.
专栏:数据结构|Linux|C语言
路漫漫其修远兮,吾将上下而求索
文章目录
- 插入排序
- 基本思想:
- 代码实现;
- 希尔排序
- 基本思想:
- 在这里插入图片描述
- 多组并排优化
- 《数据结构(C语言版)》--- 严蔚敏
- 希尔排序的特性总结:
- 时间复杂度和空间复杂度对比
- 完整代码
- 总结
插入排序
基本思想:
把马上要排序的记录按其关键码值的大小逐个插入到一个已经排好序的有序序列中,直到所有记录插入完为止,得到一个新的有序序列 。就好像玩扑克牌时候,把排按顺序一个个排好,插入排序,逆序O(n^2),最好情况O(n)接近有序

代码实现;
gap > 1是预排序,目的是让他接近有序
gap == 1 是直接插入排序,目的是让他有序!
void InserSort(int* a, int n)//插入排序O(n^2),最好情况O(n)接近有序
{for (int i = 0; i < n - 1; i++){int end = i;int tmp = a[end + 1];//记录插入数while (end >= 0){if (tmp < a[end])//判断是否插入如果小于end位置的数,end位置开始的数往后移,不用担心覆盖,因为tmp记录了被覆盖的数{a[end + 1] = a[end];//end向后移动end--;}else{break;//大于跳出循环}}a[end + 1] = tmp;//跳出循环后在当前end位置后面插入,这时候tmp>a[end]}
}
单次排序思路:用end记录开始,tmp记录要排序的数放在end后,判断tmp是否小于前面数组end位置的数,如果小于end位置的数a[end]往后移动一位,并且end–,继续判断,直到tmp大于end,插入在end前面,直到end为0结束。
直接插入排序的特性总结:
- 元素集合越接近有序,直接插入排序算法的时间效率越高
- 时间复杂度:O(N^2)
- 空间复杂度:O(1),它是一种稳定的排序算法
- 稳定性:稳定
希尔排序
基本思想:
插入排序和希尔排序都属于插入类排序算法,其基本思想是通过将待排序序列分为有序和无序两部分,然后逐步将无序部分的元素插入到有序部分中,以达到整体有序的效果。
希尔排序是对插入排序的优化先选定一个整数,把待排序文件中所有记录分成个组,所有距离为gap的记录分在同一组内,并对每一组内的记录进行插入排序。然后,取,重复上述分组和排序的工作。当到达=1时,所有记录在统一组内排好序。

void ShellSort(int* a, int n)//希尔排序
{int gap = n;while (gap > 1){gap = gap / 2; //一般的取值一篇除以2//gap = gap/3+1;优化for (int j = 0; j < gap; j++)//j=0对第一组继续排序,j=1对第2组继续排序...一组一组排{for (int i = j; i < n - gap; i += gap)// for(int i = j;i < n-gap; i += gap){int end = i;int tmp = a[end + gap];while (end >= 0){if (tmp < a[end]){ a[end + gap] = a[end];end -= gap;}else{break;}}a[end + gap] = tmp;}}}
}
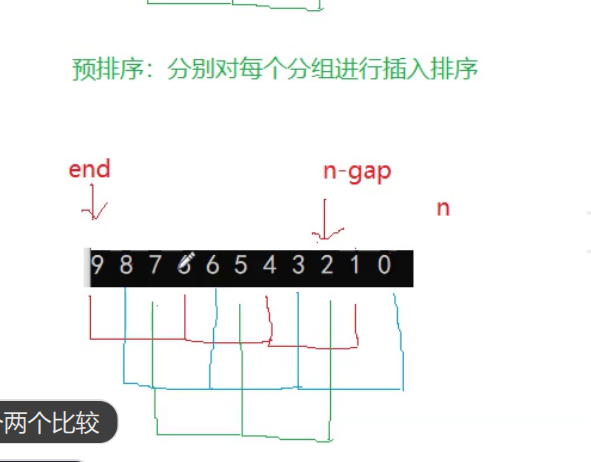
多组并排优化
这种写法相当于多组并排,原来的写法是拍完一组排下一组,这样写就是第一组排一次,然后第二组,第3组。直到循环结束,刚好就排好了。
void ShellSort(int* a, int n)//希尔排序
{int gap = n;while (gap > 1){gap = gap / 2; //一般的取值一篇除以2//gap = gap/3+1;优化for (int i = 0; i < n - gap; ++i)//这种写法相当于多组并排{int end = i;int tmp = a[end + gap];while (end >= 0){if (tmp < a[end]){ a[end + gap] = a[end];end -= gap;}else{break;}}a[end + gap] = tmp;}}}
}
时间复杂的接近n^1.3
《数据结构(C语言版)》— 严蔚敏
希尔排序的分析是一个复杂的问题,因为它的时间是所取“增量”序列的函数,这涉及些数学上尚未解决的难题。因此,到目前为止尚未有人求得一种最好的增量序列,但大量的研究已得出一些局部的结论。如有人指出,当增量序列为dlta[k]=2←-+1-1时,希尔排序的时间复杂度为0(n3/2),其中t为排序趟数,l≤k≤t≤Llogz(n+1)」。还有人在大量的实验基础上推出:当n在某个特定范围内,希尔排序所需的比较和移动次数约为 n’·³,当 n→∞时,可减少到n(log2n)^2[2]。增量序列可以有各种取法①,但需注意:应使增量序列中的值没有除1之外的公因子,并且最后一个增量值必须等于1。
希尔排序的特性总结:
- 希尔排序是对直接插入排序的优化。
- 当gap > 1时都是预排序,目的是让数组更接近于有序。当gap == 1时,数组已经接近有序的了,这样就会很快。
- 希尔排序的时间复杂度不好计算,因为gap的取值方法很多,导致很难去计算,因此在好些树中给出的希尔排序的时间复杂度都不固定:
时间复杂度和空间复杂度对比
| 算法 | 时间复杂度 | 空间复杂度 |
|---|---|---|
| 希尔排序 | 取决于间隔序列(数据量大的话接近n^1.3) | O(1) |
| 插入排序 | O(n^2) | O(1) |
完整代码
可以来我的github参观参观,看完整代码
路径点击这里–>所有排序练习
总结
希尔排序是插入排序的一种优化,通过引入间隔(gap)概念,对多个子序列进行排序,逐渐减小间隔直至为1。希尔排序的时间复杂度不易精确计算,但一般在O(n^1.3)左右。希尔排序的优势在于能够更快地将大的元素移动到序列的两端,从而加速整体排序的过程。希尔排序是不稳定的排序算法。两者的选择取决于具体的应用场景和数据特征。如果数据规模较小或者接近有序,插入排序可能更合适;而对于大规模数据或者需要更高效率的排序,希尔排序可能是更好的选择。