拦截器和过滤器有什么区别?
拦截器(Interceptor)和过滤器(Filter)都是用于在请求道道目标资源的之前或之后进行处理的组件。主要区别有以下几点:
- 依赖对象不同:过滤器是来时Servlet,而拦截器是来自Spring
- 底层实现不同:过滤器是基于方法回调实现的。拦截器是基于动态代理(底层是反射)实现的
- 触发时机不同:请求执行顺序是:请求进入容器、进入过滤器、进入Servlet、进入拦截器、执行控制器(Controller),所以过滤器和拦截器的执行时机是,过滤器现调用,拦截器在执行
- 支持的项目类型不同:过滤器是 Servlet 规范中定义的,所以过滤器要依赖 Servlet 容器,它只能用在 Web 项目中;而拦截器是 Spring 中的一个组件,因此拦截器既可以用在 Web 项目中,同时还可以用在 Application 或 Swing 程序中;
- 使用的场景不同:因为拦截器更接近业务系统,所以拦截器主要用来实现项目中的业务判断的,比如:登录判断、权限判断、日志记录等业务;而过滤器通常是用来实现通用功能过滤的,比如:敏感词过滤、字符集编码设置、响应数据压缩等功能。
什么是跨域问题?解决跨域的方案都有哪些?日常工作中会使用哪种解决方案?
跨域问题指的是不同站点之间,使用ajax无法互相调用的问题。跨域问题本质是浏览器的一种保护机制,它的初衷是为了保证用户的安全,防止恶意网站盗取数据。但是这个保护机制也带来了新的问题,它的问题是给不同站点之间的正常调用的正常调用,也带来了阻碍,那么如何解决这三种问题呢?
跨域问题的三种情况
在请求时,如果出现以下情况的的任意一种,那么它就是跨域请求:
-
协议不同:
- 例如,从一个使用HTTP协议的网页请求使用HTTPS协议的资源,或者反之
- 示例:从
http://example.com发起请求到https://api.example.com/data
-
域名不同:
- 例如,从一个域名为
example.com的网页请求另一个域名为api.example.com的资源 - 示例:从
http://www.example.com请求到http://api.example.net/data
- 例如,从一个域名为
-
端口不同:
- 例如,从一个使用默认HTTP端口80的网页请求使用非默认HTTP端口的资源,比如8080端口
- 示例:从
http://www.example.com请求到http://www.example.com:8080/data
或者类似以下这几种情况: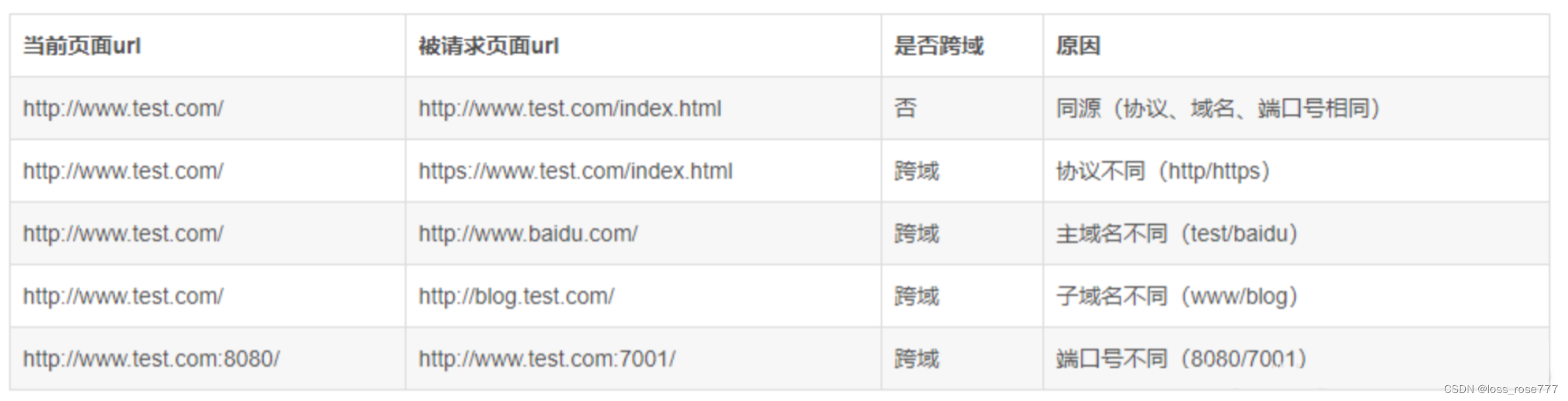
跨域问题演示
接下来,我们使用两个 Spring Boot 项目来演示跨域的问题,其中一个是端口号为 8080 的前端项目,另一个端口号为 9090 的后端接口项目
前端代码 (端口号为8080)
<!-- index.html --><!DOCTYPE html>
<html lang="en">
<head><meta charset="UTF-8"><meta name="viewport" content="width=device-width, initial-scale=1.0"><title>Frontend Project</title>
</head>
<body><h1>跨域测试</h1><button id="getDataBtn">发送跨域请求</button><div id="responseData"></div><script>document.getElementById('getDataBtn').addEventListener('click', function() {fetch('http://localhost:9090/api/data').then(response => response.text()).then(data => {document.getElementById('responseData').innerText = data;}).catch(error => {console.error('Error:', error);});});</script>
</body>
</html>
后端代码 (端口号为9090)
后端接口项目首先先在 application.properties 配置文件中,设置项目的端口号为 9090,如下所示:
server.port=9090// BackendController.javaimport org.springframework.web.bind.annotation.CrossOrigin;
import org.springframework.web.bind.annotation.GetMapping;
import org.springframework.web.bind.annotation.RestController;@RestController
public class BackendController {@GetMapping("/api/data")public String getData() {return "Hello";}
}
在这个示例中:
- 前端代码包含一个简单的HTML页面,通过JavaScript发起一个跨域请求到后端项目的
/api/data接口,并将返回的数据显示在页面上。 - 后端代码是一个简单的Spring Boot控制器,暴露了一个
/api/data的GET接口,当收到请求时返回一条简单的消息。

解决跨域问题
Spring Boot中跨域问题会有很多解决方案,如下:
- 使用@CrossOrigin注解实现跨域
- 通过配置文件实现跨域
- 通过CorsFilter对象实现跨域
- 通过Response对象实现跨域
- 通过实现ResponseBodyAdvice实现跨域
通过注解实现跨域
使用@CrossOrigin注解可以轻松实现跨域,此注解即可以修饰类,也可以修饰方法。当修饰类时,表示此类中的所有接口都是可以跨域的,实现方式如下:
// BackendController.javaimport org.springframework.web.bind.annotation.CrossOrigin;
import org.springframework.web.bind.annotation.GetMapping;
import org.springframework.web.bind.annotation.RestController;@RestController
public class BackendController {@CrossOrigin(origins = "http://localhost:8080") // 允许来自端口为8080的源的跨域请求@GetMapping("/api/data")public String getData() {return "Hello";}
}
使用此方式只能实现局部跨域,当一个项目中存在多个类的话,使用此方式就会比较麻烦(需要给所有类上都添加此注解)
通过配置文件实现跨域
接下来我们通过设置配置文件的方式就可以实现全局跨域了,它的实现步骤如下:
- 创建一个新配置文件;
- 添加 @Configuration 注解,实现 WebMvcConfigurer 接口;
- 重写 addCorsMappings 方法,设置允许跨域的代码。
实现代码如下:
import org.springframework.context.annotation.Configuration;
import org.springframework.web.servlet.config.annotation.CorsRegistry;
import org.springframework.web.servlet.config.annotation.WebMvcConfigurer;@Configuration // 一定不要忽略此注解
public class CorsConfig implements WebMvcConfigurer {@Overridepublic void addCorsMappings(CorsRegistry registry) {registry.addMapping("/**") // 所有接口.allowCredentials(true) // 是否发送 Cookie.allowedOriginPatterns("*") // 支持域.allowedMethods(new String[]{"GET", "POST", "PUT", "DELETE"}) // 支持方法.allowedHeaders("*").exposedHeaders("*");}
}
通过CorsFilter实现跨域
此实现方式和上一种实现方式类似,它也可以实现全局跨域,它的具体实现代码如下:
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
import org.springframework.web.cors.CorsConfiguration;
import org.springframework.web.cors.UrlBasedCorsConfigurationSource;
import org.springframework.web.filter.CorsFilter;@Configuration // 一定不能忽略此注解
public class MyCorsFilter {@Beanpublic CorsFilter corsFilter() {// 1.创建 CORS 配置对象CorsConfiguration config = new CorsConfiguration();// 支持域config.addAllowedOriginPattern("*");// 是否发送 Cookieconfig.setAllowCredentials(true);// 支持请求方式config.addAllowedMethod("*");// 允许的原始请求头部信息config.addAllowedHeader("*");// 暴露的头部信息config.addExposedHeader("*");// 2.添加地址映射UrlBasedCorsConfigurationSource corsConfigurationSource = new UrlBasedCorsConfigurationSource();corsConfigurationSource.registerCorsConfiguration("/**", config);// 3.返回 CorsFilter 对象return new CorsFilter(corsConfigurationSource);}
}
通过Response实现跨域
此方式是解决跨域问题最原始的方式,但它可以支持任意的 Spring Boot 版本(早期的 Spring Boot 版本也是支持的)。但此方式也是局部跨域,它应用的范围最小,设置的是方法级别的跨域,它的具体实现代码如下:
import org.springframework.web.bind.annotation.RequestMapping;
import org.springframework.web.bind.annotation.RestController;import javax.servlet.http.HttpServletResponse;
import java.util.HashMap;@RestController
public class TestController {@RequestMapping("/test")public HashMap<String, Object> test(HttpServletResponse response) {// 设置跨域response.setHeader("Access-Control-Allow-Origin", "*");return new HashMap<String, Object>() {{put("state", 200);put("data", "success");put("msg", "");}};}
}
通过ResponseBodyAdive实现跨域
通过重写 ResponseBodyAdvice 接口中的 beforeBodyWrite(返回之前重写)方法,我们可以对所有的接口进行跨域设置,它的具体实现代码如下:
import org.springframework.core.MethodParameter;
import org.springframework.http.MediaType;
import org.springframework.http.server.ServerHttpRequest;
import org.springframework.http.server.ServerHttpResponse;
import org.springframework.web.bind.annotation.ControllerAdvice;
import org.springframework.web.servlet.mvc.method.annotation.ResponseBodyAdvice;@ControllerAdvice
public class ResponseAdvice implements ResponseBodyAdvice {/*** 内容是否需要重写(通过此方法可以选择性部分控制器和方法进行重写)* 返回 true 表示重写*/@Overridepublic boolean supports(MethodParameter returnType, Class converterType) {return true;}/*** 方法返回之前调用此方法*/@Overridepublic Object beforeBodyWrite(Object body, MethodParameter returnType, MediaType selectedContentType,Class selectedConverterType, ServerHttpRequest request,ServerHttpResponse response) {// 设置跨域response.getHeaders().set("Access-Control-Allow-Origin", "*");return body;}
}
此实现方式也是全局跨域,它对整个项目中的所有接口有效
原理分析
为什么通过以上方法设置之后,就可以实现不同项目之间的正常交互呢? 这个问题的答案也很简单,我们之前在说跨域时讲到:“跨域问题本质是浏览器的行为,它的初衷是为了保证用户的访问安全,防止恶意网站窃取数据”,那想要解决跨域问题就变得很简单了,只需要告诉浏览器这是一个安全的请求,“我是自己人”就行了,那怎么告诉浏览器这是一个正常的请求呢?
只需要在返回头中设置“Access-Control-Allow-Origin”参数即可解决跨域问题,此参数就是用来表示允许跨域访问的原始域名的,当设置为“*”时,表示允许所有站点跨域访问,如下图所示: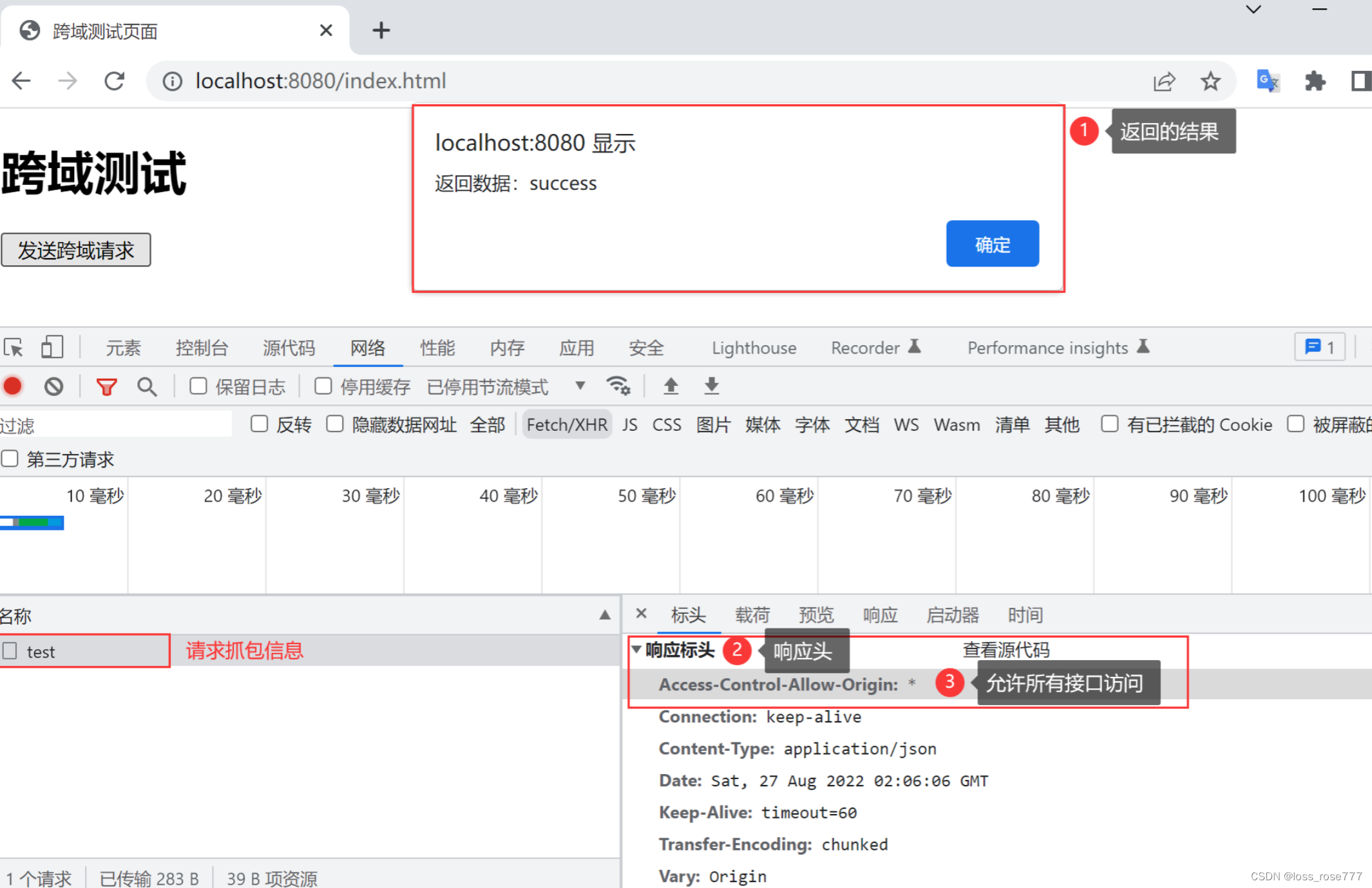
所以以上 5 种解决跨域问题的本质都是给响应头中加了一个 Access-Control-Allow-Origin 的响应头而已
@Transactional底层是如何实现的?
@Transactional时Spring框架中用于声明事务的的注解。它可以应用于方法级别,表示该方法应该在事务的范围内执行。当方法被调用时,Spring会在方法开始时开启一个事务,在方法结束时根据方法执行的结果来决定事务的提交或回滚。例如:
@Transactionalpublic void addUser(User user) {userRepository.save(user);}
当使用@Transactional注解标注一个方法的时候,Spring Boot在运行时会生成一个代理对象,该代理对象拦截被注解的方法调用,并在方法调用前后进行事务的管理。事务管理包括开始十五、提交事务或回滚事务等操作
导致@Transactional失效的场景有哪些?导致事务失效背后的原因是啥?
导致@Trancsctional失效的常见场景有以下几种:
- @Transactional添加在非public方法上
- 使用try/catch处理异常
- 调用类内部的@Transactional方法
- 事务传播机制使用不当
- 数据库不支持事务
非public方法
当使用@Transactional修饰非public方法,事务会失效,失效的原因主要是两种:
浅层原因:浅层原因是@Transactional源码限制了必须是public才能执行后续的代理流程,它的源码如下:
protected TransactionAttribute computeTransactionAttribute(Method method, Class<?> targetClass) { // 不允许非public方法作为必需的方法。 // 如果只允许public方法,并且方法不是public,则设置为null。 if (allowPublicMethodsOnly() && !Modifier.isPublic(method.getModifiers())) { return null; } // 这里可以添加更多的逻辑来处理事务属性,例如根据方法名、参数等决定事务的隔离级别、只读性等。 // 下面是一个示例,仅作参考。 // 根据方法的名称或其他属性来决定事务的隔离级别。 Isolation isolationLevel = Isolation.READ_COMMITTED; if ("someSpecificMethod".equals(method.getName())) { isolationLevel = Isolation.READ_UNCOMMITTED; } // 设置事务的其他属性,如只读、超时等。 TransactionAttribute transactionAttribute = new Propagation(Propagation.REQUIRED) .and(isolationLevel) .and(Transactional.timeout(10)) // 设置事务超时时间为10秒 .and(new ReadOnly()) // 设置事务为只读模式 .build(); return transactionAttribute;
}深层次原因:深层次原因是Spring Boot的动态代理只能代理公告方法,而不能代理私有方法或受保护方法。这是因为欸Spring的动态代理是基于Java的接口代理机制或者基于CGLib库来实现的,而这两种代理方式都是能代理公共方法:
- 接口代理:当目标类种实现了接口,Spring使用JDK动态代理来生成代理对象。JDK动态代理是通过生成实现目标类的匿名类,并将方法调用委托给目标类的实例来实现的。由于接口的方法都是公共的,所以JDK动态代理只能代理公共方法
- CGLib代理:当目标没有实现接口的时候,Spring使用CGLib动态代理来生成代理对象。CGLib动态代理使用过生成目标类的子类,并且将方法调用委托给目标类的实例来实现的。然而,Java中的继承要求要求子类能够继承父类的方法,因此CGLib动态代理也只能代理目标类中的公共方法
使用try/catch处理异常
如果在@Transactional方法内部捕获了所有可能抛出的异常,但是没有将它们重新抛出,那么十五就不会发现异常的存在了,从而就不会回滚事务
从 @Transactiona 实现源码也可以看出,@Transactional 注解只有执行方式捕获到异常了才会回滚,反之则不会,核心源码如下:
protected Object invokeWithinTransaction(Method method, Class<?> targetClass, final Invocation invocation) throws Throwable {// 如果事务属性为null,则方法为非事务性方法final TransactionAttribute txAttr = getTransactionAttributeSource().getTransactionAttribute(method, targetClass);final PlatformTransactionManager tm = determineTransactionManager(txAttr);final String joinpointIdentification = methodIdentification(method, targetClass);// 前半部分代码补全if (txAttr == null || !(tm instanceof CallbackPreferringPlatformTransactionManager)) {// 使用 getTransaction 和 commit/rollback 方法进行标准事务划分// 自动开启事务TransactionInfo txInfo = createTransactionIfNecessary(tm, txAttr, joinpointIdentification);Object retVal = null;try {// 这是环绕通知:调用链中的下一个拦截器。// 正常情况下会调用目标对象的方法// 反射调用业务方法retVal = invocation.proceedWithInvocation();} catch (Throwable ex) {// 目标调用异常// 异常时,在 catch 逻辑中,自动回滚事务completeTransactionAfterThrowing(txInfo, ex);throw ex;} finally {cleanupTransactionInfo(txInfo);// 自动提交事务commitTransactionAfterReturning(txInfo);}return retVal;} else {// 补全部分}
}
调用类内部的@Transactional方法
在Spring中,@Transactional 注解通常与动态代理结合使用来实现事务管理。当你在一个类的方法上标注了 @Transactional 注解时,Spring会为该类创建一个代理对象,并在代理对象上添加事务管理的逻辑。因此,只有通过代理对象调用的方法才能被事务管理器所控制。
如果你在类的内部调用一个带有 @Transactional 注解的方法,而是直接通过 this 对象来调用,那么事务管理器就无法介入,因为调用不经过代理对象。这样的调用会绕过代理,导致事务管理失败。
事务传播机制使用不当
如果事务传播机制设置为 Propagation.NEVER 以非事务方式运行,或者是 Propagation.NOT_SUPPORTED 以非事务方式运行,如果当前存在事务,则把当前事务挂起的传播机制,则当前 @Transactional 修饰的方法也是不会正常执行事务的
数据库不支持事务
Spring Boot/Spring 框架内之所以能使用事务是因为它们连接的数据库支持事务,这是前提条件,所以当数据库层面不支持事务时,那么框架中的代码无论怎么写都不会存在事务的
什么是事务传播机制?它有啥用?
Spring Boot事务传播机制是指,包含多个事务的方法在相互调用的时候,事务是如何在这些方法间传播的

Spring Boot事务传播机制可以使用@Transactional(propagation=Propagation.REQUIREN)来定义,事务传播机制级别重要是包含以下七种:
- Propagation.REQUIRED:默认的传播级别,它表示如果当前存在事务,则加入该事务;如果当前不存在事务,则会创建一个新的事务
- Propagation.SUPPORTS:如果当前存在事务,则加入事务;如果当前不存在,则以非事务的方式运行
- Propagation.MANDATORY:(mondatory:强制的)如果当前存在事务,则加入事务;如果不存在,则抛出异常
- Propagation.REQUIRES_NEW:表示创建一个新的事务,如果当前存在事务,则把当前事务挂起。也就i是不管外部方法是否开启事务,Propagation.REQUIRES_NEW修饰的内部方法回信开启自己的事务,且开启的事务相互独立,互不干扰
- Propagation.NOT_SUPPORTED:以非事务方式运行,如果当前存在事务,则把当前事务挂起
- Propagation.NEVER:以非事务的方式运行,如果当前存在事务,则抛出异常
- Propagation.NESTED:(nested:内嵌)如果当前存在事务,则创建一个事务作为当前事务的嵌套事务来运行;如果没有事务,则等价于Propagation.REQUIRED。其中嵌套事务是一个事务内部又包含另一个事务,它被包含的事务称为子事务。当外部事务执行时,它开启一个主事务,如果主事务需要执行多个操作,它可以开启一个或多个子事务。子事务的执行依赖于外部事务的执行状态,如果外部事务失败,所有的子事务都会被回滚,保证数据的一致性和完整性。

SpringBoot中使用了哪些设计模式?
设计模式是编写高质量、可维护和可扩展软件的重要工具。设计模式主要有以下几种:
- 工厂模式:Spring通过BeanFactory接口及其实现类如ApplicationContextdeng,为应用程序提供了一个统一的Bean工厂,负责创建和管理各种Bean的对象
- 单例模式:Spring会将所有的bean声明为单例。当容器启动的时候,每一个Bean只会被初始化一次,后续对同一个Bean的所有请求都会返回相同大的实例。例如,通过SingletonBeanRegistry接口保证单例Bean在整个应用上下文只存在一个实例
- 代理模式:Spring AOP大量使用了代理模式。它利用JDK动态代理或CGLib库生成代理对象,实现代理功能以添加额外的功能
- 观察者模式:Spring事件驱动模型以实现了观察者模式。用于在对象之间建立一种一对多的依赖关系。通过 ApplicationEventPublisher 发布和监听事件
- 策略模式:Spring框架中的资源加载(Resource)就是一个策略模式的例子。根据不同的资源路径,Spring会选择合适的策略进行资源加载
- 装饰器模式:Spring MVC的拦截器Interceptor可以看作一种装饰器模式的应用。根据不同的资源路径,它允许我们呢包装HandlerExecutionChain,在执行处理器方法的前后插入自定义行为
- 适配器模式:Spring通过适配器模式这个和不同类型的组件,比如对第三方数据源的连接池(如DBCP、HikariCP等)进行适配,使其能够与Spring容器无缝集成
- 模板方法模式:Spring JDBC等模块种,提供了如JdbcTemplate这样的模板类,它封装了通用的数据访问逻辑,而具体的操作由用户提供的SQL来实现
说一下MyBatis执行流程?
MyBatis是一款优秀的基于Java的持久层框架,它内部封装了JDBC,使开发者只需要关注SQL语句本身,而不需要花费精力去处理加载驱动、创建连接等的过程,MyBatis的执行流程如下:
- 加载配置文件:MyBatis的执行流程从加载配置文件开始。通常,MyBatis的配置文件是一个XML文件,其中包含了了数据源配置,SQL映射配置、连接池配置
- 构架SqlSessionFactory:在配置文件加载后,MyBatis使用配置信息来构建SqlSessionFactory,这是MyBatis的核心工厂类。SqlSessionFactory是线程安全的,它用于创建SqlSession对象
- 创建SqlSession:应用程序通过SqlSessionFactory床渐渐SqlSession对象。SqlSession代表依次数据库会话,它提供了执行SQL操作的方法。通常情况下,每个线程都应该由自己的SqlSession对象
- 执行SQL查询:在SqlSession种,开发人员可以执行SQL查询你,这可以通过两种方式实现:
- 使用注解加SQL:Mybatis提供了注解加执行SQL的实现方式,MyBatis会为Mapper接口生成实现类的代理对象,实际执行SQL查询
- 使用XML映射文件:开发人员可以在XML映射文件中定义SQL查询语句和映射关系。然后,通过SqlSession执行这些SQL擦汗寻,将结果有映射到Java对象上
- SQL解析和执行:MyBatis会解析SQL查询,执行查询操作,并获取查询结果
- 结果映射:MyBatis使用配置的结果映射规则,将查询结果映射到Java对象上。这包括将数据库列映射到Java对象的属性上,并处理关联关系
- 返回结果:查询结果被返回给应用程序,开发热恩于那可以对结果进行进一步处理、展示或之旧话
- 关闭SqlSession:完成数据库操作后,关闭SqlSession释放资源
${}和#{}有什么区别?什么情况下一定要使用${}?
${}和#{}都是MyBatis种用来代替参数的特殊标识,如下:
但是二者的区别二还是很大的,主要区别如下:
- 含义不同:${}是直接替换(运行时已经替换成具体的执行SQL了),而#{}是预处理(运行时只设置了占位符"?",之后通过声明器(statement)来替换占位符)
- 使用场景不同:普通参数使用#{},如果传递的是SQL命令(如desc还是asc)或者SQL关键字的时候,需要使用${},但是使用之前一定要做好安全验证
- 安全性不同:使用${}存在安全性问题,#{}不存在安全性问题
也就是说,为了防止安全问题,所以大部分场景都要使用 #{} 替换参数,但是如果传递的是 SQL 关键字,例如order by xxx asc/desc 时(传递 asc 后 desc),一定要使用 $,因为它需要在执行时就被替换成关键字,而不能使用占位符替代(占位符不用应用于 SQL 关键字,否则会报错)。
在传递 SOL 关键字时,一定要使用 ${},但使用前,一定要进行过滤和安全检査,以防止 SQL 注入。
什么是SQL注入?如何防止SQL注入?
SQL注入就是指应用程序对用户输入的数据的合法性没有判断或过滤不严,攻击者可以在应用程序中事先定义好查询语句的结尾上添加额外的SQL语句,在管理员不知情的情况下实现非法操作,依次来实现欺骗数据库服务器执行非授权的热议操作,从而进一步得到相应的数据信息
也就是说所谓的 SQL 注入指的是,使用某个特殊的 SQL 语句,利用 SQL 的执行特性,绕过 SQL 的安全检查,查询到本不该查询到的结果
如以下代码:
<select id="doLogin" resultType="com.example.demo.model.User">select *from userinfo where username='${name}' and password='${pwd}
</select>sql注入以下代码 :"'or 1='1",如下图所示:
从上述结果可以看出,以上程序在应用程序不知情的情况下实现非法操作,以此来实现欺骗数据库服务器执行非授权的敏感数据
如何防止SQL注入
预编译语句与参数化查询:使用 PreparedStatement 可以有效防止 SQL 注入,因为它允许你先定义 SQL 语句的结构,然后将变量作为参数传入,数据库驱动程序会自动处理这些参数的安全性,确保它们不会干扰 SQL 语句的结构,如下代码所示:
String sql ="SELECT * FROM users WHERE username = ? AND password = ?";
PreparedStatement pstmt= connection.prepareStatement(sql);
pstmt.setString(1,userInputUsername);
pstmt.setstring(2,userInputPassword);
ResultSet rs=pstmt.executeQuery();输入验证和过滤:对用户输入的信息进行验证和过滤,确保其符合预期的类型和格式
说一下MyBaits中的二级缓存?
MyBatis二级缓存是用于提高MyBatis查询数据库的性能和减少访问数据库的机制。MyBatis的二级缓存总共由两个缓存机制:
- 一级缓存:SqlSession级别的,MyBatis自带的缓存功能。并且无法关闭,因此当有两个SqlSession访问相同的SQL时,一级缓存也不会生效,也需要查询两次数据库。在一个service调用两个相同的mapper方法的时候,依然是查询两次,因为他会创建那两个SqlSession进行查询(为了提高查询性能)
- 二级缓存:Mapper级别的,只要是同一个Mapper,无论是使用多少个SqlSession来操作,数据都是共享的。也就是说,一个sessionFactory下的多个session之间是共享缓存的,它的作用范围更大,生命周期更长,可以减少数据库的查询次数,提高系统性能。但是MyBatis二级缓存时默认关闭的需要手动开启
二级缓存默认是不开启的,手动开启MyBatis步骤如下:
- 在mapper.xml中添加<cache/>标签
- 在需要缓存的标签上添加usrCache="true"(新版本可以忽略,为了兼顾老版本,保留)
完整示例如下:
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE mapper PUBLIc "-//mybatis.org//DTD Mapper 3.0//EN" "http://mybatis.org/dtd/mybatis-3-mapper.dtd">
<mapper namespace="com.mybatis.demo.mapper.StudentMapper"><cache/><select id="getStudentCount" resultType="Integer" usecache="true">select count(*)from student</select>
</mapper>编写单元测试代码:
import org.junit.jupiter.api.Test;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.boot.test.context.SpringBootTest; @SpringBootTest
public class StudentMapperTest { @Autowired private StudentMapper studentMapper; @Test void testGetStudentCount() { int count = studentMapper.getStudentCount(); System.out.println("查询结果:" + count); int count2 = studentMapper.getStudentCount(); System.out.println("查询结果2:" + count2); }
}运行结果: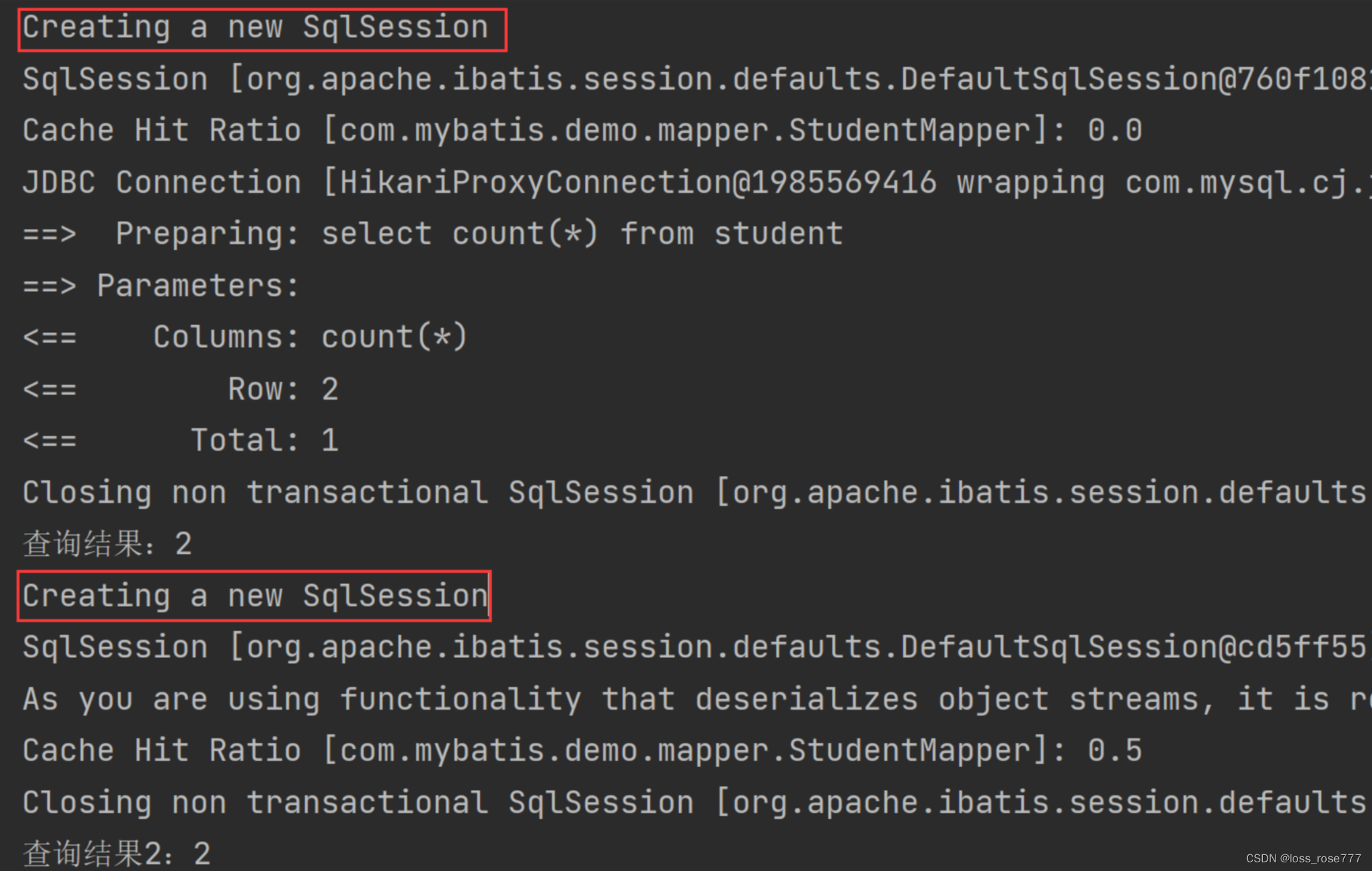
从以上结果可以看出,两次查询虽然使用了不同的 SqlSession,但第二次查询使用了缓存,并未查询数据库