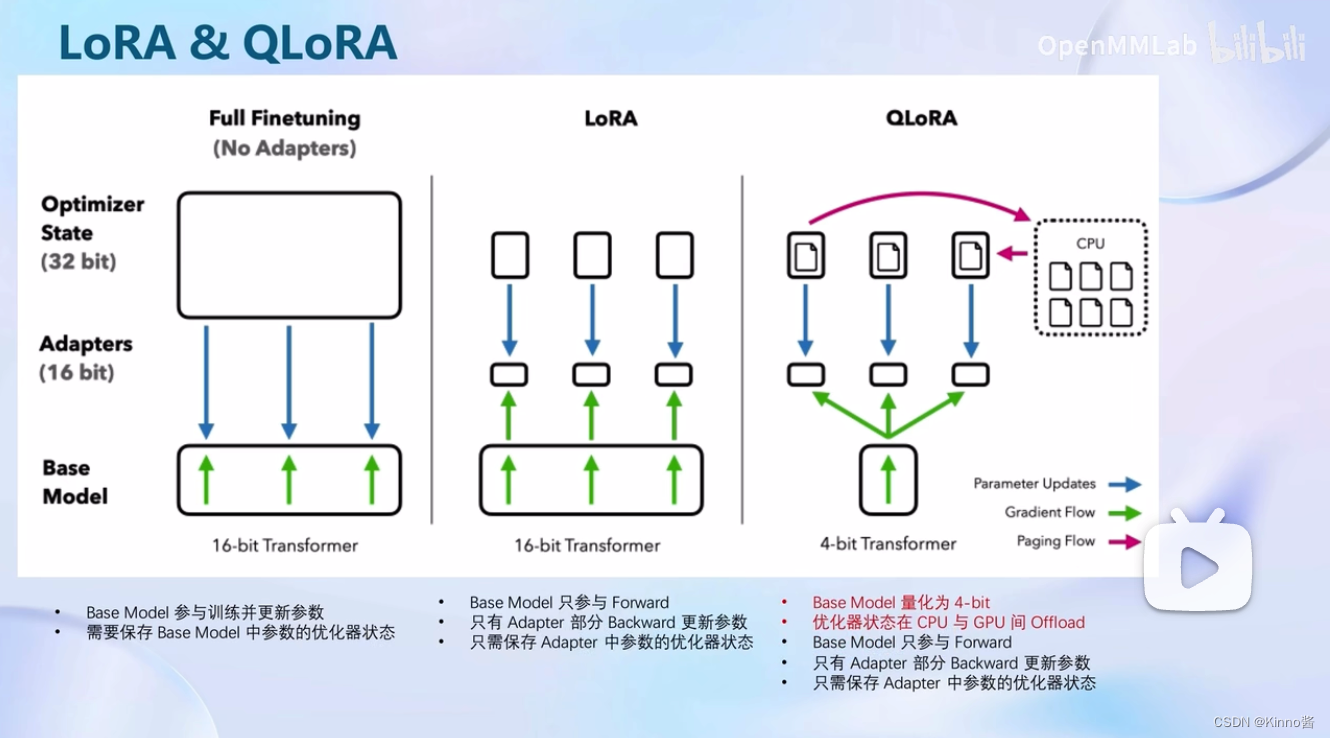
XTuner中使用的微调原理:LoRA & QLoRA
如果我们要对整个模型的所有参数都进行调整的话,需要非常大的显存才能够进行训练,但是用LoRA的方法就不需要这么大的显存开销了
LoRA: Low-Rank Adaptation

比较:全参数微调、LoRA、QLoRA
全参数微调:整个模型都要加载到显存中,所有模型参数的优化器也都要加载到显存中,显存不够根本无法进行。
LoRA:模型也是要先加载到显存中,但是我们只需要保存LoRA部分的参数优化器,大大减小了显存占用。
QLoRA:加载模型时就使用4bit量化的方式加载(相当于不那么精确的加载),但是可以节省显存开销,QLoRA部分的参数优化器,还可以在GPU和CPU之间进行调度【这是Xtunner进行整合的功能 】,显存满了就自动去内存中去跑。
XTuner介绍

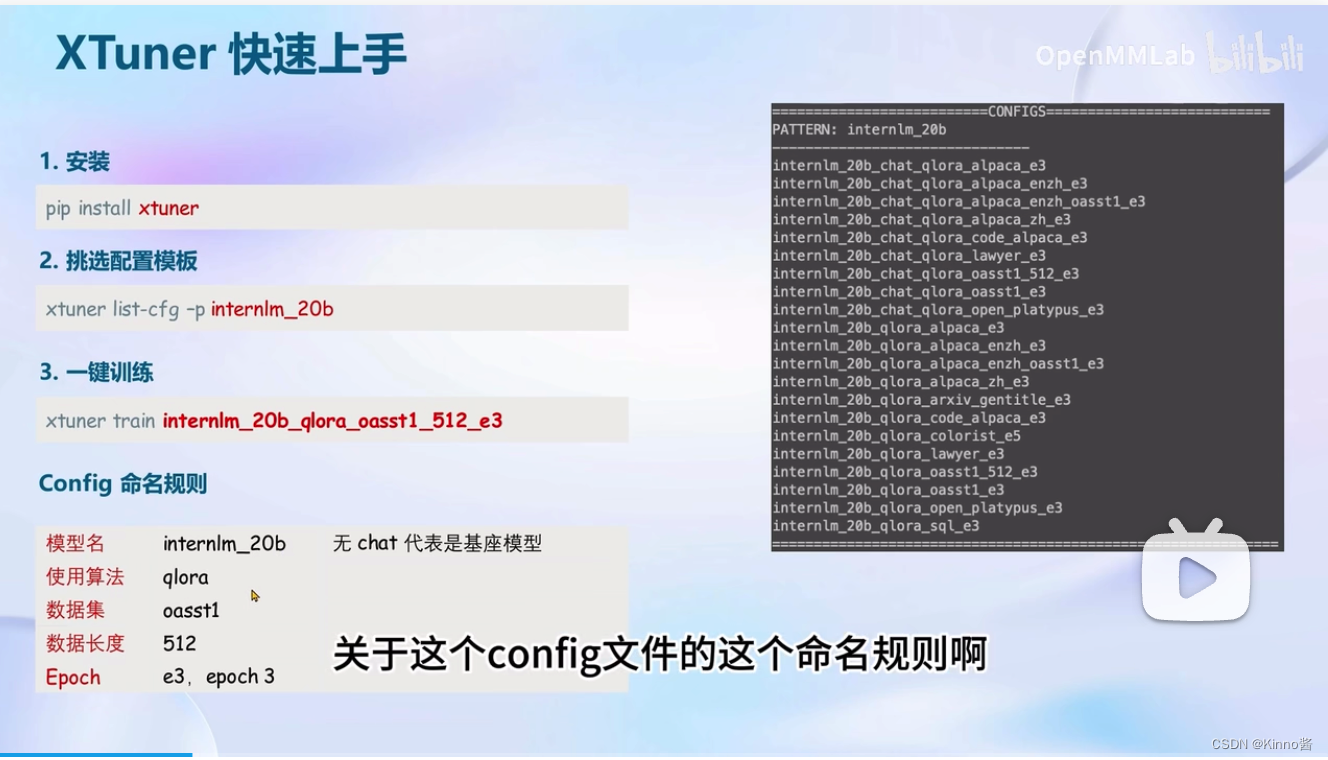
XTuner快速上手
- 安装
pip install xtuner
- 挑选配置模版
xtuner list-cfg -p internlm_20b
- 一键训练
xtuner train internlm_20b_qlora_oasst1_512_e3
- Config 命名规则
| 模型名 | internlm_20b ( 无 chat 代表是基座模型 ) |
| 使用算法 | qlora |
| 数据集 | oasst1 |
| 数据长度 | 512 |
| Epoch | e3, epoch 3 |
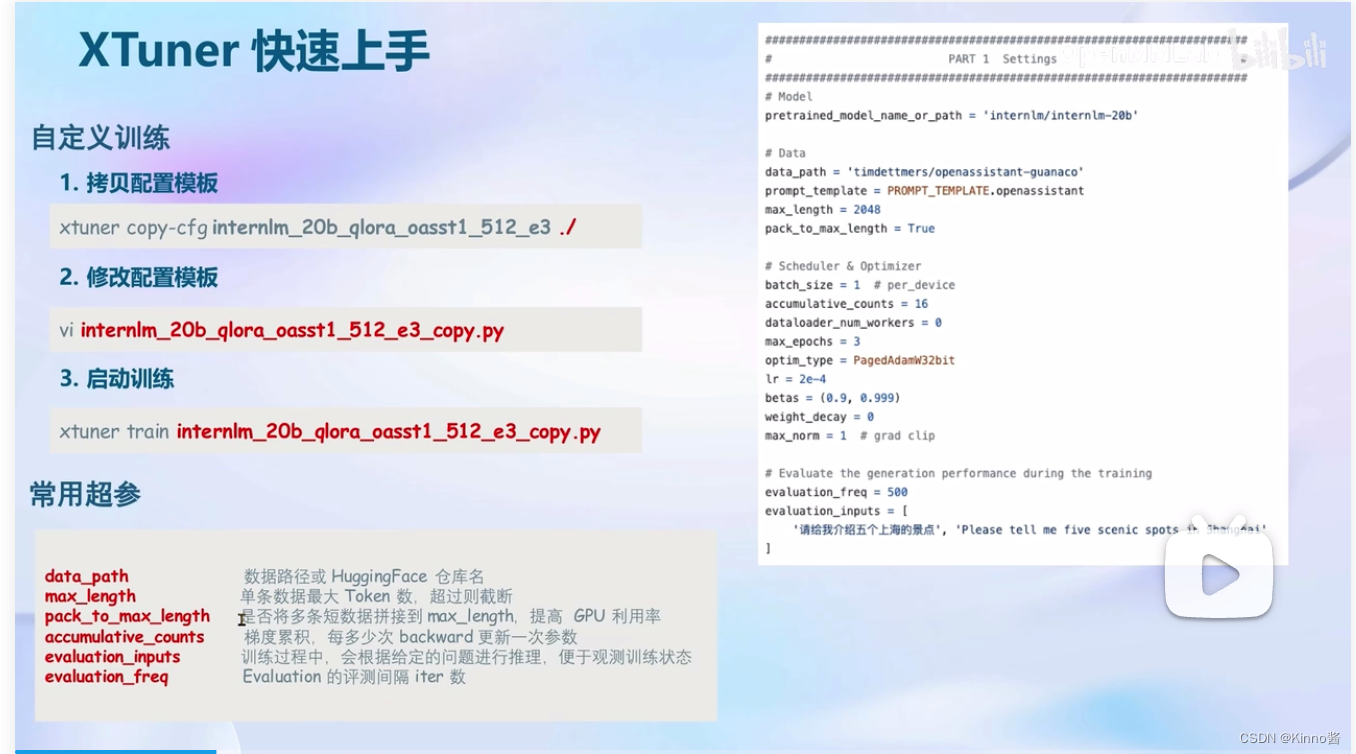
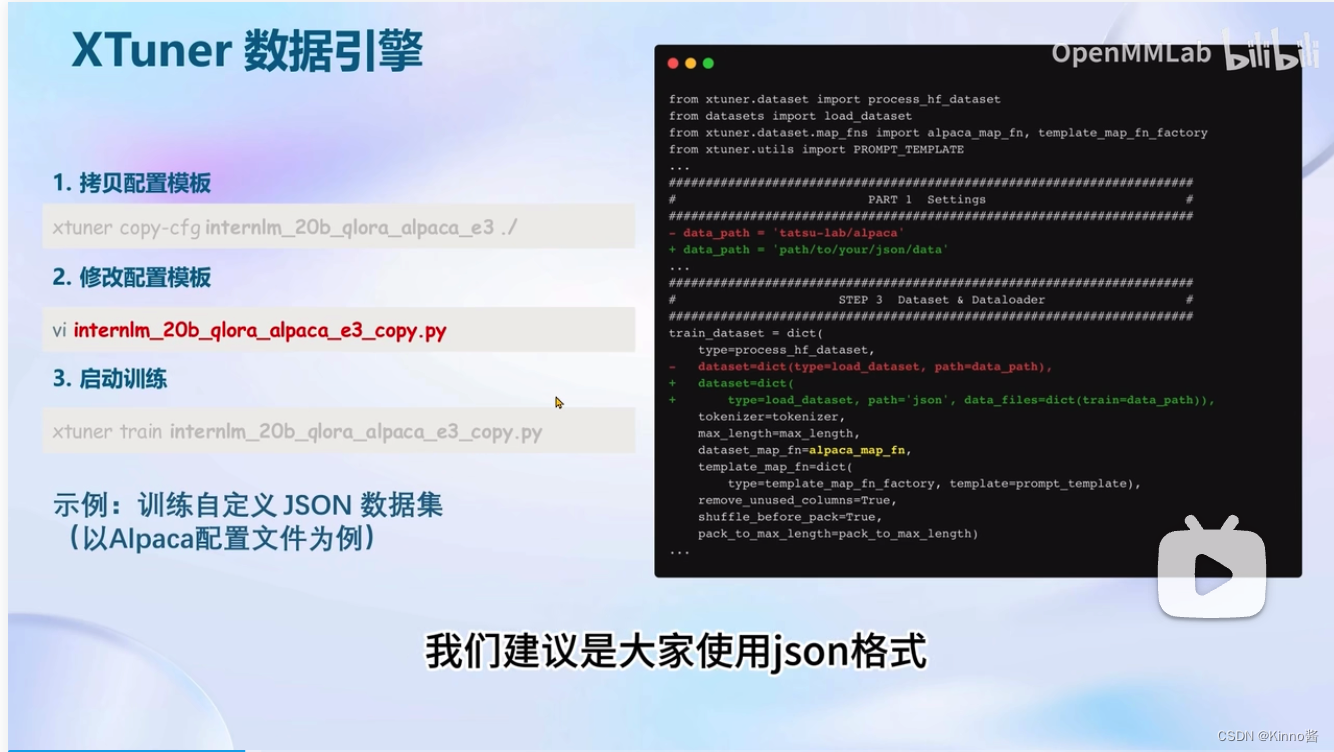
自定义训练(微调):
- 拷贝配置模板
- 修改配置文件
- 启动训练
- 配置模板中的常用超参数
对话:
训练完成后得到了Adapter文件(LoRA文件),我们就需要在加载底座模型的基础上,同时加载这个Adapter,来进行模型的对话与测试。 - Float 16模型对话
- 4bit量化模式模型对话
- 加载Adapter模型对话

XTuner还支持工具类模型的对话,类似于GPT里面的plugin

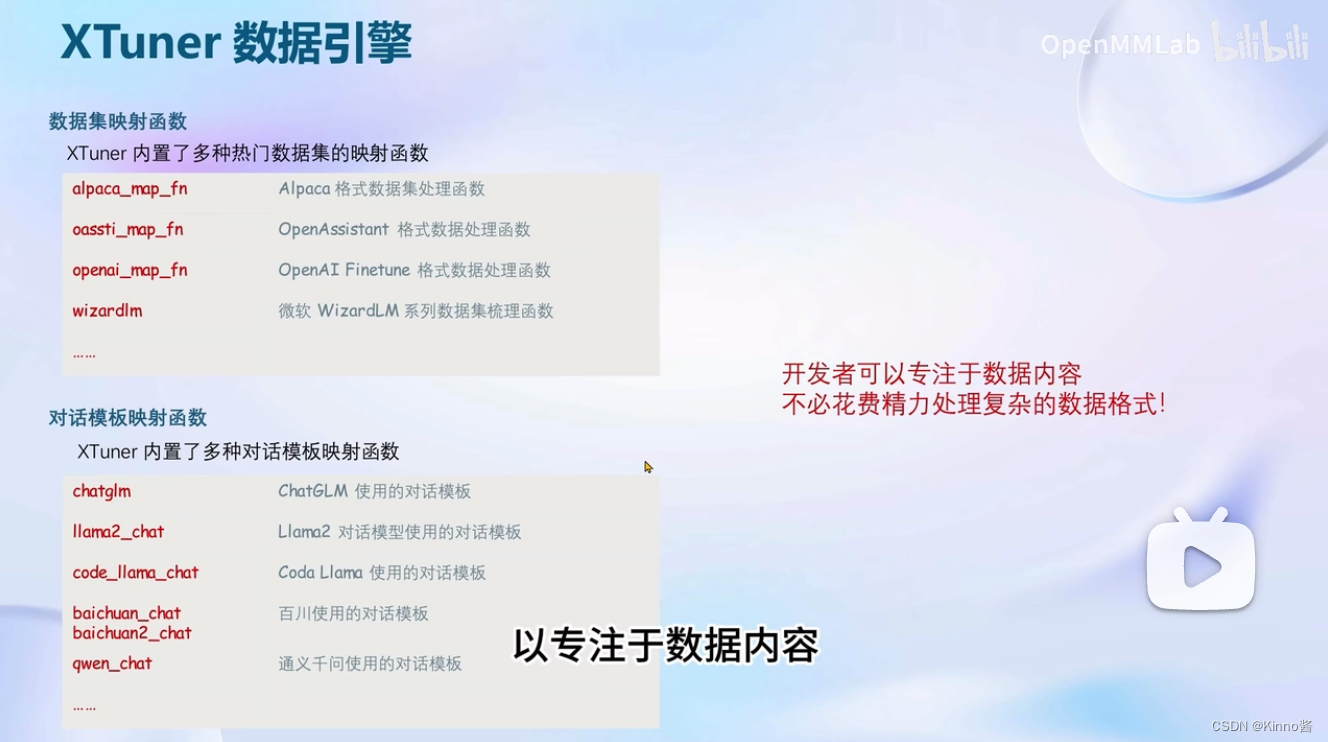
XTunner具有强大的数据处理引擎,对于这种格式化的问答对,进行了统一的数据指定。对于开源数据集进行了映射函数的内置,可以方便的在很多流行的开源数据集上进行一键启动。
这样开发者可以专注于数据内容,不必花费精力处理复杂的数据格式。

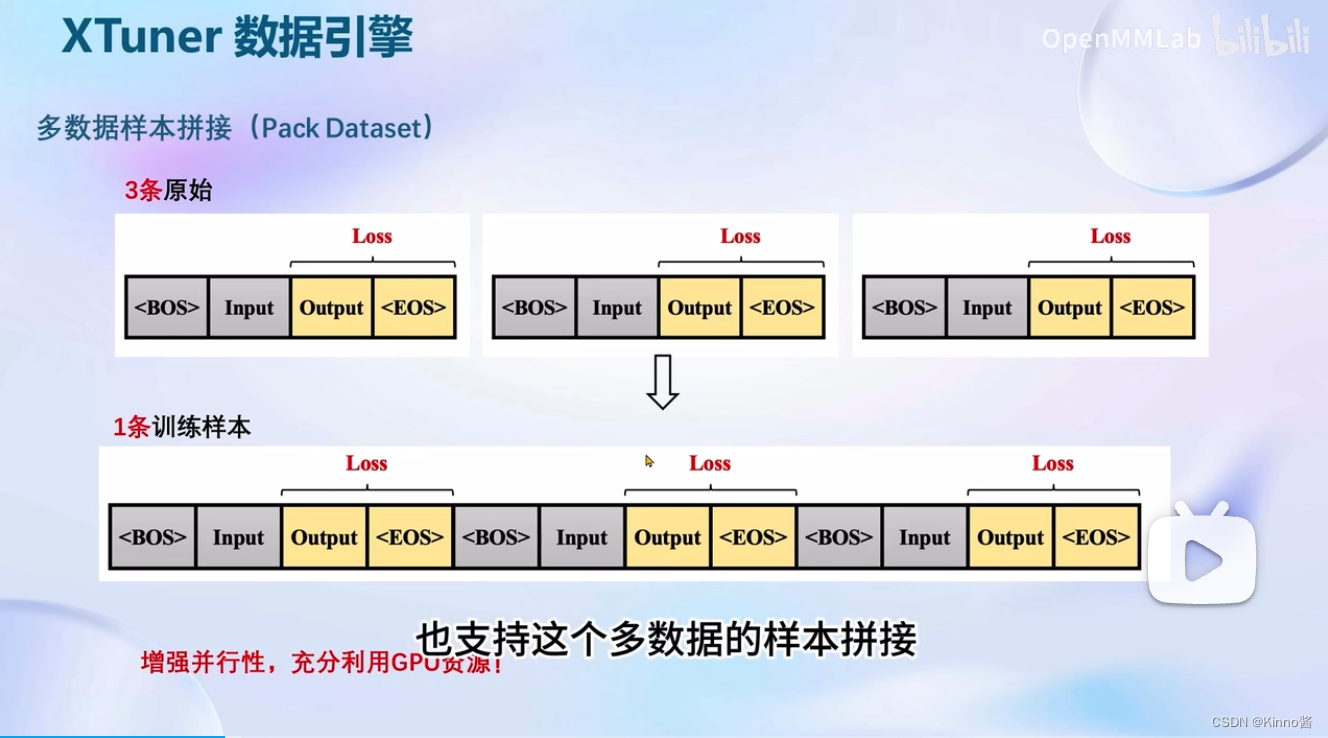
XTunner支持多数据的样本拼接,如果使用XTunner的默认配置,它只需要6GB或者8GB的显存消耗。如果有更大显存的显卡,为了利用更大显存,就需要增加运行效率,进行多数据样本拼接,将多条数据拼接到一起后,输入模型,然后统一的进行梯度的传播,增加并行性,充分利用GPU资源。
自定义数据集建议使用json格式
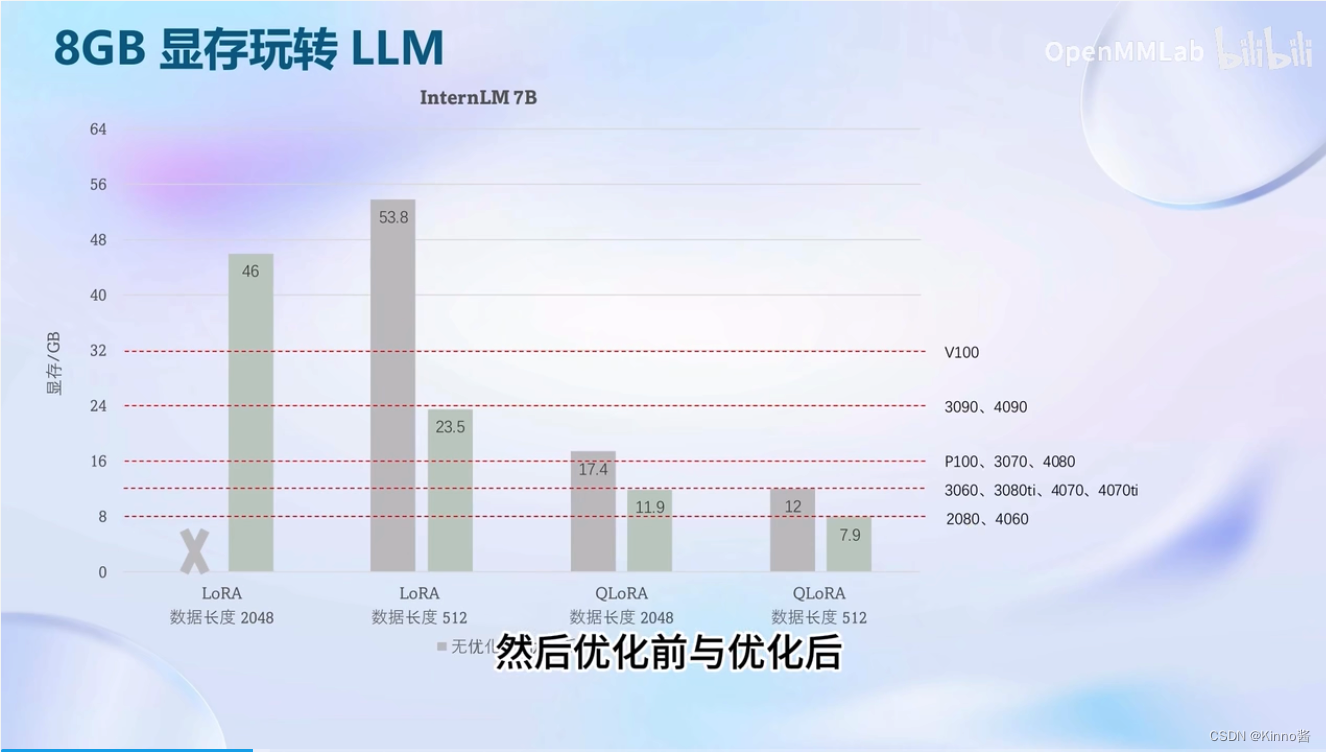
8GB显卡玩转LLM
XTuner默认开启了Flash Attention的加速方式,可以加速训练,同时也集成了deepspeed_zero的优化方法,也可以在训练在训练的过程中更快。
deep speed不是默认启动的
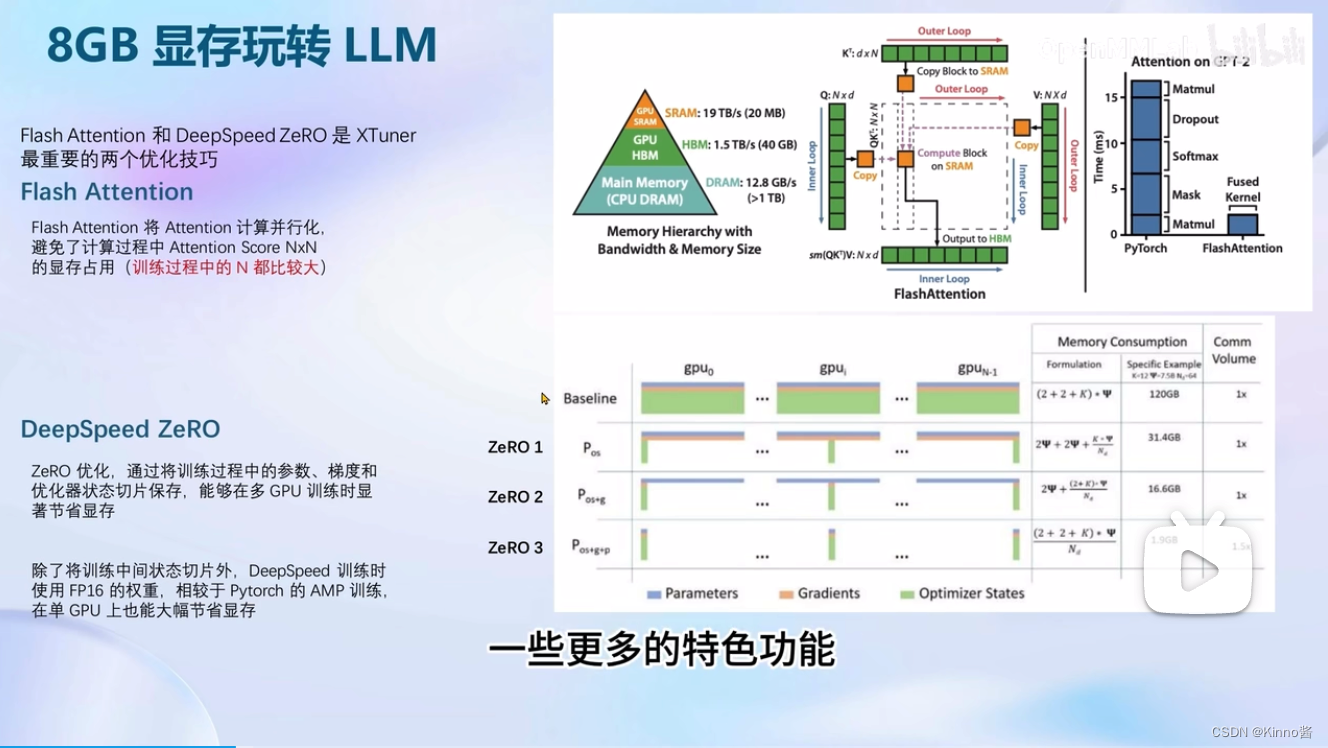

优化前优化后,不同计算卡上的显存占用情况
动手实战环节
https://github.com/InternLM/tutorial/blob/main/xtuner/README.md