1.命令:
cp -r [源文件或目录] [目的目录] #复制
ln -s [被链接的文件] [链接的目录/名称] #软连接
ln [被链接的文件] [链接的目录/名称] #硬连接注:cp -r 会把所有source当作普通文件(regular文件); 而cp -R 对特殊文件(管道文件,块设备文件,字符设备文件)会进行创建操作,而不是拷贝。
2.执行命令结果
原文件:ee_lnh.txt
复制的文件:cp.txt
硬连接的文件:lnh.txt
软连接的文件:lns.txt
3.区别
3.1 硬连接
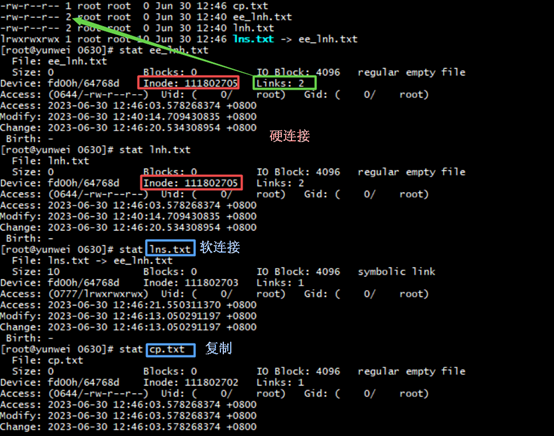
- 硬链接实际上是为文件建一个别名,链接文件和原文件实际上是同一个文件,硬链接和原来的文件没有什么区别,而且共享一个 inode 号(文件在文件系统上的唯一标识)。
方法:通过ls -li 来查看一下
结果:这两个文件的inode号是同一个,说明它们是同一个文件。
且文件的硬链接数量Links=2,说明有2个硬连接。

3.2 软连接
- 软链接建立的是一个指向,即链接文件内的内容是指向原文件的指针,它们是两个文件。
方法:通过ls -li 查看
结果:可观察到硬链接和源文件的文件类型一样为“-”,而软链接为“l”。
这两个文件的inode号不相同,说明它们非同一个文件。

3.3 复制
- 复制,其实硬链接和软链接和源文件三者任意一个改变三者都会同步改变,这是他们与复制之间的区别。
方法:然后通过ls -li 查看
结果:和源文件的inode号不相同,但是文件类型一样为“-”。
源文件:1.txt 复制的文件:cp1.txt 硬连接:h.txt 软连接1_s1.txt
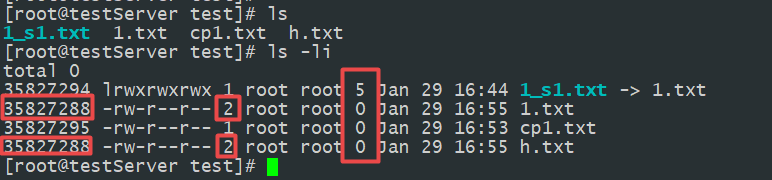
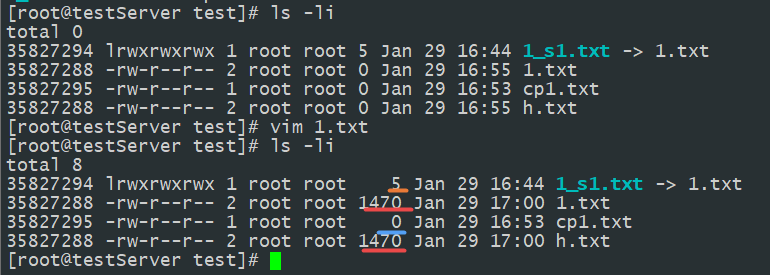
方法:修改1.txt文件,使其大小改变,然后通过ls -li 查看
结果:源文件大小、内容改变;
硬连接文件大小、内容改变;
复制的文件大小不变,内容不变;
软连接大小不变,内容改变。
 3.4 stat命令查看inode信息
3.4 stat命令查看inode信息
- 用 stat 文件名 #来查看文件的inode信息来区分两个文件是复制的还是硬链接
4.inode 是什么?
我们还必须找到一个地方储存文件的元信息,比如文件的创建者、文件的创建日期、文件的大小等等。这种储存文件元信息的区域就叫做inode,中文译名为"索引节点"。 磁盘上inode节点存储和数据“块”存储是在两个不同的区域,inode存储文件的元数据,但是不包括变长的文件名信息,因此inode大小是固定的,包含的元数据如下:
* 文件的字节数
* 文件拥有者的User ID
* 文件的Group ID
* 文件的读、写、执行权限
* 文件的时间戳,共有三个:ctime指inode上一次变动的时间,mtime指文件内容上一次变动的时间,atime指文件上一次打开的时间。
* 链接数,即有多少文件名指向这个inode
* 文件数据block的位置
硬盘格式化的时候,操作系统自动将硬盘分成两个区域。一个是数据区,存放文件数据;另一个是inode区(inode table),存放inode所包含的信息。
每个inode节点的大小,一般是128字节或256字节。inode节点的总数,在格式化时就给定,一般是每1KB或每2KB就设置一个inode。假定在一块1GB的硬盘中,每个inode节点的大小为128字节,每1KB就设置一个inode,那么inode table的大小就会达到128MB,占整块硬盘的12.8%。
1GB 硬盘 1KB 1个 1个为128B1GB=1024M=1024*1024K=1048576KB (个)Inode table大小=1048576*128B=1048576*128/1024 KB=1024*128/1024 MB=128MB因此,对于存储大量小文件来说,可能文件系统的inode不够用,如果inode资源耗尽,就无法新建文件。
比如阿里的TFS(专门用于存储小文件的分布式存储)就是将小文件合并成“大块”文件来存储的,节省inode资源。可以使用 df -i 查看各个分区的Inode使用情况:
每个inode都有一个号码,操作系统用inode号码来识别不同的文件。Unix/Linux系统内部不使用文件名,而使用inode号码来识别文件。对于系统来说,文件名只是inode号码便于识别的别称或者绰号。
表面上,用户通过文件名,打开文件。实际上,系统内部这个过程分成三步:首先,系统找到这个文件名对应的inode号码;其次,通过inode号码,获取inode信息;最后,根据inode信息,找到文件数据所在的block,读出数据。使用*ls -i file_name*命令可以查看inode号码。
笔记日期:20230630