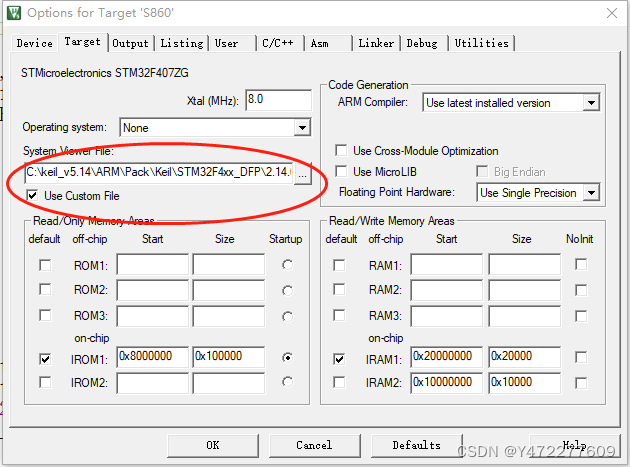
导读:
2023 和鲸社区年度科研闭门会以“对话 AI for Science 先行者,如何抓住科研范式新机遇”为主题,邀请了多个领域的专家学者共同探讨人工智能在各自领域的发展现状与未来趋势。
在脑科学领域,数字化大脑通过数学模型和计算机仿真对大脑进行精确的建模和重构,可以更好地理解和探索大脑的神经活动和功能。
以《BrainPy:迈向数字化大脑的计算基础设施》为题,来自北京大学心理与认知科学学院博士后王超名,介绍了为大尺度脑动力学建模提供计算基础设施的 BrainPy 项目,可弥补现有国内外软件存在的一系列问题,包括容纳最新的 AI 编译方法、兼容 AI 训练算法、提供独特的稀疏与事件驱动算子、多尺度建模范式、大尺度建模算法,帮助大脑研究者进行高效的大脑建模和模拟。
分享嘉宾|王超名
北京大学心理与认知科学学院博士后
北京大学博雅博士后,北京大学理学博士,研究领域为计算认知神经科学与大尺度脑仿真,合作导师为北京大学心理与认知科学学院吴思教授。开发的通用脑动力学编程框架 BrainPy,三年内下载量突破十万次,广泛应用于国内外脑动力学建模。研究成果近期发表于 eLife、frontiers 等杂志。荣获北京大学优秀毕业生、北京大学校长奖学金、国奖奖学金等荣誉。
本文内容已做精简,如需获取专家完整版视频实录及课件,请点此链接联系工作人员领取。
01 数字化大脑的进展与关键技术挑战
数字化大脑一直是全人类很重要的一个梦想。
假如能实现大脑数字化,人类就能去开展很多很重要的研究,比如可以基于虚拟大脑分析大脑认知功能的机理、进行个性化脑疾病的诊断或治疗,支持更 powerful 的类脑人工智能,或者推动脑机接口研究的发展。
我们自己认为,在未来的 5-10 年内,数字化大脑会迎来革命性的突破,主要原因就是数据的爆发式增长和技术的快速发展。
一方面,全球主要的经济体都在开展脑计划。比如 2005 年开始,瑞士洛桑理工学院的科学家 Henry Markman 推动了蓝脑计划,通过计算机重构仿真的方式去模拟大脑;后面欧洲、美国、日本都推出了他们自己的脑计划,并且都是重大投资;中国在 2021 年也推出了我们自己的脑计划。
随着脑计划的发展,我们在各个尺度都有很多数据的积累,包括像 Nature 、 Science 这种期刊也有一些专栏报道目前脑计划的进展。以现在最新的全脑连接组为例, 2019 年, Nature 上发表了一篇线虫连接组的文章,我们已经能够去拿到几百个神经元的全脑连接组;然后在今年,Science 上有关于果蝇全脑连接组的文章,已经能拿到十几万神经元的全脑的精细连接;像我们合作的实验室——上海神经所,他们也有斑马鱼全脑连接组,期望是在明年能够推出。另外,今年各个重要的 AI 机构或研究机构,像艾伦研究所、Google,都分别启动了小鼠或猕猴的脑连接图谱项目。
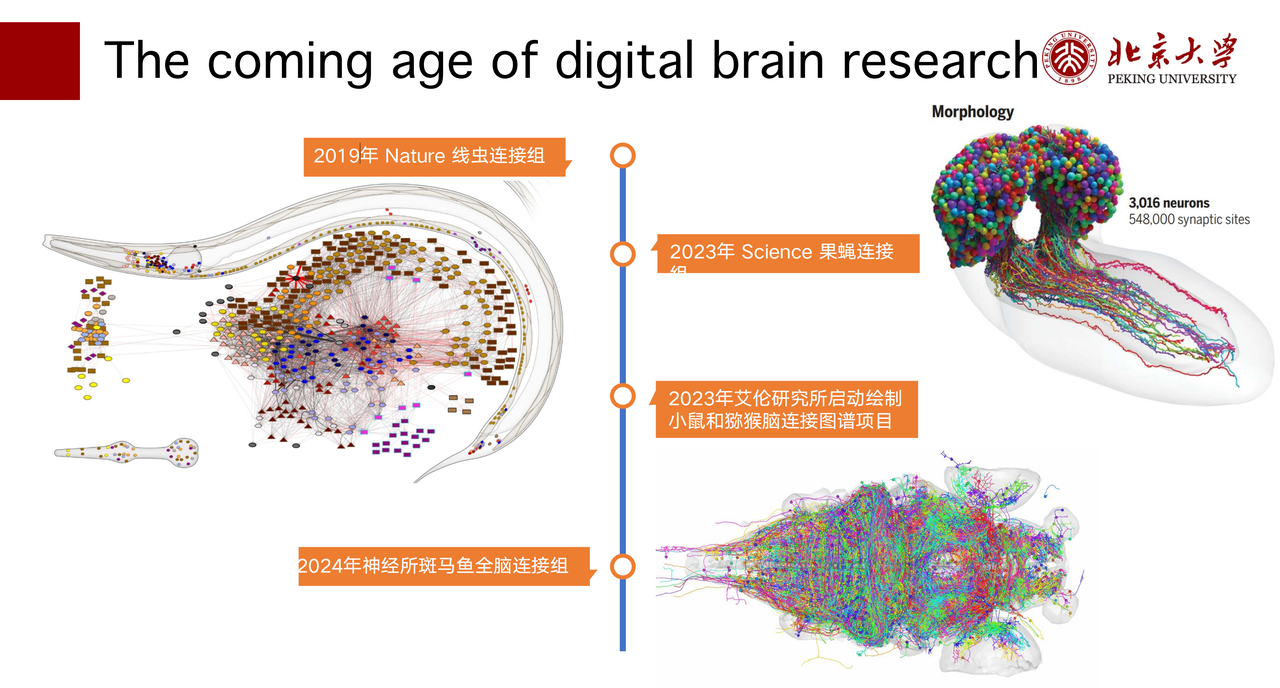
随着数据爆发式地增长,我们接下来要做的事情就是去做全脑的,或者大尺度的仿真。但大尺度的仿真其实并不是一件很容易的事情,里面存在着很多关键性的挑战。
第一是要“能够算”,就是说能不能够有算力,或者有平台去支撑我们算这种上亿量级的神经元网络。
其中一个挑战来自于,大脑是一个多尺度的建模对象,我们在分子层次要建模离子通道,其上要建模神经元、建模网络、建模脑区和系统。这种多尺度的复杂性就意味着,我们的方法或手段必须要有足够的灵活性。
同时,大脑也是个大尺度的建模对象。像小鼠就有 7000 万个神经元,大鼠有两亿个神经元,直到目前为止,这种上亿级别的大尺度的仿真依然对我们现有的通用计算设备来说,是一个很严重的挑战。
假如我们现在已经“能够算”了,那么第二问题就是要“算得准”,就是我们怎么去把各个尺度的数据整合在一起。比如,微观上我们测量到的神经元和突触的连接,怎么把它们整合起来使之能涌现出我们看到的神经活动和认知功能,这些其实都是未知的,或者说是很难做到的。
02 BrainPy,为大脑数字化提供计算基础设施
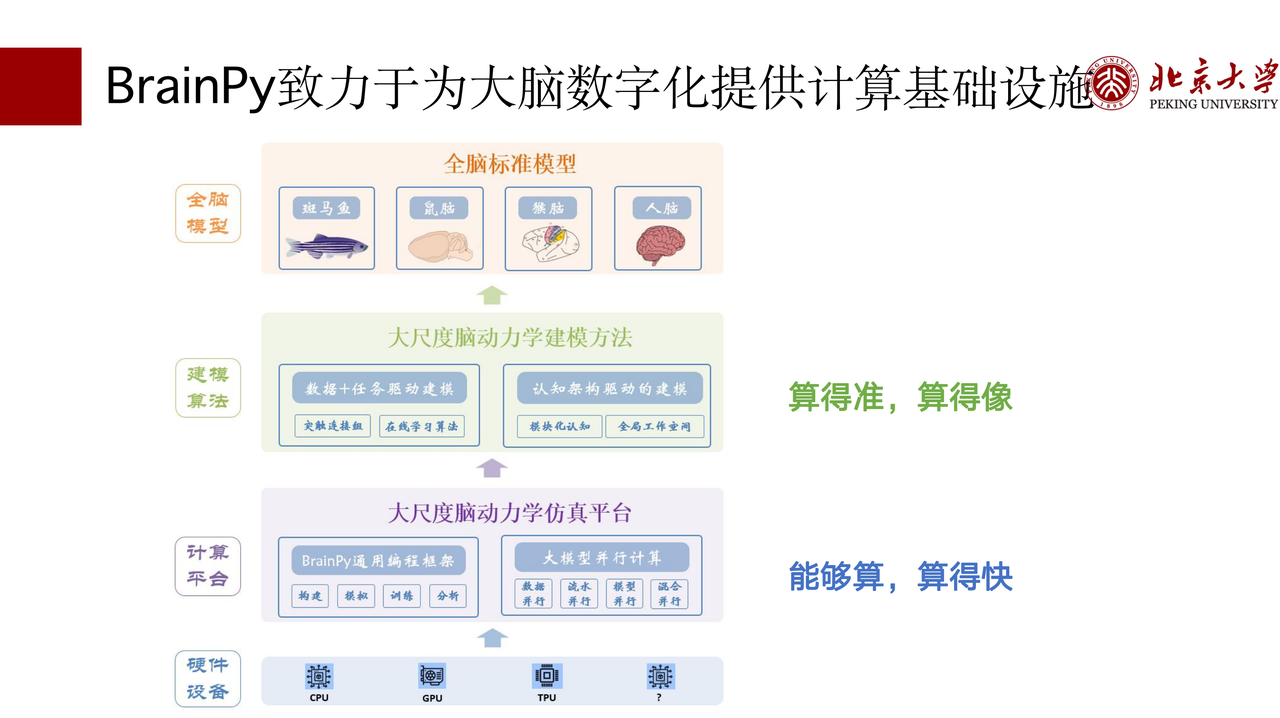
我们的 BrainPy 项目一直致力于为大脑数字化提供计算基础设施,就是想从这两个方面提供一些技术支持。
一方面,我们构建了一个通用的仿真平台,能够帮助我们去做大尺度的脑动力学的建模和仿真;另一方面,我们在此基础上正在推出一些大尺度脑动力学建模的方法,帮助我们将各个层级的数据整合起来,能够算得准,能够真正地反映出大脑的真实活动和功能;其后我们会逐渐推出像斑马鱼、鼠脑这种标准的全脑模型,期待未来推动整个脑认知、脑疾病,类脑 AI 的研究。
2.1 一种即时编译的脑动力学编程系统
当前的软件生态可以大致分为两类:
第一类是传统的 Brain simulator 大脑模拟器,比如有美国支持的 NEURON 软件,欧盟脑计划支持的 NEST 和 Brian2 ,它们能够很好地仿真神经元的模型,很高效,而且能够仿真很大规模的网络,但是它缺乏 AI 最新的一些功能和进展,比如很难去整合 AI 的模型、很难加入最新的 AI 编译的理念;
另一类就是很 powerful 的深度学习框架,比如 PyTorch 和 TensorFlow —— 已经成为了 AI 研究的基础设施,但它们很难有很高的效率和可扩展性去做脑动力学相关的仿真,主要原因就在于缺乏脑动力学相关的专用的组件。
针对这些问题,我们提出了一个解决方案。
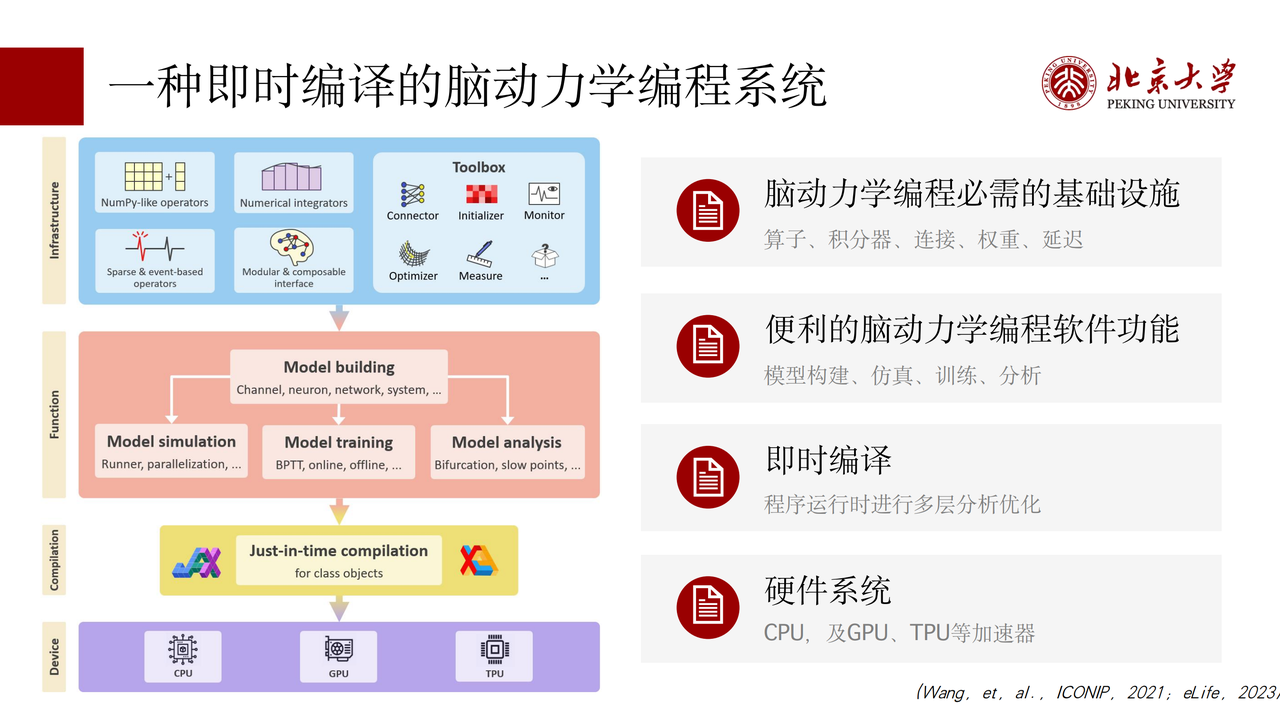
我们用即时编译的方法建设了一个叫做 BrainPy 的编程平台,基于现有的 AI 框架,比如 JAX 和 XLA,提供了脑动力学编程所必需的基础设施,包括常用的稀疏或事件驱动的算子、突触连接、权重、延迟等等。这些基础设施使得我们能够去构建一个非常完备的编程系统 BrainPy 。
它提供了一个非常模块化的、统一的编程界面,可以帮助构建各个尺度的模型,包括离子通道、神经元、网络、系统等,构建好的模型既能用于模型的仿真,也能用于模型的训练和模型的分析。由此,整个编程体系就会特别方便、快捷,因为只需要一次编程就能做各种各样的事情。同时,所有的功能都可以通过即时编译的方法部署到现在最新的硬件设备,包括 CPU、 GPU 、 TPU 或者其他设备上,去做高效的仿真和运行,使运算的速度显著地加快。
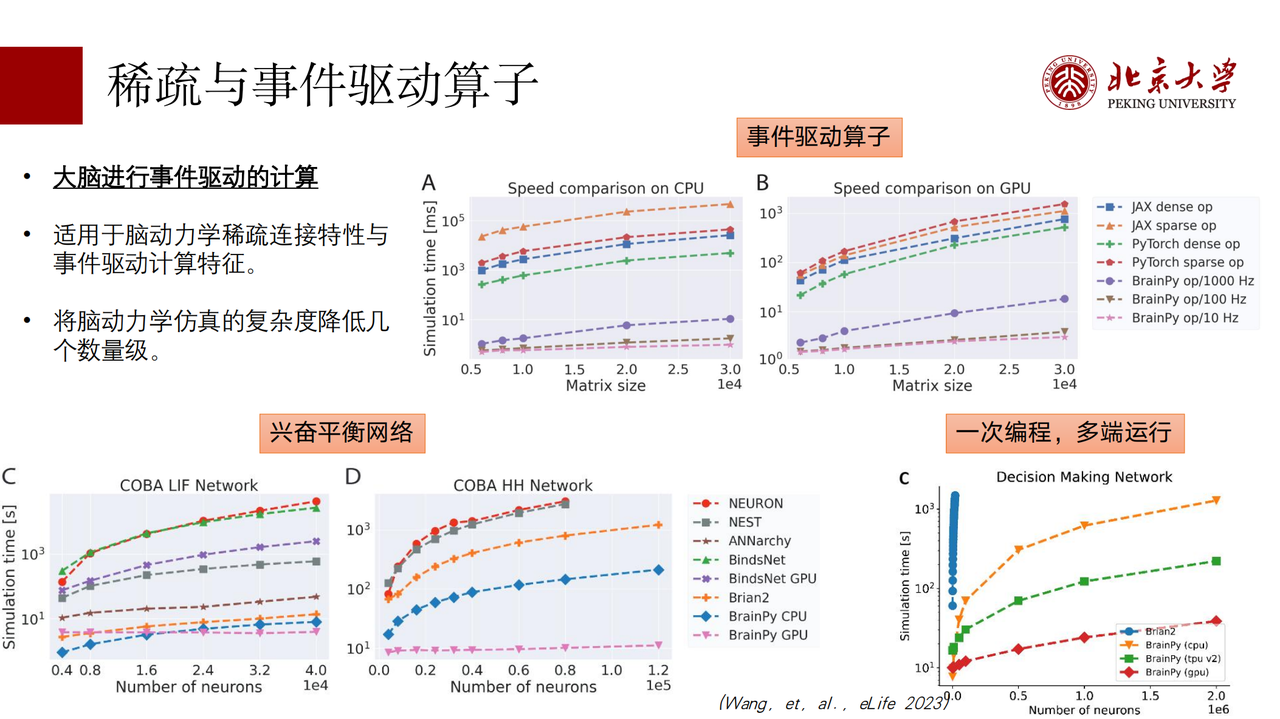
这里很关键的一点在于,我们提供了现在的深度学习框架里面没有的一些稀疏与事件驱动算子。大脑其实是基于脉冲去做计算的,有了突触前的脉冲才有突触和突触后膜的更新。可以看到,无论在 CPU 还是 GPU 上,我们基于这种特性提供的算子,比传统的深度学习的稠密或稀疏的算子,速度要快 2-4 个数量级。同时我们也发现, BrainPy 在网络上的仿真的速度也比现在的深度学习框架要快很多,比现有最好的一些 Brain simulator 要快一个数量级左右。
2.2 多尺度建模范式与大尺度建模算法
前文提到,大脑是一个多尺度的建模对象,BrainPy 针对多尺度建模提供的解决方案就是模块化的和组合编程的范式,使我们能够像大脑真正的层级一样去堆叠网络模型。
比如,我们提供了 bp.DynamicalSystem 去构建 ion channel,构建好的 ion channel 能够组合堆叠成一个 H-H model,H-H model 进而可以堆叠成一个 Network model,Network model 可以形成 System 模型的一部分。
这种模块化组合编程的范式已经应用到了 BrainPy 的各个方面。以神经动力学模型为例,我们知道大脑 spike 的产生其实是离子的流入流出,所以在 BrainPy 编程就只需要定义有什么样的离子,以及使得离子流入流出的 ion channel 是什么,就可以去构建好神经元的模型;突触的模型也类似,BrainPy 首次把非常复杂的突触模型 decompose 成了各个模块,用户只需要关注他所需要的模块是什么,再把模块对接起来,就可以形成各种各样的突触模型。

同时,大脑也是一个大尺度的建模对象。
大脑大尺度建模的难点在于什么?其实 99% 的时间和内存都耗费在了突触的计算上,所以大尺度建模的关键就在于降低突触计算的复杂度。
BrainPy 目前提供两种解决方案:即时连接和模型约简。
即时连接指的是,对于一些脑仿真、类脑的 AI 模型,当权重初始化后不需要修改时,就可以用即时连接的方法直接在计算时实时生成。因为是在计算的时候生成,不需要存储,因而相对于传统的算法来说便减少了内存的开销,使它可以扩展到很大的规模。同时,假如实时生成能快于索引或访存,那么计算的速度也会比传统的方法要快。因此,即时连接的算子不仅比传统的方法运算得快,内存开销也要小,我们在 AI 的模型中应用后发现它确实能很好地提升模型的 performance。
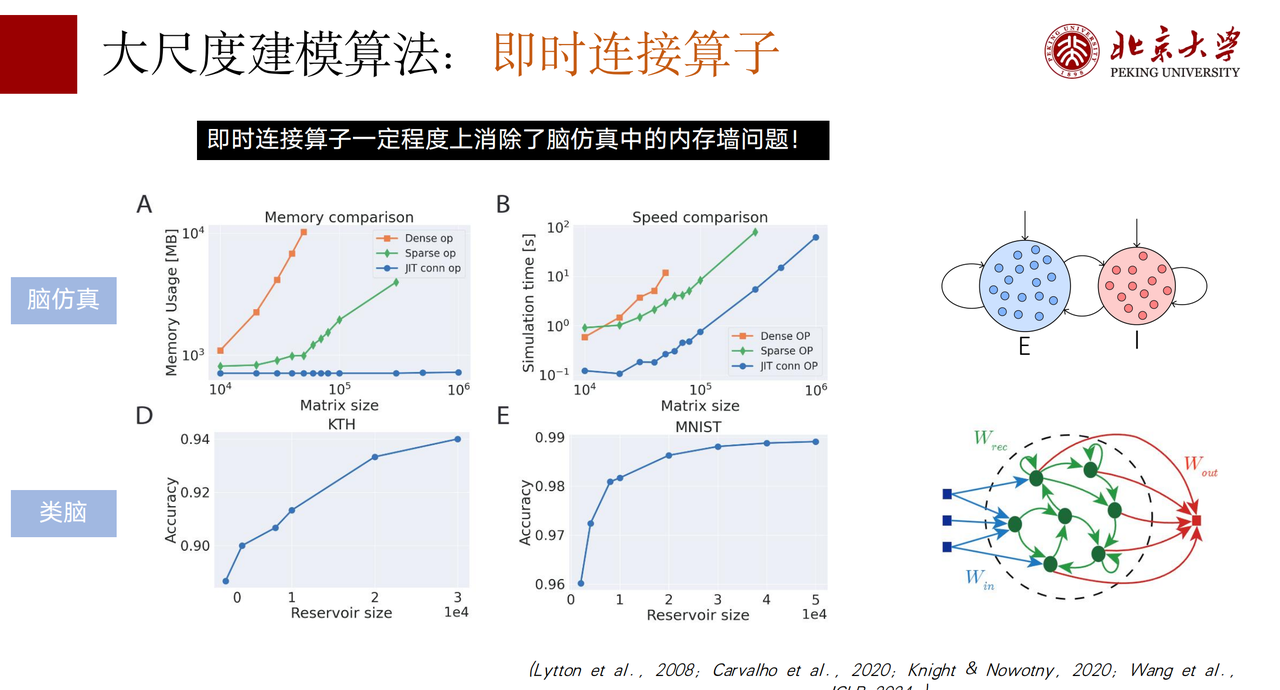
很多时候模型的权重肯定是要训练的,这时我们提供了另一种解决方案叫模型约简,也就是在尽可能保证模型仿真精度的同时有效约简模型。BrainPy 提供了两个非常好的思路,分别是 Align pre 与 Align post 。Align pre 和 Align post 使得突触变量的建模只需要存储突触前的 dimension 或者 突触后的 dimension 就可以了。这样,它使得 O(n²) 的复杂度能够降低为 O(n) 。目前 Align pre 和 Align post 已经在 BrainPy 各种各样的突触模型中都能适用。
这种约简的另一个优点是它可以显著地把有 dynamics 和没有 dynamics 的部分分开了。从这幅图(见下图)可以看到,所有有 dynamics 的可以精确地 align 到神经元的维度,使得我们能做动力学的更新;没有 dynamics 的部分,比如像稀疏连接或卷积计算的部分就能独立出来。通过这样的方式,我们就能把一些传统的、经典的 AI 模块引入进来,使得 AI 的方法和模型也能引入到 brain simulation 中。

模型约简的第三个优点是使得我们能够自动地去 merge 突触投射。大脑仿真的复杂度其实有时候不仅在于 O(n²) 的突触变量存储和计算,还在于它的连接投射。每一个突触投射都会建立新的突触变量,使得突触投射越多,模型变量越多,然而,使用 Align pre 和 Align post,BrainPy 能够自动 merge 来自同一个 population 的突触投射,或者汇聚到同一个 population 的突触投射,这样能够显著地降低大尺度模型的计算图,我们在一些经典的模型中发现这样的方法在运算速度和编译时间上都有显著提升。
2.3 数据驱动与任务驱动的建模范式
前文还提到的一项挑战是如何整合不同尺度的模型,所以第三点是我们提出了“数据驱动与任务驱动的建模范式”。
一方面,模型是基于真实的生物数据所构建的,比如神经元模型的 firing pattern 或离子通道,都可以基于真实的生物数据构建神经元模型或网络模型;模型构建好以后,我们就可以把它应用到机器人或 AI 的 task 中,让它做一些任务驱动的训练,使得真实的生物大脑通过模型的优化完成认知任务,这样能有效地把各个尺度的模型、数据整合在一起。
另一方面,Brainpy 是一个可微分的大脑模拟器,我们提供的很多模型都可以直接跟数据拟合,能够 fit 实验的 data。这方面我们提供了很多支持,比如在网络上,只需要很少的代价就能把原本从数据里面拟合的模型直接用于训练。最近的一项进展是我们做了一个 demo ,让一个 PFC 的模型——有 excitatory neuron 和 inhibitory neuron ,做一个 working memory task,每个模型的动力学都可以通过拟合数据的方式精确地得到它的 firing pattern 。同时,在任务上做训练后,我们就可以得到一个与真实猴子做任务时相似的 spiking dynamics。
此外,当前深度学习主要的范式是反向传播训练,但其实大脑是个循环神经网络,怎么能有更好的方法去训练这个循环神经网络是个非常重要的问题。如果我们用 BPTT 的方法训练,它会很难 scale up,那我们前面提倡的 large scale modeling 就很难开展。所以我们目前正在开发适合于脑动力学模型的训练算法,引入内存高效的方法进行大规模训练。
03 生态与发展
总结下来,我们 BrainPy 致力于提供一个数字化大脑的计算基础设施,从各个层级,包括软件平台、建模方法,全脑标准模型提供基础支持。我们也正在开展像斑马鱼这样的一些全脑模型的建模,期待未来有机会与大家交流。
最后,Brainpy 也正在扩建生态,一方面我们跟和鲸社区已经合作了两届神经计算建模的培训班,每一届都非常火爆,有几百名同学报名,大家如果想了解最新、最前沿的计算神经科学的知识也可以关注一下我们的培训班。同时,基于 BrainPy 我们也撰写了一本书籍叫做《神经计算建模实战》,这本书应该是国内第一本计算神经科学的专业教材,已经被很多实验室采用。BrainPy 也被用于很多实验室的研究中,并获得了一些奖项,包括 OpenI 新一代人工智能开源开放平台两年优秀项目的嘉奖。
未来,我们会持续推出更有意思的、更有帮助的功能。
以上为王超名博士的分享内容,如需获取专家完整版视频实录及课件, 请点此链接联系工作人员领取。
您也可以点击此处免费体验了解与多个临床研究中心合作的数据科学协同平台 ModelWhale 。