目录
一、引入
二、基本术语
三、假设空间与归纳偏
四、模型选择
一、引入
机器学习:通过计算手段,得出具有能够自我修改、完善能力的模型,利用经验改善系统自身性能。算法使用数据得到模型的过程即称为学习,或训练
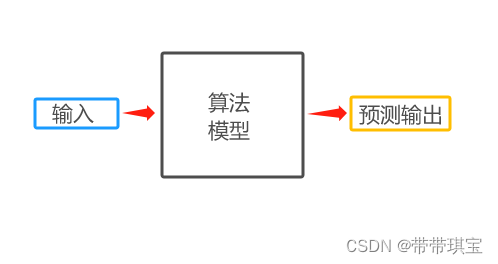
流程:根据输入数据,通过算法得到预测模型,对目标进行预测
模型类别:分为有监督学习和无监督学习,其中有监督学习主要有分类和回归,无监督学习有如聚类等。关于有监督学习和无监督学习可见另一篇文章
机器学习:什么是监督学习和无监督学习-CSDN博客
得到模型之后即可进行预测,会有用于测试的测试样本
二、基本术语
以例子的方式理解一些主要的术语,现有一个问题:如何判断一个西瓜是否是好瓜。取100个西瓜进行研究,则
数据集:这100个西瓜通过量来表示,即可视为数据集,数据集可分为训练集和测试集
训练集:训练的过程使用的数据集。
测试集:进行预测或测试使用的数据集。
一般机器学习的任务是希望通过对训练集进行学习,建立一个从输入x到输出y的映射——f:X->Y。在学到模型 f 后,对测试集进行测试,看这个模型训练的精度能够达到多少。
样本:取其中部分西瓜进行研究,可称为样本
属性:又称特征,描述事物在某个方面的具体表现,常常在数据中的表现形式为数据集的某一列,一个特征表示一列数据。
属性值:又称特征值,表示某样本在该属性上的具体取值,比如西瓜的体积是 60cm³ 。这个“60cm³ ”在此处即是西瓜大小这一属性的取值
维度:用于表示特征的多少,如上面三个特征就是三维
属性空间:又称样本空间,属性张成的空间。是属性的所有可能取值组成的集合,如果属性是多维度的,则属性空间是多维度的集合。
例:只有一个属性,在该属性上的所有可能取值组成的集合 [1,2,3,...] 构成一维属性空间,若有多个维度,如一个人的年龄,身高,体重构成一个属性空间为三维[[1,2,3,...],[171,181,182,...],[140,152,110,...]]
特征向量:使用西瓜三个特征——色泽,根蒂,敲声三个属性,作为三个坐标轴,每个西瓜对应一个空间点(一个原点指向该点的坐标向量),每个这种示例称为一个特征向量。
泛化能力:算法对于未见过的新数据的预测能力
三、假设空间与归纳偏
假设空间:由于机器学习是学习得到由输入到输出的映射(或模型),对于所有属性的所有取值会构成假设空间。如好西瓜问题的假设空间由“(色泽=XXX)^(根蒂=XXX)^(敲声=XXX)”中所有可能的取值假设构成。
版本空间:在过程中可以有许多策略对假设空间进行搜索,例如自顶向下、从一般到特殊,不断删除和正例不一致的假设、和与反例一致的假设,最终将会获得与训练集相匹配(即所有训练样本基本都能够判断正确)的假设,这些假设构成版本空间。
如上述假设空间中,满足“是好西瓜”的特征的假设构成版本空间
归纳偏好:假如现在版本空间中有三个与训练集相匹配的假设,但是对应的模型在遇到一个新问题时可能会产生不同的预测结果。那么,应该如何选择?这时,学习算法本身的“偏好”就会起到决定性作用。机器学习算法在学习过程中对某种类型假设的偏好,称为:“归纳偏好”。简单来说就是对哪一个特征或模型更相信,可看作学习算法本身在一个有可能很庞大的假设空间中的“价值观”。
关于这几个概念可以看一下这个例子:
西瓜书《机器学习》阅读笔记1——Chapter1_假设空间_机器学习周志华,西瓜问题假设空间微为65怎么计算的-CSDN博客
如何来引导算法树立正确的偏好,或者说如何选择合适的模型呢
四、模型选择
两个重要原则:
原理1:奥卡姆剃刀:如无必要,勿增实体。即若有多个假设与研究结果一致,选择最简单的
原理2:NFL原理(没有免费午餐原理):若学习算法 A 在某些问题上比学习算法 B 要好,那么必然存在另一些问题,在这些问题中比 A 表现更好。原理之类的感兴趣朋友可以看看↓
机器学习周志华--没有免费的午餐定理_机器学习的没有免费的午餐的公式证明-CSDN博客