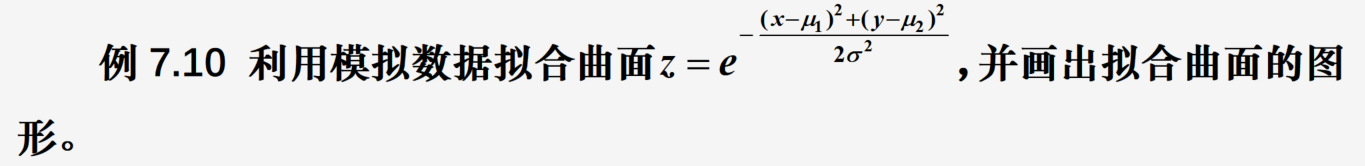Mysql
- 索引
- 索引的分类
- 索引失效
- sql优化
- 删除数据库
- 数据恢复
| 索引 | InnoDB引擎 | MyISAM引擎 | Memory引擎 |
|---|---|---|---|
| Btree索引 | 支持 | 支持 | 支持 |
| hash索引 | 不支持 | 不支持 | 支持 |
| R-tree索引 | 不支持 | 支持 | 不支持 |
| Full-text索引 | 5.6版本以后支持 | 支持 | 不支持 |
索引
解释说明:
索引指的是帮助mysql高效的获取数据的结构叫做索引(有序)
没有建立索引的时候–全表扫描–再数据非常庞大的时候查询效率会非常慢
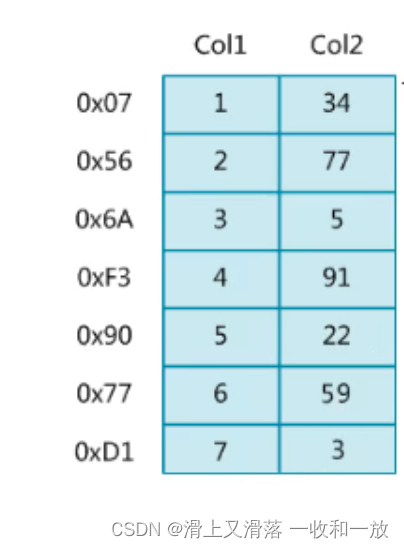
建立索引的时候----参考BTree和B+tree
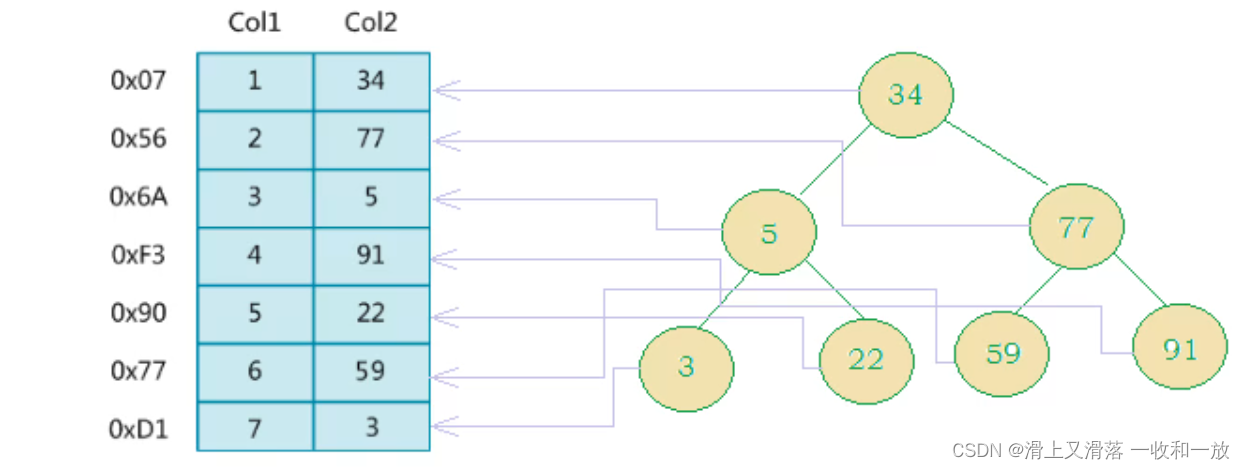
优点:
1.提高了数据检索的效率降低了数据库的io成本
2.通过索引列对数据进行排序,降低额数据排序的成本,降低CPU的消耗
缺点:
1.索引本身也是一种数据结构,所以也就会占用一定的磁盘空间
2.可以参考btree树和b+tree树的规则就知道,他是可以提高插叙效率但是再新增删除修改数据的时候是比较麻烦的,每次都有可能调整索引的数据结构
索引的分类
| 索引 | 解释说明 |
|---|---|
| 单值索引 | 即一个索引只包含单个列,一个表可以有多个单列索引 |
| 唯一索引 | 索引列的值必须唯一 |
| 复合索引 | 即一个索引包含多个列 |
索引的语法
例如:现在有一个表
create table city
(city_id bigint null comment '城市id',city_name varchar(50) null comment '城市名称',country_id bigint null comment '国家id',constraint city_pkprimary key (city_id)
);create table country
(country_id bigint null comment '国家id',country_name varchar(50) null comment '国家名称',constraint country_pkprimary key (country_id)
);#创建索引语法
create [unique | fulltext |spatial] index index_name [using index_type] on tbl_name(index_col_name,...)index_col_name: column_name[(length)][asc | desc]
#实例sql(普通索引):
create index idx_city_name on city(city_name);#查看索引
show index from table_name;
show index from city\G;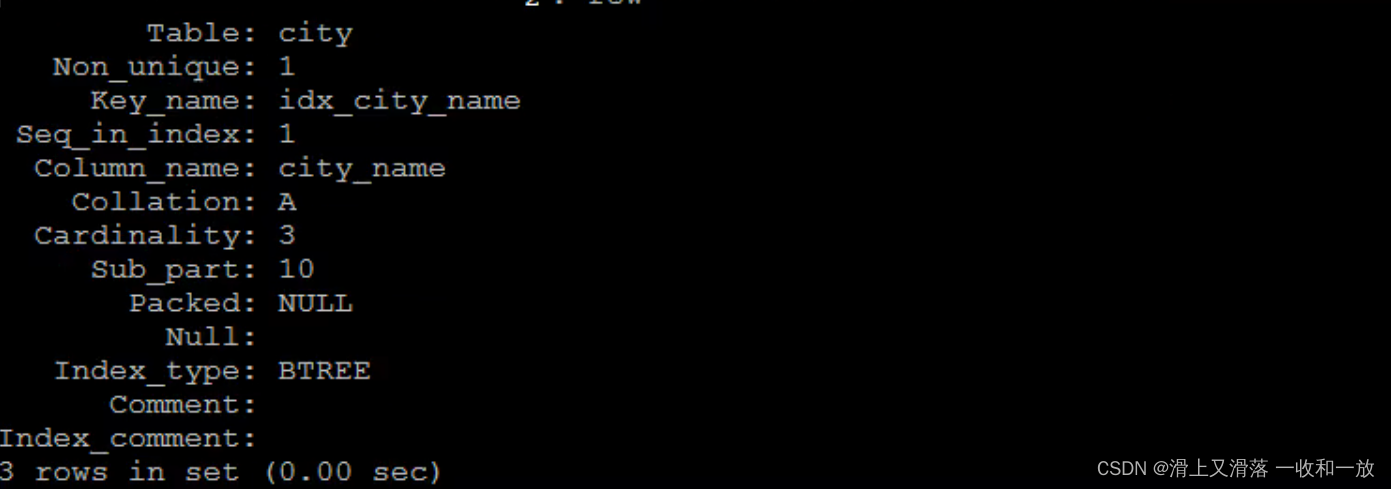
#删除索引
drop index index_name on tbl_name;
drop index idx_city_name on city;#alter命令操作
1.添加主键--索引引用值必须唯一并且不可以为null
alter table tb_name add primary key(column_list);
2.添加唯一索引
alter table tb_name add unique index_name(column_list);
3.普通索引--索引值可以出现多次
alter table tb_name add index index_name(column_list);
4.FULLTEXT--指定的索引为FULLTEXT,用于全文检索
alter table tb_name add fulltext index_name(column_list)
索引设计原则
1.对于查询频率比较高的,并且数据量比较大的表建立索引
2.索引的字段选择,最好是选列从where子句的条件中进行提取.如果where后面的组合比较多,根据实际情况选择最佳的组合列
3.使用唯一索引的时候,区分度越高,使用的索引的效率就会越大
4.使用短索引,索引创建之后也是使用磁盘来进行存储的,因此提高索引的访问i/o效率,也可以提升总体的访问效率,如果索引字段总长度比较短,那么在给定大小的存储内可以存储更多的索引值,相对应的有效提高了mysql的访问索引的i/o效率
5.利用最左前缀,N个列组合而成的组合索引,那么想当于创建了N个索引,如果查询时where子句中使用了组合索引的前几个字段,那么也是可以有效的提高查询的效率的
6.索引的数量并不是越多越好,索引越多,降低了增删改的维护,并且占用的磁盘空间也是会越来越多
查询索引是否生效的语句
#如果这个时候name是有索引的情况
explain select * from tb_seller where name='张三'
#查询当前会话的索引使用情况
show status like 'Handler_read%';
# 查询全局索引的使用情况
show global status like 'Handler_read%';


索引失效
索引失效有哪些情况
1.组合索引需要遵循最左匹配原则,如果中间跳过某一个索引就会导致索引的失效,比如我的组合索引是name-status-address,但是我查询的时候是where status='2’这样就会导致索引的失效;但是如果这个时候我是where后面是name-address,name的索引是生效的但是address的索引是失效的
2.范围查询的时候右边的列不能使用索引(组合索引),比如我现在是where name=‘张三’ and status>‘0’ and address=‘北京’,这个时候address的索引就是失效的情况
3.不要再索引列上进行运算的操作,否则会导致索引失效
4.字符串不加单引号,导致索引失效
5.使用or分割的条件,如果or前的条件中列有索引但是or后面没有索引就会导致前面的有索引失效
6.以%号开头的like模糊查询,索引也是会导致失效,如果是尾部模糊查询那么素索引还是会生效的,但是如果前后都是加了%号这个时候可以使用覆盖索引这个时候索引就会生效了
7.如果mysql觉得全表扫描更快也是不走索引的
8.is null 和is not null根据实际情况决定索引是否失效,和第7点差不多的意思
9.in走索引,not in 不走索引索引失效
10.表连接中的索引失效: 如果在表连接查询中,连接条件中的字段没有索引,可能导致索引失效。
sql优化
查询优化
1.尽量使用覆盖索引(只访问索引的查询,避免出现回表查询),避免使用select *
2.如果查询列超出了索引列,也是会降低查询的效率
3.多字段进行排序的时候要么统一升序要么统一降序要不然可能就会不是通过索引顺序扫描的结果了,这里就是会有针对查询的返回结果在进行排序,多了一个步骤查询效率不高
4.group by后面的字段可以增加索引,因为group by里面也会涉及到排序,所以按照索引进行排序效率高点或者在后面加上 order by null 不进行排序也是可以的
5.尽可能少的使用子查询使用多表联查查询
6.有索引的情况下使用inner join > in > exists
7.没有索引的情况下小表驱动大表,因为join方法里面需要distict,没有索引distict消耗性能较大,所以inner join < in < exists
8.order by尽量使用索引排序,避免使用fileSort文件排序
9.数据类型不匹配: 如果查询条件的数据类型与索引字段的数据类型不匹配,数据库无法使用索引
10.使用函数操作: 如果查询条件中对字段进行了函数操作(如 LOWER(column)),索引可能失效,因为数据库无法直接使用索引。
删除数据库
| 操作 | 是否可以删除全部数据 | 是否删除表结构 | 是否可以和where连起来使用 | 删除速度 |
|---|---|---|---|---|
| delete from | 可以(也可以删除部分数据) | 否 | 可以 | 慢 |
| truncate table | 可以 | 否 | 不可以 | 快 |
| drop table | 可以 | 是 | 不可以 | 最快 |