下面聊聊以下主题:
- 基于条件的分支
- 循环
- 函数
- 属性
- 测试
基于条件的分支
基于条件的分支,可以通过常见的 if、if else 或 if else if else 构造来完成,例如下面的示例:
fn main() { let dead = false; let health = 48; if dead { println!("游戏结束!"); return; } if dead { println!("游戏结束!"); return; } else { println!("你还有机会赢!"); } if health >= 50 { println!("继续战斗!"); } else if health >= 20 { println!("停止战斗并恢复力量!"); } else { println!("躲起来尝试恢复!"); }
}
这将产生以下输出:
你还有机会赢!
停止战斗并恢复力量!
if 语句后的条件必须是布尔值。然而,与 C 语言不同的是,这个条件不需要用括号括起来。在 if、else 或 else if 语句后需要使用 { }(大括号)括起来的代码块。第一个示例还展示了我们可以通过返回值来退出函数。
另外,if else 条件是一个返回值的表达式。这个值可以作为函数调用参数在 print! 语句中使用,或者可以在 let 绑定中赋值,像这样:
let active = if health >= 50 { true } else { false };
println!("我活跃吗? {}", active);
这将打印以下输出:
我活跃吗? false
代码块可以包含多行,但要注意:当返回一个值时,你必须在 if 或 else 块的最后一个表达式后省略分号(参见 第2章 使用变量和类型 中的表达式部分)。此外,所有分支必须始终返回相同类型的值。
这也减少了对三元运算符(?:)的需求,就像在 C++ 中一样;简单地使用 if,如下所示:
let adult = true;
let age = if adult { "+18" } else { "-18" };
println!("年龄是 {}", age); //
这将产生以下输出:
年龄是 +18
循环
对于重复的代码片段,Rust 提供了常见的 while 循环,同样不需要在条件周围加上括号:
fn main() { let max_power = 10; let mut power = 1; while power < max_power { print!("{} ", power); // 打印不换行 power += 1; // 计数器增加 }
}
这将打印以下输出:
1 2 3 4 5 6 7 8 9
要开始一个无限循环,请使用 loop 语句,如下所示:
loop { power += 1; if power == 42 { // 跳过此次迭代的剩余部分continue; } print!("{} ", power); if power == 50 { print!("好了,今天就到这里"); break; // 退出循环 }
}
打印包括 50 但不包括 42 的所有 power 值;然后循环通过 break 语句停止。由于 continue 语句,42 不被打印。因此,loop 相当于 while true,带有条件的 break 的 loop 模拟其他语言中的 do while。
当循环嵌套在彼此内部时,break 和 continue 语句适用于直接包围的循环。任何循环语句(包括我们接下来将看到的 while 和 for 循环)都可以在前面带有标签(表示为 labelname:),以便我们跳转到下一个或外部的循环,如下代码片段所示:
'outer: loop { println!("进入外层地牢。"); inner: loop { println!("进入内层地牢。"); // break; // 这将退出内层循环break 'outer; // 跳转到外层循环 } println!("这宝藏永远无法到达。"); } println!("已退出外层地牢!");
这将打印以下输出:
进入外层地牢。
进入内层地牢。
已退出外层地牢!
显然,使用标签会使代码阅读更困难,因此请谨慎使用。幸运的是,Rust 中不存在 C 语言中臭名昭著的 goto 语句!
使用 for 循环和范围表达式可以完成从起始值 a 到结束值 b(不包括 b)的变量 var 的循环,如以下语句所示:
for var in a..b
以下是一个打印数字 1 到 10 的平方的示例:
for n in 1..11 { println!("{} 的平方是 {}", n, n * n);
}
一般来说,for 循环遍历一个迭代器,即逐个返回一系列值的对象。范围 a…b 是最简单的迭代器形式。
每个后续的值都绑定到变量 n 并在下一个循环迭代中使用。当没有更多的值时,for 循环结束,并且变量 n 随之离开作用域。如果我们在循环中不需要变量 n 的值,可以用 _(下划线)替换,如下所示:
for _ in 1..11 { }
C 风格 for 循环中的许多错误,如计数器的越界错误,在这里不会发生,因为我们是在遍历一个迭代器。
变量也可以用在范围中,如以下片段所示,它打印九个点:
let mut x = 10;
for _ in 1..x { x -= 1; print!("."); }
函数
每个 Rust 程序的起点都是一个名为 main() 的函数,它可以进一步细分为单独的函数,以便代码重用或更好地组织代码。Rust 不在乎这些函数的定义顺序,但将 main() 函数放在代码的开头是个好习惯,因为这样可以更好地概览代码结构。Rust 吸收了许多传统函数式语言的特性;我们将在高阶函数与错误处理* 中看到这方面的例子。
让我们从一个基础函数示例开始:
fn main() { let hero1 = "吃豆人"; let hero2 = "里迪克"; greet(hero2); greet_both(hero1, hero2);
} fn greet(name: &str) { println!("嗨,伟大的{},你来这里是为了什么?", name);
} fn greet_both(name1: &str, name2: &str) { greet(name1); greet(name2);
}
这将输出以下内容:
嗨,伟大的里迪克,你来这里是为了什么?嗨,伟大的吃豆人,你来这里是为了什么?嗨,伟大的里迪克,你来这里是为了什么?
像变量一样,函数具有必须唯一的变量 snake_case 名称,其参数(必须进行类型化)用逗号分隔,如此示例所示:
name1: &str, name2: &str
它看起来像一个绑定,但没有 let 绑定。强制对参数进行类型化是一个优秀的设计决策,因为它为函数的调用代码提供了文档,并允许在函数内部进行类型推断。这里的类型是 &str,因为字符串存储在堆上
上面的函数没有返回任何有用的东西(事实上,它们返回单位值()),但如果我们希望一个函数实际返回一个值,其类型必须在箭头 -> 之后指定,如此示例所示:
fn increment_power(power: i32) -> i32 { println!("我的力量将会增加:"); power + 1
} fn main() {
let power = increment_power(1); // 调用函数
println!("我现在的力量等级是:{}", power);}
执行时,它打印出如下输出:
我的力量将会增加:
我现在的力量等级是:2
函数的返回值是其最后一个表达式的值。请注意,为了返回一个值,最后一个表达式不得以分号结束。如果你以分号结束会发生什么?试试看:在这种情况下会返回单位值(),编译器会给你以下错误:
error: not all control paths return a value
我们可以写 return power + 1 作为最后一行,但那并不是惯用代码。如果我们想要在最后一行代码之前从函数返回一个值,我们必须写 return value; 如下所示:
if power < 100 { return 999 }
如果这是函数中的最后一行,你应该这样写:
if power < 100 { 999 }
一个函数只能返回一个值,但这并不是一个很大的限制。例如,如果我们有三个值 a、b 和 c 要返回,就用一个元组 (a, b, c) 将它们组合起来并返回。我们将在下一章更详细地检查元组。
一个从不返回的函数称为发散函数,它的返回类型是 !。
例如:
fn diverges() -> ! { panic!("这个函数永远不返回!");
}
它可以用作任何类型,例如用于隔离异常处理,如此示例所示。
一个函数可以是递归的;这意味着该函数调用自身,如下示例所示:
fn main() { let ans = fib(10); println!("{}", ans);
} fn fib(x: i64) -> i64 { if x == 0 || x == 1 { return x; } fib(x - 1) + fib(x - 2)
}
确保递归停止通过包括一个基本情况,在这个例子中,当函数被调用 x 等于 1 和 0 时。
函数有类型,例如,之前代码片段中函数 increment_power 的类型如下:
Fn(i32) -> i32
fn 函数通常表示一个函数类型。
在 Rust 中,你也可以在另一个函数内部写一个函数(称为嵌套函数),这与 C 或 Java 不同。这应该只用于本地需要的小型辅助函数。
作为练习,尝试以下操作:
了解到 if 可以是一个表达式,简化以下函数:
fn verbose(x: i32) -> &'static str { let result: &'static str; if x < 10 { result = "小于 10"; } else { result = "10 或更多"; } return result;
}
参见第3章\exercises\ifreturn.rs 中的代码。
静态的 in 和 static str 变量是所谓的生命周期指示,需要在这里指示函数返回值将存在多久。静态生命周期是可能的最长生命周期,这样的对象在整个应用程序中存活,并且在其所有代码中都可用。
这个返回给定数字变量 x 的绝对值的函数有什么问题?
fn abs(x: i32) -> u32 { if x > 0 { x } else { -x } }
更正并测试它(参见第3章/exercises/absolute.rs 中的代码)。
文档化一个函数
让我们展示一个文档化代码的例子。在 exdoc.rs 文件中,我们如下文档化了一个名为 cube 的函数:
fn main() { println!("4 的立方是 {}", cube(4));
}
/// 计算立方 `val * val * val`。
///
/// # 示例
///
/// ```
/// let cube = cube(val);
/// ```
pub fn cube(val: u32) -> u32 { val * val * val
}
如果我们现在在命令行上调用 rustdoc exdoc.rs,将会创建一个 doc 文件夹。对于一个项目,请在项目的根文件夹中执行 cargo.doc。这将包含一个子文件夹 exdoc,其中有一个 index.html 文件,这是一个网站的起点,为每个函数提供文档页面。例如,fn.cube.html 显示如下内容:
- 文档会详细介绍
cube函数,包括它的定义、用途、示例代码等。 - 页面会以友好和清晰的格式展示所有相关信息,使开发者能够快速理解和使用
cube函数。
Rustdoc 是一个非常强大的工具,它可以自动生成代码的文档。这对于保持项目的文档最新且易于理解非常有帮助。通过在代码中包含适当的注释,Rustdoc 能够创建详尽的文档,这在大型项目或公共库中尤其重要。通过这种方式,即使是新加入项目的开发者也可以快速了解代码的工作方式和目的。
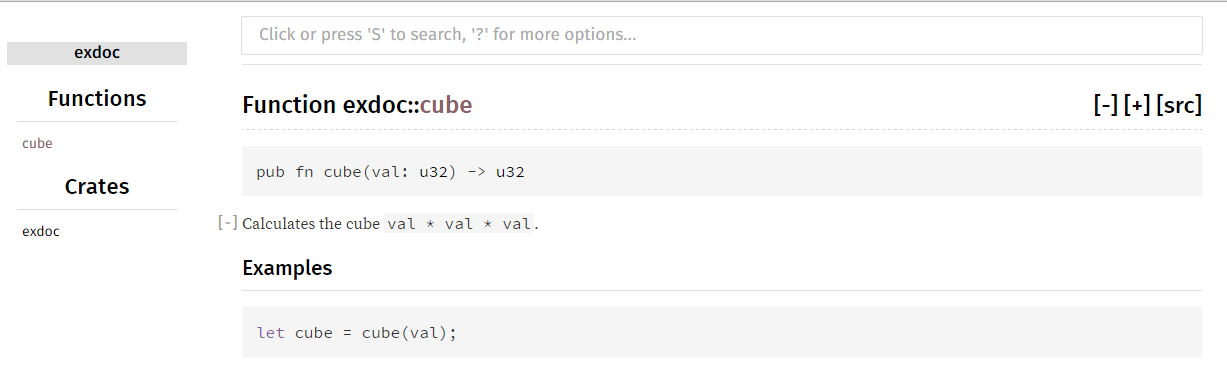
点击 exdoc 链接会返回到索引页面。
文档注释是用 Markdown 编写的(简要介绍见 https://en.wikipedia.org/wiki/Markdown)。它们可以包含由 # 预先的特殊部分。例子包括 Panics、Failures 和 Safety。代码放在 ```之间。要被文档化的函数必须属于公共接口,因此必须以 pub 为前缀。
可以使用 //! 注释来文档化模块,这些注释在初始 { 之后开始。
更多信息请见 https://doc.rust-lang.org/book/first-edition/documentation.html。
属性
在编译器中,你可能已经看到了像 #[warn(unused_variables)] 这样的警告示例。这些是属性,代表了关于代码的元数据信息。你可以在代码中自己使用它们,它们被放置在它们要说明的项目(比如一个函数)之前。例如,它们可以禁用某些类别的警告、打开某些编译器功能,或标记函数作为单元测试或基准测试代码的一部分。
条件编译
如果你想要一个函数只在特定的操作系统上工作,那么用 #[cfg(target_os = “xyz”)] 属性来标注它(其中 xyz 可以是 “windows”、“macos”、“linux”、“android”、“freebsd”、“dragonfly”、“bitrig” 或 “openbsd” 中的一个)。例如,下面的代码在 Windows 上运行正常:
fn main() { on_windows();
} #[cfg(target_os = "windows")]
fn on_windows() { println!("这台机器的操作系统是 Windows。")
}
这会产生以下输出:
这台机器的操作系统是 Windows。
如果我们尝试在 Linux 机器上构建这段代码,我们会得到以下错误:
error: unresolved name `on_windows
这段代码甚至无法在 Linux 上构建,因为属性阻止了它!此外,你甚至可以制作你自己的自定义条件,详见 http://rustbyexample.com/attribute/cfg/custom.html。
属性也在测试和基准测试代码时使用。
测试
我们可以用 #[test] 属性前缀一个函数,以表明它是我们应用程序或库的单元测试的一部分。然后我们用以下命令编译并运行生成的可执行文件:
rustc --test program.rs
这将用测试运行器替换 main() 函数,并显示用 #[test] 标记的函数的结果,例如:
fn main() { println!("No tests are compiled,compile with rustc --test! ");
} #[test]
fn arithmetic() { if 2 + 3 == 5 { println!("You can calculate!"); }
}
测试函数,像示例中的 arithmetic(),是黑盒子,它们没有参数或返回值。当这个程序在命令行上运行时,它会产生以下输出:
但是,如果我们将测试改为 if 2 + 3 == 6,测试同样会通过!试试看。事实证明,当测试函数的执行没有导致崩溃(在 Rust 术语中称为 panic)时,它们总是通过的,只有在发生 panic 时才会失败。这就是为什么测试(或调试)必须使用 assert_eq! 宏(或其他类似的宏),如下面的代码所示:
assert_eq!(2, power);
这个语句测试变量 power 是否具有值 2。如果是,什么也不会发生,但如果 power 不等于 2,就会发生异常并使程序 panic,产生以下命令:
thread '<main>' panicked at 'assertion failed.
在我们的第一个函数中,我们会写测试 assert_eq!(5, 2 + 3);,这会通过。
我们也可以使用 assert! 宏,以 assert!(2 + 3 == 5); 的形式写。如果括号内的表达式为真,这个宏什么也不做,但如果表达式为假,它会发生 panic。
这些宏在普通代码中也很有用,用于确保满足特定条件。只需注意,当它们失败时,它们是在程序运行时发生的!
当函数发生 panic 时,测试失败,如以下示例所示:
#[test]
fn badtest() { assert_eq!(6, 2 + 3);
}
这会产生以下输出:
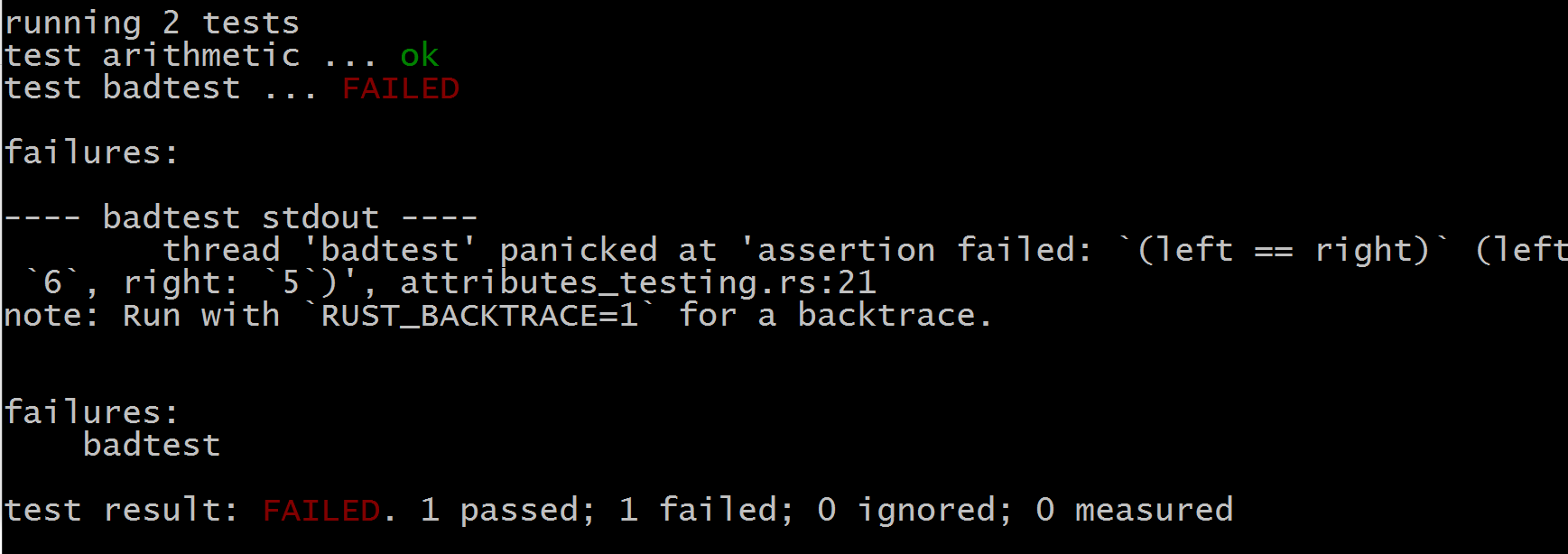
如果你想确保一个测试失败,请使用 #[should_panic] 属性,像这样:
#[test]
#[should_panic(expected = "assertion failed")]
fn failing_test() { assert!(6 == 2 + 3);
}
在这个例子中,failing_test 通过了,因为这是我们所期望的!我们最好添加 expected = "assertion failed" 文本,以确保 panic 是由断言失败引起的。
你可以通过给它额外的 #[ignore] 属性来禁用一个测试。
通过的测试以绿色显示,失败的测试以红色显示。
通过使用宏调用 assert_eq!(actual, expected) 将实际函数结果与预期结果进行比较来对你的函数进行单元测试。因此,考虑如下的一个函数:
pub fn double(n: i32) -> i32 { n * 2
}
它是这样被测试的:
assert_eq!(double(42), 84);
pub 表示 double 是一个公共方法,可以被使用我们库的客户端代码调用。普通的私有方法不应该被显式测试,它们应该通过调用测试它们的公共方法来检查。
如果你不使用 test 属性编译,比如以下命令:
rustc attributes_testing.rs
没有测试函数被编译,当运行时 main() 函数会执行,在我们的例子中会打印以下输出:
No tests are compiled, compile with rustc --test!
在正常构建中不包括测试代码。
在真实项目中,测试将被放在一个单独的测试模块中
使用 cargo 进行测试
一个可执行项目,或者在 Rust 中称为 crate,需要有一个启动函数 main(),但是一个库 crate,用于其他 crate,不需要 main() 函数。如下使用 cargo 创建一个新的库 crate mylib:
cargo new mylib
这将创建一个包含以下内容的源文件 lib.rs 的子文件夹 src:
#[cfg(test)]
mod tests { #[test] fn it_works() { }
}
因此,创建了一个没有自己代码的库 crate,但它包含一个用 cfg(test) 属性注释的测试模板。这个属性表明,接下来的代码只会在测试模式下编译。为了与普通库代码区分开来,使用像这样的前缀 not 在属性中:
#[cfg(not(test))]
fn main() { println!("正常模式,没有编译测试");
}
在测试部分,你可以添加你对库函数编写的单元测试。要运行这些测试,请转到项目根文件夹并输入 cargo test,这将产生与前一节类似的输出。
你可以通过提供其函数名称来运行单个测试,像这样:
cargo test it_works
命令 cargo test 尽可能并行运行测试。如果这可能造成问题,比如一个测试依赖于另一个测试,你可以使用以下命令在一个线程中执行它们所有:
cargo test -- --test-threads=1
测试模块
在更现实、更大型的项目中,测试与应用程序代码是分开的:
- 单元测试被收集在一个模块 test 中
- 集成测试被收集在 tests 目录的 lib.rs 文件中
Cargo 为库生成的代码将测试分组到一个称为 mod tests 的模块内
为了使用主代码中定义的函数,我们必须添加命令 use super::*;,这会将所有这些函数带入测试模块的范围内:
pub fn double(n: i32) -> i32 { n * 2
} #[cfg(test)]
mod tests { use super::*; #[test] fn it_works() { assert_eq!(double(42), 84); }
}
模块 tests 通常用来包含你的库函数的单元测试。
使用函数和控制结构 中的 cube 函数作为另一个例子,使用 cargo 新建项目:cargo new cube。我们用以下代码替换 src\lib.rs 中的代码:
pub fn cube(val: u32) -> u32 { val * val * val
} #[cfg(test)]
mod tests;
在第二行,我们用测试配置属性先声明我们的测试模块。现在这个模块的代码放到同一个文件夹下的 tests.rs 文件中,这样它们就可以更清晰地与我们的库代码分开:
use super::*; #[test]
fn cube_of_2_is_8() { assert_eq!(cube(2), 8);
}
集成测试放在 tests 文件夹中的 lib.rs 文件中,我们需要手动创建它:
extern crate cube;
use cube::cube; #[test]
fn cube_of_4_is_64() { assert_eq!(cube(4), 64);
}
这里,我们需要用 extern 命令导入 cube crate,并用它的模块名 cube 来限定函数名 cube(或者使用 use cube::cube;)。
像之前一样,测试代码只有在我们给出 cargo test 命令时才会被编译和运行,结果如下:
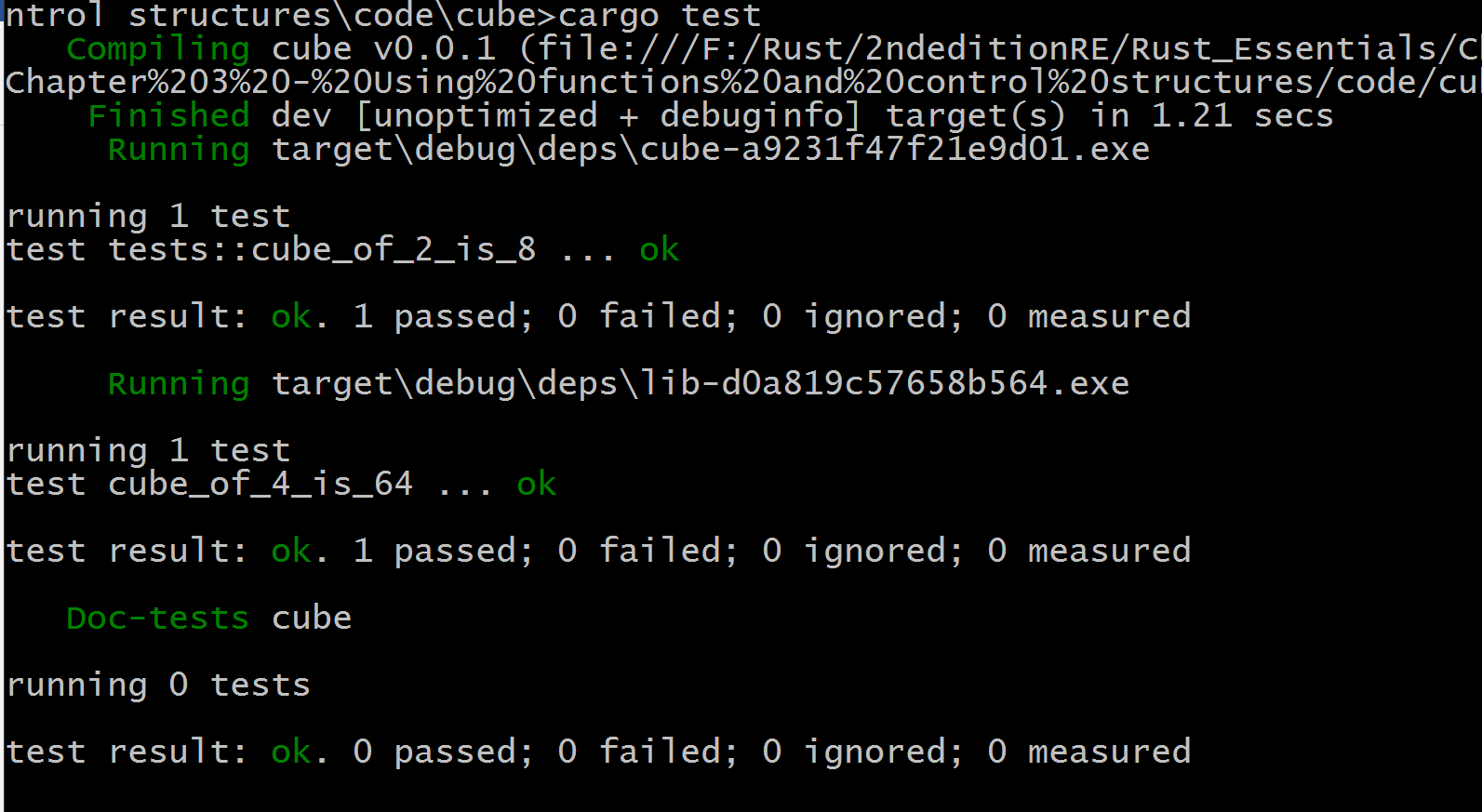
我们看到我们的两个测试(单元测试和集成测试)都通过了。输出结果显示,如果文档中存在测试,它们也会在最后执行。
如果你想要能够使用像 describe 和 it 这样的更类似 Speclike 框架的关键词,你肯定应该看看 stainless crate (https://github.com/reem/stainless)。