基于机器学习的地震预测(Earthquake Prediction with Machine Learning)
- 一、地震是什么
- 二、数据组
- 三、使用的工具和库
- 四、预测要求
- 五、机器学习进行地震检测的步骤
- 六、总结
一、地震是什么
地震几乎是每个人都听说过或经历过的事情。地震基本上是一种自然发生的事件,当地壳中突然释放能量导致地面振动或晃动时,就会发生地震。在地球表面之下,有很大一部分被称为构造板块,它们构成了地球的外层。这些部分经常移动并相互作用。由于这种相互作用和运动,这些板块可能会因摩擦而锁定,这反过来又会导致压力增加。
随着时间的推移,随着压力的不断积累,在某一点上,它达到了一个点,沿着板块边界的岩石破裂,释放出大量储存的能量。这种释放出来的能量以地震波的形式在地壳中传播,从而导致地面震动和颤抖。地震的强度和强度都是用里氏震级来测量的。
二、数据组
地震数据集包含2001年1月1日至2023年1月1日在世界各地发生的各种地震的详细信息。它是与地震事件相关的结构化数据。这些数据是由地震研究所、研究机构等组织收集和维护的。这个数据集可以用来建立和训练各种机器学习模型,这些模型可以预测地震,这将有助于拯救人们的生命,并采取必要的措施来减少造成的损害。
数据集可以使用此此链接下载: dataset
该数据集总共包含782行和19个属性(列)。属性的简要描述如下:
标题: 指给地震起的名称/标题
震级: 用来描述地震的强度或强度
日期: 地震发生的日期和时间
cdi: cdi表示给定地震记录的最高烈度
mmi: mmi代表修正Mercalli烈度,表示地震的最大仪器报告烈度
alert: 此属性指的是与特定地震相关的可能威胁或风险的警报级别
tsunami: 表示本次地震是否引起海啸
震级: 用来描述地震的严重程度。地震的重要性与这个数字成正比
net: 表示采集数据的源的id。
nst: 此属性用于描述用于确定地震位置的地震台站的总数。
dmin: 表示离震中最近的监测站的水平距离。
缺口: 用于确定地震的水平位置。数值越小,表明确定地震水平位置的可靠性越高
magType: 这是指用于计算地震震级的算法类型
深度: 表示地震开始破裂的深度
纬度,经度: 用坐标系统表示地震发生的位置
location: 该国家的具体位置
大陆: 指发生地震的大陆
country: 表示受地震影响的国家
三、使用的工具和库
该项目使用了以下Python库:
● Numpy
● Matplotlib
● Seaborn
● Pandas
● Scikit-learn
四、预测要求
先决条件是:
NumPy:
-
理解数组和矩阵运算。
-
能够有效地进行数值计算。
Pandas:
-
熟练处理和分析结构化数据。
-
了解数据框架和系列。
-
能够处理和预处理地震数据,包括清理、过滤和转换数据。
Matplotlib:
-
掌握基本的绘图技术,包括线形图、散点图和直方图。
-
理解子图,以便在单个图中创建多个图。
-
熟悉高级绘图类型,如热图、等高线图和地理可视化。
Seaborn:
-
了解统计数据可视化技术。
-
Seaborn功能的知识,创建视觉吸引力和信息丰富的情节。
Scikit-learn:
-
熟悉机器学习概念,如监督学习和无监督学习。
-
了解模型选择、培训和评估程序。
五、机器学习进行地震检测的步骤
- 导入所需的库
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns- 导入所需库后,可以读取和显示数据集。可以使用**read_csv()**函数读取数据集,并且可以使用head()函数显示数据集的前5行。
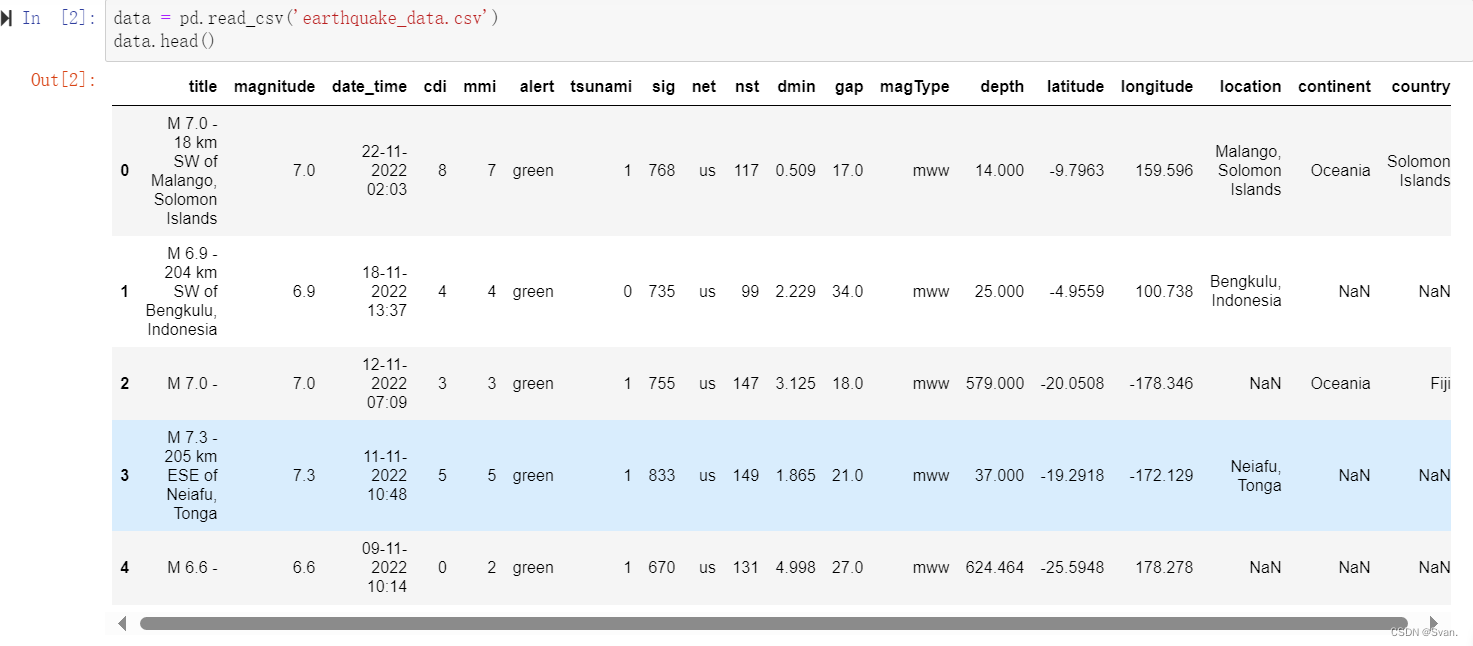
data = pd.read_csv('earthquake_data.csv')
data.head()
输出:
输出显示数据集的前5行。
3. 一旦数据被读取,就可以对数据进行一些基本的探索性数据分析,以获得对数据的一些见解,并对数据有更多的了解。
data.info()
输出:
info()函数用于获取有关数据集中存在的属性、数据集中的行数、每个属性中缺失值的数量、每个属性的数据类型等信息。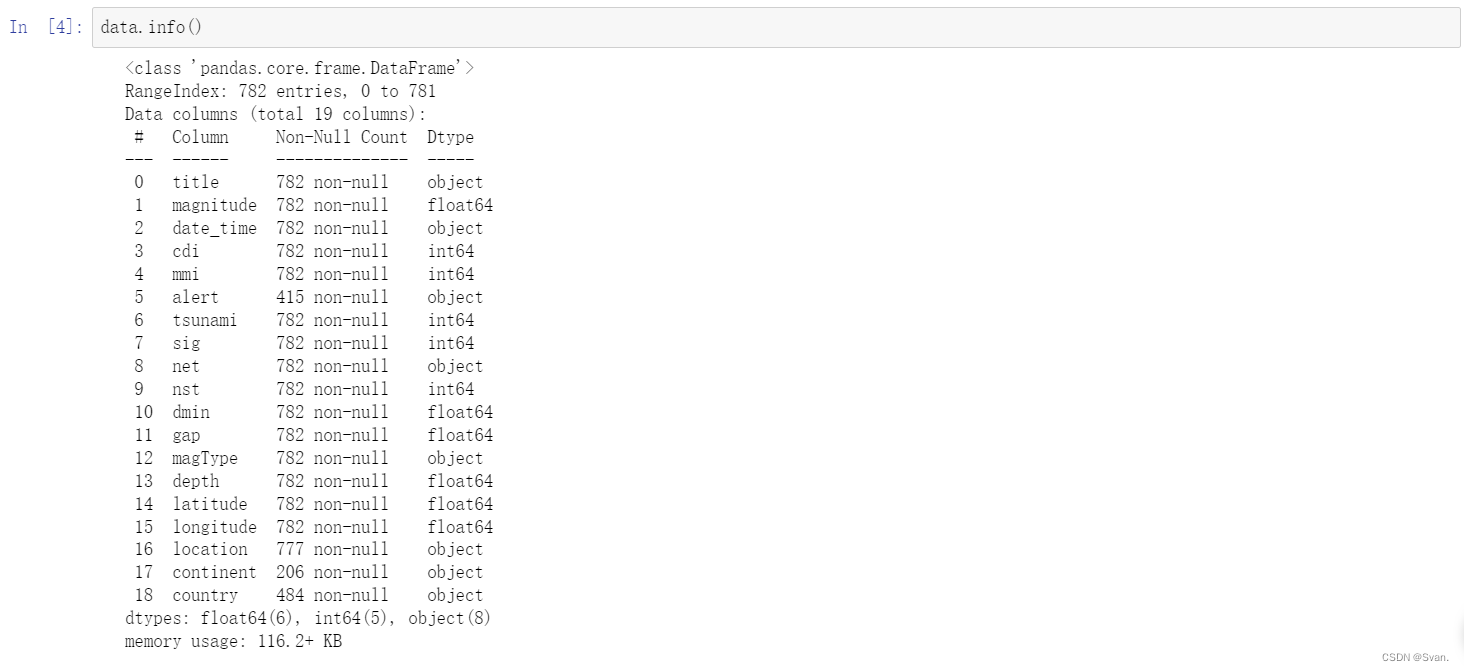
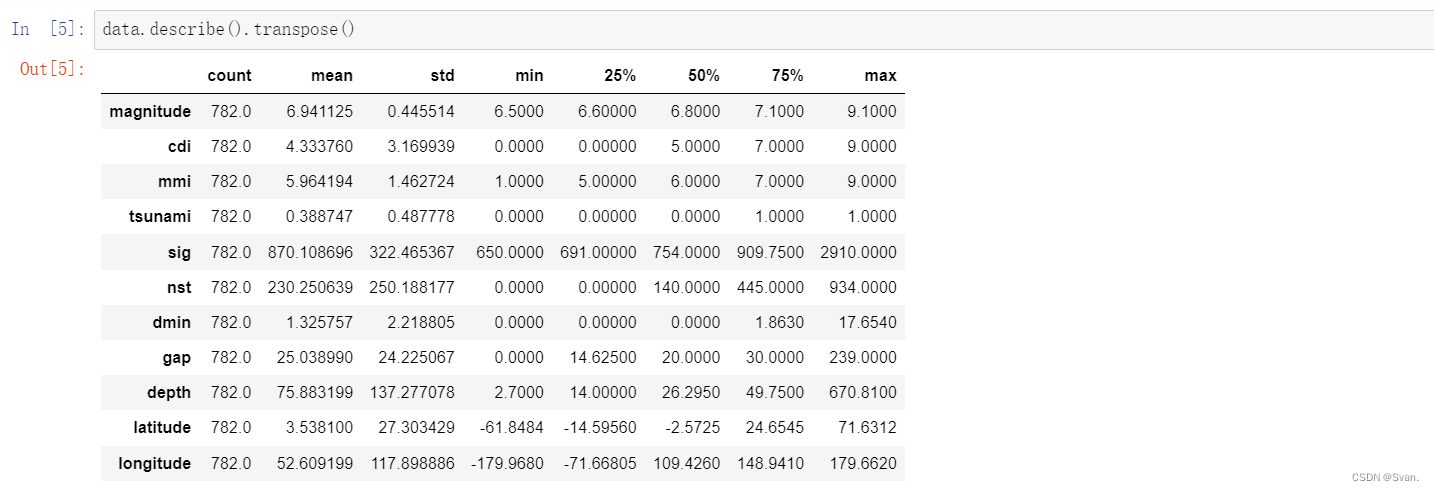
4. 除了info()函数,description()函数还可用于获取数据集的统计信息。
data.describe().transpose()
输出:
description()函数为属于数据集的所有属性提供最小值,最大值,平均值,标准差等统计见解。
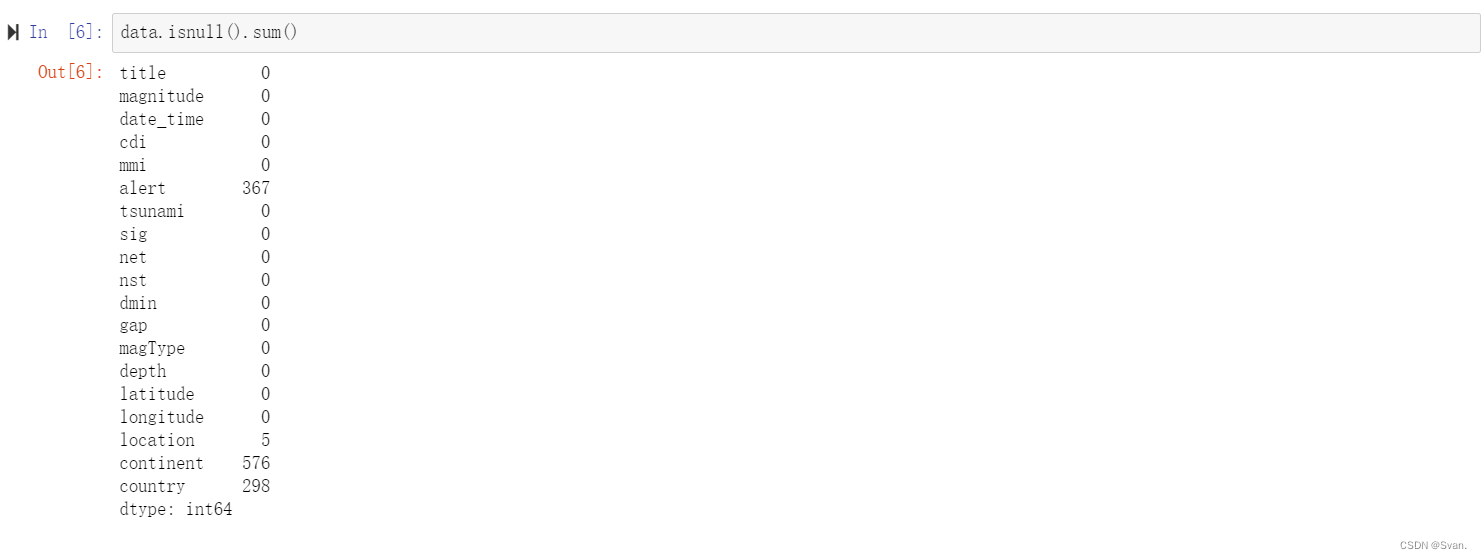
5. isnull()函数可用于查找数据集中是否存在任何空值,聚合函数sum()用于获取数据集中每个属性中空值的总数。
data.isnull().sum()
输出:
输出图像显示数据集所有属性中空值的总数。列alert、continent和country分别有367,576和298个空值。
6. 在获得关于数据的一些基本见解之后,我们可以继续清理数据集。清理数据集将有助于将其转换为更好的形式,以便以后用于训练各种机器学习模型。
features = ["magnitude", "depth", "cdi", "mmi", "sig"]
target = "alert"
data = data[features + [target]]
data.head()输出:
在上面给出的代码中,我们创建了一个名为features的列表,其中包含名为震级,深度,cdi, mmi, sig。我们将使用机器学习模型来预测警报属性。
警报属性存储在一个名为target的变量中。在下一步中,我们将创建一个数据框架,并只选择功能列表中提到的列/属性以及目标变量。
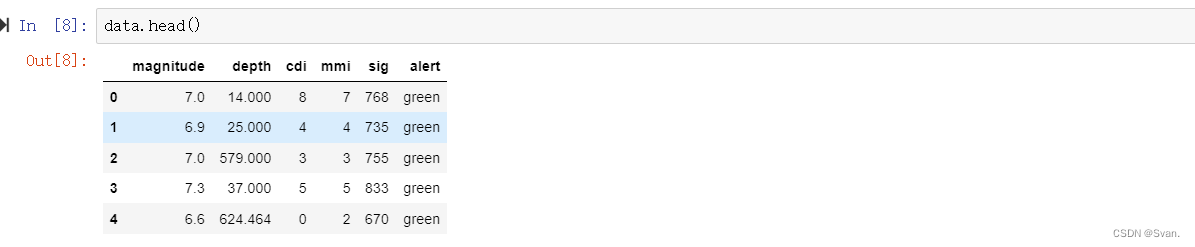
新数据框的前10行可以使用head()函数显示。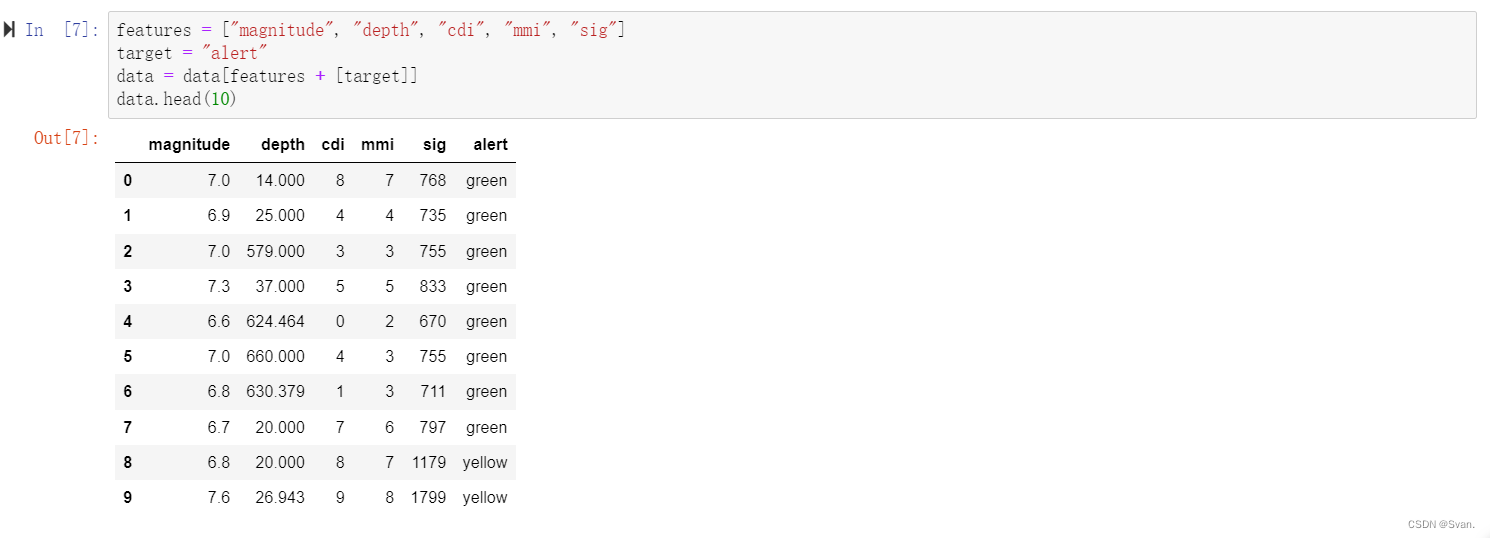
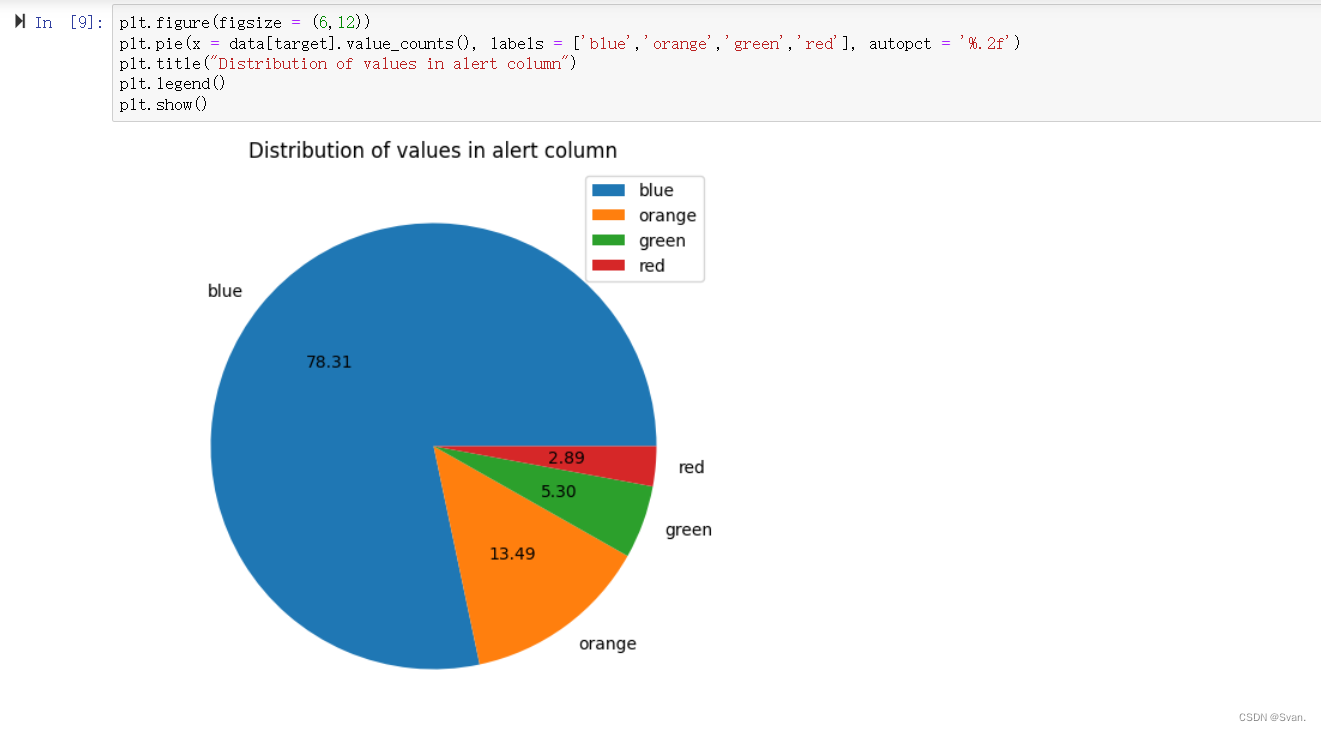
- 警报属性中所有值的计数可以使用饼图显示。
plt.figure(figsize = (6,12))
plt.pie(x = data[target].value_counts(), labels = ['blue','orange','green','red'], autopct = '%.2f')
plt.title("Distribution of values in alert column")
plt.legend()
plt.show()输出:
饼状图显示警报列中出现的各种值的分布。各种值出现的百分比为:蓝色= 78.31%,橙色= 13.49%,绿色= 5.30%,红色= 2.89%。
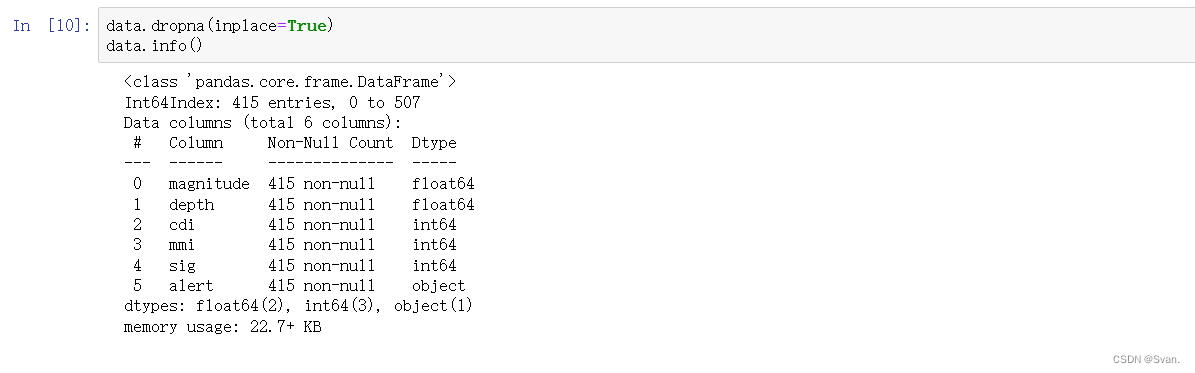
8. 前面我们已经看到数据集中的一些属性包含某些空值。由于空值不多,因此可以使用dropna()函数从数据集中删除这些值。
data.dropna(inplace=True)
data.info()输出:
使用dropna()函数删除空值,在下一行中,使用info()函数获取有关数据集的一些基本信息。
9. 在下一步中,我们将对数据进行预处理。在此步骤中,将更改某些属性的数据类型。代码中将属性cdi、mmi、sig从int64类型转换为int8类型,将属性depth从float64类型转换为int16类型。属性警报也从类型对象转换为类别。这些转换主要是为了内存优化。转换数据类型的其他原因是,使用整数而不是浮点数以更好的方式表示数据。
data = data.astype({'cdi': 'int8', 'mmi': 'int8', 'sig': 'int8', 'depth': 'int16', 'alert': 'category'})
data.info()输出:一旦转换了属性的数据类型,就可以使用info()函数来显示属性关于属性及其数据类型的信息。

10. 现在,让我们检查目标(警报)列中出现的各种值的计数。我们可以使用条形图来实现这个目的。
data[target].value_counts().plot(kind='bar', title='Count (target)', color=['green', 'yellow', 'orange', 'red']);
输出:输出图像是一个条形图,显示alert属性中所有值的计数。的值是绿色,黄色,橙色,红色。大多数值是绿色的,其次是黄色、橙色和红色。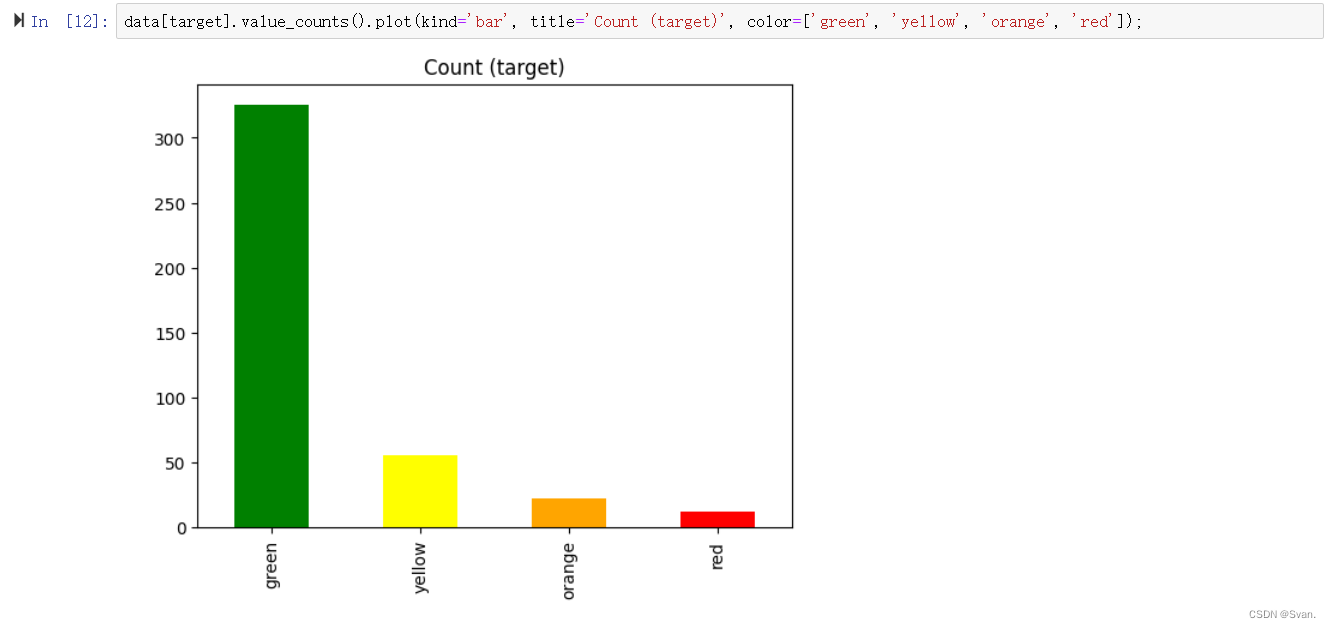
11. 在前面的步骤中,可以看到alert属性中最常出现的值是绿色的价值。这表明alert属性是不平衡的,即alert属性中的值没有相同的出现次数。为了克服alert属性不平衡的问题,我们可以执行over-sampling过采样也有助于模型表现良好,因为它消除了被偏向于出现次数最高的值的可能性。
X = data[features]
y = data[target]X = X.loc[:,~X.columns.duplicated()]sm = SMOTE(random_state=42)
X_res, y_res= sm.fit_resample(X, y,)y_res.value_counts().plot(kind='bar', title='Count (target)', color=['green', 'orange', 'red', 'yellow']);在前两行中,变量X被初始化为名为data的数据框。这是一个功能列表先前指定的属性。变量y是用数据框架的目标(警报)列初始化的。在下一行中,代码从X值中删除所有重复的列。只有那些列不会重复,并将存储在X中。完成此操作后,我们将创建SMOTE算法的一个新实例。SMOTE代表合成少数过采样技术。这是一种常用的解决问题的技术机器学习中的类不平衡。创建SMOTE算法的实例后,可以使用该实例应用SMOTE算法对变量X和y进行重采样,应用SMOTE算法得到的值为分别存储在x_res和y_res变量中。完成后,我们可以使用条形图绘制y_res变量中的值。
输出:从柱状图中可以明显看出,y_res变量中存在的所有值具有相同数量的出现了。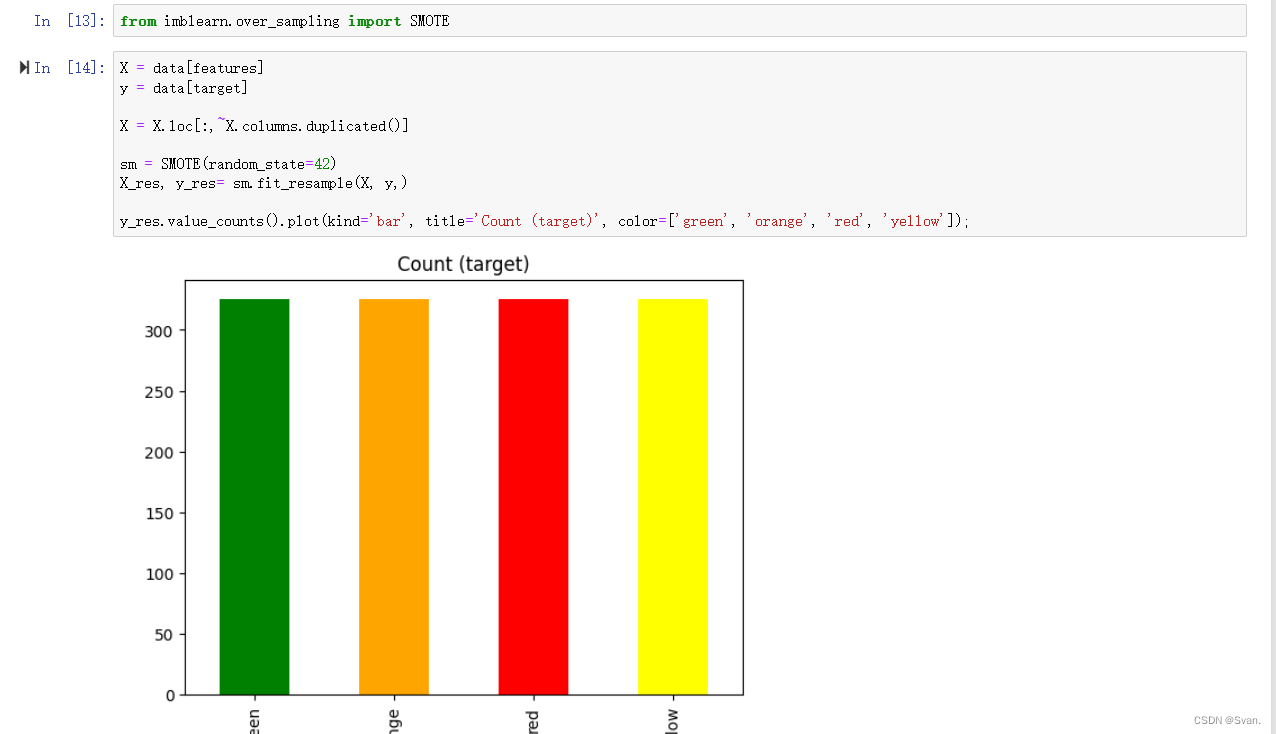
12. 接下来,我们可以使用train_test_split()将数据分割为训练数据和测试数据函数。
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X_res, y_res, test_size=0.2, random_state=42)注意,在上面的代码中,我们使用变量X_res和y_res作为独立变量和因变量分别为。我们使用X_res和y_res,因为它没有问题alert属性不平衡。原始数据帧在告警中面临着不平衡的问题属性。
- 在我们开始在数据集上实现模型之前,我们必须使数据符合标准这将最终帮助机器学习模型以更好的方式理解数据。这可以使用StandardScaler()函数来完成。
from sklearn.preprocessing import StandardScaler
scaler = StandardScaler()
X_train = scaler.fit_transform(X_train)
X_test = scaler.transform(X_test)- 我们可以绘制出数据集中存在的各种值之间的相关性。相关矩阵表示数据集中存在的各种变量之间的关系,以及每个变量如何受到其他变量的影响。也可以使用下面的代码绘制它。
plt.figure(figsize = (10,6))
sns.heatmap(data.corr(), annot=True, fmt=".2f")
plt.plot()输出:
相关矩阵表示数据集中存在的各种值之间的相关系数。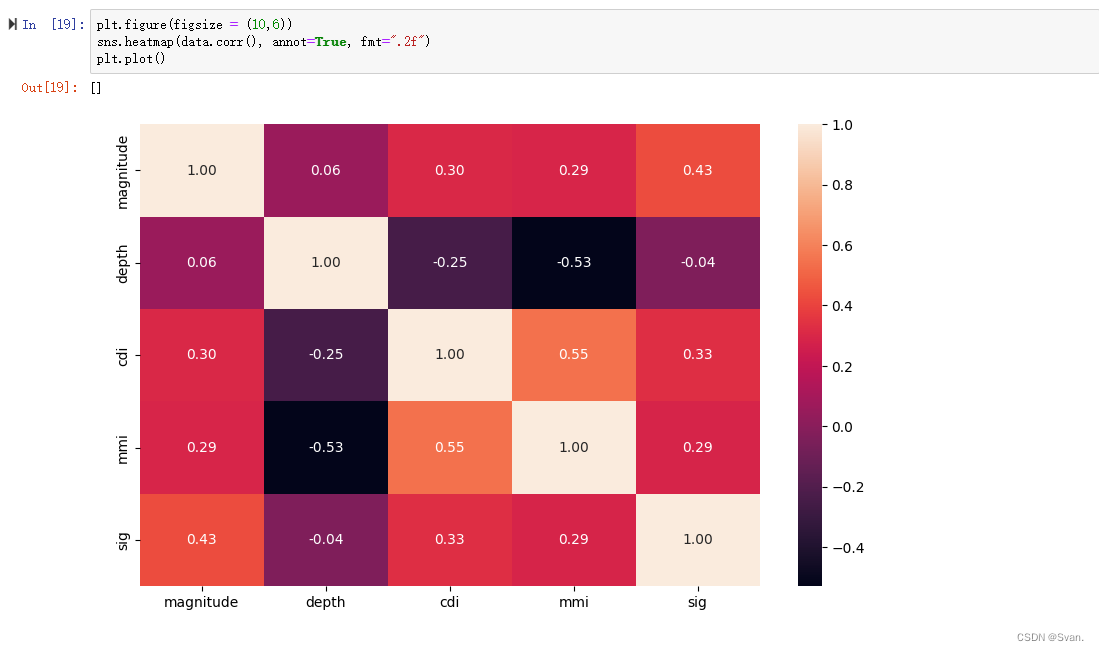
15. 下一步,我们可以在训练数据集上训练各种机器学习模型这些模型的性能可以使用测试数据集进行评估。
models = []
from sklearn.tree import DecisionTreeClassifier
dt = DecisionTreeClassifier(random_state=42)
dt.fit(X_train, y_train)可以使用predict()方法对模型进行预测。模型的性能可以使用指标accuracy_score、classification_report、confusion_matrix。
from sklearn.metrics import classification_report, confusion_matrix, accuracy_score
dt_pred = dt.predict(X_test)
print(accuracy_score(dt_pred,y_test)*100)
print(classification_report(dt_pred, y_test))
sns.heatmap(confusion_matrix(dt_pred, y_test), annot = True)
plt.plot()输出:出现在混淆矩阵对角线上的值(54,64,60,51)表示被模型正确分类的数据点的数量。从准确性来看得分,显然决策树分类器的准确率为88.07%。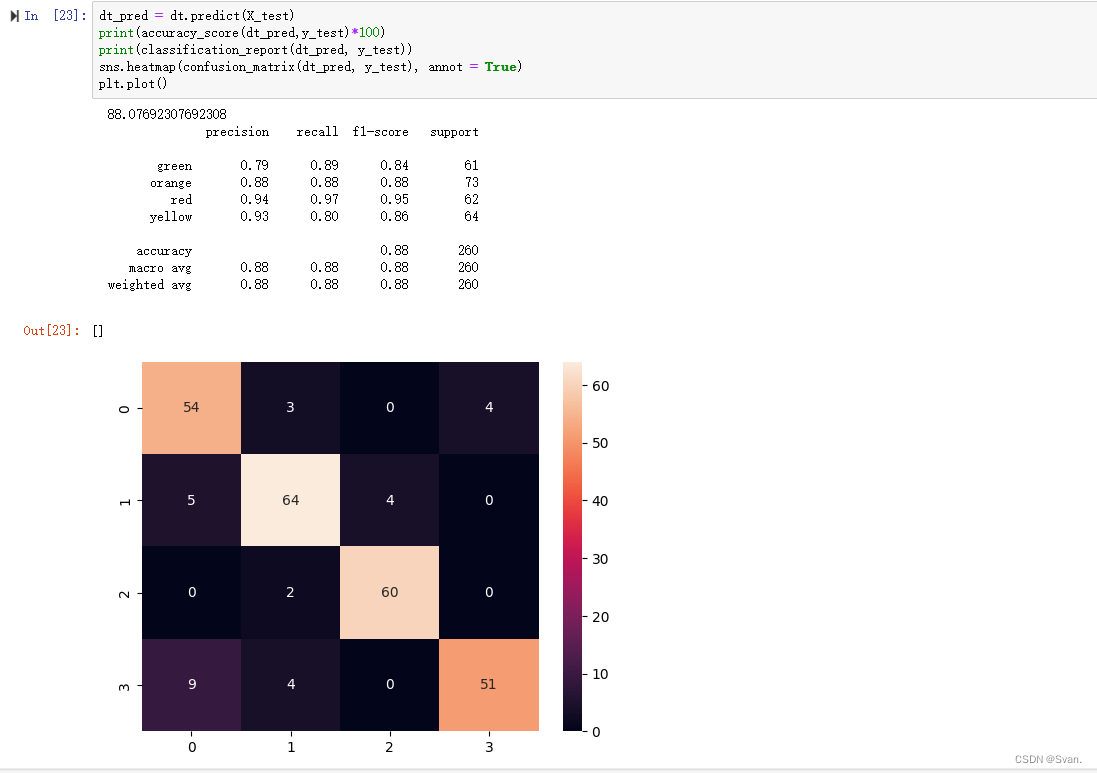
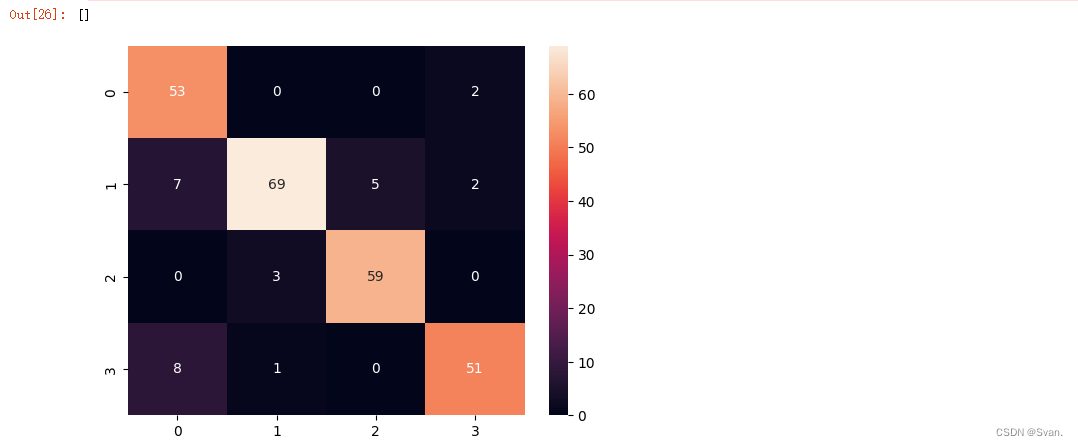
16. 我们要实现的下一个模型是KNN。
from sklearn.neighbors import KNeighborsClassifier
knn = KNeighborsClassifier()
knn.fit(X_train, y_train)该模型的预测方式与之前的预测方式相似
knn_pred = knn.predict(X_test)
print(accuracy_score(knn_pred, y_test)*100)
print(classification_report(knn_pred, y_test))
sns.heatmap(confusion_matrix(knn_pred, y_test), annot = True)
plt.plot()输出:
混淆矩阵和准确度分数可以像前面一样显示。从输出可以明显看出KNN的准确率为89.23%。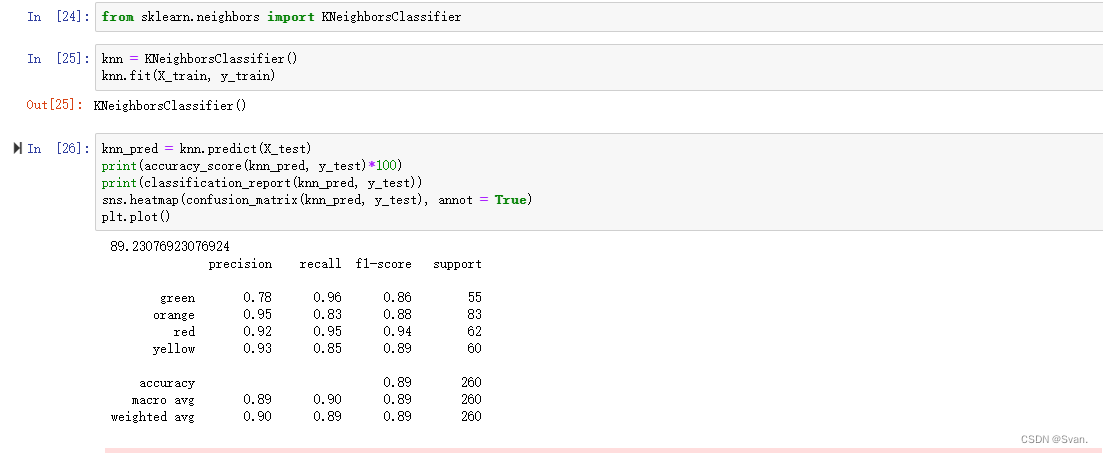
17. 在使用KNN算法之后,我们可以在数据集上使用随机森林分类器。
from sklearn.ensemble import RandomForestClassifier
rf = RandomForestClassifier(random_state=42)
rf.fit(X_train, y_train)来自随机森林分类器的预测可以使用predict()方法进行。混淆矩阵和准确性评分可以像前面一样显示。
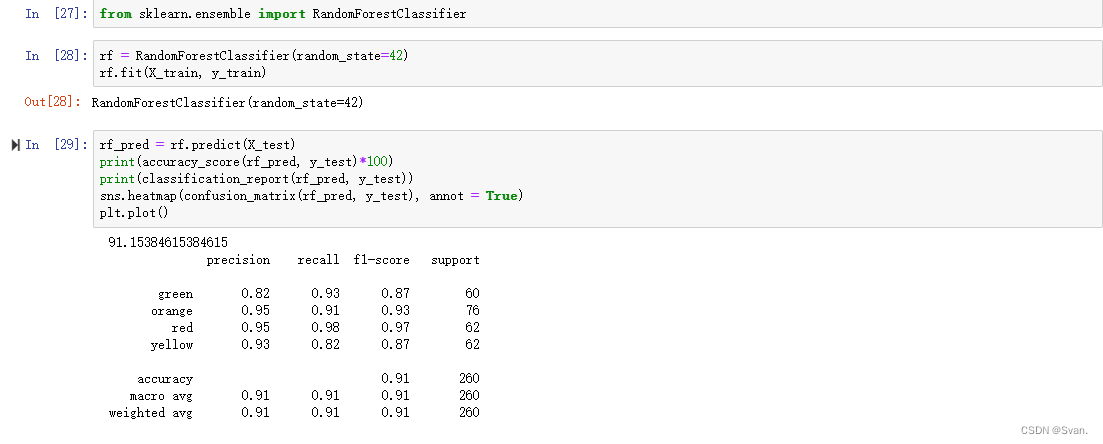
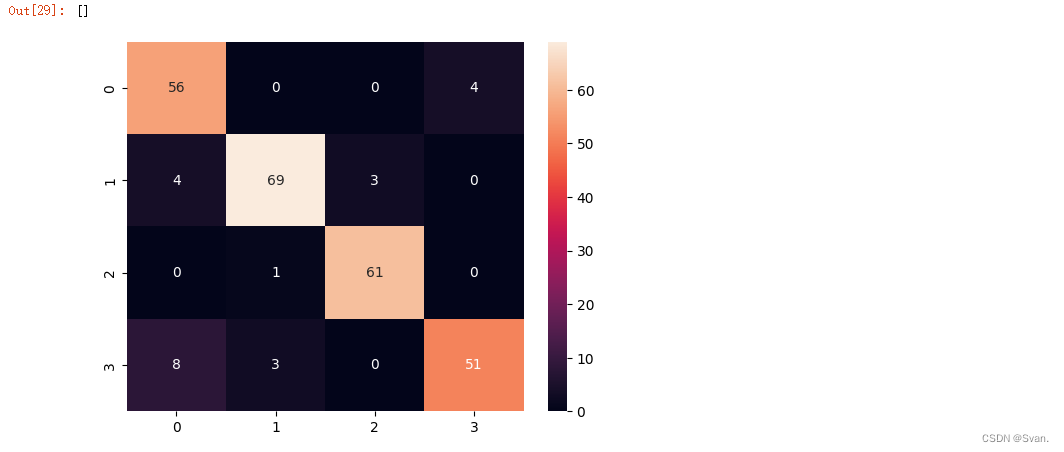
rf_pred = rf.predict(X_test)
print(accuracy_score(rf_pred, y_test)*100)
print(classification_report(rf_pred, y_test))
sns.heatmap(confusion_matrix(rf_pred, y_test), annot = True)
plt.plot()输出:可以看出随机森林分类器的准确率为91.15%。
18. 我们将实现的最后一个模型是梯度增强分类器。
from sklearn.ensemble import GradientBoostingClassifier
gb = GradientBoostingClassifier(random_state=42)
gb.fit(X_train, y_train)混淆矩阵和精度可以像前面那样显示。
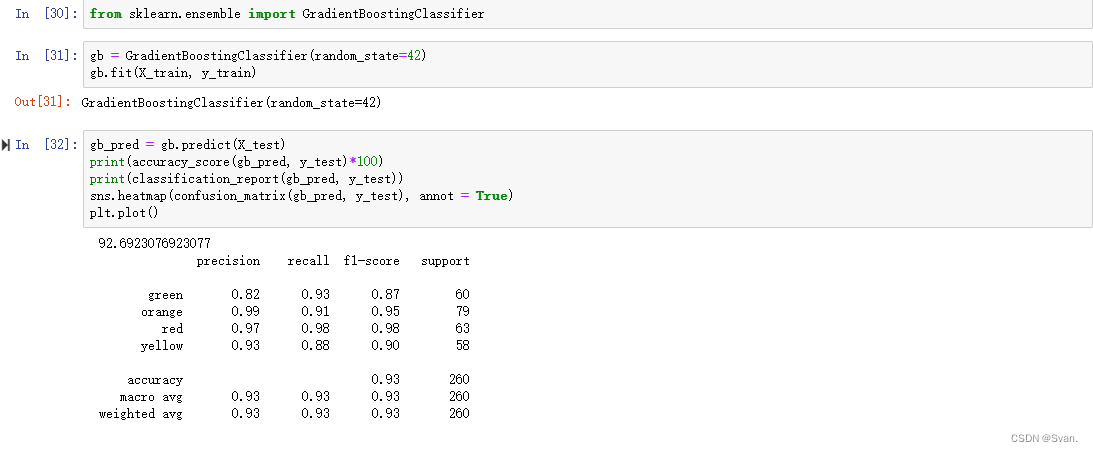
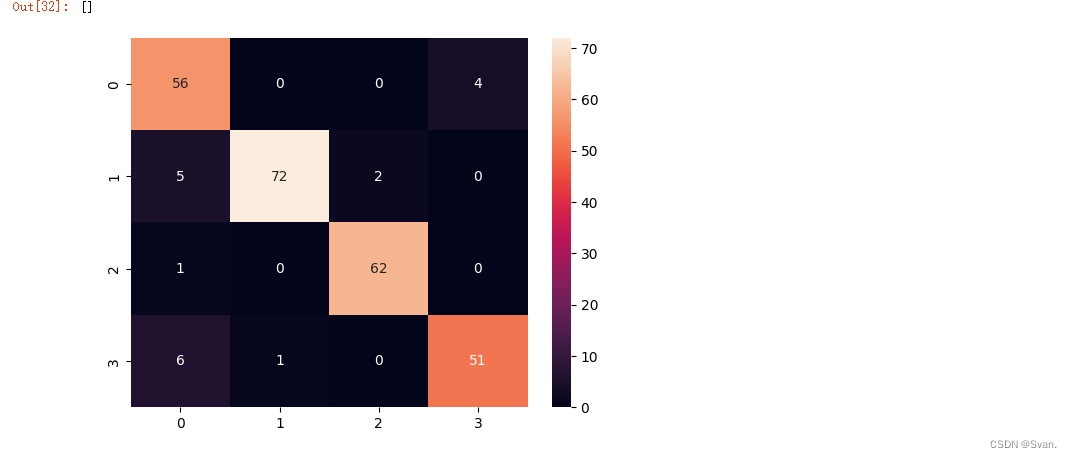
gb_pred = gb.predict(X_test)
print(accuracy_score(gb_pred, y_test)*100)
print(classification_report(gb_pred, y_test))
sns.heatmap(confusion_matrix(gb_pred, y_test), annot = True)
plt.plot()输出:梯度增强算法的准确率为92.69%。
六、总结
总之,机器学习技术在地震预测方面显示出了很好的结果。通过分析各种数据源,如地震记录、地理空间信息等,机器学习模型可以学习模式、趋势和关系,这些可以帮助识别潜在的地震发生。
虽然机器学习模型可以帮助预测地震,但重要的是要注意,这是一个正在进行的研究领域,实现可靠和准确的预测仍然是一项复杂的任务。领域专家和机器学习工程师之间的合作努力对于推进该领域和开发可以帮助早期检测地震的强大模型至关重要。