kafka-shell工具
- 背景
- 日志 log
- 一.启动kafka->(start-kafka)
- 二.停止kafka->(stop-kafka)
- 三.创建topic->(create-topic)
- 四.删除topic->(delete-topic)
- 五.获取topic列表->(list-topic)
- 六. 将文件数据 录入到kafka->(file-to-kafka)
- 七.将kafka数据 下载到文件->(kafka-to-file)
- 八. 查看topic的groupID消费情况->(list-group)
背景
注意:我用的kafka版本是 3.2.1 其他版本kafka提供的 命令行可能有细微区别。
因为经常要用kafka环境参与测试,所以写了不少脚本。在很多时候可以大大提高测试的效率。
主要包含如下功能:
topic的管理【创建,删除】
topic信息查看【topic列表,topic groupid 消费情况】
topic数据传输【file数据录入到topic,topic数据下载到本地文件】
脚本中做了各种检查,日志的输出做了颜色区分,用起来没啥问题。
日志 log
此文件是个额外的日志文件主要用于打印日志,该文件会被下面的shell文件引用
#!/bin/bash
#日志级别 debug-1, info-2, warn-3, error-4, always-5
LOG_LEVEL=2#调试日志
function log_debug(){content="$(date '+%Y-%m-%d %H:%M:%S') [DEBUG]: $@"[ $LOG_LEVEL -le 1 ] && echo -e "\033[32m" ${content} "\033[0m"
}
#信息日志
function log_info(){content="$(date '+%Y-%m-%d %H:%M:%S') [INGO]: $@"[ $LOG_LEVEL -le 2 ] && echo -e "\033[32m" ${content} "\033[0m"
}
#警告日志
function log_warn(){content="$(date '+%Y-%m-%d %H:%M:%S') [WARN] $@"[ $LOG_LEVEL -le 3 ] && echo -e "\033[33m" ${content} "\033[0m"
}
#错误日志
function log_err(){content="$(date '+%Y-%m-%d %H:%M:%S') [ERROR]: $@"[ $LOG_LEVEL -le 4 ] && echo -e "\033[31m" ${content} "\033[0m"
}
~
一.启动kafka->(start-kafka)
下面代码中的路径你要替换成自己的路径
#!/bin/bash
source /home/shell/logpid=`ps -aux | grep /home/kafka/kafka_2.12-3.2.1/bin/ | grep -v grep |awk '{print$2}'`
log_info "Start checking kafka process"
if [ -z $pid ]; thenlog_info "The kafka process does not exist, startting.........................................................................................."
elselog_warn "The kafka process exists and does not need to be started"exit 1
fi
nohup kafka-server-start.sh /home/kafka/kafka_2.12-3.2.1/config/server.properties >>/home/kafka/kafka.log 2>&1 &
# 日志的路径是安装kafka的时候指定的,也要替换成自己的路径
tail -f 20 /home/kafka/kafka.log二.停止kafka->(stop-kafka)
下面代码中的路径你要替换成自己的路径
#!/bin/bash
source /home/shell/log
log_info "Start checking kafka process"
pid=`ps -aux | grep /home/kafka/kafka_2.12-3.2.1/bin/ | grep -v grep |awk '{print$2}'`
if [ -z $pid ]; thenlog_warn "The kafka process does not exist and does not need to be stopped"exit 1
elselog_info "The kafka process alive, stopping.............................................................................................................."
fi
kafka-server-stop.sh
log_info "Stop kafka success"三.创建topic->(create-topic)
下面代码中的路径你要替换成自己的路径
#!/bin/bash
source /home/shell/log
log_info "脚本功能: 创建topic"
log_info "脚本参数: topic名称(必选)"
if [ $# -ne 1 ]; thenlog_err "错误:请传入topic名称"exit 1
fi
#TOPIC名称
TOPIC_NAME=$1
#KAFKA地址
KAFKA_BROKER=ip:9092
# 检查Kafka主题是否存在, 若已存在则放弃创建
if kafka-topics.sh --bootstrap-server $KAFKA_BROKER --list | grep -q "^$TOPIC_NAME$";thenlog_warn "$TOPIC_NAME 已经存在,放弃创建"
else# 默认1副本,3分区kafka-topics.sh --create --bootstrap-server $KAFKA_BROKER --replication-factor 1 --partitions 3 --topic $TOPIC_NAMElog_info "请执行topic-list检查创建是否成功"
fi
~

四.删除topic->(delete-topic)
下面代码中的路径你要替换成自己的路径
#!/bin/bashsource /home/shell/log
log_info "脚本作用:删除topic"
log_info "脚本参数: 支持多个topic,用空格分开,可以批量删除"
KAFKA_BROKER=ip:9092
function check_kafka_topic() {local local_topic_name=$1if kafka-topics.sh --bootstrap-server $KAFKA_BROKER --list | grep -q "^$local_topic_name$";thenlog_info "$local_topic_name存在->true"return 0 # 返回true elselog_warn "$local_topic_name 不存在->false"return 1 # return falsefi
}# 逐个删除topic
for topic in "$@"
doif ! check_kafka_topic $topic; thenlog_info "tpoic->$topic 不存在,跳过删除行为"continueelselog_info "topic->$topic 执行删除"kafka-topics.sh --delete --bootstrap-server $KAFKA_BROKER --topic $topiclog_info "topic->$topic 删除成功"fi
done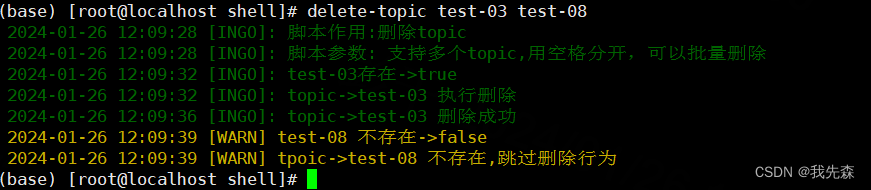
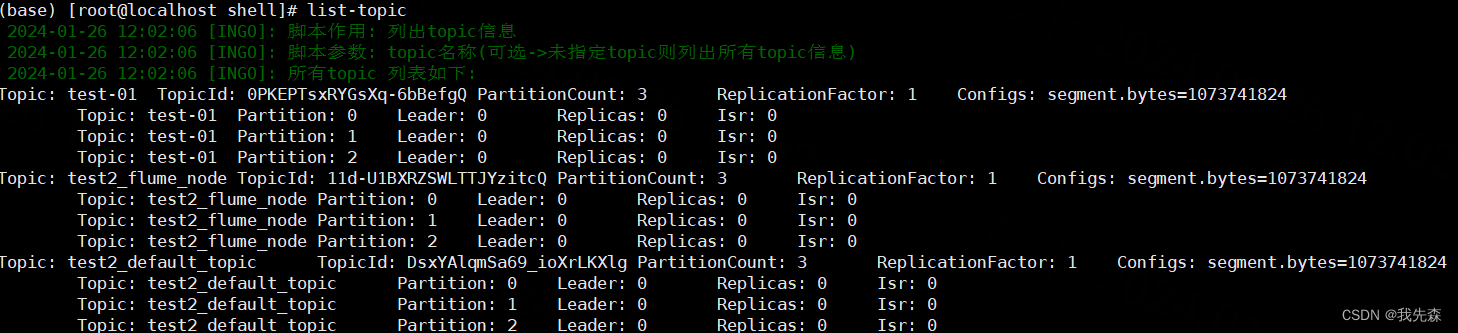
五.获取topic列表->(list-topic)
#!/bin/bash
source /home/shell/log
KAFKA_BROKER=ip:9092
log_info "脚本作用: 列出topic信息"
log_info "脚本参数: topic名称(可选->未指定topic则列出所有topic信息)"
if [ $# -eq 1 ]; thenlog_info "目标$1 详情如下"kafka-topics.sh --describe --bootstrap-server $KAFKA_BROKER | grep -v "__consumer_offsets" | grep $1
elselog_info "所有topic 列表如下:"kafka-topics.sh --describe --bootstrap-server $KAFKA_BROKER | grep -v "__consumer_offsets"
fi
六. 将文件数据 录入到kafka->(file-to-kafka)
#!/bin/bash
source /home/shell/log
log_info "脚本作用: 将文件中的数据录入指定topic"
log_info "脚本参数: 1.文件路劲(必选) 2.topic(必选)"
log_info "参数校验"
log_info "执行条件检查.........................................................................................................."
if [ $# -ne 2 ]; thenlog_err "必须传入两个参数: 1.文件路劲(必选) 2.topic(必选)"exit 1
fiif ! [ -f $1 ]; thenlog_err "$1不是一个有效的数据文件"exit 1
fiFILE_PATH=$1
TOPIC_NAME=$2
KAFKA_BROKER=ip:9092 #检查topic是否存在
function check_kafka_topic() {local local_KAFKA_BROKER=$1if kafka-topics.sh --bootstrap-server $KAFKA_BROKER --list | grep -q "^$local_KAFKA_BROKER$";thenreturn 0 # 返回true elsereturn 1 # return falsefi
}#将文件数据推送到kafka
function send_to_kafka(){local local_path=$1local count=0while IFS= read -r line; do kafka-console-producer.sh --broker-list $KAFKA_BROKER --topic $TOPIC_NAME <<< "$line" count=$((count+1))done < "$local_path"echo $count
} if ! check_kafka_topic $TOPIC_NAME;thenlog_err "条件检查不通过, 原因: topic->$TOPIC_NAME不存在, 请先创建topic"exit 1
filog_info "参数检查通过.........................................................................................................."
start_time=`date "+%Y-%m-%d %H:%M:%S"`
start_seconds=$(date -d "$start_time" +%s)log_info "开始录入数............................................................................................................"
count=$(send_to_kafka $FILE_PATH)end_time=`date "+%Y-%m-%d %H:%M:%S"`
end_seconds=$(date -d "$end_time" +%s)
time_diff=$((end_seconds - start_seconds)) log_info "录入条数: $count"
log_info "花费时间:$time_diff 秒"
log_info "录入完成.............................................................................................................."
七.将kafka数据 下载到文件->(kafka-to-file)
#!/bin/bash
source /home/shell/log
log_info "脚本作用: 将kafka指定topic的数据消费到指定文件中"
log_info "脚本参数:1.数据文件路径(必选) 2.topic名称(必选) 3.groupID(可选->不存在则从头消费,存在则从grooupID offset 开始消费)"
log_info "group-list 脚本可以查看当前的"
# Kafka的bin目录
KAFKA_BIN_DIR=/path/to/kafka/bin#kafka 地址
KAFKA_SERVER=ip:9092 # Kafka的配置文件目录
KAFKA_CONFIG_DIR=/home/kafka/kafka_2.12-3.2.1/config# Kafka消费者配置文件
CONSUMER_CONFIG=$KAFKA_CONFIG_DIR/consumer.properties# 指定要消费的主题
TOPIC_NAME=your_topic_name# 指定要写入的文件
FILE_PATH=$1
TOPIC_NAME=$2
GROUP_ID=$3log_info "执行检察............................................................................................................................"function check_kafka_topic() {local local_topic_name=$1if kafka-topics.sh --bootstrap-server $KAFKA_SERVER --list | grep -q "^$local_topic_name$";thenreturn 0 # 返回true elsereturn 1 # return falsefi
}if ! check_kafka_topic $TOPIC_NAME;thenlog_err "topic->$TOPIC_NAME 未找到"exit 1
fi
log_info "检查通过............................................................................................................................"log_info "当前topic,所有groupID的消费情况如下>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>"
while IFS= read -r line; doif [[ $line == *"PARTITION"* ]]; thencontent="$(date '+%Y-%m-%d %H:%M:%S') [INFO] $line"echo -e "\033[45m" ${content} "\033[0m"else log_info "$line"fi
done< <(kafka-consumer-groups.sh --bootstrap-server $KAFKA_SERVER --describe --all-groups | grep -v '__consumer_offsets' | grep "$TOPIC_NAME\|PARTITION")log_info "当前topic,所有groupID的消费情况输出完成>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>"log_info "消费进程运行中( CTRL+C 可退出消费 )................................................................................................."
# 运行消费者脚本并将输出重定向到文件
if [ $# -eq 2 ]; thenkafka-console-consumer.sh --bootstrap-server $KAFKA_SERVER --topic $TOPIC_NAME --from-beginning > $FILE_PATH
fi
if [ $# -eq 3 ]; thenkafka-console-consumer.sh --bootstrap-server $KAFKA_SERVER --topic $TOPIC_NAME --from-beginning --group $GROUP_ID > $FILE_PATH
fi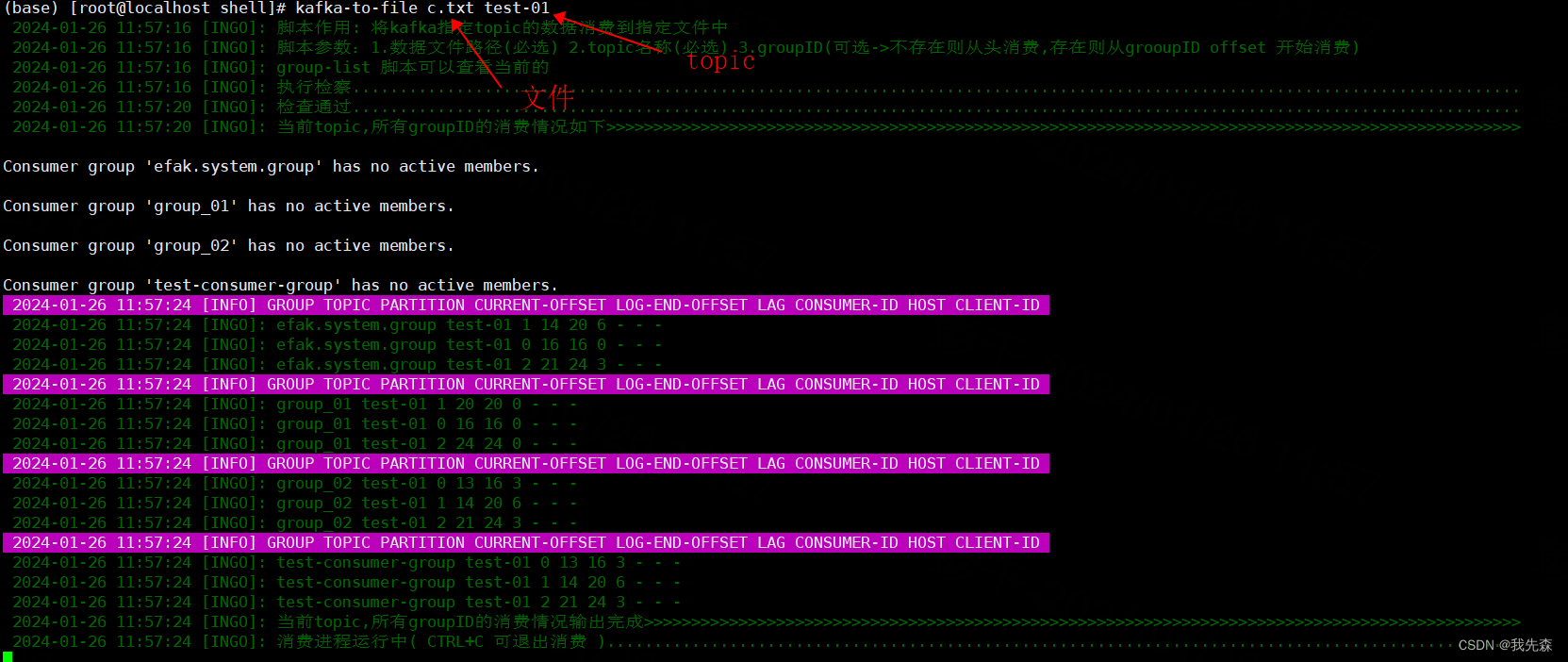
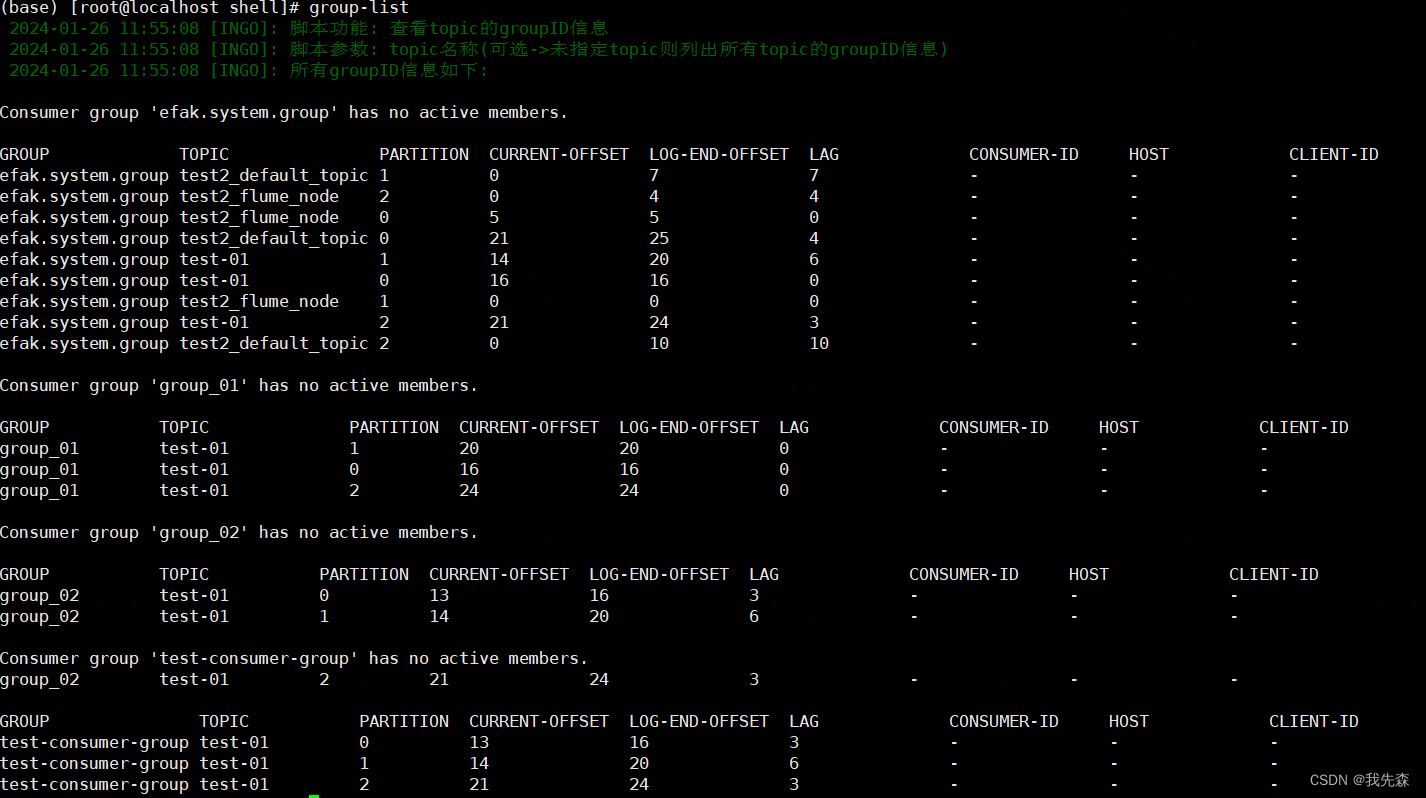
八. 查看topic的groupID消费情况->(list-group)
#!/bin/bash
kafka_broker=ip:9092
source /home/shell/log
log_info "脚本功能: 查看topic的groupID信息"
log_info "脚本参数: topic名称(可选->未指定topic则列出所有topic的groupID信息)"
function check_kafka_topic() {local local_topic_name=$1if kafka-topics.sh --bootstrap-server $kafka_broker --list | grep -q "^$local_topic_name$";thenlog_info "$local_topic_name存在->true"return 0 # 返回true elselog_warn "$local_topic_name 不存在->false"return 1 # return falsefi
}if [ $# -eq 1 ]; thenif ! check_kafka_topic $1; then#topic 不存在则直接退出程序log_warn "topic=$1, 不存在"exit 1filog_info "topic_name=$1 的gruoupID信息如下:"kafka-consumer-groups.sh --bootstrap-server $kafka_broker --describe --all-groups | grep $1 | grep -v __consumer_offsets
elselog_info "所有groupID信息如下:"kafka-consumer-groups.sh --bootstrap-server $kafka_broker --describe --all-groups | grep -v __consumer_offsets
fi

![[嵌入式软件][启蒙篇][仿真平台] STM32F103实现IIC控制OLED屏幕](https://img-blog.csdnimg.cn/direct/920c16a889344e6ca1fd2e0c56c3aac2.gif#pic_center)