目录
设置中文
配置调试功能
提效和增强相关插件
主题和图标相关插件
创建js文件
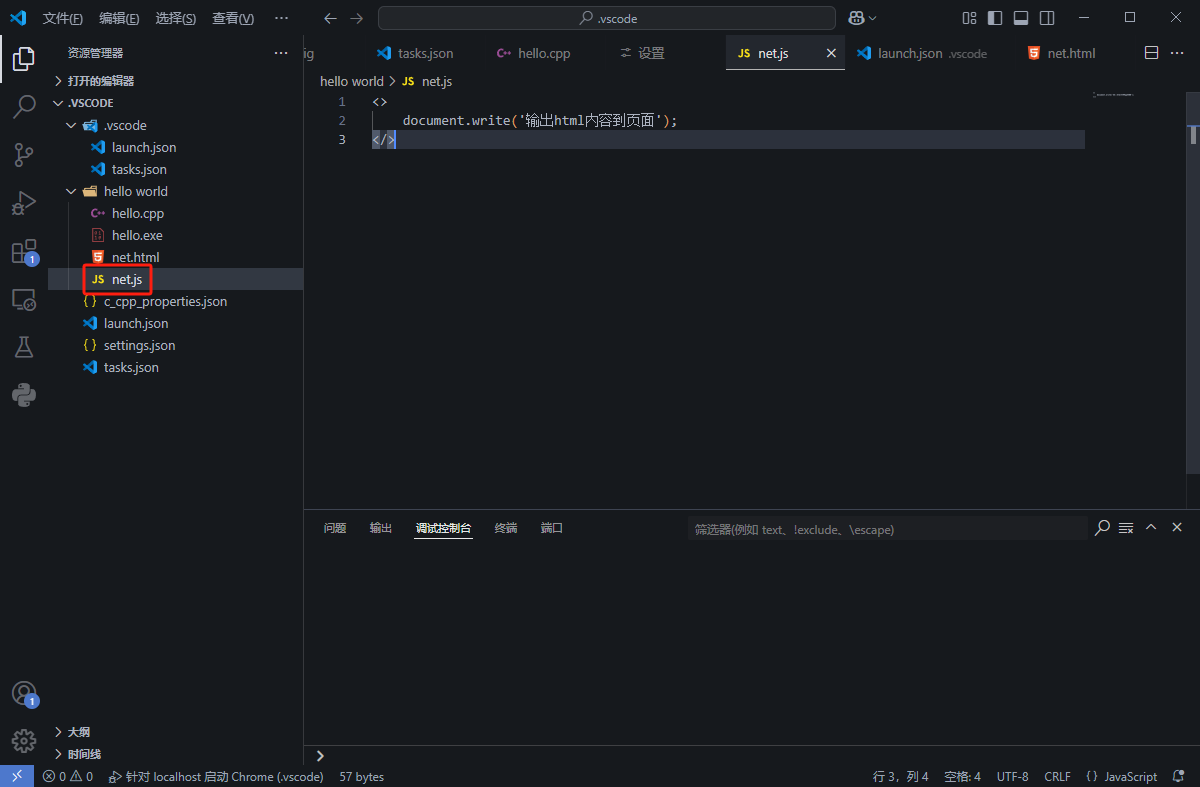
设置中文
打开【拓展】
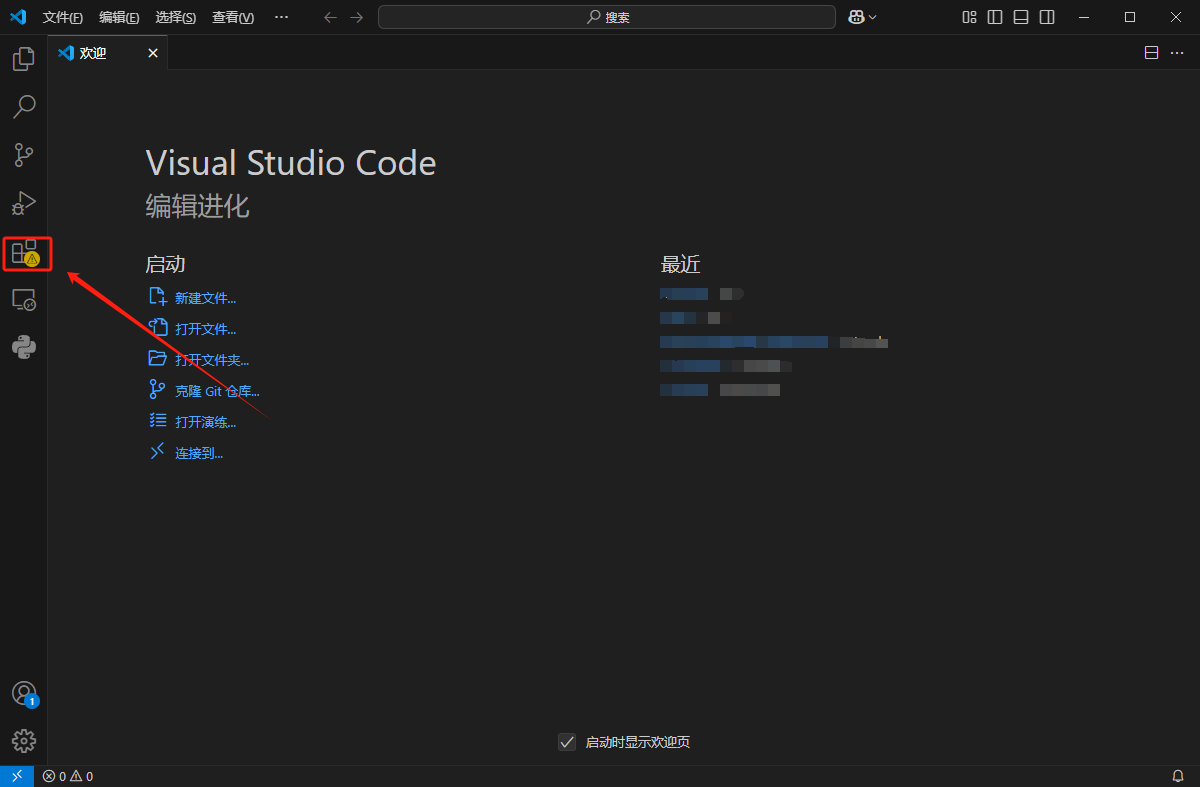
输入【Chinese】

下载完成后重启Vs即可变为中文
配置调试功能
在随便一个位置新建一个文件夹,用于放置调试文件以及你未来写的代码,随便命名但切记不可用中文!!!
然后进入VSCode,点击Open Folder或者点击左上角File -> Open Folder,然后打开刚刚建的文件夹,选择信任父级文件夹。
点击这个图标新建一个文件夹,命名为.vscode(注意必须是这个名字!)
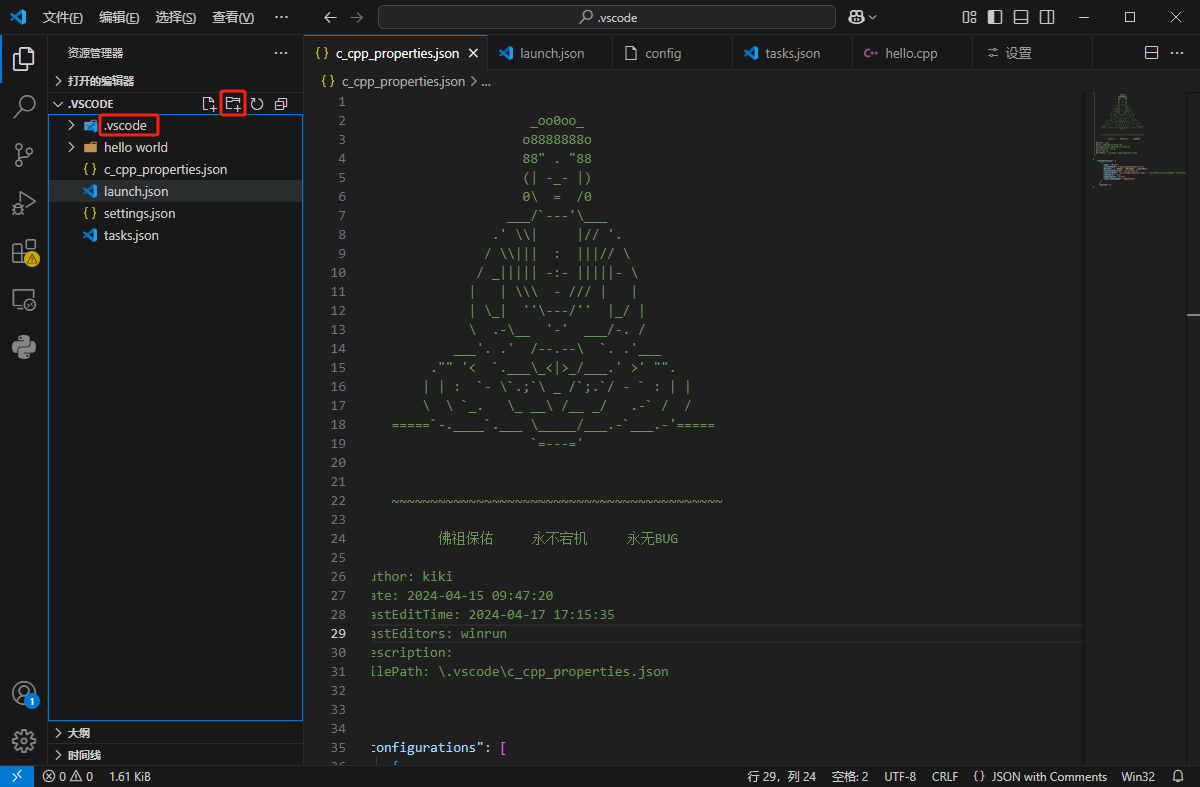
创建完成后再点击这个图标新建四个文件,文件名分别是
//c_cpp_properties.json
//launch.json
//settings.json
//tasks.json接下来复制粘贴这四个文件的内容
//c_cpp_properties.json{"configurations": [{"name": "Win64","includePath": ["${workspaceFolder}/**"],"defines": ["_DEBUG", "UNICODE", "_UNICODE"],"windowsSdkVersion": "10.0.18362.0","compilerPath": "C:/MinGW/bin/g++.exe","cStandard": "c17","cppStandard": "c++17","intelliSenseMode": "gcc-x64"}],"version": 4
}注意compilerPath这一项要把路径改成刚才g++的安装路径:找到刚刚的安装文件夹->MinGW->bin->g++,exe ,然后复制或者手动把g++.exe的路径敲上去,格式要跟上面代码段一样
launch.json
//launch.json{"version": "0.2.0","configurations": [{"name": "(gdb) Launch", "type": "cppdbg", "request": "launch", "program": "${fileDirname}\\${fileBasenameNoExtension}.exe", "args": [], "stopAtEntry": false,"cwd": "${workspaceRoot}","environment": [],"externalConsole": true, "MIMode": "gdb","miDebuggerPath": "C:\\MinGW\\bin\\gdb.exe","preLaunchTask": "g++","setupCommands": [{"description": "Enable pretty-printing for gdb","text": "-enable-pretty-printing","ignoreFailures": true}]}]
}settings.json
{"files.associations": {"*.py": "python","iostream": "cpp","*.tcc": "cpp","string": "cpp","unordered_map": "cpp","vector": "cpp","ostream": "cpp","new": "cpp","typeinfo": "cpp","deque": "cpp","initializer_list": "cpp","iosfwd": "cpp","fstream": "cpp","sstream": "cpp","map": "c","stdio.h": "c","algorithm": "cpp","atomic": "cpp","bit": "cpp","cctype": "cpp","clocale": "cpp","cmath": "cpp","compare": "cpp","concepts": "cpp","cstddef": "cpp","cstdint": "cpp","cstdio": "cpp","cstdlib": "cpp","cstring": "cpp","ctime": "cpp","cwchar": "cpp","exception": "cpp","ios": "cpp","istream": "cpp","iterator": "cpp","limits": "cpp","memory": "cpp","random": "cpp","set": "cpp","stack": "cpp","stdexcept": "cpp","streambuf": "cpp","system_error": "cpp","tuple": "cpp","type_traits": "cpp","utility": "cpp","xfacet": "cpp","xiosbase": "cpp","xlocale": "cpp","xlocinfo": "cpp","xlocnum": "cpp","xmemory": "cpp","xstddef": "cpp","xstring": "cpp","xtr1common": "cpp","xtree": "cpp","xutility": "cpp","stdlib.h": "c","string.h": "c"},"editor.suggest.snippetsPreventQuickSuggestions": false,"aiXcoder.showTrayIcon": true
}tasks.json
{"version": "2.0.0","tasks": [{"label": "g++","command": "g++","args": ["-g","${file}","-o","${fileDirname}/${fileBasenameNoExtension}.exe"],"problemMatcher": {"owner": "cpp","fileLocation": ["relative", "${workspaceRoot}"],"pattern": {"regexp": "^(.*):(\\d+):(\\d+):\\s+(warning|error):\\s+(.*)$","file": 1,"line": 2,"column": 3,"severity": 4,"message": 5}},"group": {"kind": "build","isDefault": true}}]
}保存这四个文件就配置完成了!
再次强调:以后的C/C++代码文件必须放在这个Code文件夹里,或者说有.vscode文件夹的文件夹里,如果调试放在其他位置的代码文件会报错!
提效和增强相关插件
Auto Rename Tag
该插件帮助我们在重命名一个标签时,自动重命名 HTML 标签的开始和结束标签。避免只修改了开始标签,而忘记修改结束标签。该扩展适用于 HTML、XML、PHP 和 JavaScript。
Alignment
Alignment 是一个非常实用的 VSCode 插件,它可以帮助你快速对齐代码中的各种元素,使用 Alignment 非常简单,只需要在 VSCode 中按下 Ctrl + Shift + P,然后输入“Alignment”即可查看插件的所有命令和快捷键。比如,你可以选择几行代码,然后按下 Alt + A 快捷键,就可以自动对齐选中的代码。
Error Lens
这是一款非常实用的 VSCode 插件,它可以在编辑器中直接显示代码中的语法错误、warning以及其他问题,让开发者更加方便地发现和解决代码问题。
使用 Error Lens 非常简单,只需在 VSCode 中搜索并安装该插件即可。安装完成后,打开一个代码文件,如果该文件中有语法错误、warning或其他问题,Error Lens 就会直接在编辑器中显示相应的提示和解决方案。
此外,Error Lens 还支持许多其他的功能,比如
- 支持在代码中直接显示错误的具体信息,如错误类型、位置等。
- 支持定位并跳转到代码中出现问题的位置。
- 支持配置插件的提醒方式、颜色、样式等,使其更符合你的编码习惯
主题和图标相关插件
One Dark Pro
该插件的设计灵感源自于 Atom 编辑器的 One Dark 主题,因此它具有相似的外观和感觉。One Dark Pro 主题为用户提供了易于阅读的代码高亮显示和舒适的身心体验,且很多选项支持自定义。