文章目录
- 共享内存的通信速度
- 消息队列
- msgget
- msgsnd
- msgrcv
- msgctl
- 信号量
- semget
- semctl
- 内核看待ipc资源
- 单独设计的模块
- ipc资源的维护
本篇主要是基于共享内存,延伸出对于消息队列和信号量,再从内核的角度去看这三个模块实现进程间通信
共享内存的通信速度
共享内存是所有进程间通信里面速度最快的,并且是没有质疑的,何以见得这个结论呢?
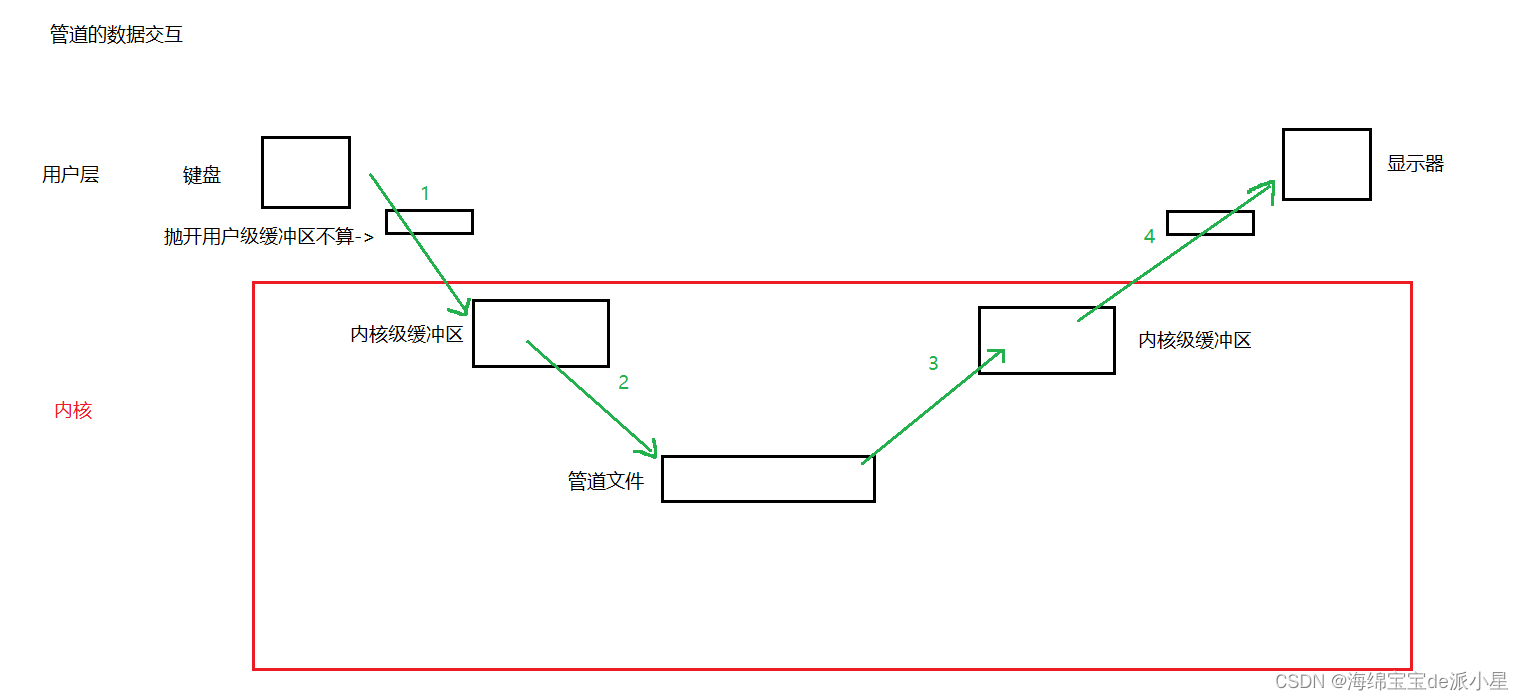
要说这个结论,还要从管道说起,对于进程来说,如果想要使用管道进行通信,那么首先要有进程的PCB和对应的进程地址空间,其次如果选择管道进行通信,那么就会建立管道之后,将用户自己的数据交给另外一个进程,通过write的系统调用写到缓冲区中,本质上就是把用户级的缓冲区直接经过系统调用拷贝到内核的管道中,对于读端来说,就是用read系统调用再读取信息,相当于是把内核中的数据经过read系统调用,把数据拷贝到用户空间内,此时就完成了从进程a到进程b数据通信的目的
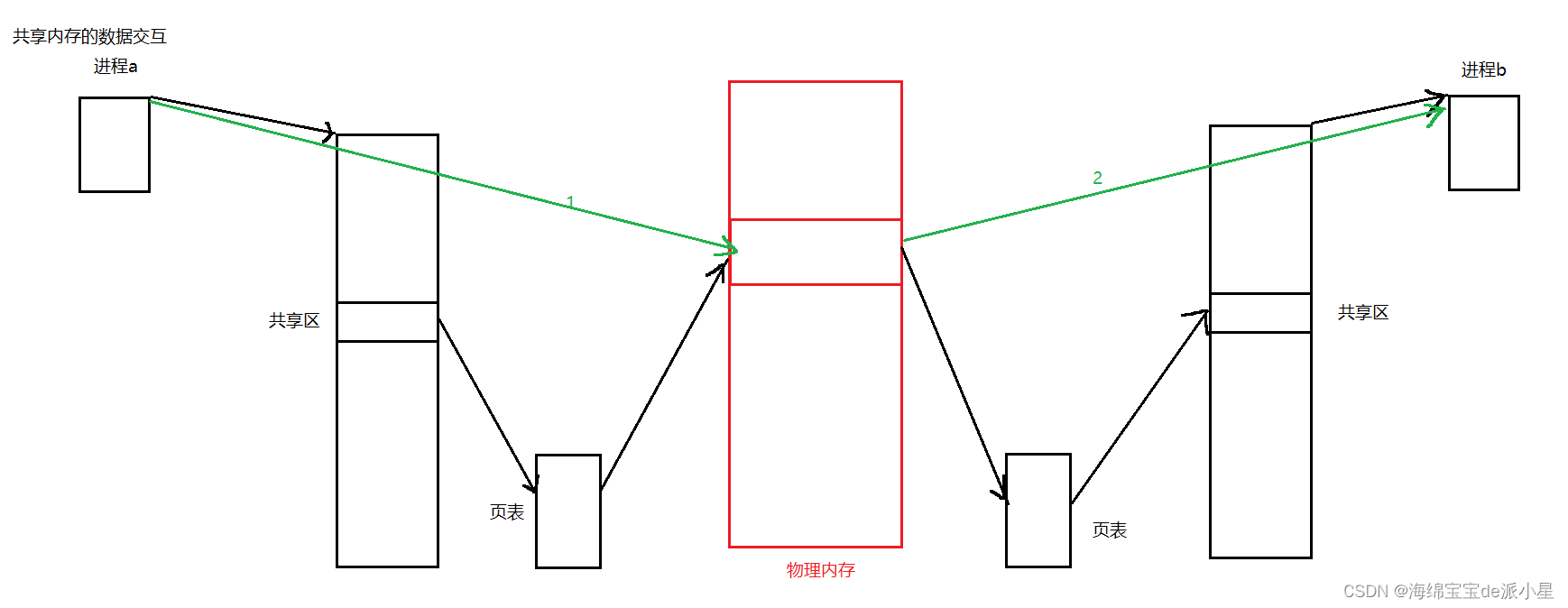
而对于共享内存来说,创建好共享内存之后,经过挂接在自己的地址空间的共享区中就能找到这个区域,之后就可以在这个共享内存中进行写入,写入后共享内存这里就会立刻有这段信息,在这个过程中是没有任何系统调用的,写的信息立刻就能看到,没有任何延误,换而言之,这两个进程之间不需要通过内核进行拷贝,甚至都不需要用户定义的缓冲区,直接向共享内存中写入信息,用户立刻就能看到,可以理解为是把用户级别的缓冲区合并成一个缓冲区,只要进程a向里面写,进程b立刻就能看到,有效的减少了数据通信过程中经由数据拷贝造成的消耗问题
因此我们说,对于共享内存来说,它的效率体现在可以减少数据拷贝,不需要经过用户到内核,内核到用户这样的拷贝,而是直接在用户的层面上,进程a向共享内存写信息,进程b就能看到,甚至可能都不需要缓冲区的概念,所以是高效的
那能减少多少次拷贝呢?
对于这个问题来说,这里简单做个解释,具体可能会因为实际场景和配置略有差距
假设现在有输入的函数需求,数据也从键盘输入了,那么从文件的角度来讲,就相当于从文件里面读取了信息,而从文件中读取信息也算是一层拷贝,而现在有输出的需求,需要把数据输出到显示器上,而现在的数据是存储到内存或者是缓冲区中,而从内存刷新到外设这个过程,也算是一层拷贝,而实际上,CPU只认识内存,所以想要让CPU处理数据,就必须把外设的信息加载到内存中,再从内存处理后刷新到外设上,而这个过程实际上就是把数据从一个设备拷贝到另外一个设备上,凡是数据迁移,都可以看成是拷贝,所以对于管道文件来说,不管是write系统调用还是read系统调用,都是和内核进行交互,从内核交互的角度来讲,这两个函数其实就是一个拷贝的函数,那么来回进行数据的拷贝,效率自然不能和共享内存比
那么回到这个问题,到底可以减少多少次拷贝?假设现在有硬件,那么从键盘到显示器这个过程,输入数据是需要用户自己提供缓冲区,把数据从键盘读取到缓冲区中,再把数据从缓冲区拷贝到管道当中,而最终目标是要打印到显示器上,那显示器也是有对应的缓冲区的,所以就把数据再拷贝到缓冲区中,最终就能写到显示器中,这么一套理论,保守的来讲都有四次的拷贝过程,如果把语言本身提供的缓冲区也加上,只会比这个过程更多
那如果对于共享内存来说呢?从键盘中读取的数据,直接写到共享内存中,读取的进程只需要把共享内存中的数据显示到显示器上就可以了,此时就相当于第一次拷贝,将数据从外设写到共享内存中,第二次把共享内存中的数据写到显示器上,两次拷贝就刷新过去了,直接就省去了内核之间的拷贝过程,就算不考虑语言级别的缓冲区,也能减少两次拷贝
消息队列
消息队列提供一个进程给另外一个进程发送数据块的能力,那如何理解这句话呢?先画出下面的示意图
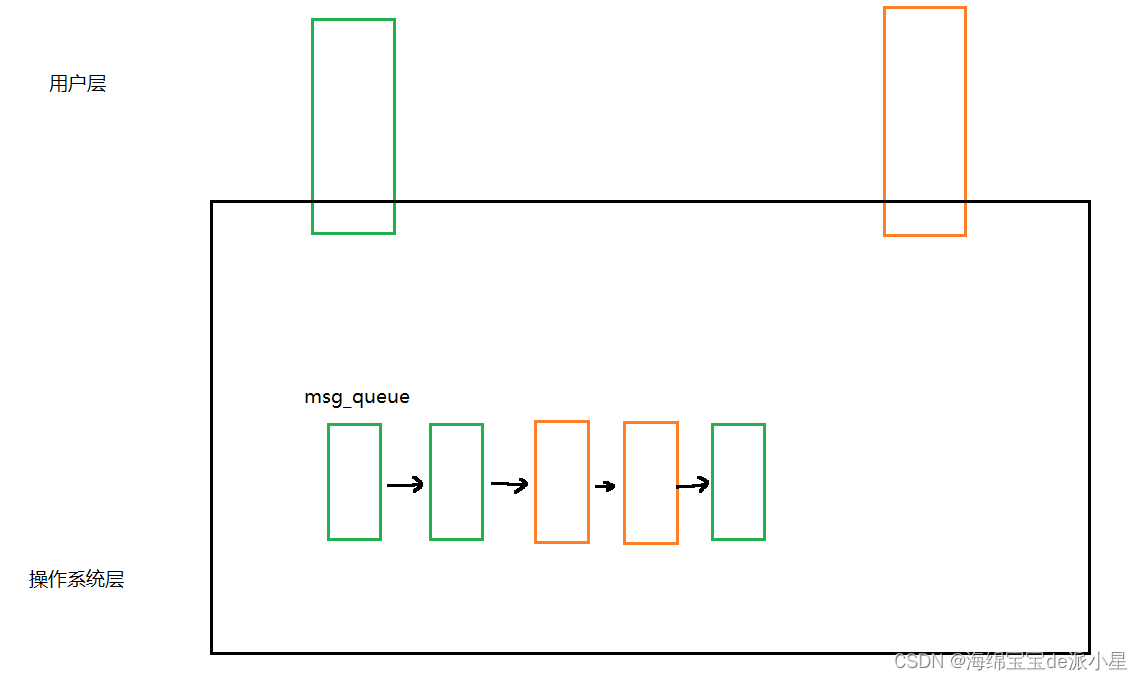
这是对于消息队列画出的最基本的示意图,在ipc资源当初被设计的时候,能够在内核层面上创建共享内存,创建对应的结构来管理这样的共享内存,那在操作系统层面上也可以创建一个队列,这个队列的名字就叫做msg_queue,这个队列刚开始是空的,但是用户是有数据的,通过一定的接口传递到队列中,此时就会在队列的底层形成一个一个的节点,这里可以理解成是链队列,把这个链队列链入到这个队列之中
消息队列的本质是要进行进程间通信,而只要涉及到进程间通信就离不开的话题是让两个不同的进程看到同一份资源,这也是在先前已经建立起来的思想观念,那么基于这个原因,进程a发送的消息队列中的内容必然是需要让进程b见到的,所以就有了接口:
msgget

它其实和共享内存是很相似的,也是从系统V中获取一个消息队列的标识符,只要调用了这个接口,那么就可以在内核中创建出一个消息队列,这个消息队列就可以使用了
那随之而来的下一个问题是,现在进程a创建出对应的消息队列,也满足了让不同的进程看到同一份资源这样的一个基本的条件,但是现在面临的问题是,如果进程a向消息队列中写信息,进程b也向消息队列中写信息,那么如何去进行区分呢?消息队列中的节点对于不同的进程来说想要看到的信息当然是不一样的,所以必然有对应的标识符,由进程a创建的数据节点中就会带有进程a的标识符,由进程b创建的节点就会有进程b的标识符,这样不同的进程在识别到某个资源中没有自己所对应的标识符就不会识别了,而是只会识别到自己对应的标识符
消息队列由于和共享内存一样,都是隶属于系统V内部的结构,所以它们之间必定会遵循一定的标准,所以从接口或是其他的层面上都几乎相似,因此消息队列的生命周期也是随内核的,而操作系统中各种各样的进程也都会有通信的需求,如果创建出各种各样的消息队列,那么操作系统也必然会为这一个一个的消息队列进行维护,所以从逻辑上讲,消息队列和共享内存基本上是一样的,所以对于消息队列的管理,就转换成了对于描述该消息队列的数据结构对象的增删查改,这样就把消息队列管理起来了
msgsnd
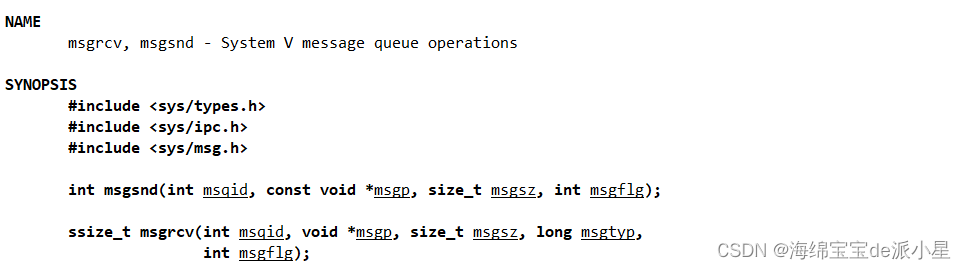
发送数据块到消息队列
msgrcv

获取消息队列中的数据块
msgctl

这个接口也和共享内存基本一致,这里不再过多描述
信号量
信号量本质上就是一种计数器,用来保护共享资源,未来可能会有多个线程看到同一个公共资源,那在执行和访问共享资源的过程中,就可能会产生问题,例如一个进程正在写信息,另外一个进程就已经来读了,那么就会产生数据干扰,这当然是不被操作系统认可的行为,为了避免这样的问题导致内部数据紊乱,所以就引入了信号量的概念,来保护操作系统内部的公共资源,这是对于信号量最初步的理解
semget

这是信号量的创建接口
semctl

这是信号量的控制接口,和消息队列以及共享内存不太一样的是,多了一个可变参数,所以对于信号量的控制相比起其他来说要略复杂一些
消息队列和共享内存都有具体管理的数据结构对象,所以对于信号量也不例外,肯定有其对应的管理对象,所以也会有对应的struct ipcperm结构体对象
对于信号量之后的其余内容,放在之后的内容里,这个模块本身主要是要对于共享内存的理解,但由于消息队列和信号量都是ipc资源,所以拿来一谈,之后对于信号量还有更多的内容补充
内核看待ipc资源
下面进行的模块是,内核是如何对待ipc资源的
上述有了三种共享资源,有共享内存,消息队列,信号量,由于这三个模块都是遵循一套标准做出来的,所以也是比较相似,例如接口的设计,数据结构的管理方式,以及返回的id值,那对于操作系统来说,是不是应该把这些也进行统一的管理呢?答案是肯定的
单独设计的模块
第一个想要输出的结论是,这个模块是操作系统内部单独设计出的模块,对于模块的概念,大体上可以细分为进程管理,内存管理,文件管理,驱动管理,这是操作系统的四大管理模块,而对于ipc资源的管理也是一个模块,只不过是下属的细分模块,不属于最大的四个管理模块,有了这个概念之后,那么在操作系统内部是如何进行管理的呢?
ipc资源的维护
ipc资源是如何在内核中进行维护的呢?现在有三种共享资源,这三种共享资源又有它们对应的id,key值,这些分散的数据理应被管理起来,事实上操作系统也确实把他们管理起来了
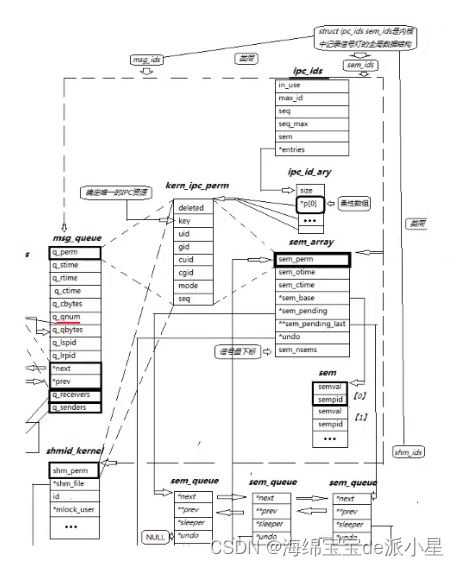
那在内核中是如何进行数据维护的呢?在操作系统内部存在这样的结构
struct ipc_id_ary
{int size;struct kern_ipc_perm *p[0];
}
这个结构体中存储的是数组元素个数以及一个柔性数组,在上图中也有对应,这里单独将其拿出分析
那生成这样的一个结构,存放的数据类型是kern_ipc_perm的一个结构体类型的指针,这个指针会指向一个指针数组,这个指针数组中存储的不是其他信息,存储的是具体的ipc资源的结构体的开头的第一个元素,这也就是为什么在内核中不管是消息队列还是共享内存还是信号量,它们的第一个元素都是一个perm类型的字样,就是为了方便于将这个内容统一管理到这样的一个结构体中,这样就能把所有的ipc资源统一用指针数组来管理起来
那这有什么用?用处就是未来可以通过这个内容找到对应的内容,在实际的使用中,可以通过数组中的一个指针,找到它对应的属于哪个共享资源,然后转换成对应的类型,有了起始地址和偏移量,整个数组内的对应元素的各种内容也就都有了,这样就能做到进行数据的访问过程
因此有了这样的结构,之后再管理所有的ipc资源的时候,在设计模式中就将所有内核结构的第一个成员设计成一样的,都是key值,未来在辨别这些ipc资源是否存在的时候,只需要遍历这个数组指针,在这个数组中找到各个内容中的key值,然后判断这个key值是否存在就可以了,如果不存在就进行创建,因此往后就可以统一用数组的方式访问对应的资源,如果想要找到对应资源中的其他信息也可以做出指针对类型做强转来定位到具体的位置
整个流程其实有些类似于C++中的多态,多态的概念已经不是第一次提出了,再对于外设作为文件系统的篇章中,已经讲述了虚拟文件系统就有些类似于多态,而在这里也是第二次提出对于多态的概念,多态就是令子类去继承基类,那么对应到ipc的模式中,每一个具体的ipc资源填充不同的属性,但是开头的元素都一样,再定义一个指针数组,指针数组都会指向一个具体的ipc资源,这就是一个典型的多态的过程
在Linux内核当中,管理System V版本的ipc资源,虽然内部实现的差异比较大,但是利用抽象的方式还是用c语言实现了多态,最终把所有的ipc资源都收拢在了一个数组中,这样对于ipc资源的管理就转换成了对于这个数组的增删查改,这样就做到了管理好共享资源